
【導讀】Meta員工在TeamBlind爆料,點燃了一把火。自詡開源先鋒的Meta,直接被DeepSeek這家中國公司整得無地自容。不僅工程師爭分奪秒復現模型,年薪超過DeepSeek訓練成本的高管們,心底也有點虛。
今天,Meta員工在匿名社區TeamBlind上的一個帖子,在業內被傳瘋了。
DeepSeek,真實地給了美國人億點點「震撼」。
DeepSeek R1是世界上首個與OpenAI o1比肩的AI模型,而且與o1不同, R1還是開源模型「Open Source Model」,比OpenAI還Open!
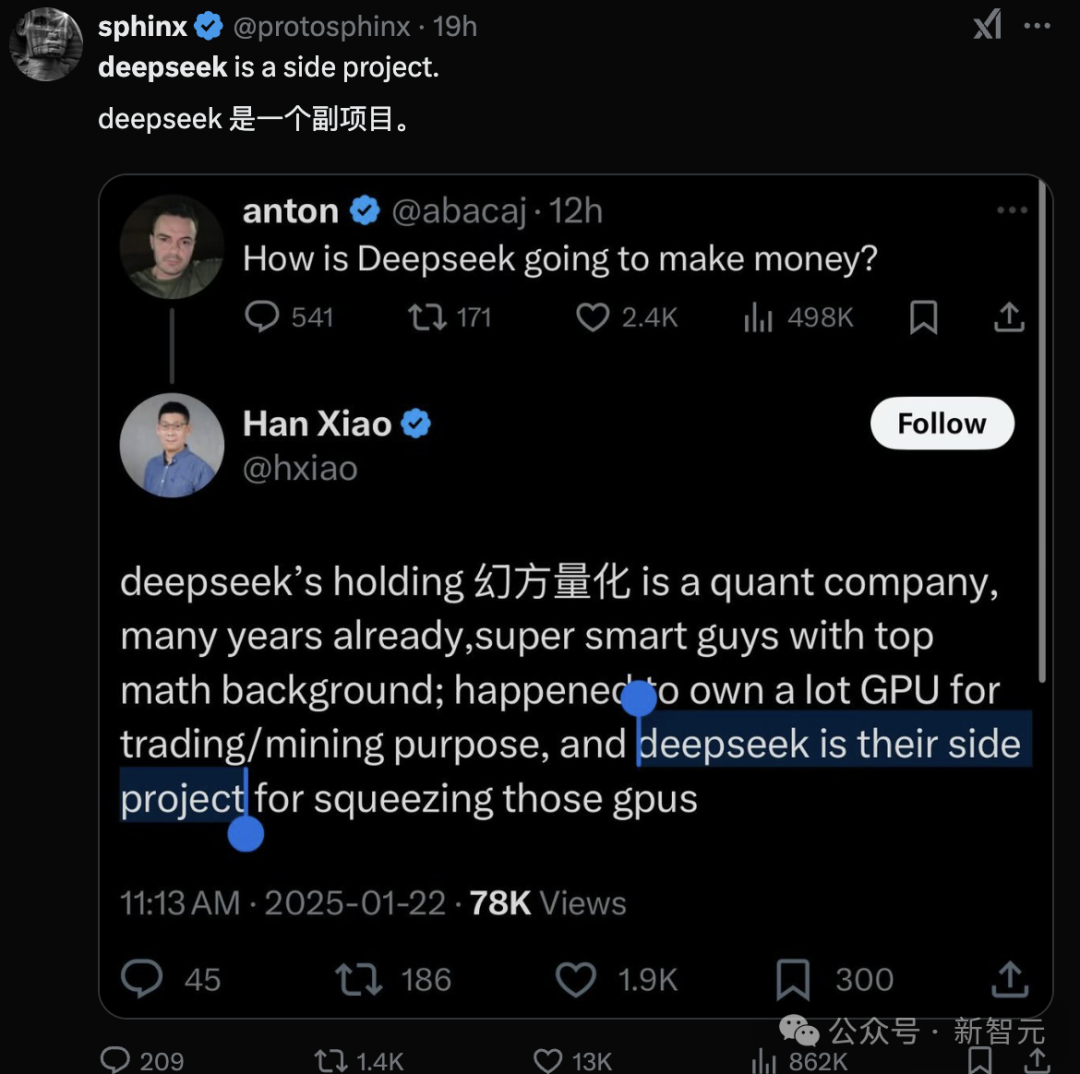
更有人曝料,DeepSeek還只是個「副項目」,主業根本不是搞大模型!
