中國大模型又在包括硅谷在內的全球AI圈炸場了。
兩天前,幻方量化旗下AI公司深度求索(DeepSeek),以及月之暗面相隔20分鐘相繼發布了自家最新版推理模型,分別是DeepSeek-R1以及Kimi 全新多模型思考模型k1.5,且都給出了非常詳盡的技術報告, 「中國雙子星」很快引發全球AI圈的關注。
在社交軟件X上,包括英偉達AI科學家Jim Fan在內的全球AI從業者紛紛發出了自己的感嘆:
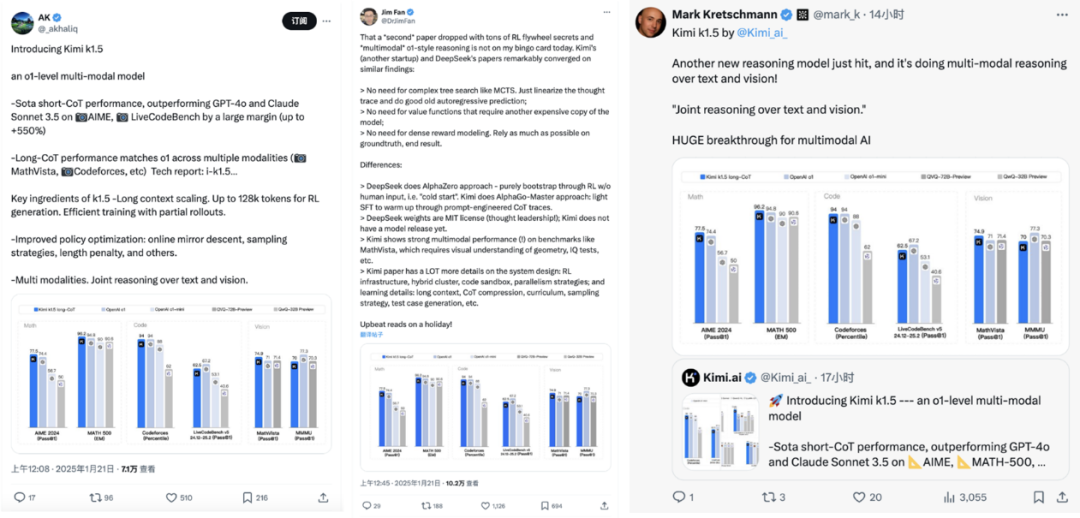
相關數據顯示,區別於過往類o1-preview模型,這次兩家中國公司正面硬剛OpenAI o1,發布的都是滿血版o1,而Kimi k1.5還是具備視覺思考的多模態。
表面上,是中國大模型某種程度上又一次在技術能力上直起了腰,而全球AI從業者的「圍觀」,本質上則透露出業界對大模型這台「蒸汽機」能夠儘快出現屬於自己的「瓦特」的期許。
01
大模型這台蒸汽機,急需要一個「瓦特」
大模型對時代的意義,不亞於蒸汽機之於工業革命。
但正如蒸汽機是在發明之後,是經過一段時間的改進,尤其是瓦特的改進後才正在成為工業革命驅動力一樣,大模型這台「蒸汽機」要想大展拳腳,還一直處在不斷改進之中。
那個屬於它的「瓦特」,還一直沒有到來,所有從業者都在熱切期待這個時刻。
參與的人越多,「瓦特時刻」出現的可能性就越大,只有一個遙遙領先的OpenAI未必符合業界的普遍期許,當出現了與之肩並肩的DeepSeek、Kimi,關鍵進化的可能性變得更大,炸場AI圈就成為普遍期待下的必然。

而回看DeepSeek與Kimi這對中國雙子星,他們發布的模型呈現了很多相似之處,都側重以強化學習(RL)為核心驅動力(即在僅有極少標註數據的情況下,極大提升模型推理能力)。
具體來說,二者在實現方式上都不需要進行像 MCTS 那樣複雜的樹搜索(只需將思維軌跡線性化,然後進行傳統的自迴歸預測即可),也不需要配置另一個昂貴的模型副本的價值函數、不需要密集獎勵建模,只儘可能多的依賴事實和最終結果。
很明顯,這些,都在提升推理模型的運行效率、降低資源需求,而有意思的是,這同樣是當年瓦特改造蒸汽機的方向,他在衆多改造中最完美地實現了這些目標。
歷史,總是驚人的相似。
