
作者 | 陳駿達
編輯 | 漠影
洋抖難民瘋狂湧入小紅書,都快看不懂帖子了,怎麼辦?
除了找翻譯軟件和期待小紅書的官方工具外,你還可以試試國產AI:截取你看不懂的帖子,AI就能告訴你海外網友的狗狗品種,還能用中英雙語撰寫回復。
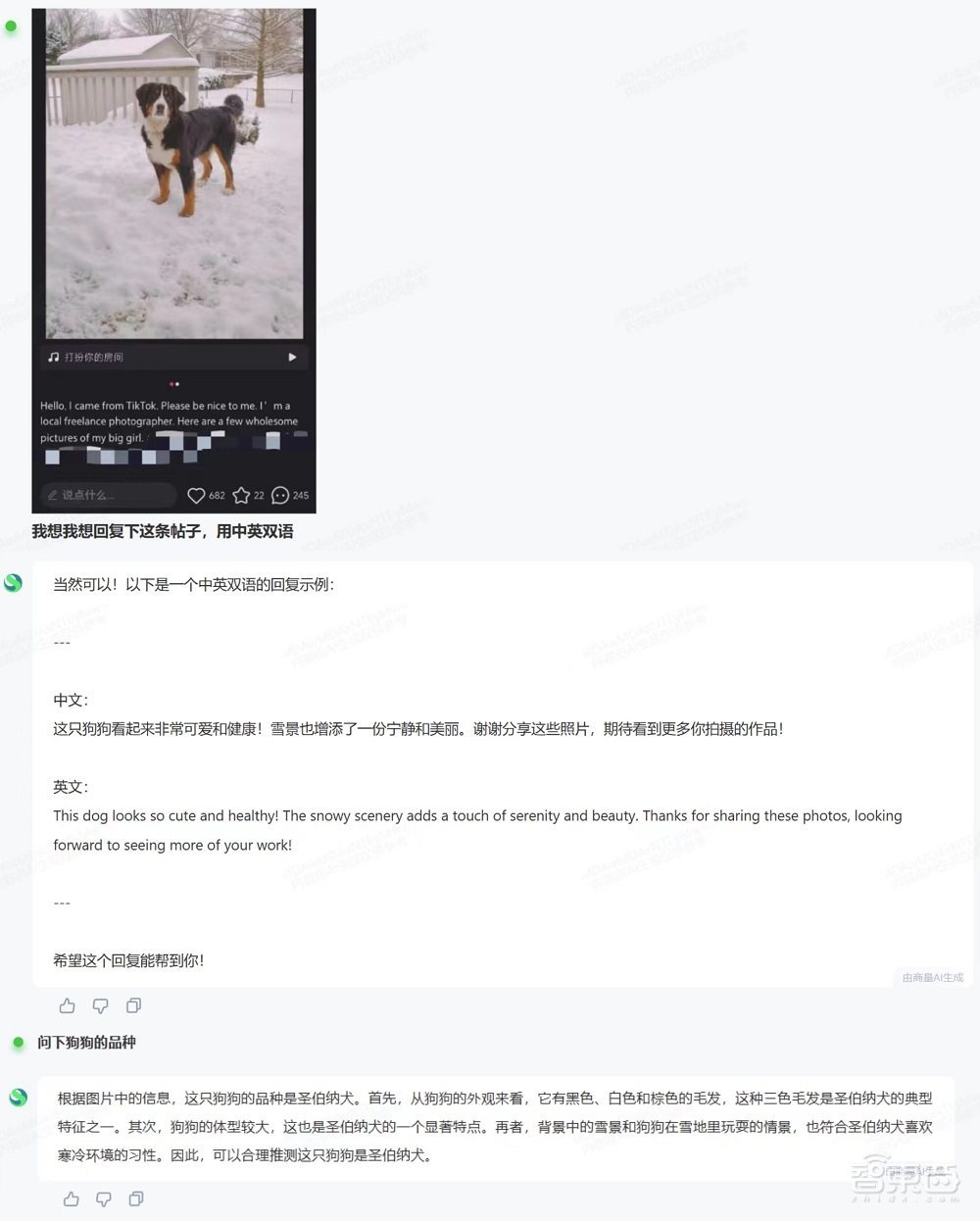
海外網友或許也可以嘗試嘗試中國AI。下方帖子中,網友用字跡潦草的中英雙語撰寫了帖子。AI能幫根據英文原文幫網友修改中文,無縫實現國際網上衝浪。
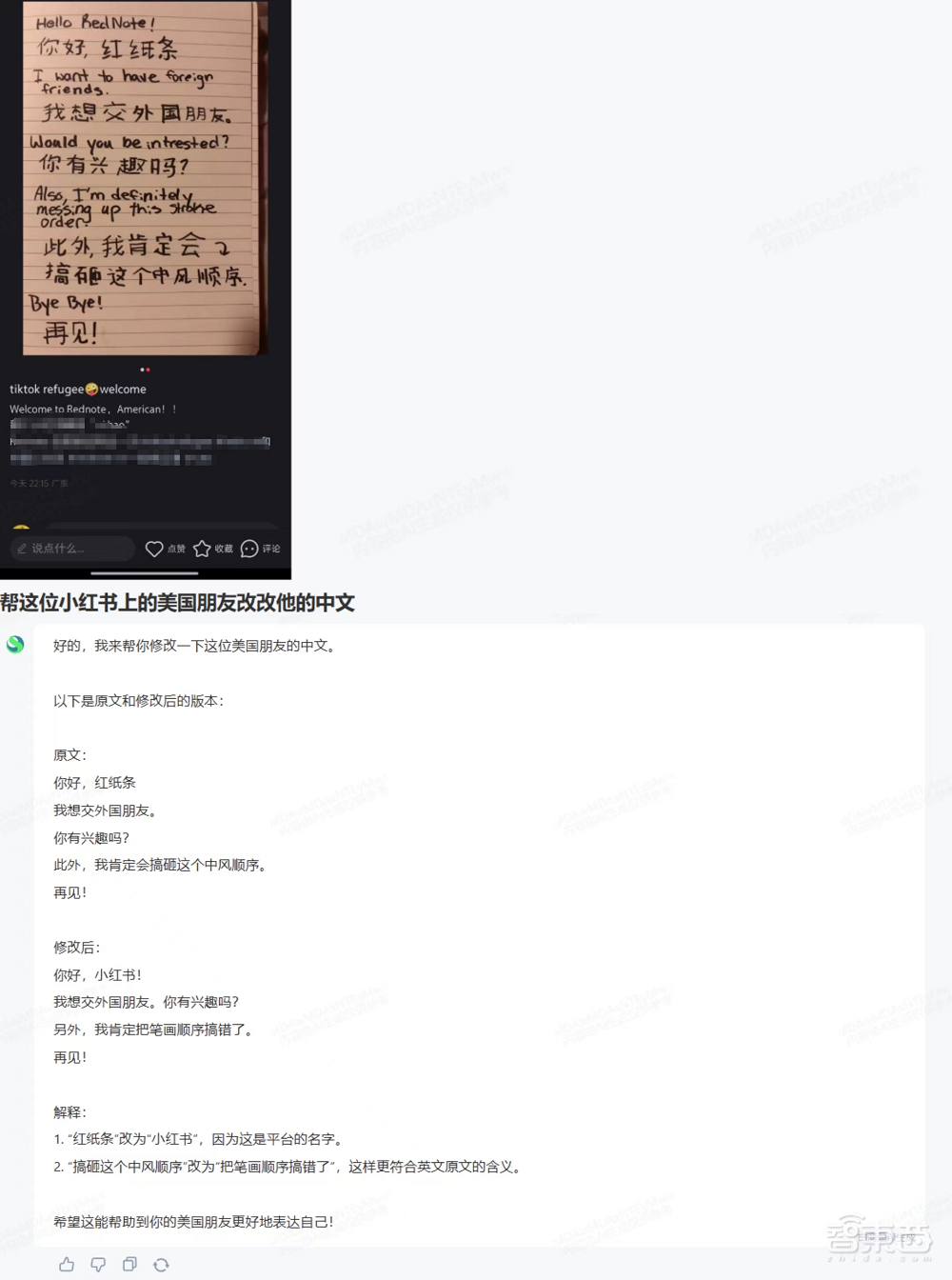
上述有趣有用又有梗的回覆背後,是來自國內首個採用原生融合方法的多模態模型——商湯 「日日新」融合大模型。
多模態融合是指將文字、圖像、視頻、聲音等多種信息整合在一起,進行全模態的分析和理解。依照模態融合路徑訓練的模型能夠更好地處理跨模態任務,具備類似人類的認知方式、更強的泛化能力、更廣泛的應用場景以及更強大的推理能力。
從上述的例子中也可以看出,「日日新」能從畫面中提取文字中未包含的信息,並綜合文字和畫面中的要素,給出與場景高度契合的回覆。
「日日新」融合大模型在原生融合模態訓練上,突破傳統方法侷限,實現了兩個關鍵技術創新,解決了困擾多模態研究的「蹺蹺板」問題,成功跨越了模態之間的鴻溝。