這不,OpenAI還沒慌呢,Meta先慌了!
畢竟Meta一直自詡開源先鋒,但DeepSeek這種程度的開源,直接把它們拍在沙灘上。
更可怕的是,DeepSeek的成本也太太太低了,這麼比起來,Meta拿着超高預算的團隊,就顯得很尷尬。
那些一個人拿的薪資,就超過整個DeepSeek V3訓練成本(僅550萬美元)的高管,尤其如坐鍼氈。

根據內部Meta內部人士爆料,DeepSeek去年的V3,已經給他們壓力了。
現在,Meta的工程師正在抓緊一切時間,爭分奪秒地分析DeepSeek,試圖複製其中一切可能的技術。
以前,是全世界追着美國的大模型拿着放大鏡研究,現在情況竟倒轉了過來,美國人也開始逆向工程了。今夕是何夕?
中國大模型的狂飆猛進,真的讓我們感到了魔幻現實主義的味道。
Meta工程師嚇瘋了
TeamBlind上的帖子,全文曝料如下:
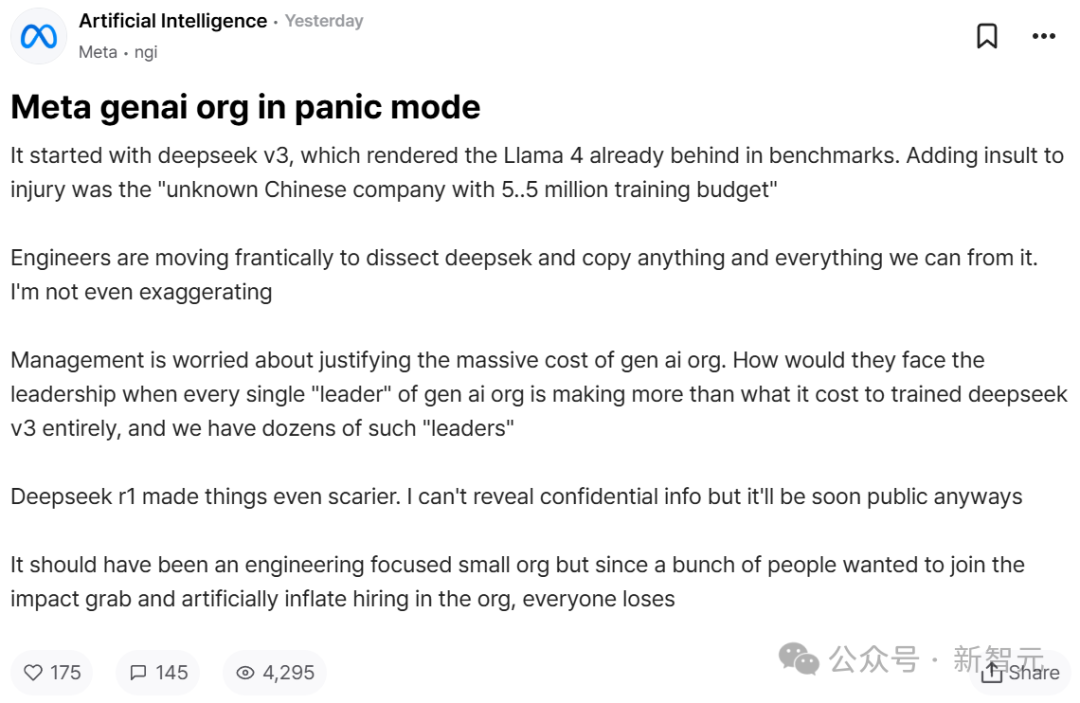
一切源於DeepSeek V3的出現,它在基準測試中已經讓Llama 4相形見絀。更讓人難堪的是,一家「僅用550萬美元訓練預算的中國公司」就做到了這一點。
工程師們正在爭分奪秒地分析DeepSeek,試圖複製其中的一切可能技術。這絕非誇張。
管理層正為如何證明GenAI研發部門的鉅額投入而發愁。當部門裏一個高管的薪資就超過訓練整個DeepSeek V3的成本,而且這樣的高管還有數十位,他們該如何向高層交代?