值得一提的是,在這次中國雙子星炸場的過程中,OpenAI薩姆·奧爾特曼也加入其中,只不過他發揮了一貫的「陰陽」技能,「AGI不會下個月就到來」,在一片讚譽甚至狂歡中,暗地裏諷刺社交平台的關注是不是太過瘋狂。
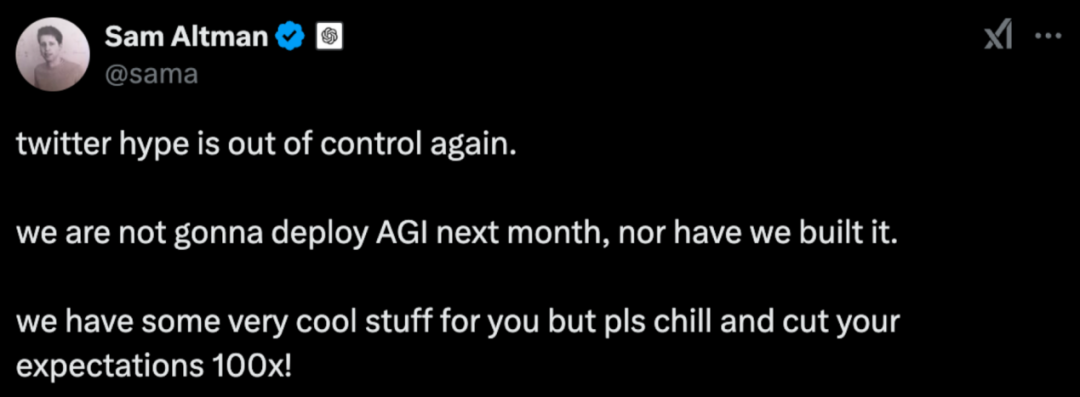
實際上,AGI確實不是短期能做到的,但這並不是制止全球從業者歡欣鼓舞的理由。蒸汽機花了很長時間才完成進化能夠走入工廠,大模型也需要這樣的過程才能實現對社會進步的全面賦能,也正因為如此,每一次對這個進程的縮短,都值得每一個從業者欣慰。
02
中國雙子星,讓業界看到「瓦特」的更多可能性
具體到技術層面,當仔細分析中國雙子星尤其是Kimi的SOTA模型能力後,就會發現業界人士的驚喜有着充分的理由。
以「蒸汽機」類比,瓦特的改進首先是直接提升了運行效率,提升了蒸汽轉化為機械動力的能力,從而能夠由「試驗裝置」走向真正的「機器」。
這次發布的模型首先也是在推理能力上大幅跨越,發布的都是真正的「滿血版o1」,而不是其他各家所發布的「準o1」,或者得分差得太遠的o1,有着絕對實力上的領先而非只是小小的一次迭代。
更進一步看,瓦特對蒸汽機的改進還在機器對不同生產環境的適應能力上進行了改造,對應到大模型這裏,則是推理大模型的多模態進化。
目前,DeepSeek R1只能識別文字、不支持圖片識別不同,Kimi k1.5則能進行一步多模態推理,且在數學、代碼、視覺等複雜任務上的綜合性能提升,成為OpenAI之外首個多模態類o1模型。
以Kimi k1.5為例:
一方面模型在數學和代碼能力上的推理能力和正確率(諸如 pass@1、EM等指標)大幅領先或趕超其他主流對比模型;
另一方面模型在在視覺多模態任務上,無論是對圖像中信息的理解、還是進一步的組合推理、跨模態推理能力,都有顯著提升。
截取Kimi的發布Paper原文,其長文本處理能力大幅提升,支持高達128ktokens 的 RL生成,採用部分展開方式進行高效訓練,且在訓練策略上有包括在線鏡像下降法等在內的多項改進。
在長思考模式(long-CoT)下,Kimi K1.5在數學、編程和視覺任務中的表現與OpenAI o1的性能水平接近。
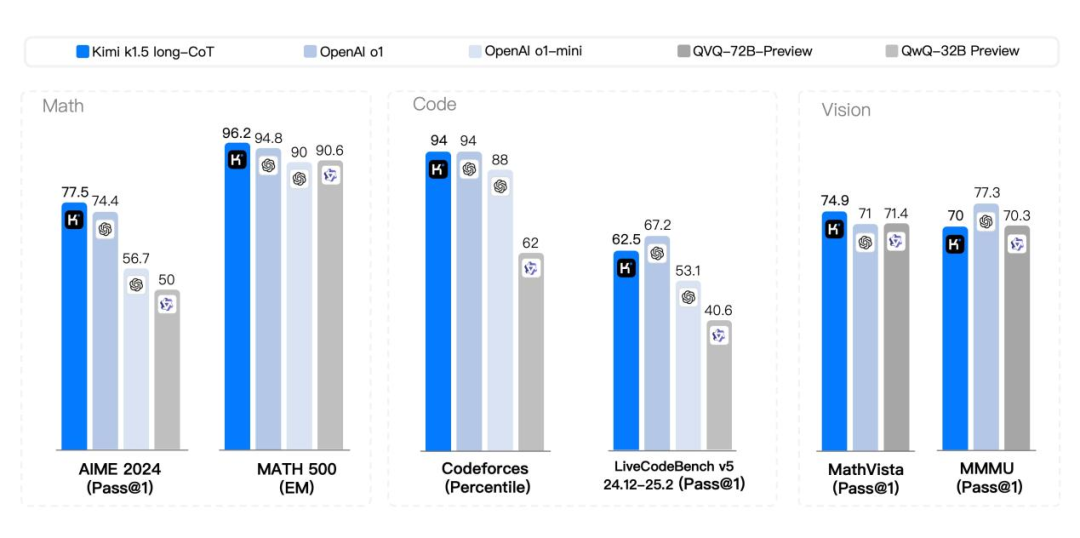
而到了短思考模式(short-CoT)下,Kimi k1.5 更是讓業界驚喜,做到了某種程度上的「遙遙領先」,其數學、代碼、視覺多模態和通用能力,大幅超越了全球範圍內短思考SOTA模型GPT-4o和Claude 3.5 Sonnet的水平,領先達到550%。
