1.23

智識學研社新年科學演講現場
編者按
過去幾年是AI發展突飛猛進的幾年,2024年,諾貝爾物理學獎和化學獎更是破天荒地頒給了AI領域的科學家。
然而,即使拿下了諾貝爾獎,我們也很難將這些年AI的進展單純歸結為科學上的勝利,它更像是一個工程上的奇蹟。當下業界甚至學界廣泛追隨和信仰的Scaling Laws,本質上仍是「大力出奇跡」:相信更多數據、更大算力、更大參數能給模型帶來更高的性能。
與此同時,AI系統內部的運作機制依然是一個巨大的黑箱,從神經網絡的表徵學習到決策邏輯的可解釋性,核心的科學問題仍未得到根本性解答。AI雖然對傳統科學貢獻良多,但它本身的科學原理卻仍在迷霧之中。
在智識學研社2025年新年科學演講上,香港大學計算與數據科學研究院院長馬毅教授提醒,在討論人工智能甚至通用智能(AGI)之前,我們首先要了解什麼是智能,智能背後的數學原理是什麼?過去十年,在機器智能這個領域,「術」的層面取得了長足的進步,但是「道」的層面還有很長的路。在現在這個時間節點上,科學變得非常重要。
以下為馬毅新年演講全文,全文共9301字。
● ● ●

毋庸置疑,這十年來人工智能技術突飛猛進,進展日新月異,甚至超出了很多人的想象。不光是學術界,還有產業,乃至政府、社會都變得非常關心這件事。技術發展很快,但是對智能的科學問題、數學問題,乃至後面的計算問題,並沒有界定得很清楚。
自古以來,中國的哲學中一直有「道」和「術」的概念。那麼在科技這個領域,術是工程技術,千變萬化;但是道,思想、科學理論的本質問題,大道至簡。過去十年,在機器智能這個領域,「術」的層面取得了長足的進步,但是「道」的層面恐怕還有很長的路要走。
今天大會的主題是‘AI for science’,我想在今天強調一個觀點,就是——可能「智能就是科學,科學就是智能」。
過去幾年,我們團隊一直在研究智能到底是什麼,智能的背後有沒有嚴格的數學問題,有沒有非常嚴謹的計算基理。這是我們想搞清楚的。

愛因斯坦說過一句話,這句話是在講science。Everything should be made as simple as possible,but not any simpler(凡事力求簡潔,但不能過於簡化)。意思是所有的事情都應該解釋得儘可能的簡單到不能再簡單。這個標準是什麼呢?要簡化,把世界的規律用最簡單的方式找到;但是不能再簡單,再簡單就解釋不了現象。這兩句話在我看來是科學的本質,也是智能的本質。
剛纔韓院士也提到,對於未來會怎麼樣,大家現在都很焦慮。一個古老的智慧是——欲知未來,先知過去。
01
從生物演化視角重新思考智能
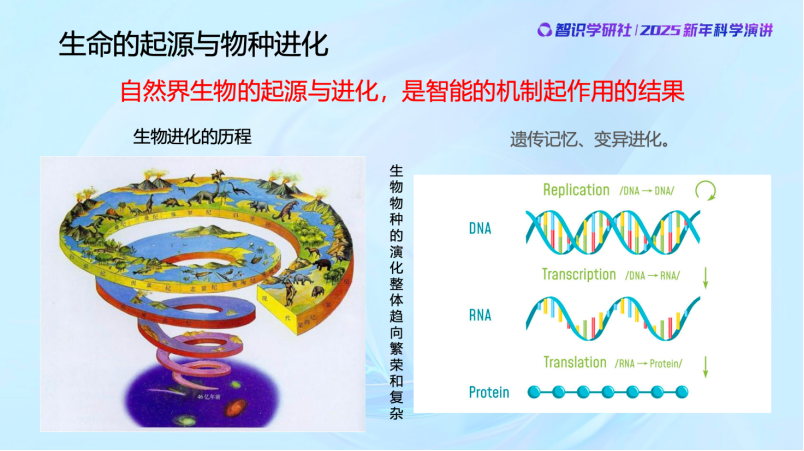
最近幾年,我和團隊做了一些跨學科的合作研究,我們的智能研究本身也越來越深入,這讓我強烈地感受到——自然界生物的起源與進化是就是智能機制起作用的結果,甚至可以認為——生命的本質就是其智能的演進。智能是生命的更底層的機制,而生命形式只是智能的載體。

可以看到,其實生命的起源與發展過程就是生物智能發生和發展的過程。最早的時候只有DNA,後來開始有了早期的生命。這些最早的生命個體基本上沒有學習和自我進化的能力,幾乎可以認為在個體層面沒有智能。但羣體有智能,羣體一步步通過遺傳變異和基因的優勝劣汰,代代相傳外部世界的知識,從而幫助適應與生存。這種過程現在有一個很流行的名字,就是生物羣體在做Reinforcement learning,不是不能進步,但代價很大。
帶着這個視角來看今天的大模型,你會發現大模型的進化與上述情況非常相似。現在的 「大模型」完全可以類比 DNA和早期生命階段,我們對它的內部機制並不完全了解,但試錯、競爭、優勝劣汰的過程和現象,如出一轍。早期無數生命快速誕生和消亡,現在的大模型則是百模大戰,一將功成萬骨枯——同樣,這個過程當然也能進步,但代價極大,資源消耗驚人。
