來源: 創業資本匯
DeepSeek衝擊波還在持續,而且已經從科技圈蔓延至資本圈。
1月27日,由國產大模型公司深度求索開發的移動應用DeepSeek超越ChatGPT登頂蘋果美國區免費應用排行榜。同日,蘋果中國區應用商店的免費榜也顯示,DeepSeek為排行榜第一。由於用戶源源不斷地湧入DeepSeek,繼昨天下午出現局部服務波動導致數分鐘的短暫系統崩潰後,DeepSeek今日上午又火到「宕機」,服務狀態頁面顯示網頁/API不可用。據DeepSeek回應稱,可能與服務維護、請求限制等因素有關。
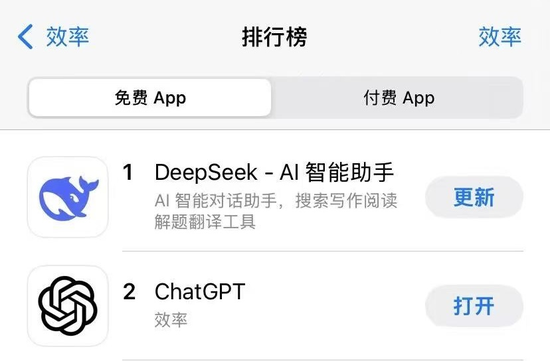
同時,DeepSeek這匹「AI黑馬」也在資本界掀起了滔天巨浪。由於DeepSeek通過結構化稀疏注意力、混合專家系統、動態計算路由等技術,顯著降低了模型訓練和推理的算力消耗,由此引發了市場關於算力需求下降的擔憂。受此影響,美股科技巨頭股價盤前集體大跌,英偉達跌超8%,超威半導體一度跌超5%,台積電一度跌逾8%,博通跌近9%。除此以外,歐洲股市方面,光刻機巨頭阿斯麥跌近10%;A股AI算力指數今日跌3.94%,寒武紀一度跌10%,中際旭創跌超10%,工業富聯跌超8%。
DeepSeek火遍國內外
這兩天,爆火的DeepSeek已在海內外引發諸多討論。
記者注意到,華爾街頂級風投A16Z的創始人、被稱為風投教父的MarcAndreessen今日在社交平台上發文稱,「DeepSeek是AI的斯普特尼克時刻」。所謂的「斯普特尼克時刻」,指的是1957年蘇聯成功發射第一顆人造衛星斯普特尼克1號。這一比喻充分說明了DeepSeek在生成式人工智能時代帶來的震動與衝擊。
國內方面,有關DeepSeek的多個詞條在27日登上了微博熱搜。許多體驗了DeepSeek的網友紛紛發帖,對其思考的深度水平、回答的智能程度給予了高度評價。有網友表示,「DeepSeek思考的方向比我全面多了,更不要談它的知識儲備比我豐富好幾千倍。」有醫生編了幾個病例讓DeepSeek給出診療意見和治療方案,DeepSeek給出的方案「毫無錯誤,思考全面而且專業」。網友「自來水」地曬使用體驗,這一現象不禁讓人想起2022年底OpenAI啱啱發布ChatGPT後,大家爭先恐後試用並「秀對話框」的場景。
黑神話悟空的創始人馮驥也在微博發文評價DeepSeek。他說自己已經使用V3一個月了,最新發布的R1則啱啱使用5天。馮驥認為「DeepSeek可能是個國運級別的科技成果」,不僅強大、便宜、免費,而且開源,任何人都可以自行下載和部署,提供論文詳細說明訓練步驟與竅門。「深度求索是一家很小規模的年輕中國公司,由沒有海外經歷甚至沒有自身從業經驗的本土團隊開發完成。」馮驥說,「太幸運了!太開心了!這樣震撼的突破,來自一個純粹的中國公司。」

值得注意的是,DeepSeek暫時是目前唯一支持聯網搜索的推理模型,這使得DeepSeek的回答能夠結合最新的互聯網數據,相較其他模型準確性更強。記者實測發現,當讓DeepSeek寫一份其創始人梁文峯的簡歷時,它不僅能梳理出梁文峯的基本信息、在浙江大學的教育背景以及量化投資領域的職業經歷,還能抓取到梁文峯「2025年1月受邀參加國務院總理座談會,代表AI領域建言獻策」的最新媒體報道。

DeepSeek衝擊算力股
作為「國產大模型之光」,DeepSeek不僅引發了硅谷的震動,也讓華爾街陷入了恐慌。受此影響,美股科技巨頭股價盤前集體大跌,英偉達跌超8%,超威半導體一度跌超5%,台積電一度跌逾8%,博通跌近9%。除此以外,歐洲股市方面,光刻機巨頭阿斯麥跌近10%;日本股市方面,英偉達的主要供應商Advantest Corp.一度暴跌超8%。
A股方面,AI算力指數今日跌3.94%,寒武紀一度跌10%,中際旭創跌超10%,工業富聯跌超8%。值得注意的是,被稱為「英偉達影子股」的高速銅纜概念股沃爾核材,以及英偉達BlackwellGB200供應商英維克今日也雙雙跌停。