在最近的兩項權威評測中,商湯用單一模型挑戰圖文多模態、純語言與推理等各項任務,並戰勝其他所有單一模態模型,通過「換道超車」,躍升至國產大模型領跑行列。
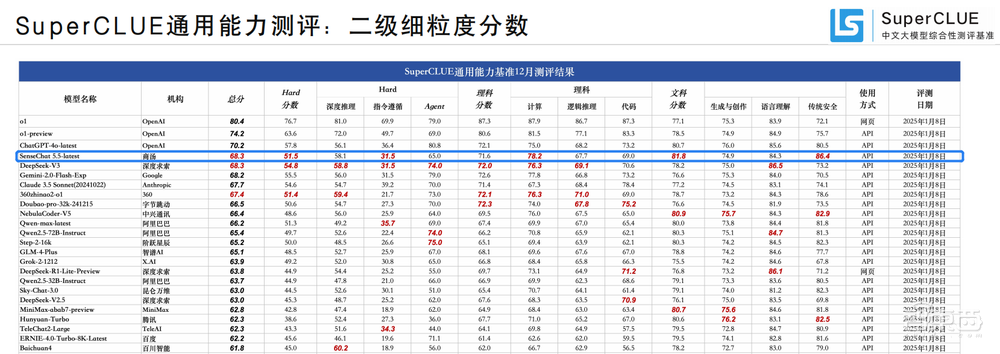
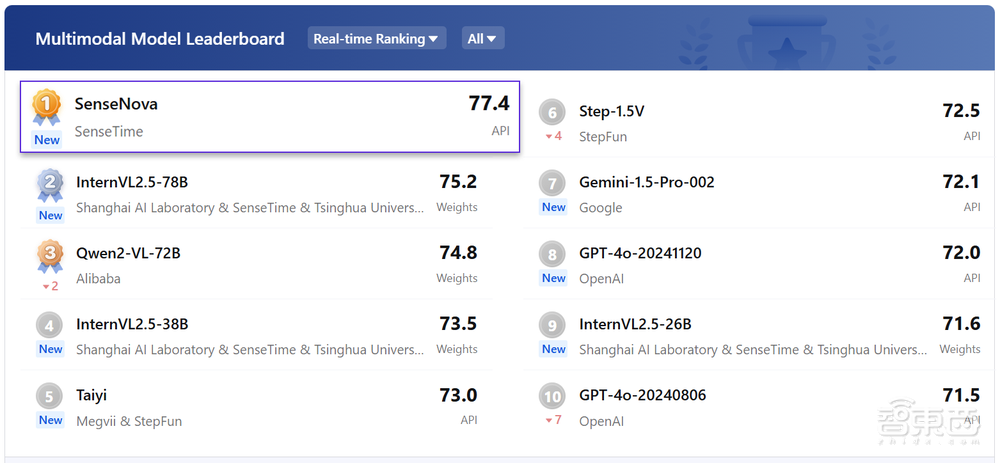
在最新的SuperCLUE 2024年度報告中,商湯「日日新」融合大模型以總分68.3的優異成績,與DeepSeek V3並列國內榜首,成為年度第一。其中文科成績超越OpenAI的o1模型。同時,在OpenCompass多模態評測中,商湯的同一款模型同樣取得了排行榜第一,分數大幅領先GPT-4o。
日前,這款模型已上線商量、辦公小浣熊等商湯旗下產品,智東西也第一時間上手體驗了這一模型。作為一款打破語言與多模態兩大能力維度壁壘的模型,「日日新」融合大模型貢獻了不少新奇有趣的玩法和場景。
一、大模型秒變遊戲軍師、文案助手,不僅看懂畫面還能深度推理
無論是對傳統視覺算法還是多模態大模型而言,識別畫面中的某一具體元素都要比識別單一物體更具挑戰。為測試這一能力,我向搭載新款「日日新」融合大模型的商量發送瞭如下截圖,並詢問圖中的游泳池位於哪裏。

這一遊戲的像素風對識別提出了更多的挑戰,不過,「日日新」很快給出了回答:
