去年底,我們寫了一篇筆記, 《2024年,DeepSeek帶給硅谷「苦澀的教訓」》,提出了一個觀點,相比聖誕前OpenAI的連續12天線上發布會,DeepSeek-V3的發布,纔是當年真正的壓軸戲。
沒想到這篇文章引發了一陣狂炒。DeepSeek-R1推理模型就在特朗普就職日那天發布,性能基本超過了GPT-4o,媲美OpenAI-o1,成本僅為其十分之一到二十分之一。這次不僅讓硅谷懵逼,而且讓華爾街也不安起來。
尤其是特朗普宣佈了任期內投資5000億美元AI基礎設施的 星際之門計劃,由軟銀、OpenAI和甲骨文操盤,微軟、英偉達、ARM等為技術夥伴,更是把美國的AI發展的資本+算力模式推到了一個新的高度,還不用說其他科技巨頭每年高達數千億的資本支出主要投向AI。但DeepSeek以高效的訓練和推理,讓砸錢搞GPU軍備競賽的AI發展模式開始遭到一些質疑,建立在這一基礎之上的AI概念公司,無論在一級市場,還是在二級市場,都面臨着一次估值的拷問。
相比之下,DeepSeek正在探索一條中國式的AI發展之路,我們在 對2025年AI的十個展望中,第一條就提出來,中國將參與基礎模型的創新,而不僅僅是跟隨。辭舊迎新之際,我們再度對DeepSeek進行一次」模式「級別的梳理,分下面四個部分:
1,深度求索有深度
2,螢火和R1論文
3,DeepSeek衝擊
4,改寫AI遊戲規則
深度求索有深度
DeepSeek遠遠不像是許多介紹的、尤其是海外報道和傳說中的那樣,是一家僅成立一年多的AI公司。實際上它脫胎於幻方量化基金,這是一家已經創辦了17年的、有數學、計算、研究和AI基因的對沖基金。
2008年,浙江大學學習信息與通信工程的梁文鋒創立了幻方量化,直到2014年,在幻方量化的初創階段,團隊從零開始探索全自動化交易。
2015年纔是幻方自認為的創始元年,真正依靠數學與人工智能進行量化投資。「創始團隊意氣風發、勇於創新、勤勉奮進,立志成為世界頂級的量化對沖基金。」2016年,幻方第一個AI模型建立的股票倉位上線實盤交易,算力開始從CPU轉向GPU。至 2017 年底,幾乎所有的量化策略都已經採用 AI 模型計算。
作為一家對沖基金,幻方開始確立以 AI 為公司的主要發展方向。但是, 複雜的模型計算需求使得單機訓練遭遇算力瓶頸,同時日益增加的訓練需求和有限的計算資源產生了矛盾,2018年,幻方的AI團隊開始尋求大規模算力解決方案。
其實2019年可能是幻方大模型之路的起點,這一年,幻方AI(幻方人工智能基礎研究有限公司)註冊成立,致力於 AI 的算法與基礎應用研究。AI 軟硬件研發團隊自研幻方「螢火一號」AI集羣,搭載了500塊顯卡,使用 200Gbps 高速網絡互聯。一年之間,「螢火一號」總投資近2億元,於2020年正式投用,滿血搭載1100塊加速卡,為幻方的AI研究提供算力支持。
幻方AI很快又投入10億元建設螢火二號。2021年,螢火二號一期確立以任務級分時調度共享AI算力的技術方案,從軟硬件兩方面共同發力:高性能加速卡、節點間 200Gbps 高速網絡互聯、自研分佈式並行文件系統(3FS)、網絡拓撲通訊方案(hfreduce)、算子庫(hfai.nn),高易用性應用層等,將螢火二號的性能發揮至極限。
到了2022年,ChatGPT時刻前夕,幻方已經成為國內一家領先的AI公司,而且手中握有上萬塊英偉達A100卡和一定數量的AMD卡。螢火二號取得了多800口交換機互聯加核心擴展子樹的軟硬件架構革新,突破了一期的物理限制,算力擴容翻倍。新的hfai框架讓模型加速50-100%。集羣連續滿載運行,平均佔用率達到96%以上。全年運行任務135萬個,共計5674萬 GPU 時。用於科研支持的閒時算力高達1533 萬GPU 時,佔比27%。
