原標題:來自中國的大模型成最大黑馬,成本僅國外三十分之一,硅谷恐慌
「Meta的生成式AI部門正處於恐慌中。這一切始於 Deepseek,它使得 Llama 4 在基準測試中已經落後。雪上加霜的是:那個不知名的中國公司,僅有 550 萬美元的訓練預算。工程師們正在瘋狂地剖析 Deepseek,並試圖從中複製一切可能的東西……」
一位Meta的工程師在美國科技公司員工社區Blind中這樣寫道。
5天前,中國的一家AI大模型創業公司DeepSeek(深度求索)正式發布 DeepSeek-R1大模型。在發布聲明中,DeepSeek表示, DeepSeek-R1在數學、代碼、自然語言推理等任務上,性能比肩 OpenAI o1 正式版。這一消息震動了全球AI圈。
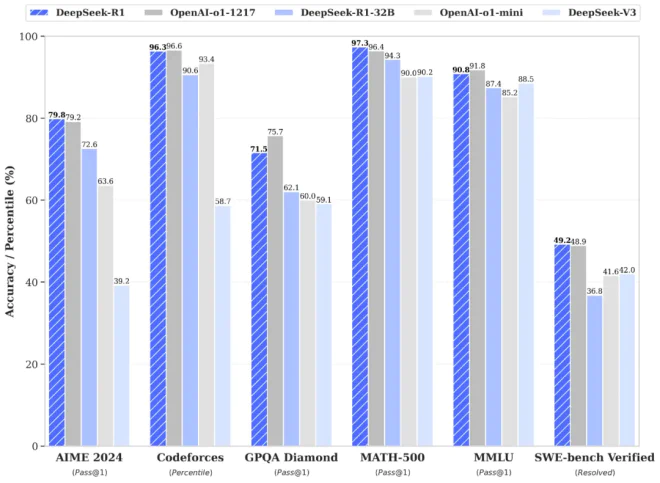
例如,在AIME 2024數學基準測試中,DeepSeek-R1的得分率為79.8%,而OpenAI-o1的得分率為79.2%。在MATH-500基準測試中,DeepSeek-R1的得分率為97.3%,而OpenAI-o1的得分率為96.4%。在編碼任務中,DeepSeek-R1超過了96.3%的人類選手,而o1是96.6%。
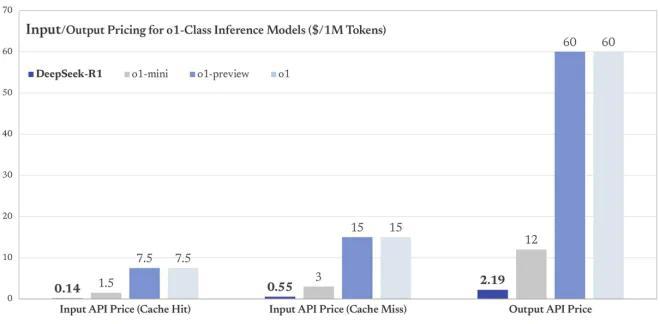
一樣好用,但成本不到三十分之一
這個來自中國的大模型,雖然各項指標往往只是與國外的競品「相當」,最多也只是「略強」,但它的低成本,以及在算力資源上的節省,仍然令國外同行在《自然》雜誌上驚呼:「這太瘋狂了,完全出乎意料」。
DeepSeek 現在尚未公布訓練 R1 的完整成本,但它公布了API的定價,每百萬輸入 tokens 1 元(緩存命中)/ 4 元(緩存未命中),每百萬輸出 tokens 16 元。這個收費大約是 OpenAI o1運行成本的三十分之一。
在低價優質的基礎上,DeepSeek-R1還實現了部分開源。官方聲明同步開源了模型權重,允許研究者和開發者在自己的項目中自由使用該模型,或在其基礎上進行進一步的研究和開發。DeepSeek-R1系列支持商業用途,並且允許用戶對模型進行任何形式的修改和衍生創作。同時,DeepSeek-R1對用戶開放思維鏈輸出,這意味着我們能直接看到它以文本形式輸出的「思考」過程。
去年 12 月底,DeepSeek發布的DeepSeek-V3已經引起過一次AI圈的震動。它的性能GPT-4o和Claude Sonnet 3.5等頂尖模型相近,但訓練成本極低。整個訓練在2048塊英偉達H800 GPU集羣上完成,僅花費約557.6萬美元,不到其他頂尖模型訓練成本的十分之一。
GPT-4o等模型的訓練成本約為1億美元,至少在萬個GPU量級的計算集羣上訓練,而且使用的是性能更為優越的H100 GPU。例如,同為頂尖大模型,去年發布的Llama 3.1在訓練過程中使用了16,384塊H100 GPU,消耗了DeepSeek-V3 11倍的計算資源,成本超過6000萬美元。
隨着大模型的競爭越來越卷,去年OpenAI、Meta、Google以及馬斯克的xAI,各大AI巨頭都開始打造自己的萬卡(GPU)集羣,萬卡集羣似乎成了訓練頂尖大模型的入場券。但DeepSeek卻用不到十分之一的資源打造出性能相近的大模型,這讓習慣了資源競賽的硅谷AI界人士感到意外。