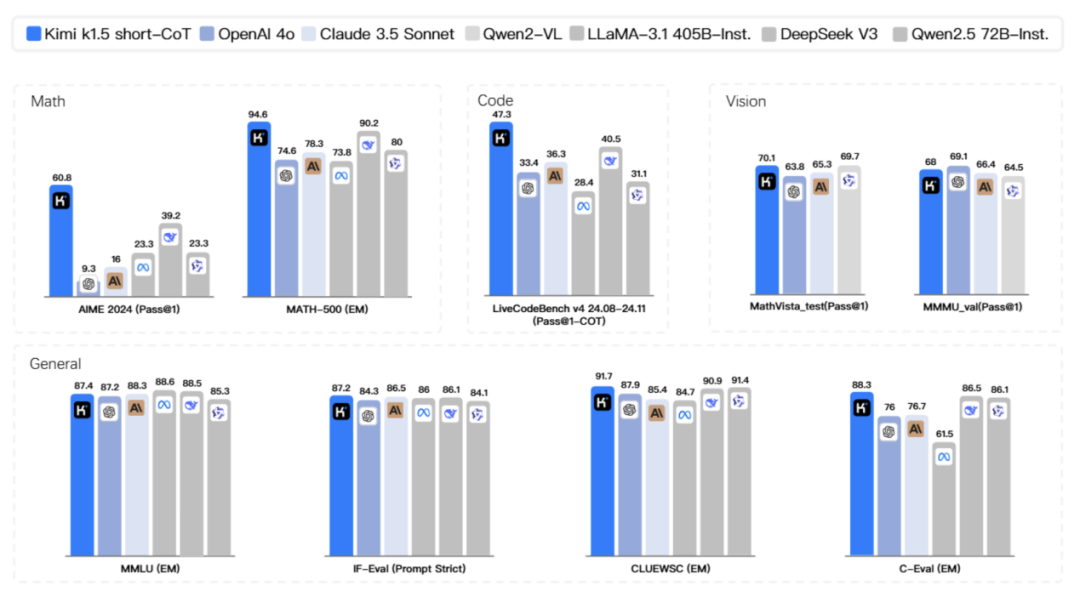
這種領先,得益於Kimi k1.5獨特的「Long2Short」訓練方案,顧名思義,即先利用較大的上下文窗口讓模型學會長鏈式思維,再將「長模型」的成果和參數與更小、更高效的「短模型」進行合併,然後針對短模型進行額外的強化學習微調。
這種做法,最大化保留了原先長模型的推理能力,避免了常見的「精簡模型後能力減弱」難題,又能同時有效挖掘短模型在特定場景下的高效推理或部署優勢,是一次推理模型的重要創新。
「Long2Short」訓練方案在算力與性能平衡方面實現了成功探索,改變了OpenAI o1以時間換空間的做法(犧牲實際應用時的用戶體驗來提升性能,這種做法一直存在爭議),有業界人士表示將會是未來新的研究方向。
而從更宏觀的視角看,這樣的創新,除了給Kimi帶來更亮眼的模型表現,毫無疑問也在讓大模型「蒸汽機」的「瓦特時刻」變得越來越近。
03
更密集的突破,才能爭搶「瓦特」
Kimi k1.5的出現顯然不會是一蹴而就的,是多次進化迭代的結果,但最令人關注的,是迭代的速度。
僅僅在三個月前的2024年11月,月之暗面就推出了初代版本的Kimi K0-math。過了1個月,k1視覺思考模型誕生,繼承了K0-math的數學能力,又成功解鎖了視覺理解能力,「會算」+「會看」。緊接着又1個月後,也就是這次的K1.5發布,在數理化、代碼、通用等多個領域中,刷新了SOTA,直接媲美世界頂尖模型。
三個月三次突破,密集創新迭代才帶來炸場的效果與成果。
在關鍵的歷史節點,業界期待「瓦特」,與此同時,業界也在爭當「瓦特」,大模型只會越來越卷。
就在中國雙子星炸場後,美國總統特朗普宣佈OpenAI、甲骨文和軟銀將聯合推進一項稱之為Stargate(星際之門)的項目,要在人工智能基礎設施領域投資至少5000億美元,大國AI競爭已經白熱化。
好在,無論是基礎設施的建設,還是以中國雙子星為代表的模型能力建設,中國都已經搶佔了先機,這一次不會再處於被動地位——在Kimi的規劃中,其將繼續發力多模態推理,快速迭代出更多模特、更多領域、更具備通用能力的Kn系列模型。
相信,大模型的「瓦特時刻」,同樣會是中國大模型贏得話語權的時刻。