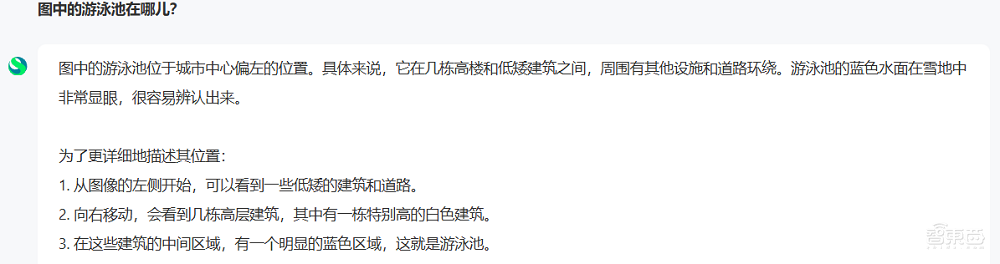
「日日新」對圖片的描述十分準確,這一游泳池確實位於城市中央偏左位置。
然而,當我上傳圖片並用英文向GPT-4o最新版本提問時,GPT-4o認為游泳池在圖片中央偏右的區域,似乎是將藍色的屋頂識別為游泳池了。
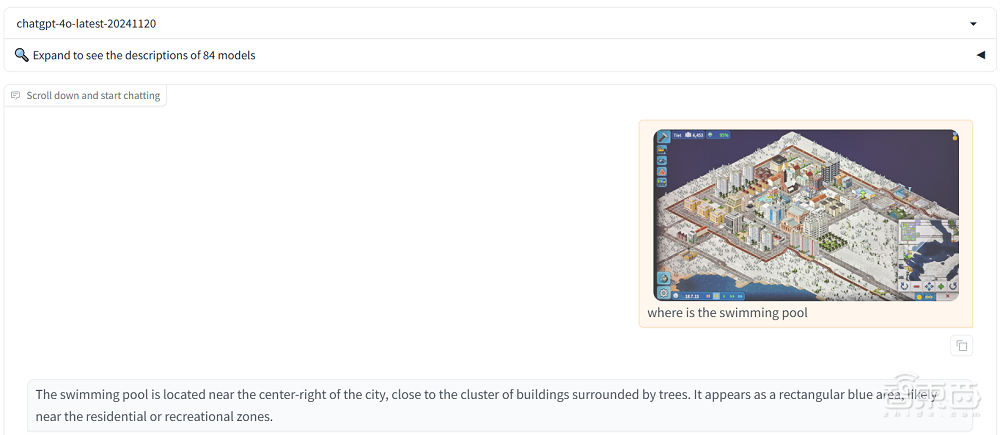
我又在大模型競技場盲測了兩款模型,它們也無法準確回答。左側的模型A(Llama-3.2-vision)認為游泳池在城市右上角,靠近網球場,但圖中並無所謂的網球場。而右側的模型B(Gemini-test)似乎辨識出了游泳池,但它對這一建築的描述並沒有「日日新」的清晰。
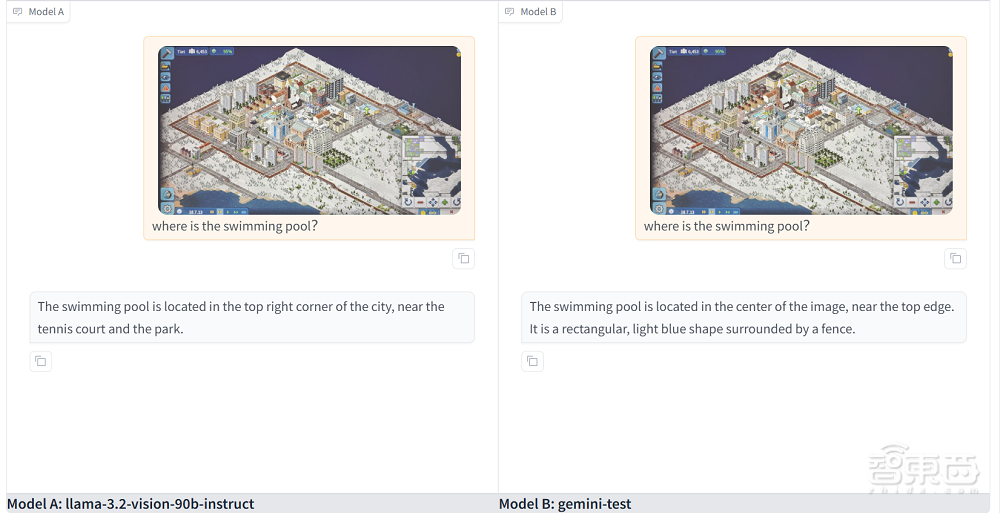
「日日新」不僅能定位畫面中的元素,還能根據畫面內容進行進一步的推理,就上方的截圖,我向這一模型提問:「圖中消防局的位置合理嗎?」
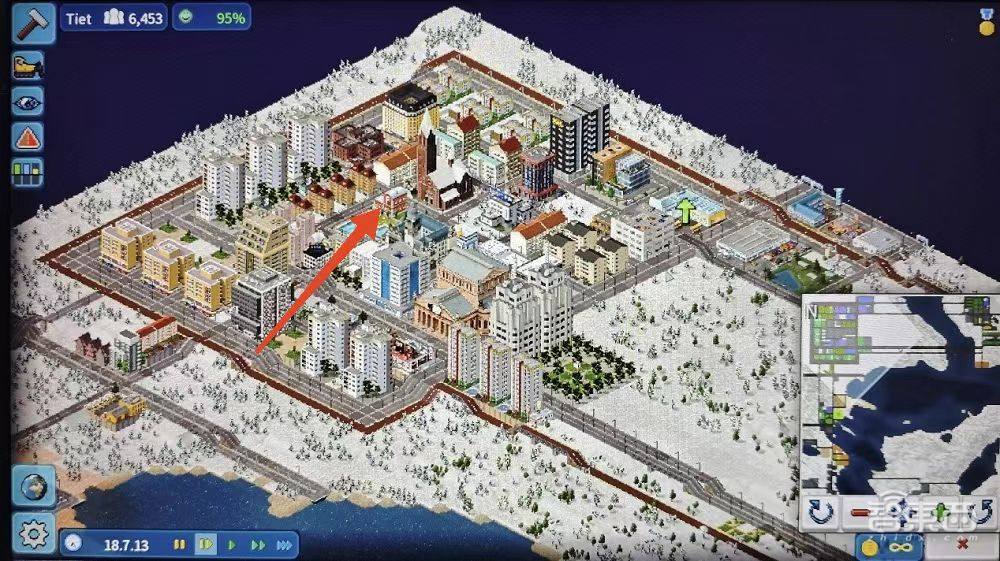
▲消防局在圖中箭頭所指處,給模型發送的圖片不帶任何標記
「日日新」先是準確找到了消防局的位置,還對消防局周邊的建築性質、道路情況進行了分析,最終得出消防站佈局合理的結論。