到了差不多5億年前,生物的神經系統和眼睛的出現,讓生物個體獲取外部信息的能力激增,引發了寒武紀生命大爆發。大腦一定程度上取代了DNA的記憶作用,個體具有了智能。

生物的智能,從基因遺傳和自然選擇這種物種層面的智能,生物學上我們叫Phylogenetic,進化到個體具有後天學習與適應的智能Ontogenetic,這是智能機制上非常大的跳躍。
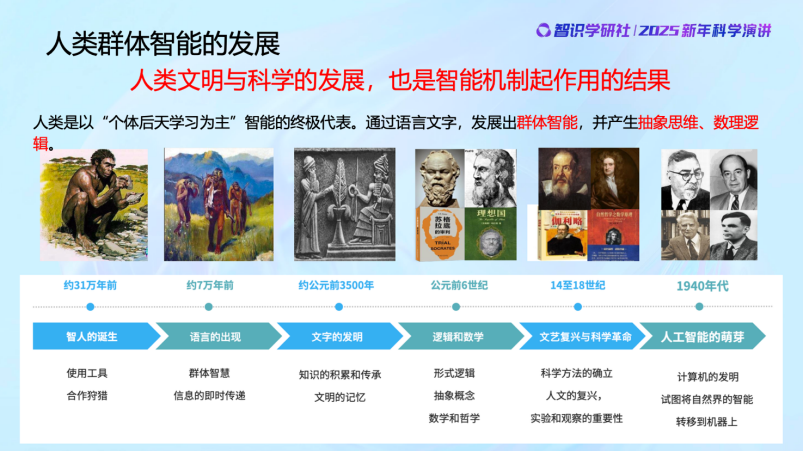
後來人類誕生,相比於此前的生物,人類的大腦高度發達,個體智能得到了極大提高,同時人類羣居行為和信息交流又進一步提升了人類的羣體智能。不但是人類的個體在學習,而且學習的東西還通過文字和語言在交流並得以在羣體中傳承,語言文字又取代了DNA的另一部分作用,能夠把知識記憶並傳下去。
然後到了幾千年前,數學與科學的出現又一次大大推動了智能的發展。人類學會了抽象的能力,超越了之前單純從經驗的數據裏尋找規律。這期間到底發生了什麼?到目前為止大家並不是很清楚,但是我們知道,作用機制從本質上和生物智能的早期機制是非常不一樣的。我們做學問一定要把歷史搞清楚。
02
智能研究歷史:
起源、寒冬與大爆發

那麼真正開始對智能進行研究,這件事情的起源在哪裏?今天一提到智能,大家都說是起源於 1956年(達特茅斯會議定義的)的「AI」,這顯然是不正確的。人類對智能機制的深入研究至少可以追溯到上世紀40年代。當時,以諾伯特·維納為代表的一大批傑出科學家,開始探索機器模擬動物和人類智能的可能性。
他們研究了哪些問題呢?比如研究「一個系統怎麼從外部世界學習有用的信息,這些信息怎麼組織管理、度量」,他的學生香農創立了信息論;維納本人研究「動物是如何學習的,反饋、糾錯」,這是控制論和系統論;然後是「怎樣通過跟外部環境或者對手博弈,不斷地提高決策質量」,這是馮·諾伊曼的對策論和博弈論。維納的思想還直接影響並催生了40年代初沃倫·麥卡洛克和沃爾特·皮茨提出人工神經網絡首個數學模型。包括圖靈研究計算(computing)如何通過機器實現,他提出圖靈測試本質上也是相信人和機器之間的計算機制應該存在着統一性。我們看到,維納的《控制論》英文名就叫Cybernetics: on Control and Communication in the Animal and the Machine。這些科學家就是想知道動物感知和預測外部世界的能力,以及這種系統的本質和機理到底是什麼。對這些科學家來說,他們都堅信——智能背後的數學機制是統一的。一旦找到了並實現了這些機制,動物與機器之間的界限將變得模糊——我們可以將其稱為「諾伯特·維納測試」。
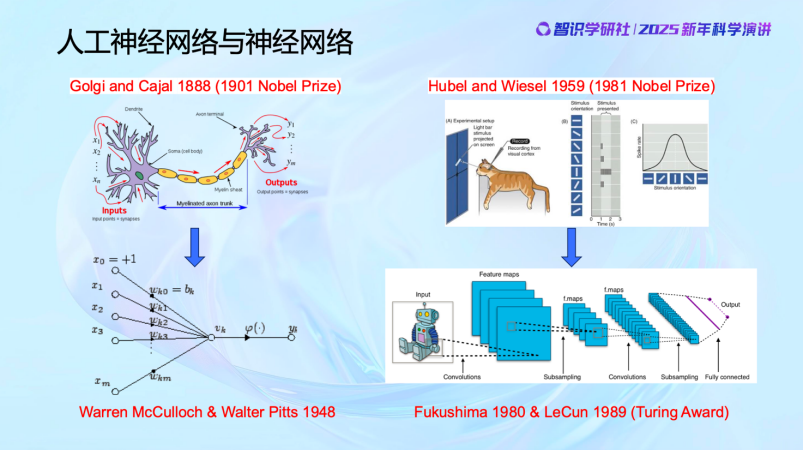
人工神經網絡的誕生與發展本身,同樣是人類從生物學和神經科學研究中獲得靈感的結果。既然動物是一種智能存在性的證明,那麼我們就可以去研究神經的工作原理。這促使了神經元的數學模型的誕生,即人工神經元。有了數學模型之後,當時大家比較急,或者說對智能的後續發展開始變得過分樂觀,覺得既然掌握了神經元的數學模型,那就可以去構建神經網絡,製造感知機,並且去訓練它。大家如果去看50年代的《紐約時報》對感知機的報道會發現,我們現在在人工智能上吹的牛當時已經吹過了,比如機器能夠自主學習和思考,人類將不再需要勞動等等,這都是50年代神經網絡模型出現後的社會討論。但是後來發現其實不行,不work。
直到80年代,人們才意識到可能還有一些關鍵因素沒有被充分理解,所以又重新開始研究大腦的工作原理,從而誕生了卷積神經網絡,這也是1989年的圖靈獎。
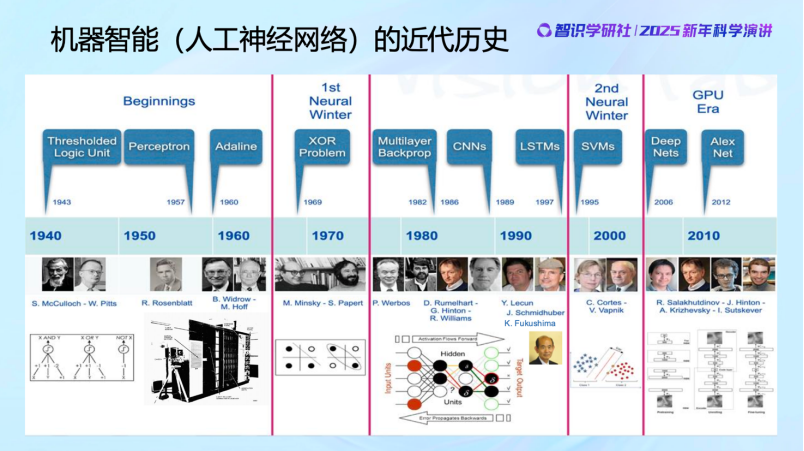