DeepSeek-V3發布後,英偉達高級研究科學家Jim Fan曾在社交媒體上表示,「DeepSeek是本年度開源大語言模型領域的最大黑馬」。
硅谷人工智能數據服務公司Scale AI的創始人亞歷山大·王(Alexander Wang)則在社交媒體上直言不諱地表達了對中國科技界追趕美國的擔憂。他認為DeepSeek-V3的發布,是中國科技界帶給美國的苦澀教訓。「當美國休息時,中國(科技界)在工作,以更低的成本、更快的速度和更強的實力趕上。」
而今年年初DeepSeek-R1發布後,硅谷科技界的評價依然很高。亞歷山大·王認為「我們發現,DeepSeek……是表現最好的,或者大致與美國最好的模型相當,這個領域的競爭越來越激烈,而不是越來越少」。
Jim Fan的評價更上一層樓,甚至討論起了DeepSeek「接班」OpenAI的話題。相比依靠閉源構築護城河的OpenAI,他在社交網站上表示「我們生活在這樣一個時間線上,一家非美國公司正在維持 OpenAI 的原始使命——真正開放、前沿的研究,賦予所有人力量。這看似不合邏輯,但最有趣的結果往往最容易發生」。
在基準測試中的得分未必能完全代表大模型的真實能力,科學家們對R1的能力持更為謹慎的態度。目前,科學家們已經開始對R1進行更深入的測試。
德國埃爾蘭根馬克斯·普朗克光學研究所人工智能科學家實驗室負責人馬里奧·克倫,讓OpenAI o1和DeepSeek-R1兩個競爭模型對3,000個研究想法按照其有趣程度進行排序,並將結果與人類的排序進行了比較。在這個評估標準上,R1的表現略遜於o1。然而,她指出R1在某些量子光學計算任務中表現優於o1。
不走尋常路
引起AI圈好奇的,除了DeepSeek-R1性能表現和低成本,還有技術論文中展示的,DeepSeek團隊對於AI訓練方法的新嘗試。
以往的模型在提升推理能力時,通常依賴於把監督微調(SFT)這個環節。在監督微調階段,研究人員會使用大量已標註的數據對預訓練的AI模型進行進一步訓練。這些數據包含了問題及其對應的正確答案,以及如何建立思考步驟的範例。靠着這些模仿人類思維的「例題」和「答案」,大模型得以提升推理能力。
DeepSeek-R1訓練過程中的DeepSeek-R1-Zero路線則直接將強化學習(RL)應用於基礎模型。他們的目標是探索大模型在沒有任何監督數據的情況下,通過純強化學習過程進行自我進化,從而獲得推理能力。
團隊建立了兩條最簡單的獎勵規則。一條是準確性獎勵,對了加分錯了減分。另一條是格式要求,模型要把思考過程寫在<think>和</think>標籤之間,類似於考試中我們必須把答案寫在答題框裏。不靠「例題」,只讓AI這個「學生」以自己的方式學會做推理。
從基準測試的成績看,DeepSeek-R1-Zero 無需任何監督微調數據即可獲得強大的推理能力。在AIME 2024基準測試裏,使用多數投票機制時的DeepSeek-R1-Zero達到86.7%準確率,高過OpenAI o1。
在訓練OpenAI o1這個級別的推理模型這個任務上,DeepSeek-R1是首個直接強化學習證明這一方法有效的模型。
