當初OpenAI拋出Sora大餅,一時間Open Sora項目熱火朝天。
現在,這股Open的風也是反向吹起來了,最新目標,正是國產大模型DeepSeek-R1。
Open R1項目由HuggingFace發起,聯合創始人兼CEO Clem Delangue是這麼說的:
我們的科學團隊已經開始致力於完全複製和開源R1,包括訓練數據、訓練腳本……
我們希望能充分發揮開源AI的力量,讓全世界每個人都能受益於AI的進步!我相信這也有助於揭穿一些神話。
HuggingFace振臂一呼,立刻歡呼者衆。項目上線僅1天,就在GitHub上刷下1.9k標星。
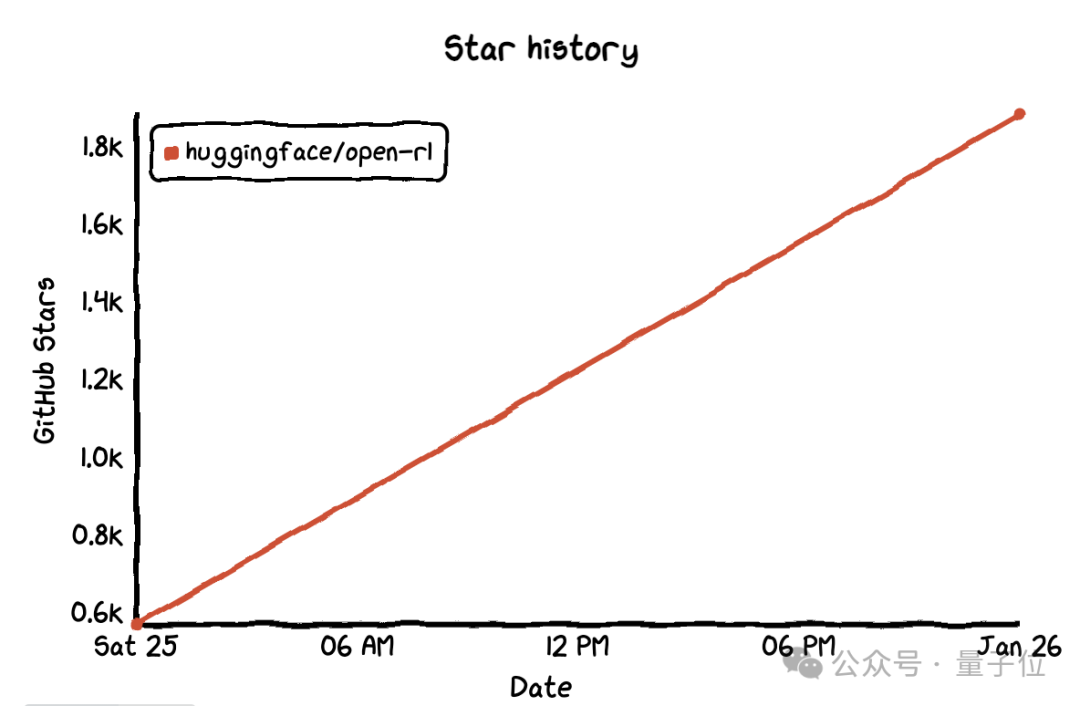
看來這一波,DeepSeek-R1真是給全球大模型圈帶來了不小的震撼,並且影響還在持續。
01 Open R1
不過話說回來,DeepSeek-R1本身就是開源的,HuggingFace搞這麼個「Open R1」項目,又是為何?