DeepSeek R1的出現讓情況更加嚴峻。具體細節屬於機密,不便透露,不過很快就會公開了。
這本該是一個以工程為導向的精簡部門,但因為太多人想要分一杯羹,人為膨脹招聘規模,最終導致人人都付出了代價。
在成本上,「一個高管 = DeepSeek V3」,這對給高管們開出天價年薪的硅谷大廠們,實在是啪啪打臉。

更是有網友被震驚到:「DeepSeek R1在OpenAI、Meta、Grok以及谷歌的屁股下點了一把火,就像Open AI在第一次推出ChatGPT時那樣震撼。如果去掉人力瓶頸,達到o1級性能真的不需要花太多錢!!」

有網友認為,在這次AI浪潮中,Meta的確落後了。
但也有網友為Meta解釋,畢竟Meta已經開始行動了,雖然在GenAI領域的確「人浮於事」。
甚至,這個來自中國的AI已經上了美國的新聞。措辭非常誇張——
「中國初創企業DeepSeek,威脅了美國AI的主導地位。」
「否認、憤怒、絕望、接受,美國人正在進行艱難的心理重建。這是他們歷史上從未見過的最強對手。」
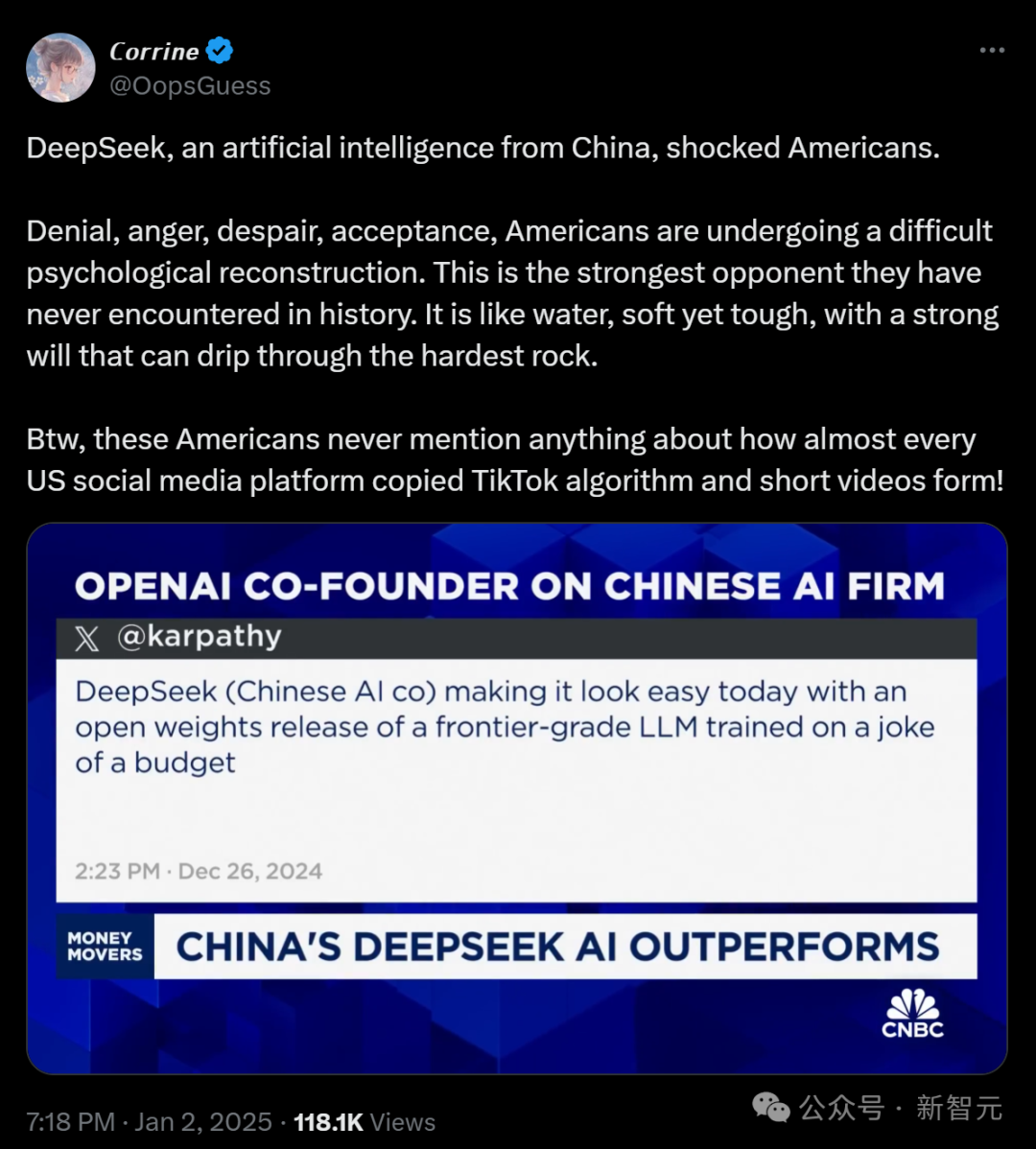
不到600萬美元的成本,就能訓出一個如此強的模型,這簡直是徹底扯掉了美國金融業的遮羞布。
AI產業,真的需要動輒數萬億美元的投資麼?
連帶着,特朗普和奧特曼搞的5000億美元星際之門,也一下子變得可疑了起來。
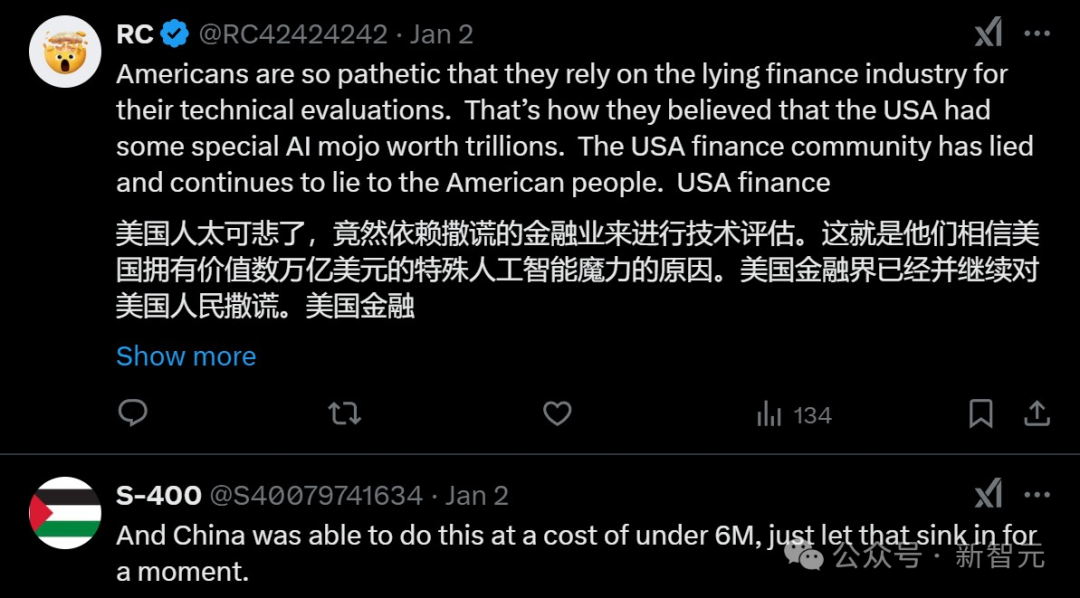
DeepSeek-R1有多強?