此外,市面上大部分模型都存在重理輕文的特點,但「日日新」融合大模型在文科、理科任務的表現上都同樣出色。
在下方的創意寫作類任務中,「日日新」融合大模型憑藉融合模態能力,準確地捕捉到了「水深危險,請勿靠近」這句警示標語和水面上悠閒嬉水的綠頭鴨之間的衝突,還給鴨子們撰寫了內心os:「我們是來監督的!」

而針對這副法國印象派作家莫奈的作品,「日日新」融合大模型分析得頭頭是道,不僅注意到了顏色的細微變化、具體部位的描繪特點,還能理解畫作背後的視覺觀感、繪畫技巧。

二、直面現實世界,讓真正的多模態大模型替你工作
傳統大語言模型僅支持單一文本輸入,部分視覺模型能通過OCR(文字識別)提取圖片中的語言信息進行理解,但作為真正的多模態大模型,「日日新」融合大模型可以綜合處理圖像、視頻、語音、文本等多源異構信息,實現深度融合和推理,最終給出更為全面準確的回應。這種能力讓模型能夠真正理解現實世界的需求,在各種複雜的業務場景中,成為你的交互對象和工作助手。
我將手頭一份《2024中國翻譯行業發展報告》交給搭載商湯「日日新」融合大模型的辦公小浣熊和搭載Gemini谷歌Notebooklm,看看這兩款支持文檔上傳的AI工具在報告解讀的場景表現如何。