從中可以推算出,在2022年,幻方已經平均每天用4.2萬GPU時,相當於每天有近2000張GPU卡在幾乎滿負荷跑科研而不是交易。如果按照當時A100每小時雲服務的市場價,相當於每年在科研方面投入2億元人民幣。這樣規模的AI研究,在當時的國內處於領先狀態,在當時的國際上巨頭之外的AI初創公司中,也算得上是領先的。
2023年4月11日,開源模型Llama1和GPT-4和相繼發布之後,幻方宣佈做大模型,2023年5月把技術部門做大模型的團隊獨立出來,成立深度求索公司,進軍通用人工智能AGI。
所以,如果從深度求索公司成立算起,DeepSeek還不滿2年;但是如果從成立幻方AI算起,已近5年;再從2016第一個AI股票倉位模型上線交易算起,已近10年。
當2018年,幻方確立以AI為公司的主要發展方向時,就已經註定了它將是一家AI技術公司,而對沖基金是其當時主要的應用。
我們可以看到,量化投資與AI研究,構成了幻方基因的雙螺旋結構。2019年,幻方躋身百億私募,這一年,幻方AI成立,並且開始獨立構建螢火集羣。2021年,幻方管理基金規模一度超過千億元,它開始構建更大更復雜的算力集羣螢火二號。幻方的基金管理業務最輝煌的是2019年和2020年,自然年收益分別為58.69%和70.79%,此後因為行業等方面的原因,量化發展一蹶不振,但幻方作為一家AI公司凸顯出來。
如果對比成立於2010年的DeepMind和成立於2015年的OpenAI,作為創業公司,幻方與其處於同一時代。DeepMind和OpenAI創立時都是純粹的AI實驗室,以實現通用人工智能(AGI)為使命,而且在這場深度學習革命中起到了先鋒作用,從AlphaGo、AlphaFold到ChatGPT,都是革命性的技術與產品。相比之下,幻方AI一直在復刻研究其成果,直到成立深度求索,推出DeepSeek大模型。從這一點來說,DeepSeek取得的成就,是站在巨人的肩膀上。
從AI交易模型到幻方AI,再到DeepSeek,推動了幻方的對沖基金業務的同時,也一步一步從業務部門獨立出來,並逐步重新定義幻方這家公司。幻方AI的發展離不開對沖基金業務的支持。進行長期的AI研究,離不開資金與算力資源的強有力支持。DeepMind最後被谷歌收購,作為一家獨立的公司,它一直虧損,但作為一家AI研究實驗室,在谷歌內部的作用是戰略性的。
我在2017年採訪DeepMind創始人哈薩比斯時,他告訴我說,谷歌收購DeepMind,就是為了推動從移動第一到AI第一的戰略轉型。在ChatGPT之後,谷歌更是對其內部顯得雜亂的AI研發和業務進行了整合,全部 歸併到DeepMind旗下。
同樣,OpenAI也從非營利改組為營利。其中微軟先後投資達140億美元,對於OpenAI能持續以大算力推進Scaling Law (擴展定律),以大資金和高估值吸引全球頂尖人才,成為一家生成式人工智能的領軍企業,發揮了至關重要的作用。
對於所有的技術公司來說,AI大模型將成為其技術底座,也將重構所有企業的IT和軟件部門,這可以部分解釋為什麼一個企業內生的AI能力,強大到一定程度,有可能定義出企業新的增長曲線。
從2019年幻方開始構建螢火一號開始,就註定了它走上了一家AI公司的軌跡。2021年,幻方構建螢火二號,在亞太第一個拿到A100卡,在ChatGPT之後,幻方成為全國少數幾家擁有上萬張A100 GPU的機構。投資十多億元構建萬卡級算力級羣,這不會是僅僅用於炒股。
而硅谷和Alex王和Dylan Patel等,在DeepSeek-3V推出之後,更是相信DeepSeek擁有5萬塊H100。不管怎麼說,在DeepSeek做研究,應該是中國實現GPU自由的地方。