大家可以看到,40 年代之後,有了人工神經元的模型後,開始建立了系統和網絡,有了神經網絡的概念。在過去大概 80 年的時間裏,神經網絡幾起幾落,這是一個基本的發展歷史。最早由於 practice比較粗糙,效果並不是很好,當然理論上也發現了神經網絡有它的侷限性,讓大家在70年代對神經網絡的能力產生了一些質疑,導致在70 年代進入了一個寒冬。但是在 80、90 年代還是有不少人仍在堅持,比如Hinton、LeCun 等等,而且在設計越來越好的算法,去訓練神經網絡,包括 Backpropagation 等。到 2000 年,神經網絡又進入第二個寒冬,原因主要是在做分類的問題上,出現了一個支持向量機的工作,由於它的數學理論比較嚴謹、算法比較高效,所以對神經網絡也帶來一些衝擊。一直到2010年以後,神經網絡隨着數據以及算力的加持,它的性能得到逐漸的提高,才帶來了這些年的蓬勃發展。
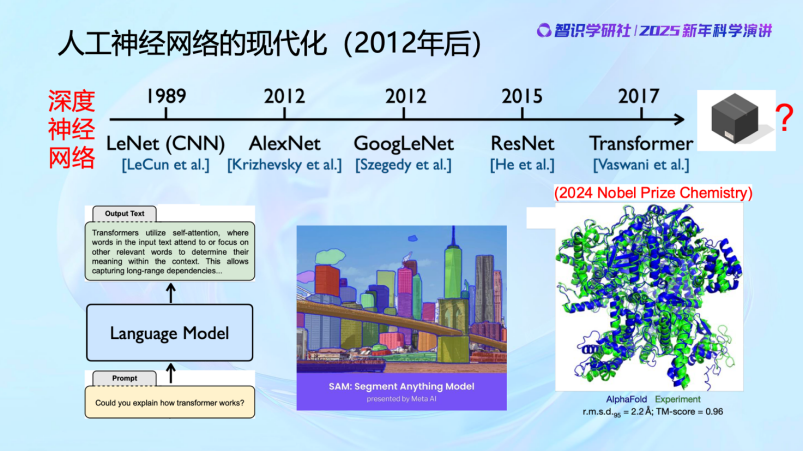
最近這十幾年,憑藉算力和數據的支持,人工神經網絡的應用開始迎來飛躍,直到今天。特別是在文本、圖像和科學領域尤為突出。比如說 在Transformer 下,不管是文本、圖像,甚至在各方面的科學數據上都取得了非常顯著的成效。所以其實近年來AI的成果,實際上是多年前的理念在技術層面的實現。
03
從黑盒到白盒

現代深度神經網絡一直是黑盒子。因為基於這些深度網絡的人工智能系統都是基於經驗或者試錯的方式設計出來的。當然,這個黑盒子的確取得了很多非常突出的成果。所以不少人會認為深度網絡作為「黑盒子」,只要能用、好用就足夠了。從工程角度看,這或許沒問題,但從科學角度來看,我覺得這難以接受。更何況歷史上,但凡影響力巨大的事物,一旦它還是一個「黑盒子」,就極有可能被人利用。
以天文為例,歷史上,在天體物理、牛頓力學誕生之前,迷信與巫師活動盛行。一些人會利用民衆對天文現象的無知製造恐懼,從而達到自己的目的。而科學家的重要的價值和責任之一就是要破除這種現象。從這個角度出發,我們必須要搞清楚,智能究竟是什麼,這些深度網絡究竟在做什麼、能做什麼。
我們需要研究怎麼把智能定義為一個科學問題,明確其科學問題的核心,探究它的數學本質,以及確定正確的計算方法——這些議題現在必須被提上日程。
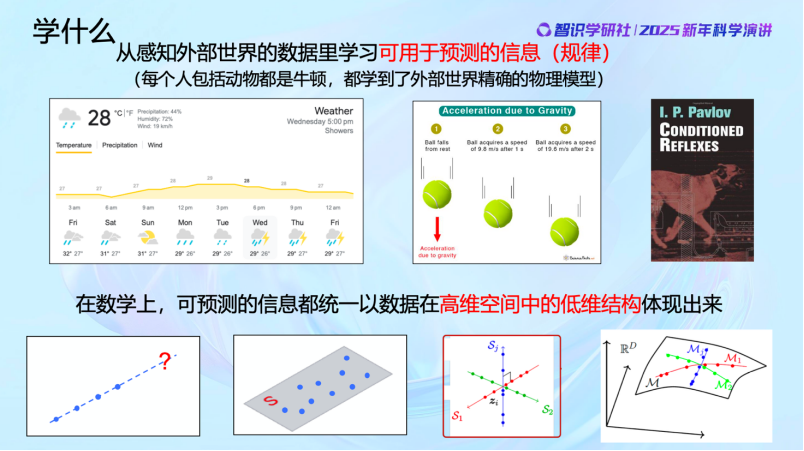
今天的主題是「AI for science」。科學到底是什麼,能做什麼?某種程度上講,科學就是感知到並學習外部世界,然後獲取可預測的信息和規律。
這裏有很多例子,比如氣象學,正是因為世界並不是完全隨機的,有一些是可以找到內在規律的,我們才能預測天氣。物理規律的發現同樣是如此。比如一個球的下落,我們知道它是遵循物理定律的。但其實,從智能的角度,我們在座的每個人甚至是阿貓阿狗都是「牛頓」。因為人和貓狗這樣的動物其實都對外部世界建立了極為精準的物理模型。比如當玩的球下落的時候,貓和狗能夠迅速且精準地接住,甚至比人還準。它們不需要懂牛頓定律,卻能不斷學習,並用學到的東西對外部物理世界做出精準預判。學習到的是什麼呢?是外部世界的數據的分佈規律。
那能不能從數學角度把這些規律統一起來呢?其實是可以的。牛頓定律和動物學到的物體運動的規律差別僅在於表達的方式不同,語言不同,但在數學上其實是具有一致的表現形式的。比如說一個物體在不受外力影響的情況下,會在一條直線上運動,我們很容易判斷它在下 一 秒出現在哪裏,它不會隨機出現在其它的地方。當然還有更復雜的可預測的問題,它可能不是一條直線,很可能是一個平面,或者是多條直線,甚至多個平面、多個曲面等等,數據裏面很多的信息就是通過這種結構體現出來的。
我們學習就是要從這些觀測到的高維空間中的數據裏面學到低維的數學結構和特徵,學到以後還要把它組織好、表示好,這也是現在AI領域的前沿課題。