官方在項目頁中做了解釋:
這個項目的目的是構建R1 pipeline中缺失的部分,以便所有人都能在此之上覆制和構建R1。
HuggingFace表示,將以DeepSeek-R1的技術報告為指導,分3個步驟完成這個項目:
第1步:用DeepSeek-R1蒸餾高質量語料庫,來複制R1-Distill模型。
第2步:複製DeepSeek用來構建R1-Zero的純強化學習(RL)pipeline。這可能涉及為數學、推理和代碼整理新的大規模數據集。
第3步:通過多階段訓練,從基礎模型過渡到RL版本。
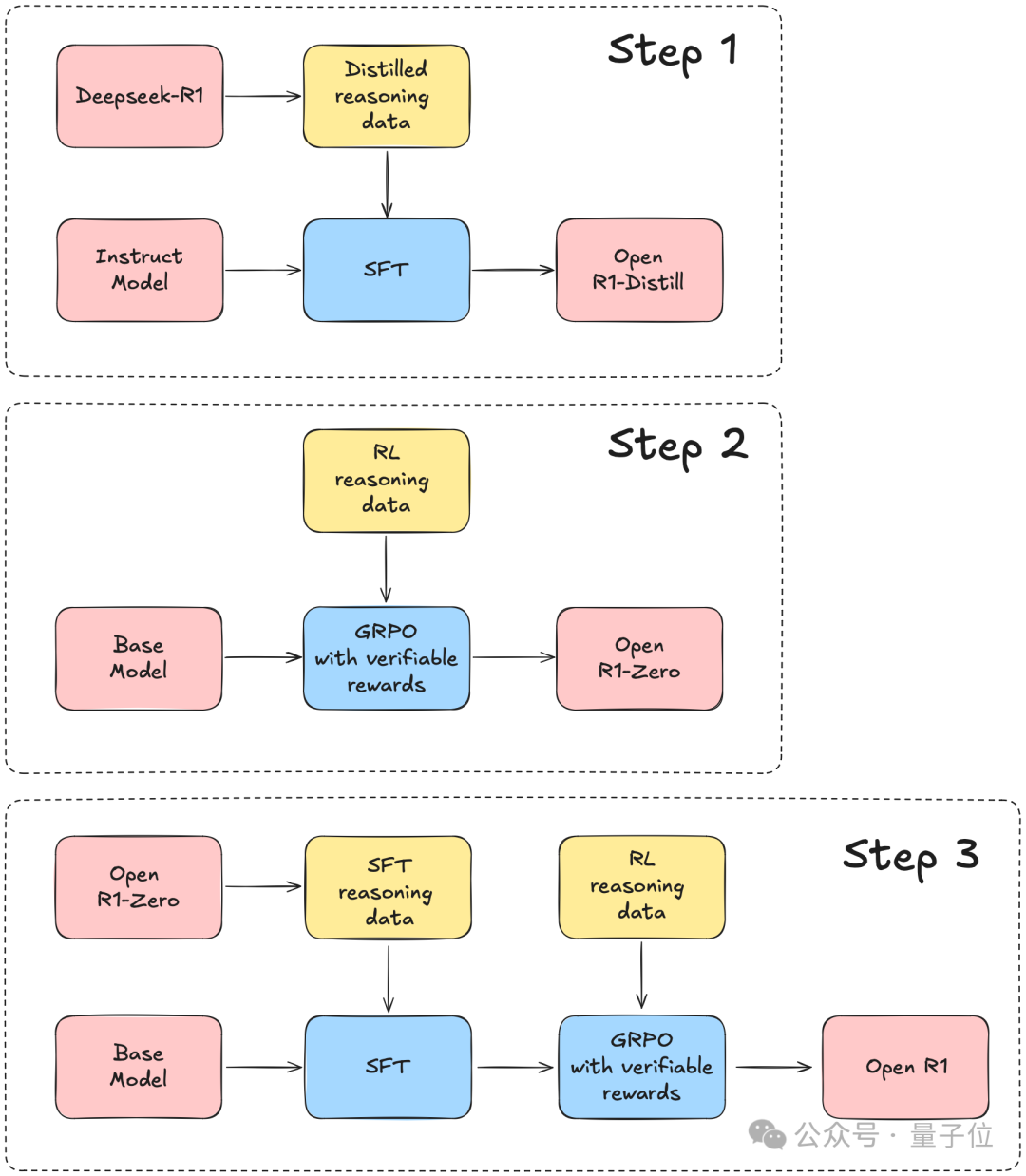
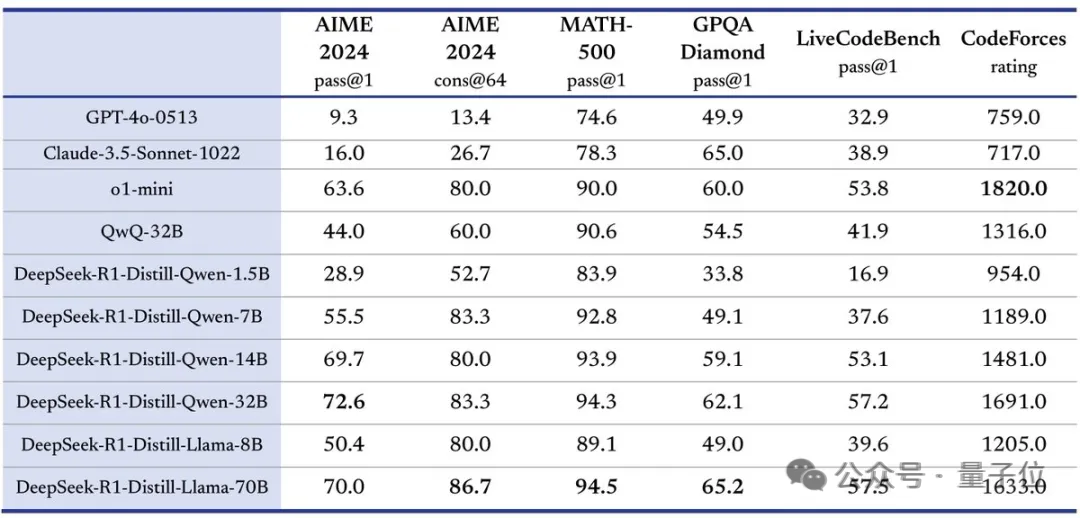
結合DeepSeek的官方技術報告來看,也就是說,Open R1項目首先要實現的,是用R1數據蒸餾小模型,看看效果是不是像DeepSeek說的那麼好:
DeepSeek開源了6個用R1蒸餾的小模型,其中蒸餾版Qwen-1.5甚至能在部分任務上超過GPT-4o。
接下來,就是按照DeepSeek所說,不用SFT,純靠RL調教出R1-Zero,再在R1-Zero的基礎上覆刻出性能逼近o1的R1模型。