DeepSeek與DeepMind和OpenAI一樣追求人才密度,所不同的是,後兩者吸收了全球最優秀的AI人才,而前者目前只吸收了國內最優秀的人才。記得當時我採訪哈薩比斯時問過同樣的問題,他回答說:DeepMind吸引了全球60多個國家頂尖的博士生和科學家。
DeepSeek從一家對沖基金的技術研究部門,逐步將其母體轉變為一家AI公司,這是一個非常特殊的例子。對沖基金和AI技術都來自美國,但無論是華爾街的對沖基金、還是從華爾街海歸做量化的團隊,沒有一個能像幻方這樣,進化出一個做通用AI大模型的核心能力,例如,彭博曾經很早推出了BloombergGPT大模型,然後就沒有然後了。從這一點上來說,DeepSeek這個本土團隊是獨特的,沒有「模式」可談。
但是,DeepSeek也蹚出了一條路,可能用500萬美元、千張GPU卡訓練出高性價比的模型,這讓許多在巨頭面前感到絕望、紛紛放棄預訓練的初創AI企業,開始重新思考它們的戰略,從這一點來說,DeepSeek開創了一種「模式」。
螢火和R1論文
2024年,DeepSeek一口氣發布了從V1到V3三個基礎模型版本,全部開源,如果看其研究部門之前幾年發的論文和技術博客,可以理解這也是厚積薄發的結果。我們在去年底的文章裏介紹了DeepSeek的8篇論文,這裏再補充介紹兩篇。一篇是被國際AI界廣泛讚譽為2025年最迄今為止最佳論文的R1。
它的亮點包括:對基礎模型直接上強化學習,而不是先用收集起來非常耗時的監督數據進行訓練;採用了羣體策略相對優化(GRPO),強化學習訓練的成本和複雜性都得到了顯著降低,同時保持了較好的性能表現;還蒸餾了6個Qwen和Llama的小模型,用起來更加節省,而且針對領域的性能更加強大;特別是DeepSeek-R1-Distill-Qwen-1.5B在數學基準測試中優於GPT-4o和Claude-3.5 Sonnet。它可以裝到一個手機裏。
這裏要特別提及論文中有一段,用散文化的語言,描述了在訓練過程中出現的模型自我「頓悟」的時刻:
「在DeepSeek-R1-Zero的訓練過程中,觀察到一個特別有趣的現象,即「頓悟時刻」(aha moment) 的出現。這一時刻出現在模型的中間版本中。此時,DeepSeek-R1-Zero學會了重新評估其初始方法,為問題分配更多的思考時間。這種行為引人入勝,不僅證明了模型推理能力的提升,也例證了強化學習如何帶來意外且複雜結果。
這不僅是模型的‘頓悟時刻’,也是研究人員的‘頓悟時刻’,他們觀察到了強化學習的力量與美感:我們並未明確教導模型如何解決問題,而是為其提供了正確的激勵,使其自主發展出高級的問題解決策略。‘頓悟時刻’有力地提醒我們,強化學習有潛力在人工系統中解鎖新的智能水平,為未來更自主和自適應的模型鋪設道路。」

一個有趣的「頓悟時刻」出現在DeepSeek-R1-Zero的中間版本中。該模型學會了以擬人化的語氣重新思考。這對我們來說也是一個頓悟時刻,讓我們見證了強化學習的力量與美感。(來源:DeepSeek R1論文)
如何構建一個高效的萬卡算力集羣?DeepSeek發布於2024年8月的論文,介紹了高性價比的螢火AI-HPC架構,提出了深度學習的軟件與硬件一體化設計的理念。按姓氏拼音字母,創始人梁文鋒排在第17位作者。
這篇論文總結了構建螢火二號的經驗,配備10,000個PCIe A100 GPU,其性能接近英偉達的DGX-A100,同時將成本降低了一半,能耗減少了40%。
DeepSeek團隊特別設計了HFReduce以加速allreduce通信,並實施了多項措施以確保計算-存儲一體化網絡無擁塞。通過我們的軟件堆棧(包括HaiScale、3FS和HAI-Platform),還通過重疊計算和通信實現了顯著的擴展性。