學習到低維結構有哪些好處呢?低維結構具有很多很好的性質,比如completion(補全)、denoising(去噪)和error correction(糾錯)。
首先,completion補全。數據分佈在一條線上,部分缺失,AI能夠填補這些空白,就像GPT做填空題一樣。事實上Transformer就在做這件事,nothing else。

第二是denoising,去噪。當我們識別出數據中的噪聲並找到規律後,就能清除噪聲,就像我們的大腦會自動清晰化模糊的圖像。這就是Diffusion model在做的事,大家現在經常看到的以及用到的用AI生成聲音、圖像的功能和應用,本質上就是在做這個,nothing else。
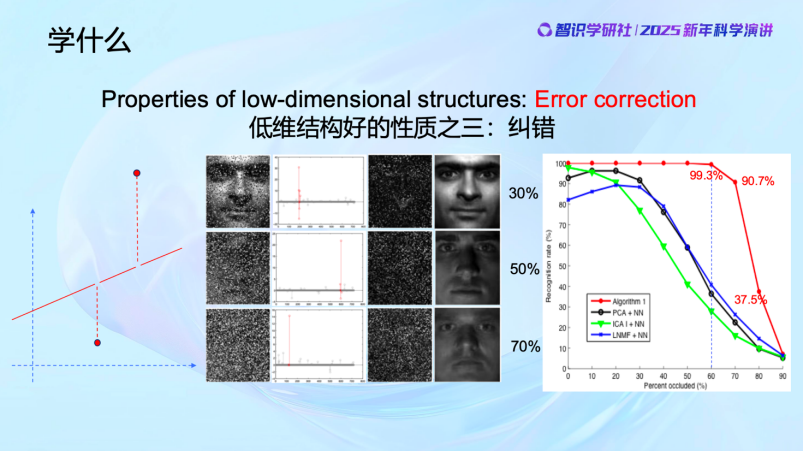
低維結構第三個特別好的性質是Error correction,糾錯。當發現數據與已知規律不符的時候,比如物體被遮擋,AI能夠像像大腦一樣填補缺失部分,甚至損毀了的內容都可以恢復,現在機器做出來的效果可以非常好,遠遠超過很多人的想象。
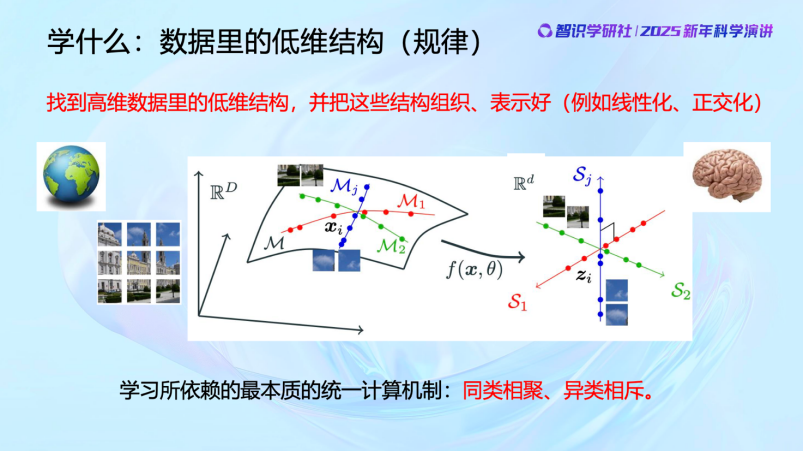
所以我們學習的統一的數學問題,就是從高維世界中學習數據的低維分佈,然後把它組織好並結構化。前面講到,人和動物的大腦天然就在做這個事情,找到相關性和規律。我們現在通過數學方法讓機器來做同樣的事情——去發現數據間的相關性和規律。
數據分佈在很高維空間中,一張圖像可能包含一百萬或一千萬像素,但其結構可能只有幾維,甚至非常線性。宇宙廣袤,千變萬化,但研究弦理論的數學家和物理學家可能會說,從宇宙大爆炸到今天的所有觀測到的物理現象,用一個9維或11維的模型就足夠描述了,極為簡潔。內在的道理是一樣的,規律本身簡單,而表象千變萬化。
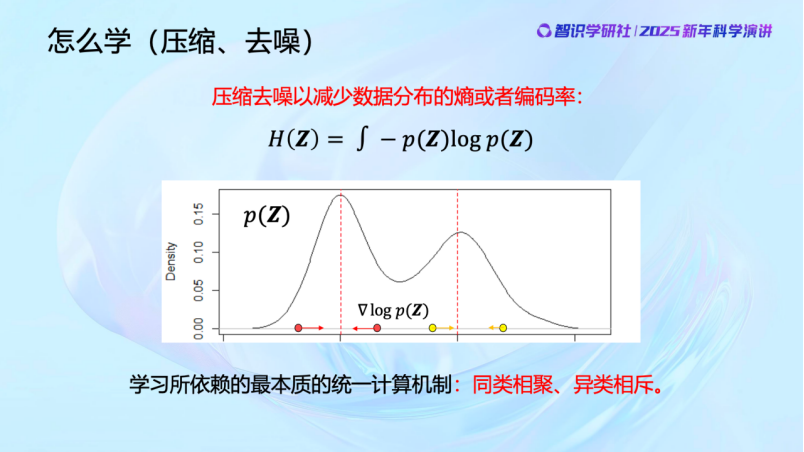
剛纔談的是「學什麼」的問題,我們要去找低維結構。那麼該怎麼找,怎麼學呢?
首先是去解決觀測數據中的噪聲問題。比如我們觀察的世界空間是一維的,那麼它更低維的規律就應該在零維上。我們看這張圖,偏離紅線以外的觀測就應該是噪聲,我們可以通過數據壓縮,把這兩條紅線外的區域往裏擠壓來去噪。而衡量這些數據分佈的不確定性的指標就是熵。當我們在去除噪聲,朝低維結構壓縮的時候熵在減少,這是信息論描述的事情。通過這樣的過程,相似的東西會自然聚集,而不相似的則應該被分開。
過去十年間,神經網絡不管是感知、分類還是生成,所做的事情都可以通過這張圖來解釋,今天大家所見的所有AI的現象,它最基本的原理都在這張圖上,包括執行方式和優化算子。這裏面的數學機理即使是本科生也能理解。
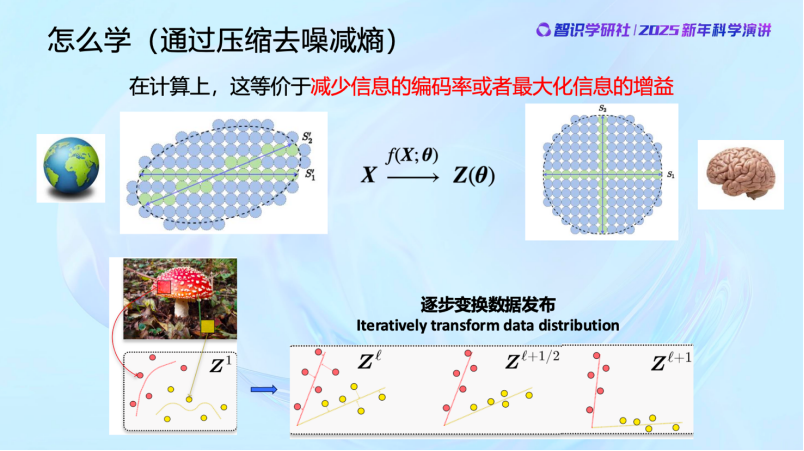
好,剛纔說的是從一維到零維的情況。當數據維度更高的時候,情況會稍微複雜一些,但道理是一樣的。
當我們對這個世界還什麼都不知道的時候,什麼事情都可以發生,你可以想像整個未知世界一開始可能是整個藍色球覆蓋的區域。但因為我們的世界不是隨機的,它是有規律可預測的,可能發生的事情就是這些綠色的球所表示的區域。如果我找到這些綠色的區域,其實就是對這個世界認知的信息有所增加,這就是信息增益。從信息表達的角度,我就用不着去把每個球都記下來,我只需要記住這些綠色的球,對這些球進行編號,球的編碼量就會減少。所以你會看到,對世界的認知的信息在增加,實際上是一種編碼量減少的過程,這其實就是壓縮的概念。因為這個世界是可預測的,發生的事件存在的分佈就是可以被壓縮的。這是第一點。香農的信息論其實就是告訴我們怎麼用類似編碼的方式把信息記錄下來。當然,現在有了一個更時髦的詞,叫Tokenization.