這份報告共有55頁,其中包含大量圖表,圖文交錯,對模型的多模態文檔分析能力提出較高的要求。下方是辦公小浣熊的回答,它成功找到了我需要的信息,而這一信息是位於一張圖表中的。
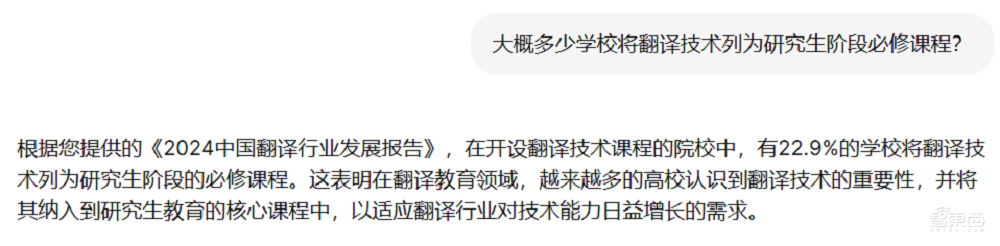
Notebooklm在這一問題上落敗,它將「必選」與「選修」的數據混淆了,正確答案與它的回答正相反。
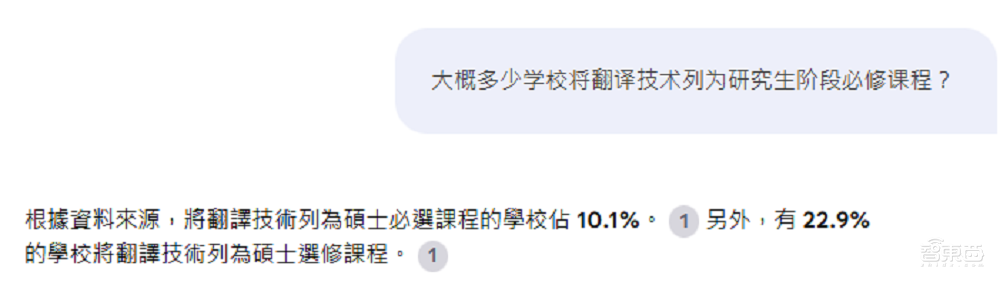
Notebooklm雖然引用了原文,但點進引用後可以發現它對文檔的處理比較混亂,圖表變為了零散的文字,這可能也最終導致了它的錯誤回答。

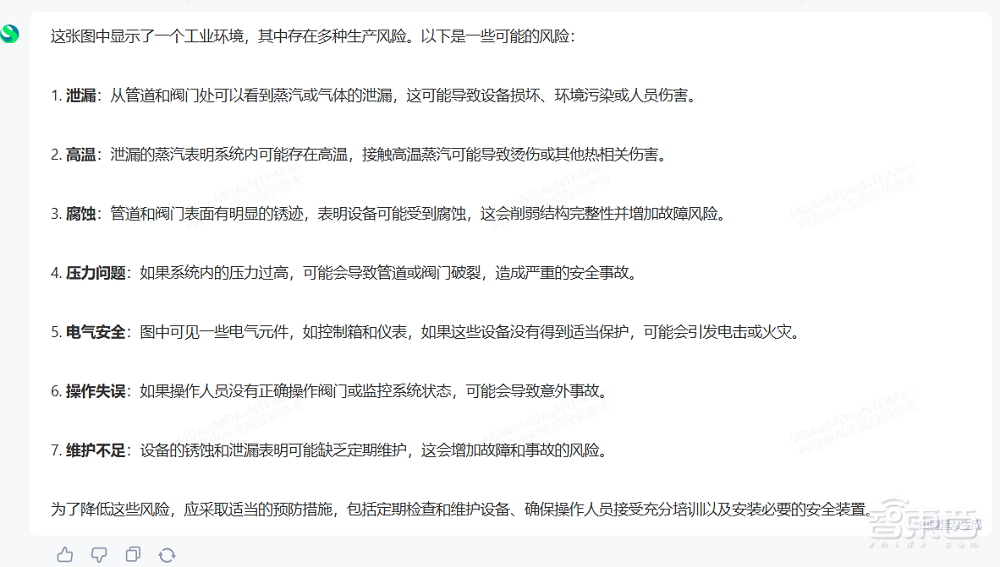
商湯「日日新」融合大模型還能在一線工業生產場景中發揮作用。我將下方的工廠實拍圖片發送給它,它迅速對圖中的生產風險進行分析。

「日日新」發現了圖中的7個潛在問題,並警告了燙傷、電擊等風險。
當我繼續詢問該如何解決這一問題時,「日日新」給出了一個包含12個步驟的解決方案,從維修人員的保護措施到維修流程,再到維修完成後的記錄與報告,一應俱全。

隨着AI越來越多地與物理世界產生聯繫,商湯「日日新」融合大模型將可能與汽車、智能硬件、具身智能機器人等實現有機結合,將語言、圖像、視頻等多模態信息作為輸入,理解用戶指令並完成推理後,使用語言和圖像等進行輸出,在特定的生產、服務場景中發揮重要作用。