艾倫人工智能研究所(Allen Institute for AI)的研究科學家內森·蘭伯特(Nathan Lambert)在社交媒體上表示,R1的論文「是推理模型研究不確定性中的一個重要轉折點」,因為「到目前為止,推理模型一直是工業研究的一個重要領域,但缺乏一篇具有開創性的論文[5]。」
中山大學集成電路學院助理教授王美琪解釋稱,直接強化學習方法與 DeepSeek 團隊在多版模型迭代中的一系列工程優化技術(如簡化獎懲模型設計等)相結合,有效降低了大模型的訓練成本。直接強化學習避免了大量人工標註數據的工作,而獎懲模型的簡化設計等則減少了對計算資源的需求。
DeepSeek-R1 的成果顯示,大規模運用直接強化學習,而非依賴大模型經典訓練範式(如採用預設思維鏈模版和監督微調)是可行的。這為大模型訓練提供了更高效的思路,有望啓發更多研究人員和工程師沿着這一方向進行復現與探索。DeepSeek 還開源模型並提供了詳細技術報告,也有助於他人快速驗證和拓展該方法。
「從核心原理上來講,DeepSeek的大部分訓練技巧在AI發展過程中都有跡可循,但其所揭示的直接強化學習的巨大潛力,以及訓練過程中自反思和探索行為的湧現,對大模型高效訓練乃至人類學習模式的探索都有很大啓發意義。」相關研究人員表示。
這個大模型能為中國的AI行業帶來什麼?
對於DeepSeek,《自然》雜誌指出:儘管美國出口管制限制中國公司獲得為人工智能處理而設計的最佳計算機芯片,但它還是成功製造了(DeepSeek的) R1。
在硅谷,人們將這個節省算力的中國大模型稱作「來自東方的神祕力量」,從《紐約時報》到《連線》《福布斯》幾乎所有的媒體都在說:美國對先進半導體的出口管制旨在減緩中國人工智能的發展,但這可能無意中刺激了創新。」
那麼,這樣一個節省算力的大模型會成為中國針對AI芯片禁運的解法嗎?
一位人工智能領域的專家告訴《知識分子》:最終,「還是需要把芯片搞上去。」
算力困境仍在,然而,這樣一個極度節省算力的大模型的出現仍然給中國的大模型們帶來了新的希望——除了算力,我們可以依靠的還有優化。正如《自然》雜誌上引用的華盛頓西雅圖的人工智能研究員 François Chollet 的評價:「這一事實表明,高效利用資源比單純的計算規模更重要。」
《福布斯》則指出,它讓世界認識到,「中國並未退出這場(人工智能的)競賽。」
這個來自中國的大模型讓人們看到了從構架、算法上進行優化的潛力,幾乎是以一己之力扭轉了全球大模型領域對算力的瘋狂追逐,為無數的小公司帶來了新的機會。
《自然》雜誌說,DeepSeek的V3訓練時只花了不到600萬美元,而Meta訓練其最新人工智能模型Llama 3.1 405B時所耗資金超過6000萬,《紐約時報》說:「有600萬美元資金的公司在數量上遠遠多於有1億美元或10億美元資金的公司」。
效率之外,DeepSeek另一個常被誇讚的亮點是開源。Reddit上,人們讚嘆DeepSeek「開源、而且可以本地運行」,「我一定要下載一個到我的電腦上」。
開源,這意味着這個模型的研發者將不僅只與自己的同事合作,他們「其實在與世界各地最優秀的同行合作」,《紐約時報》說,「如果最好的開源技術來自中國,美國開發人員將在這些技術的基礎上構建他們的系統。從長遠來看,這可能會讓中國成為研發人工智能的中心。」
當然,引領整個生態,那是遙遠的未來,開源,更為直接的,肉眼可見的一個影響是:「一個開源又好用的AI,它會迅速佔領學術界的」,前述人工智能相關專家告訴《知識分子》。