第二,當我找到這些綠色球所在的地方之後,我還需要在大腦裏面把它們組織好。可能一開始我們的腦子還區分不了蘋果和桃子,比如說這兩條線,一個代表蘋果,一個代表桃子,我要把蘋果和桃子在我的大腦裏面最大限度的分開。相關的變成獨立的,不正交的變成正交的。實際上現在Transformer就是在做這樣的事,它就是將圖像打為Tokens並組織好。
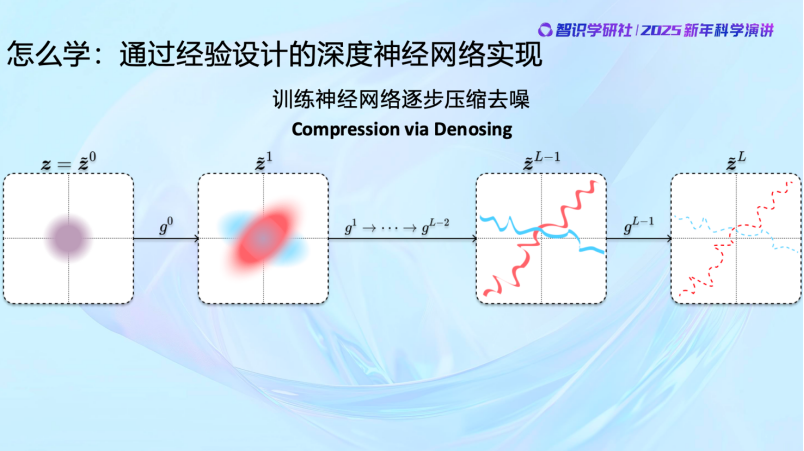
包括現在,我們看到Diffusion Model ,一樣的,當我們知道怎麼做了以後,就是從一個隨機的過程逐漸壓縮去噪,最後找到自然圖像的分佈。而且目前Diffusion Model還有一些缺陷,沒有完全組織好。所以完全可控的生成還沒有完全實現。
現在大家看到的Stability AI, Midjourney等等其實也都是在做這件事。
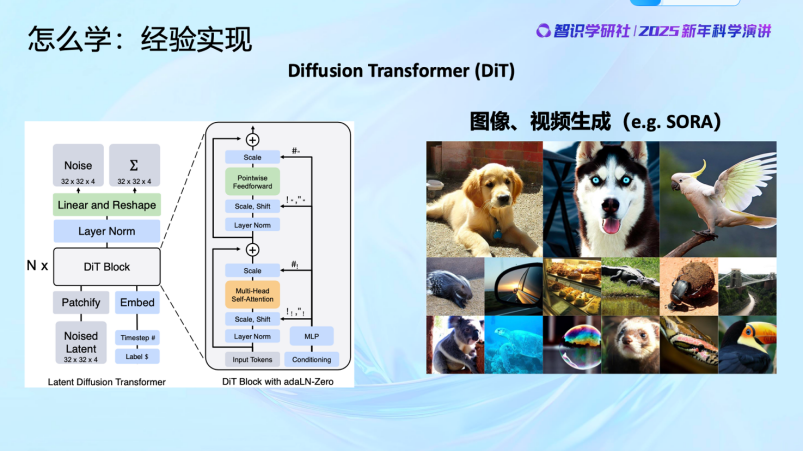
今天的AI技術像Diffusion Transformer,用到圖像、視頻上,像Sora,本質上都在做這件事。原理上其實是一樣的。
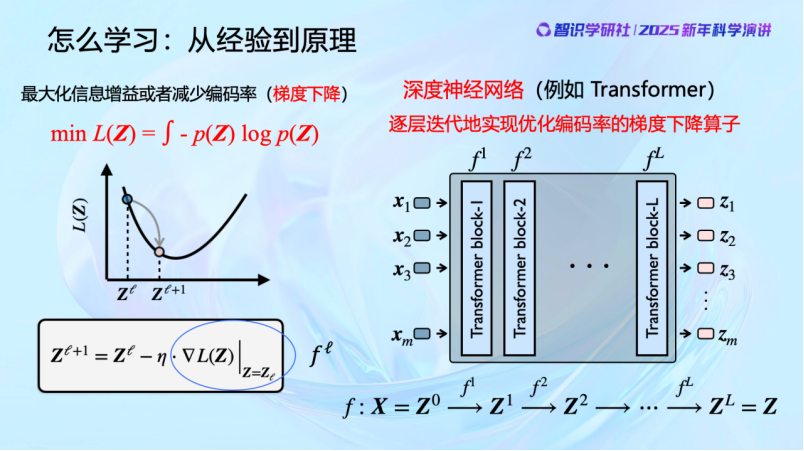
現在知道了學習的目的,那麼具體要怎麼去實現它呢?
壓縮去噪要優化的目標是一個很複雜的函數,目標很複雜。我們找不到全局最優解。但至少可以局部地去優化它。通過對輸入的數據的分佈稍微重組織一下,使其熵略微減少,一層一層地進行。自然界也不會一次做到位,但自然界知道可以在原有的基礎上一步步變化。那我們也可以一步步優化,使得每次數據被處理後都更好一點,熵都減少一點,一層一層,一次一次地來做。神經網絡每一層都在做這種整理,讓使輸出數據比輸入更好。所以其實從這裏,一目瞭然,神經網絡就是在做壓縮、去噪,以找到數據的低維分佈並把它組織好。
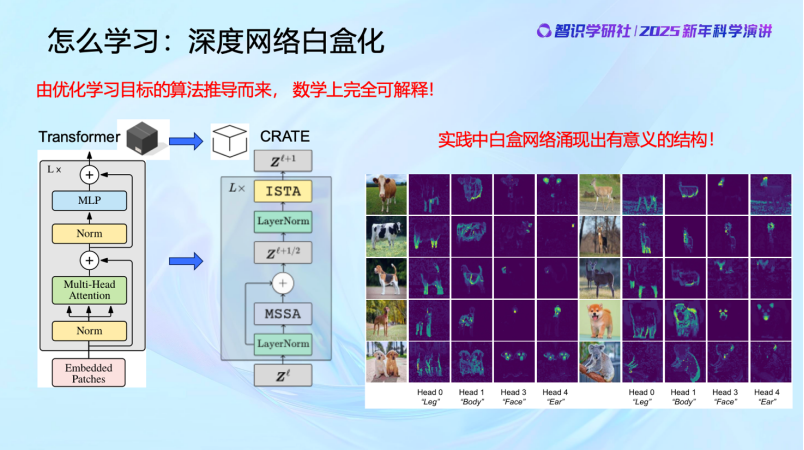
知道了這些,我們就可以通過數學推導,設計這些網絡每一層的算子並優化明確的目標函數。大家可以看到,這些數學推導只需要本科生的數學知識,主要就是求導以及做梯度下降。然後大家會發現,對這樣的算子的一些簡單的實現就有類似Transformer的結構出現。並且這樣的網絡學到的結構更加簡潔,更加具有統計和幾何意義。它就是在對數據做聚類和分類。
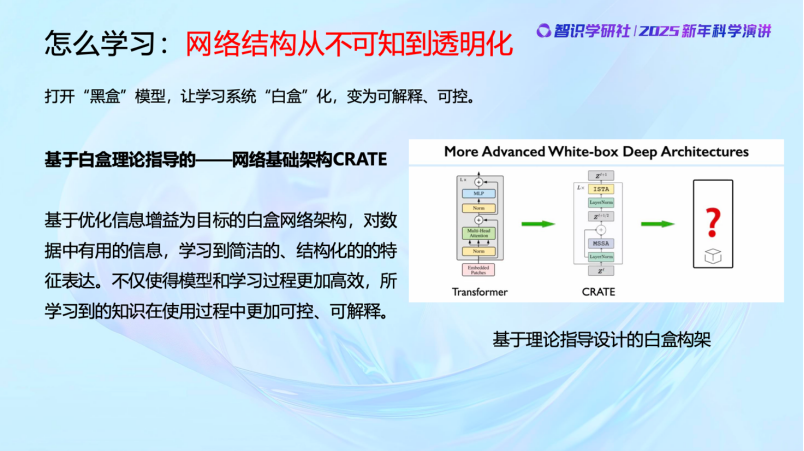
當我們了解神經網絡要實現的目標後,就可以完全理解它其實是實現這個目標的手段而已(means to the end)。那麼我們就可以清晰、可控地設計每一層的結構,每一層要實現什麼算子,作用是什麼,算子、參數在做什麼,都可以看得很清楚,而且數學上完全是可解釋和可控的, 不需要人去猜測、調整。
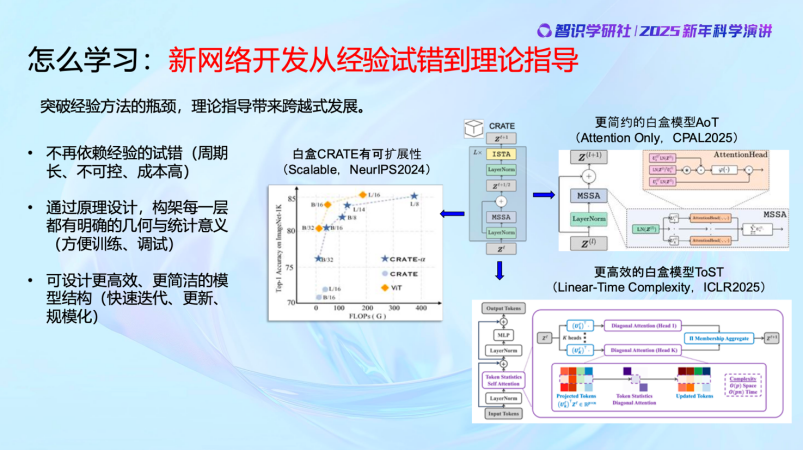
前面講的是早期的最基本的白盒模型。最近這兩年的時間,我們的工作又有了令人振奮的進展。首先,白盒的結構完全可以擴展,處理的圖像規模完全可以擴展到幾十億,甚至上百億。而且,白盒也正在變得更加簡約,過去的很多通過經驗設計的冗餘的地方,全部可以不需要。甚至我們還讓它變得更加高效,我們優化了Transformer,每一層算子的計算複雜度從二次複雜度降到了線性複雜度,而且全部是通過數學推出來的,不是猜出來或者試出來的。清清楚楚,更高效,而且去除了冗餘的、經驗設計中不必要的部分。
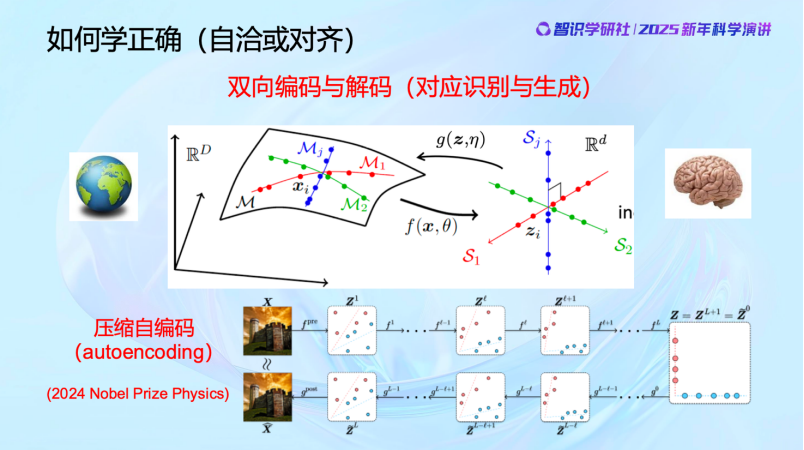
前面是學習,從外部世界學到數據分佈,並且組織好。
但怎麼判斷做對了沒有呢?數據夠不夠學習完整的分佈,有沒有漏掉的地方?怎麼去驗證這個模型壓縮去噪以後是對的,而且夠了呢?只有一個辦法——回去用,把它decode 回去。