從中可以看出,DeepSeek的策略,是用接近最先進的大模型和基礎設施的性能,設計出遠超其接近性的高性價比的產品,參與國際大模型競爭。
DeepSeek衝擊
DeepSeek-R1已經成為MIT和斯坦福美國頂尖高校研究人員的首選模型。甚至有研究人員表示,它已經代替了ChatGPT。其實最大的受益者,應該是中國用戶,它讓美國在大模型上對中國的卡脖子基本無效了,中國大多數用戶以後可以用上和美國基本相當的AI模型和應用。
全球最大開源平台HuggingFace團隊,也正式宣佈復刻DeepSeek-R1所有pipeline。完成之後,所有的訓練數據、訓練腳本等,亦將全部開源。DeepSeek已飆升至 HuggingFace 上下載量最多的模型,僅R1下載已經超過13萬次(本文截稿時為止),蒸餾小模型如Qwen 32B 和1.5B,也都名列前茅。
DeepSeek-R1激起了開發人員極大的熱情,社交媒體和社區網站上,大家興奮地分享着自己的嘗試,並交流着對他們的 AI 開發意味着什麼。用戶評論說,DeepSeek的搜索功能現在優於 OpenAI 和 Perplexity ,只有 Google 的 Gemini Deep Research 可以與之匹敵。
尤其是在基礎模型上直接強化學習,成為衆多AI實驗室及研究人員紛紛採用的新範式,為了過程中追求DeepSeek的那一「呵哈時刻」,港科大助理教授何俊賢團隊,只用了8K個樣本,就在7B模型上覆刻出了DeepSeek-R1-Zero和DeepSeek-R1的訓練。
一些團隊證明,採用了R1-Zero算法——給定一個基礎語言模型、提示和真實獎勵信號,運行強化學習,小到1.5B的開源模型,應用於一些遊戲當中,都能復現出解決方案、自我驗證、反覆糾正、直到解決問題為止。1.5B模型更是可以下載到手機上,在數學等性能上,相當於擁有了一個性能相當GPT-4o和Claude 3.5 Sonnet的最先進閉源模型。
美國的主流商業、財經、甚至綜合時政媒體,也開始報道DeepSeek現象。CNBC對AI獨角獸Perplexity創始人CEO Aravind Srinivas的專訪,從一個技術產業專家的角度,對DeepSeek V3的亮點進行了點評:
需求是創新之母。正因為他們必須尋找變通方案,他們最終建造出了一個效率更高的系統。「除非在數學上能證明這是不可能的,否則你總能想出更有效率的方案。」
性價比。「他們推出了一個成本比GPT-4低10倍、比Claude低15倍的模型。運行速度很快,達到每秒60個token。在某些基準測試中表現相當或更好,某些則稍差,但總體上與GPT-4水平相當。更令人驚訝的是,他們僅用了大約2048個H800 GPU,相當於1000-1500個H100 GPU,總計算成本僅500萬美元左右。這個模型免費開放,並發布了技術論文。」
巧妙的技術解決方案。「首先,他們訓練了一個混合專家模型(Mixture of Experts),這並不容易。人們難以追趕OpenAI,特別是在MOE架構方面,主要是因為存在大量不規則的損失峯值,數值並不穩定。但他們提出了非常巧妙的平衡方案,而且沒有增加額外的技術修補。他們還在8位浮點訓練方面取得突破,巧妙地確定了哪些部分需要更高精度,哪些可以用更低精度。據我所知,8位浮點訓練的理解還不夠深入,美國的大多數訓練仍在使用FP16。」
Perplexity 已經開始使用DeepSeek。他們提供API,而且因為是開源的,我們也可以自己部署。使用它可以讓我們以更低的成本完成許多任務。但我在想的是更深層的問題:既然他們能訓練出如此優秀的模型,這對美國公司來說,包括我們在內,就不再有藉口說做不到這一點了。
DeepSeek-R1開源,已經逼得o3 mini免費!