三、破解「蹺蹺板」效應,多模態是大勢所趨
商湯發布的「日日新」融合大模型,對國內多模態大模型及AI行業來說具有重要的引領性意義。在探索原生多模態融合訓練過程中,商湯發展出兩項關鍵的創新技術:融合模態數據合成,和融合任務增強訓練。這使其擁有強大的對多模態信息理解分析能力,以及對場景的有效響應,並湧現出多模態信息的深度推理能力;同時在圖文模態之間建立了交互橋樑,為更好地完成跨模態任務打下堅實基礎。
商湯在打造最強原生多模態大模型方面,具有三個維度的優勢。
從訓練數據的維度來看,「日日新」採用的原生融合技術路徑擴展了模型接觸數據的通路和空間,讓模型能接觸到更大量級、更多類型的數據。
與之相對的傳統圖文對齊範式依賴於文字描述,但文字這一介質不免會帶來多模態信息的壓縮和損失,限制模型能力的提升。

▲一條典型的圖文對齊數據,標誌上的塗鴉和上方的「NO TRUCKS」均沒有體現在文本中(圖源:LAION)
這種模型還可能出現「蹺蹺板效應」,也就是多模態能力提升的同時,子模態能力下降。此外,簡單的圖文對齊模型也很難對圖像和文本之間的複雜關係有深刻理解。
在高質量數據日益枯竭的當下,「日日新」不僅能有效利用廣泛存在的天然多模態數據,還通過合成數據平衡數據分佈,補齊天然數據短板。