啱啱過去的2024年,Hinton獲得了諾貝爾物理學獎。獲獎的這個工作是他在80年代做出的,其實就是在做這件事,從物理學得到啓發,把autoencoding做好。當然,今天看來這個方法不見得就完全正確,但這個問題是很對的。

我們是怎麼解決這個問題的,又做到了什麼樣的效果呢?可以看到,用白盒的方法,所有算子都是數學方法搭建出來,完全可以做到和通過經驗設計的網絡一模一樣的效果,甚至可以更好。
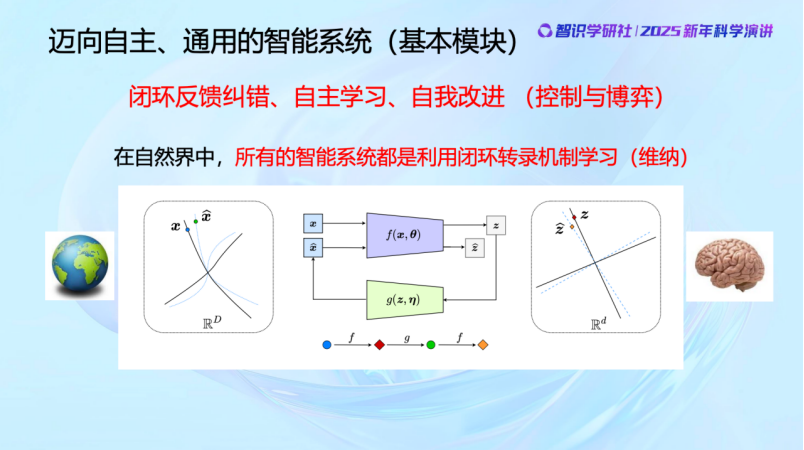
那僅僅依靠編碼(encoding)和解碼(decoding)就夠了嗎?
2022年,Hinton發表了一篇文章,叫Forward-Forward Algorithm (編者注:在NeurIPS 2022 上,Hinton 介紹了他的最新工作「 Forward-Forward Algorithm 」即FFA,這是一種新的人工神經網絡學習算法,靈感來自於人類對大腦神經激活的了解。他認為forward-forward 有可能在未來取代 backprop。該論文還提出了一種新的更接近大腦的節能機制的計算模型,並可以支持forward-forward算法)。其實我們早就知道,自然界沒有BP這個option(選項),沒辦法像程序員那樣可以看左邊不夠補一下左邊,看右邊不夠又補一下右邊,數據不夠又去量一量再給系統補下數據。人也好,貓狗也好,我們的大腦是不直接在外部物理世界度量對錯的,我們做不到這一點,我們所有的學習都是在大腦內部進行的。
比如說,我看到現場有很多圓形的設備和裝飾,但大家怎麼確定它的形狀就一定是圓的呢?你是用尺子圓規一個個去測過的嗎?不是的吧。那你怎麼知道的呢?從小到大,我們並沒有逐一測量過這些東西,但我們還是能夠分辨物體的形狀、種類、判斷速度並且採取行動。動物也是一樣的,當一隻山羊看到老虎向它衝過來時,它不可能說老虎你等一下,我來測測你的距離和奔跑速度,不會的。如果真有過這樣做的生物,也早就被自然選擇淘汰掉了。動物的學習全部是自主(Autonomous)的學習。
其實這就是諾伯特·維納80年前就提出並且探討的問題。維納本科學的是動物學,所以他很早的時候就在思考——動物是怎麼學習這些的呢?動物的方法是,我要讓我的記憶能夠恢復我觀察到的物理世界,並對它進行預測。動物沒法把自己大腦中的世界和真實的物理世界直接比較,來看到底對還是不對。
那它們是怎麼做的呢?答案是閉環。就是不用在真實世界中去比,而是把你假想的和你感知到的進行比較,這就是閉環做的事情。所有的自然界的生物,全部都是閉環學習。
為什麼現在有些人主張進行端到端的模型訓練呢?那估計他們想賣更多的數據或者芯片給你吧。端到端的方式當然可以訓練,但代價很大,成本很高。而像螞蟻和其他小動物,都能高效、自主地學習,不需要大量的數據和算力,因為它們的學習從機制上就是不一樣的。

預訓練存在一個顯著問題:容易出現災難性遺忘。大家也可以看到,預訓練模型從1.0到2.0再到3.0,每次都需要重新訓練。但是我們看我們自己,你的大腦有每次都重新訓練的1.0、2.0、3.0的版本嗎?沒有的。你每天都在持續學習,而且你長大了學了新東西以後,你小時候學的是不會忘的,你還是知道加減乘除怎麼算,對不對?閉環系統是不會忘的。這是最近我們與Yann LeCun(楊立昆)團隊合作的一些工作。

我們看近年來生物學和計算機科學的跨學科研究。證明了生物的智能就是具備這樣的特徵,它們就是這樣來組織它們的記憶,而且組織得非常精妙。這是對猴子大腦的研究,可以看到它把記憶組織得非常好,組織成正交子空間,而且是稀疏表達,predict control,通過閉環、反饋控制進行糾錯與學習。這些機制在自然界的生物中是普遍存在的。
04
我們離通用智能還有多遠?