從硅谷到華爾街,分析人士已經開始思考,DeepSeek可能對熱炒AI的美國資本市場,從一級到二級,會帶來多大的影響。中國企業地板價的AI服務,會不會衝擊美科技巨頭的估值,AI相關基礎設施的投資規模,等等。科技巨頭每年鉅額的AI資本支出,短期內是否值得。美國AI概念股,是否需要來一次重新估值呢?而中國的AI概念股,是否也需要來一次重新估值呢?有人開玩笑說,DeepSeek背後的幻方量化,在發布V3、R1的同時,幻方可以建立起沽空美國AI概念股的策略。
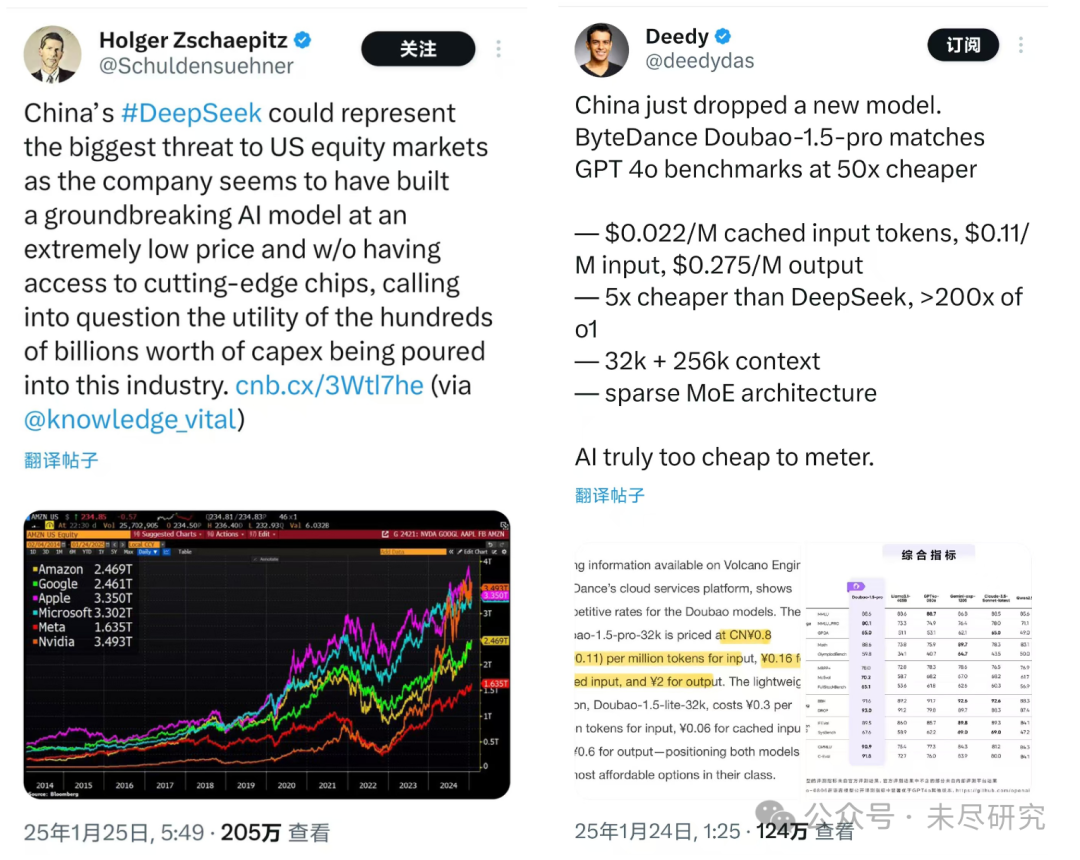
DeepSeek也在改變硅谷的AI初創企業估值,讓風險資本多數不約而同站在DeepSeek一邊,他們找到了殺價初創公司的最好理由:我pre-A給你500萬美元,你能幹出點啥?看看人家的孩子,看看DeepDeek!