商湯科技聯合創始人、人工智能基礎設施及大模型首席科學家林達華認為,原生融合技術路徑將幫助他們突破傳統大語言模型的Scaling Law限制。換言之,原生融合多模態大模型的能力上限要更高。
從應用維度來看,商湯在計算機視覺領域深耕超過10年,積累了AI賦能場景的豐富經驗,和對視覺和多模態的獨到理解,這是許多企業所不具備的。依託於這些經驗和思考,商湯在「日日新」融合模型的訓練過程中構建大量跨模態任務,培養出模型對業務場景和需求的深刻理解。
當大模型走出實驗室,步入生產、生活中的複雜多模態、跨模態環境後,這種場景感知、業務感知讓「日日新」能更好地理解用戶意圖、更準確地執行用戶指令,真正將模型紙面能力變為生產力、交互能力。
從成本的維度來看,雖然原生融合大模型的能力更強,但其訓練成本依舊具有優勢。要打造一款兼具優秀語言和多模態能力的模型,原生融合訓練方式的成本僅為傳統訓練方式的60%。
結語:多模態原生融合,世界模型的必由之路
人類存在於真實世界之中,而AI若要真正給人類的生產、生活過程帶來變革,就必須建立起一套描述、理解、預測外部世界的模型,這也就是所謂的世界模型。
在當下大部分語言模型、多模態模型仍然處於分立的背景下,商湯的「日日新」融合大模型已實現多種模態的深度融合,而這或許也是通往世界模型的必經之路。