最後總結一下。
這幾年,越來越多的人開始講「通用智能」,我們的目標好像很明確,也很一致。但,到底要怎麼實現呢?計算機科學之所以叫計算機科學,這件事的本質就是和計算問題高度相關的。
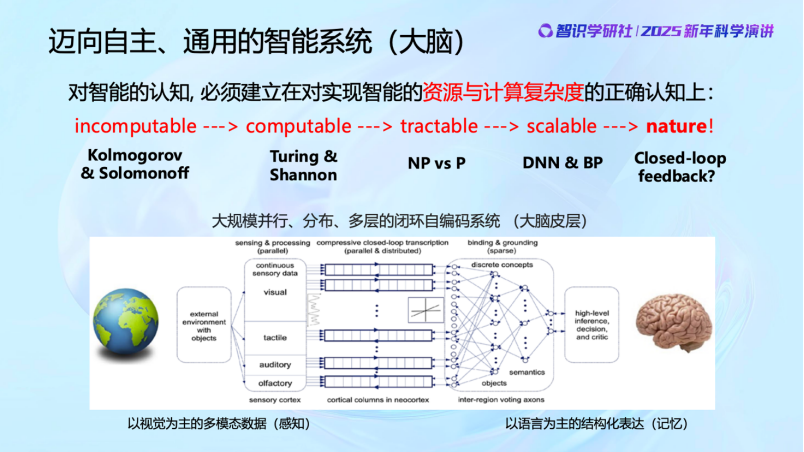
過去80年,人類對的計算的理解一直在演進。從incomputable(不可算)到computable(理論上可算)到tractable(可以通過計算機計算)到scalable(可擴展的計算),一步一步。現在許多人認為智能就是在做壓縮,這是完全錯誤的,因為這件事情它甚至有可能是不可計算的。當然圖靈後來定義了可算與不可算。而即使被證明是可計算的,也未必能計算。NP-hard的問題傳統計算機算不了。現在DNN(深度神經網絡)和BP(反向傳播)之所以流行,是因為它們計算複雜度相對較低。但即便如此,自然界也沒有同樣的資源用類似BP這樣的機制來算。我們看現在的大模型,動輒百億、千億的參數,能源消耗動不動就要多少個兆瓦。而我們人類大腦的能耗只有十幾二十瓦,這中間還差了很多個數量級。自然界不可能這樣去浪費算力和資源。
自然界的計算機制到底是怎麼樣的?其實現在科學界還在不斷的探索研究中,現在還並不完全清楚。但已經知道的是——大腦絕對不僅僅是一個大模型,而是由數十萬個並行單元組成的,甚至是以多模態的分佈式的處理方式來實現的。這和當前流行的把所有內容砸在一個模型中的做法是完全不同的。我們還有很多需要向自然界學習的地方,也希望在探索智這個問題上,面對自然界的時候,大家能夠謙虛一點。
今天的大會主題是「AI for science」,我覺得其實還有另外半句,就是 「Science also for AI」。關於智能的科學機制,我們知道的還太少,還有很長的路要走。
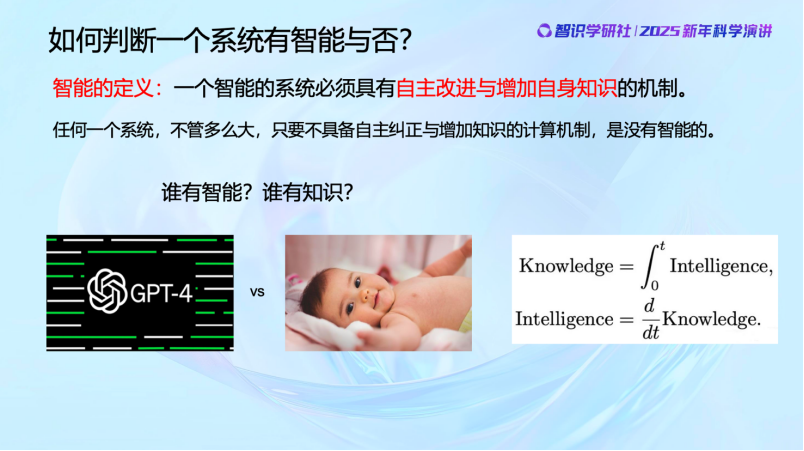
我們看到,今天好像所有人都在談論智能,但其實對智能一直沒有一個明確的科學的定義。這裏我們提出一個對智能的定義——真正的智能系統必須具有自主改進和增加自身知識的機制。
任何一個系統,不管它能力多強,儲存的知識數據有多龐大,只要不具備自主糾正或增加知識的計算機制,它就是沒有智能的。我們經常舉的一個例子是 ChatGPT 和一個嬰兒,誰更有智能、誰更有知識?顯然,GPT雖然擁有大量知識,但按這個標準,它是不具備智能的。一個嬰兒雖然知識不多,但通過不斷思考與學習,最終可能成為下一個愛因斯坦。某種意義上說,我們認為智能是能夠增加知識的,是知識的微分,知識是通過智能活動所積累起來的,它是智能的積分。

我也建議大家,尤其是年輕的研究者和從業人士多深入研究歷史。當我們真正理解了人工智能的整個發展歷史以後,會發現過去10年所做的事情與50年代定義的「人工智能」其實不是一個東西。當時參加達特茅斯會議的年輕人,其實是想避開維納和馮·諾依曼等等當時在學術界有着巨大聲望的前輩,要在學界證明自己。他們想做和動物層面的感知、預測不一樣的智能,研究屬於人的獨特的智能。50年代圖靈提出圖靈測試也是。他們想研究人類如何解決符號、抽象問題,這纔是當年「人工智能」program 原本想做的事情。
回過頭來再看過去十年的智能發展做的事情,我們把它們跟40年代研究的「動物的智能」和50年代提出的「人的智能」要做的事情列出來對比,你可以做下判斷,到底離誰更近,離誰更遠。
可以說,過去十年做的事,主要還是屬於 「Cybernetics」的範疇,而且還沒有做全,距離50年代追求的那個「Artificial Intelligence」其實還非常遙遠。
05
多一點思想
少一點技術
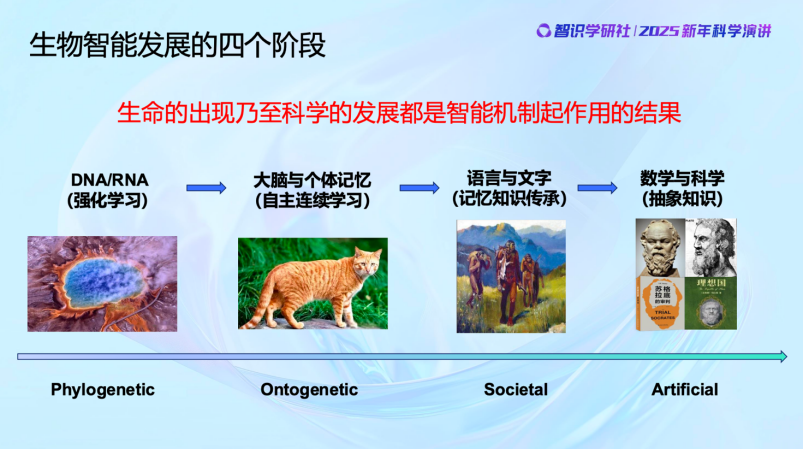