難道你們都把錢用來買OpenAI的服務了嗎?現在不是有DeepSeek,便宜10倍到20倍呵!而且,緊接着DeepSeek,字節的豆包-1.5-pro也推出了,比DeepSeek便宜5倍,比o1最多便宜200倍!
就連OpenAI啱啱推出的智能體Operator,只有月費200美元的訂戶才能使用,但是,用DeepSeek可以做出同樣好的開源免費版本,而且已經有四五個了。
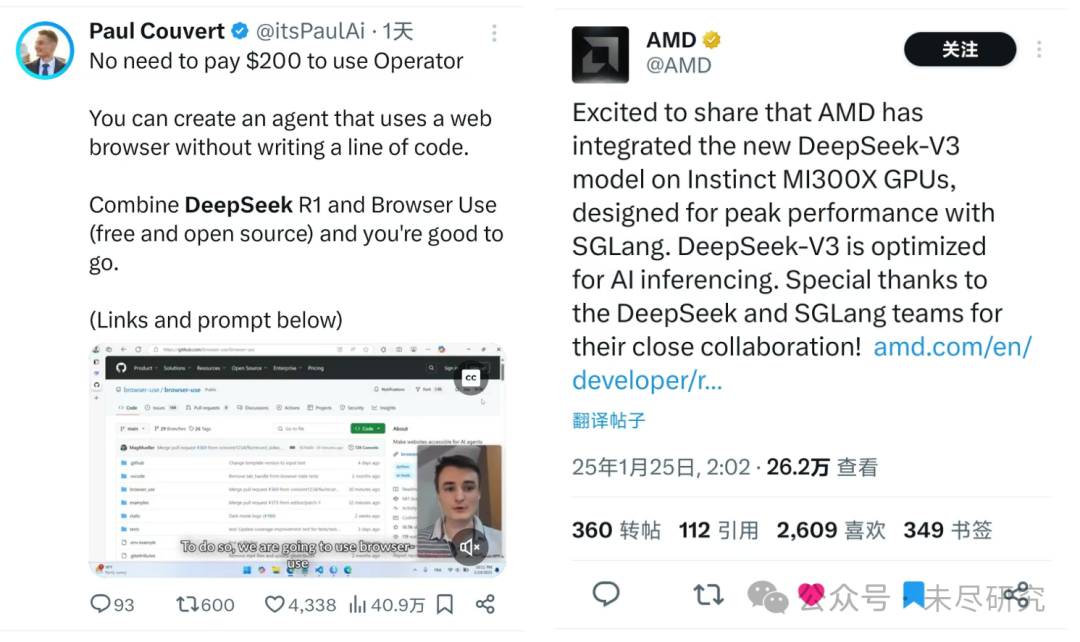
AMD反應很敏銳,已經把DeepSeek-V3集成到了Instinct MI300X GPU上。
用DeepSeek,還出現了一些新的玩法:如RAT,( retrieval angment thinking),把R1的推理過程,嫁接到任何一個大型語言模型上,可以顯著提升其性能,並獲得函數調用和JSON模式。
這位小哥在用DeepSeek開發了一個研究智能體。
不過也有一些研究人員表示,DeepSeek 模型在跟蹤長時間對話的背景等方面,其能力與花費更高的競爭對手模型相比,還有欠缺。
改寫AI遊戲規則
這次楊立昆最有話說。「與其說是中國正在超越美國AI,不如說是開源正在超越閉源AI。」
開源與閉源
面對美國的封鎖和巨頭的軍備競賽,中國的一些AI企業選擇了一條不同的道路——開源。較低的成本可以做出優秀可用的推理模型,而且好的模型轉化為更「殺手」的應用,似乎是更有效的路徑。DeepSeek沒有在應用方面花一分錢推廣,但它已經在國內和國際的各大應用商店佔據榜首。這讓一些AI「小龍」們重新思考,迴歸技術,擁抱開源,如最近MiniMax果斷轉向開源。

開源能夠匯聚全球社區的力量,加速大模型的研發和應用創新。開源模型更容易被廣泛採用,尤其是在算力和人才資源有限的國家和行業。 通過開源,中國有機會在全球AI領域建立自己的技術標準。開源模型(如DeepSeek、阿里Qwen等)以高性價比著稱,有助於推動AI技術的普惠化,將AI技術推廣到全球南方國家,
DeepSeek會影響衆多企業AI戰略。隨着成本降低和開放訪問,企業現在可以選擇替代昂貴的專有模型,例如OpenAI。DeepSeek的發布可能會使前沿AI 功能的訪問變得民主化,使較小的企業能夠在 AI 軍備競賽中有效競爭。
Aravind Srinivas進一步指出了為什麼美國地精英階層開始產生的擔憂更具戰略意義:「比起試圖阻止他們(中國AI企業)追趕,更危險的是他們現在擁有最好的開源模型,而所有美國開發者都在使用它進行開發。這更危險,因為這意味着他們可能會掌握整個美國AI生態系統的心智。歷史告訴我們,一旦開源趕上或超越閉源軟件,所有開發者都會轉向開源。」