「花小錢辦大事」,可見DeepSeek團隊的確有「獨門祕籍」,在技術上恐怕也超越了OpenAI。
DeepSeek還發表了相關論文,介紹了DeepSeek-R1的大規模強化學習(RL)訓練、未經過監督微調(SFT)作為預處理步驟等技術細節。

論文鏈接:https://arxiV.org/pdf/2501.12948
這種「技術自信」,讓部分美國網友都開始了「反思」。

為何AI圈,如此懼怕DeepSeek?
來自VB最新一篇獨家文章,特意將AI界黑馬DeepSeek引發AI界轟動做了全面分析。

就在幾天前,只有最專業的極客們才聽說過DeepSeek。
它是一家成立於2015年幻方量化公司,背後投資者High-Flyer Capital Management。
直到過去幾天,這家公司迅速成為硅谷最受關注的顛覆者,這主要歸功於DeepSeek R1的誕生。
不用SFT,僅憑強化學習就讓模型推理性能堪比o1,而且在多項基準測試中,R1甚至超越了o1。
令人瞠目結舌的是,如此強大得模型,訓練成本僅500萬美金,使用的GPU數量也遠遠低於OpenAI。
不僅如此,他們直接將其開源,Hugging Face下載量和活躍度直接爆表。
而且,開發者可以自由微調訓練,API成本要比同等o1模型低90%還要多。
與OpenAI僅低性能模型上提供網頁搜索不同,DeepSeek直接將R1與搜索功能深度整合。
在一步一步策略中,這家中國公司完勝了OpenAI。
第一個,但不是最後一個
這也不會是最後一個,挑戰硅谷巨頭主導地位的中國AI模型。
最近,字節全新發布了「豆包1.5 Pro」,在第三方基準測試中,其性能與GPT-4o模型相當,但成本僅為後者的1/50。
中國模型的快速迭代,已經引起國際關注:
《經濟學人》雜誌啱啱發表了一篇關於DeepSeek成功以及其他中國企業的成功。

政治評論員Matt Bruenig的實際體驗,也更加印證了中國AI模型的實力。
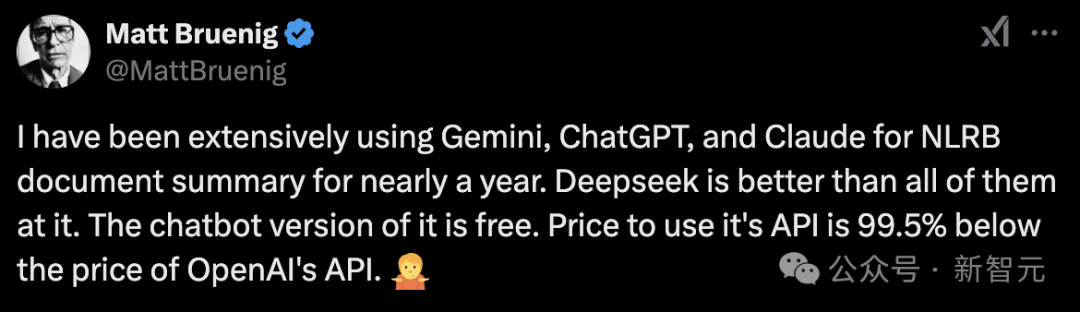
最後一句話總結:中國AI崛起了,美國還得適應。