智能不是一個籠統的概念,我們現在必須把它變成一個科學的概念。可以看到,生物智能的發展是有層次的,它們高度相關,但是每一次躍升都會有新的不一樣的東西出現。最早的時候是羣體的智能,生物羣體通過強化學習來實現羣體的智能的增長;然後個體智能得到了提升,動物個體能夠自適應、反饋閉環、糾錯,連續地來進行學習;然後人類誕生了,人類羣體中形成了語言,能夠交流,能夠共同學習,大大提高了人類羣體獲取外部世界知識的效率,然後文字誕生以後還能把知識再傳承下去,從羣體智能層面很大程度上取代了DNA的一部分作用;然後,可能是在幾千年前也可能更早,我們人類的大腦開始出現新的變化,產生了抽象思維,發展了自然數等概念,產生了數學和科學。這是整個智能的發展過程。
回過頭來看,過去幾年這麼多大模型,是不是真的有數字能力呢?每次新的大模型出來我的學生都會測這個模型有沒有數的概念,結果都是沒有,包括GPT4o出來以後,還是3.11大於3.9。當然現在他們通過工程師改過來了,但是你換個方式問,3.11還是大於3.9。大家在接受一個新的信息的時候一定要提高警惕,有沒有自己做過試驗去驗證,最後得到第一手的的可信的知識,如果沒有,小心一點。
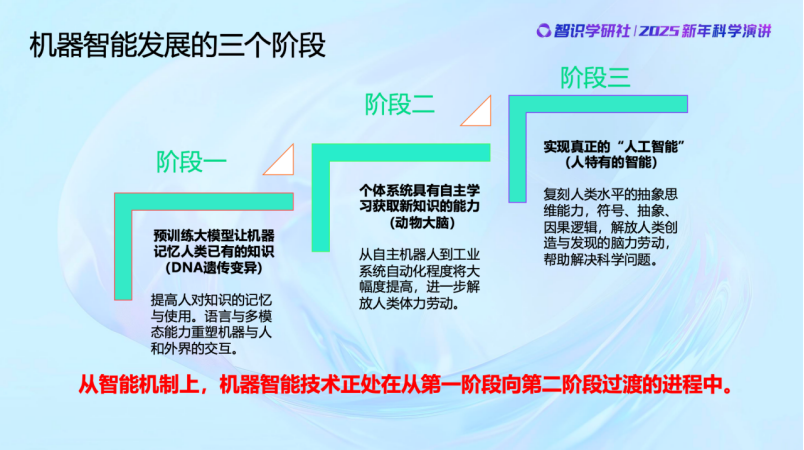
關於機器智能的發展,我個人認為可以分成幾個階段。第一個階段,預訓練大模型,就是模仿DNA,一代一代不同的結構和知識傳承下去,百模大戰,不好的被淘汰,就是這樣,而且進化的機制和方法都很像。第二個階段,機器智能真正出現個體記憶,自主學習。個體的「大腦」能夠有感知,能夠自適應,在大模型之外獲取新的知識,而且不斷改進。目前的機器智能還處於從階段一邁向階段二的過渡過程中。我們的團隊也在為之努力。至於第三階段,是真正實現人類水平的思維能力,抽象思維、因果邏輯等等。我個人認為還早,至少現在的智能機制還不太能夠做到這些事情。
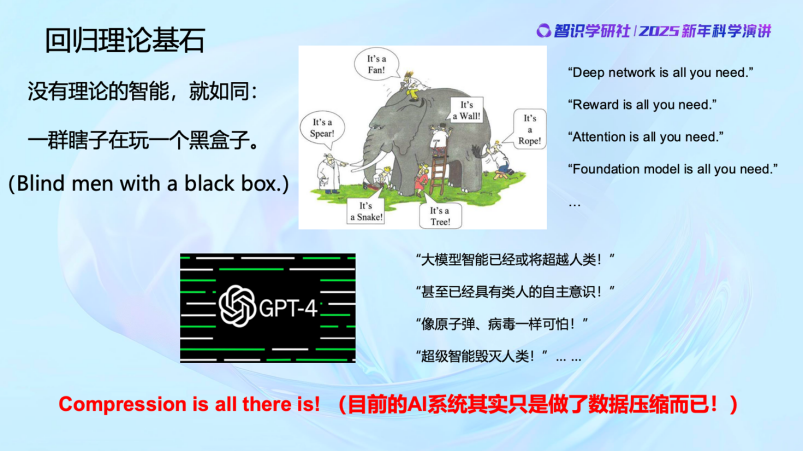
在現在這個時間節點上,理論變得非常重要。智能應該變成了一個科學問題、數學問題和計算問題,一定要科學化。不然大家就會輕易地說出一些奇怪的話來。比如我們經常能看到一些標題黨:
「Deep network is all you need.」
「Reward is all you need.」
「Attention is all you need.」
「Foundation model is all you need.」
……
我覺得這樣的提法完全是反科學的。但是現在的年輕人可能真的會把這些話當成真理。再往下,更嚴重的就是「不得了,人工智能馬上要超越人了」。那你這個「超越」是什麼意義上的「超越」呢?
當然,某種意義上確實超越了。計算機早就在很多地方已經超過人。一個普通的家用計算器,在算數、開根號方面那早就超過人了。但大家對這些事情要有本質的理解,不要泛泛去講。
現在媒體上動不動就能看到,說人工智能未來要毀滅人類了。說實話我很反感這些聳人聽聞的說法。因為我們清楚地知道,至少目前的系統還沒有超出對數據進行壓縮和編碼的範疇。

從方法論上,科學研究往往依託於兩個基本方法,一個是歸納法,一個是演繹法,這兩者都有它的作用,比如實驗物理,理論物理等等,相輔相成。過去十年,機器智能在技術上面突飛猛進,歸納出了很多好的經驗,這期間的發展靠的主要是歸納法;但是我希望今後的十年,如果要把智能研究變成科學的問題,數學的問題,應該要有很好的數學理論框架。就像我們計算機學的泰斗Donald Knuth講的,「The best theory is inspired by practice, the best practice is inspired by theory」 。我們過去十多年積累了那麼多的practice,現在就是呼喚英雄的時代,大道至簡,需要去找到智能的理論框架,去探索它的基本原理和思想。多一點思想,少一點技術。
謝謝大家!