中國與美國
在美國對中國實施芯片封鎖的背景下,DeepSeek展現了一種真正的創新——需求推動的創新。中國企業在僅能從中國本土企業獲得比美國落後一兩代GPU條件下,依然能夠開發出優秀的基礎模型。這種創新不僅僅依賴於GPU和資本的軍備競賽,而是通過算法、架構和工程的創新實現了突破。
關於OpenAI的護城河問題,2023年5月,在Meta發布了Llama開源模型後不久,谷歌內部即有人提出,我們沒有護城河,OpenAI也沒有。
今天,是這一問題再次提出的時候了。首先是OpenAI的護城河在哪裏。隨着AI技術進入實際應用領域,性價比成為關鍵因素,而非單純追求最先進的模型。OpenAI等公司投入數十億甚至上百億美元進行預訓練和基礎設施建設,但如果其技術護城河不夠深,其商業模式將面臨挑戰。這種高投入的模式是否可持續,成為從硅谷到華爾街令人感到焦慮的問題。
DeepSeek已經證明,美國無法在 AI 領域獲取絕對的競爭優勢,甚至那些科技巨頭都無法取得絕對的優勢。
應該看到,以AI發展的全棧技術來看,中國與美國依然有明顯的差距。越往底層走,差距越明顯。在AI芯片領域,從GPU到HBM,中國自主技術的差距在兩代到三代。而這一輪AI創新的一個突出特徵,是科技巨頭主導的,它們擁有自制芯片(ASIC)、數據中心、雲計算、AI平台及工具鏈、操作系統、殺手級應用,建立起全棧技術的垂直整合體系,其中尤以亞馬遜、微軟、谷歌這三大雲服務巨頭為代表。
OpenAI也在向一家AI科技巨頭演變,它依然擁有強大的技術能力和品牌影響力。它正在從基礎模型向上下游擴展,建立起自己的應用芯片團隊和數據中心,加快佈局基於推理模型的智能體,並全面探索其商業模式,如果昂貴的而又尖端的推理和智能體技術,最終證明能解決複雜和有價值的問題,在性價比上依然擁有強大的競爭力。
Srinivas認為Meta仍然會開發出比DeepSeek 3更好的模型,「不管他們叫它Llama 4還是3點幾」。他特別強調了Meta在開源領域的貢獻:「實際上,Meta的Llama 3.3技術報告非常詳細,對科學發展很有價值。他們分享的細節已經比其他公司多得多了。」相比之下,DeepSeek的技術報告沒有公布訓練數據來源。
Srinivas認為,與其擔心中國的追趕,更重要的是保持創新勢頭,繼續推動技術進步。「我們不應該把所有精力都集中在禁止和阻止他們(中國AI企業)上,而是要努力在競爭中勝出。這纔是美國人做事的方式——就是要做得更好。」
對攻的比賽更精彩。蛇年讓我們期待Llama 4,Grok 3,也期待 OpenAI-o4, Claude-4, 還有Gemini-2.5或者3,甚至GPT-5。