DeepSeek的成功對算力板塊構成了巨大的衝擊。分析人士認為,DeepSeek在有限的硬件資源下實現頂尖的模型性能,減少了對高端GPU的依賴,低廉的訓練成本預示着AI大模型對算力投入的需求將大幅下降。
值得注意的是,就在前幾天,啱啱上任的美國總統特朗普宣佈,OpenAI、軟銀集團和甲骨文將合資成立一家名為「星際之門」(Stargate)的新公司,計劃未來四年在美國投資5000億美元建設AI基礎設施,其中1000億美元將立即部署。該項目是歷史上最大的AI基礎設施項目,因投資金額之巨大,也被稱為美國的「AI曼哈頓計劃」。
除此以外,美股科技巨頭最近一段時間也公布了高額的AI資本開支計劃。例如,微軟宣佈投入800億美元用於AI數據中心建設,Meta的創始人扎克伯格最近也表示,Meta正在建設一個2GW+數據中心,將擁有超過130塊GPU,計劃今年將投入600億美元—650億美元用於AI資本開支。
DeepSeek讓人們開始質疑大規模算力基建投入的效用。美股大V「THESHORTBEAR」在社交媒體上表示,「DeepSeek創造了一個AI巨頭們的痛苦時刻,而投資者必須對此敲響警鐘。」由於美股過去兩年狂飆猛進,背後其實是AI浪潮下「美股科技七姐妹」以及英偉達支撐的主要結果,華爾街擔心DeepSeek可能會對美國股市構成衝擊。
記者向DeepSeek提出了「DeepSeek利空算力嗎?」這一問題,有意思的是,DeepSeek給出的結論是,「算力需求將長期增長,但市場結構將重塑。」它進一步解釋稱,DeepSeek的算法優化可能短期內抑制訓練端的高端GPU需求,但應用端的爆發將推動推理算力需求增長。類比「發動機效率提升反而增加石油需求」,算力總需求可能隨AI普及而擴張,因此短期局部利空,但長期整體利好。

至於對產業鏈的衝擊尤其是對英偉達和OpenAI的影響,DeepSeek表示閉源模型將(如OpenAI)面臨開源社區的競爭壓力,其API商業價值可能被稀釋;英偉達在訓練端的優勢雖穩固,但推理端可能受AMD等廠商挑戰。同時,華為升騰、寒武紀等國產芯片廠商因適配DeepSeek獲得技術驗證機會,未來或受益於國產替代趨勢。
覆盤DeepSeek爆火的一周
事實上,DeepSeek並非「一夜爆火」,它的出圈早已有跡可循。去年年底,DeepSeek的全新系列模型DeepSeek-V3首個版本上線並同步開源。由於模型性能超越或媲美全球頂級的開源及閉源模型,同時訓練成本極低,DeepSeek-V3以史無前例的性價比被國內外一衆圈內大佬讚好。這是DeepSeek第一次在海外引起廣泛關注。
自上周末起,海內外關於DeepSeek的討論開始甚囂塵上,其導火索是DeepSeek一周前發布的最新模型DeepSeek-R1。記者梳理了一下DeepSeek-R1發布後的幾個重要時間線:
1月20日,DeepSeek-R1正式發布並同步開源模型權重。據官方介紹,DeepSeek-R1在後訓練階段大規模使用了強化學習技術(RL),在僅有極少標註數據的情況下,極大提升了模型推理能力。在數學、代碼、自然語言推理等任務上,性能比肩OpenAIo1正式版。由於對標海外先進模型的說法在國產大模型領域比較普遍,R1模型的發布當時並未引起太多人的重視。
1月21日至23日,由於DeepSeek在發布R1的同時還公布了技術報告《DeepSeek-R1:強化學習驅動的大語言模型推理能力提升》,AI界一些有影響力的人閱讀了DeepSeek的技術報告,並對此感到震撼。例如,英偉達高級研究科學家JimFan在讀完報告後表示,「我們正身處這樣一個歷史時刻:一家非美國公司正在延續OpenAI最初的使命——通過真正開放的前沿研究賦能全人類。看似不合常理,但最有趣的結局往往最可能成真。」DeepSeek開始在AI界小範圍引起討論。
1月24日至25日,紐約時報、金融時報等英美主流媒體開始大量報道DeepSeek,關注的焦點主要是中國的AI創業公司DeepSeek是否會撼動美國硅谷在人工智能領域的領先地位。其中,紐約時報發表了題為《中國的AI創業公司如何與硅谷巨頭競爭》的文章,文章指出,「中國可能通過開源主導權重構全球AI競爭格局,使低成本創新成為顛覆行業的新路徑」。
與此同時,DeepSeek的影響力開始向資本市場滲透。1月24日,知名投資人MarcAndreessen在社交平台表示,「DeepSeekR1是我見過的最令人驚歎,最令人印象深刻的突破之一,並且是開源的,是給全世界的禮物。」1月24日,英偉達股價大跌超3%。據媒體報道,JPM交易台當晚交易時95%的問題均和DeepSeek有關,交易員、分析師周末開始惡補關於DeepSeek的一切。
據擁有20年投資經驗的大V「TMTBreakout」總結,DeepSeek的爆火可能有四點原因,首先是社交平台X的算法推薦,其次是知名投資人MarcAndreessen的推文,再次是紐約時報的文章,最後是英偉達股價的下跌。DeepSeek的R1模型發布若干天后,纔在海外引起軒然大波,有業內人士分析稱,這側面表明中國本土的AI科研走到了技術的最前沿。
責編:葉舒筠
校對:王錦程
責任編輯:丁文武