其中多階段訓練是指,R1技術報告提到,DeepSeek-R1訓練過程中引入了一個多階段訓練流程,具體包括以下4個階段:
冷啓動
用數千個長思維鏈(CoT)樣本對基礎模型進行監督微調(SFT),為模型提供初始的推理能力
面向推理的強化學習
在第一個SFT階段的基礎之上,用和訓練R1-Zero相同的大規模強化學習方法,進一步提升模型的推理能力,特別是應對編程、數學、科學和邏輯推理任務的能力。
拒絕採樣和監督微調
再次使用監督微調,提升模型的非推理能力,如事實知識、對話能力等。
針對所有場景的強化學習
這次強化學習的重點是讓模型行為與人類偏好保持一致,提升模型的可用性和安全性。
目前,在GitHub倉庫中,已經可以看到這幾個文件:
GRPO實現
訓練和評估代碼
合成數據生成器
02 奧特曼坐不住了
有意思的是,R1刷屏之中,奧特曼也坐不住了。
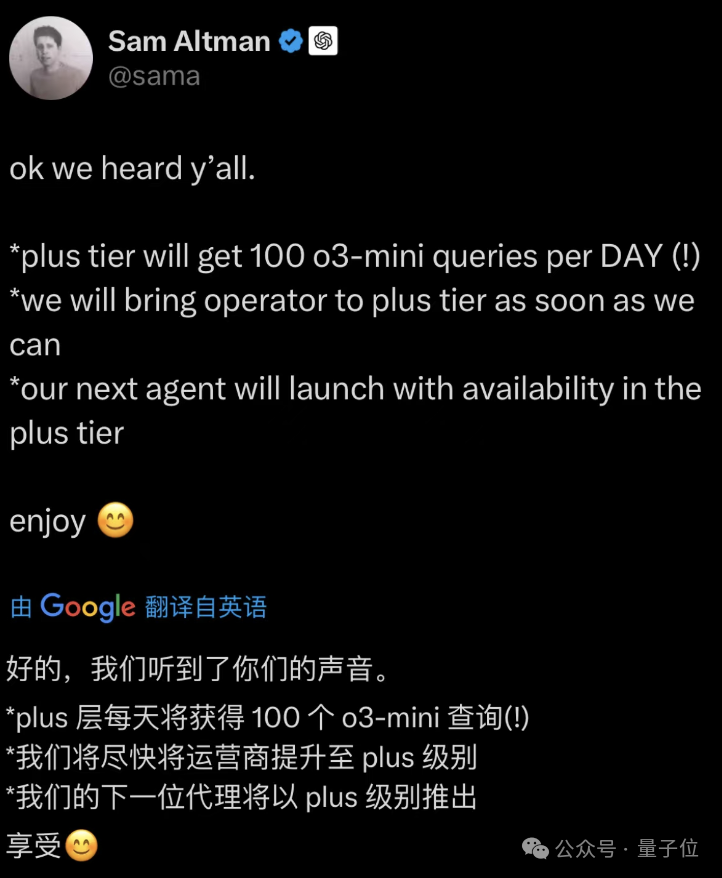
這不,他又帶來了o3-mini的最新劇透:
ChatGPT Plus會員可以每天獲得100條o3-mini查詢。
Plus會員馬上就能用上operator了,我們正在盡力!
下一個智能體Plus會員首發就能用。
這話一出,𝕏的空氣中充滿了快樂的氣息(doge):
哇!DeepSeek正在讓OpenAI主動大甩賣誒!