
作者 | 徐豫
編輯 | 漠影
智東西1月29日報道,國產AI之光DeepSeek-R1正快速平替OpenAI、Meta、Google的模型,成為應用開發者的新選擇。
該模型在知名AI開源社區Hugging Face上的下載量已超70萬次,日增40%。
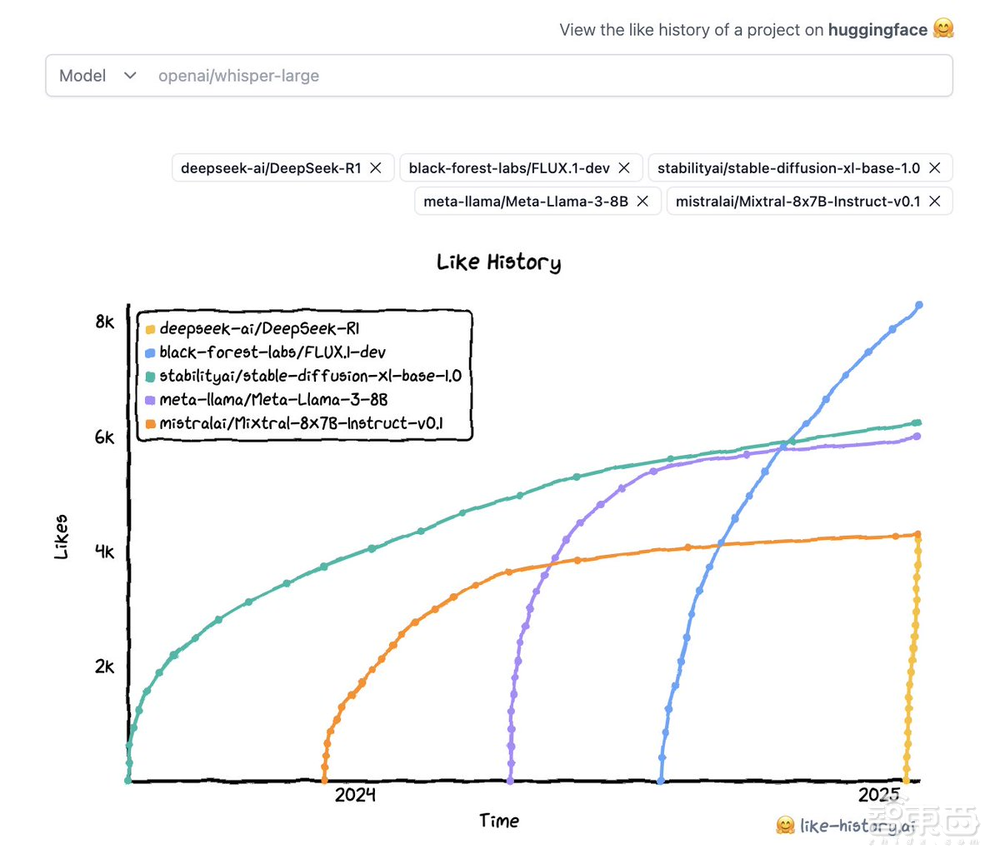
▲DeepSeek-R1躋身Hugging Face最受喜愛的模型前十名(圖源:Clem Delangue X主頁)
不過,DeepSeek強勁的增長勢頭,也引起了美方的高度關注。
今日凌晨CNBC報道稱,美國海軍基於「潛在安全和道德問題」,已要求內部人員禁止使用DeepSeek模型。
據玉淵譚天消息,昨天,美國多名官員回應DeepSeek對美國的影響,稱其「蒸餾」技術是「偷竊」,正對其影響開展國家安全調查。
同日,DeepSeek官網的服務狀態頁面顯示:「近期DeepSeek線上服務受到大規模惡意攻擊,註冊可能繁忙,請稍等重試。已註冊用戶可以正常登入,感謝理解和支持。」玉淵譚天向奇安信安全專家諮詢並獨家了解道,DeepSeek這次受到的網絡攻擊,IP地址都在美國。

截至發稿,在Chatbot Arena大模型排行榜中,DeepSeek-R1基準測試排名已升至全類別大模型第二,超過OpenAI的o1和o1-mini模型,僅次於Anthropic的Claude3.5 Sonnet,熱度持續攀升。
一、DeepSeek衍生模型數量日增30%,下載量超320萬
Hugging Face首席科學官Thomas Wolf今天接受彭博社採訪時,透露了DeepSeek-R1開源模型上線一周後增勢強勁,並且該公司有計劃在DeepSeek-R1的基礎上,自研開源項目Open-R1。
Hugging Face社區內的開發者們正在公開復現DeepSeek-R1。主頁的135萬個模型中,檢索「DeepSeek」相關的模型有將近2700個。
Hugging Face聯合創始人兼CEO Clem Delangue 1月28日發帖稱,DeepSeek-R1的衍生模型至少有500種。
Thomas Wolf今天給出了最新數據,用DeepSeek-R1搭建的模型至少有670個,累計下載量超320萬次,日增約30%;而DeepSeek-R1的下載量超過70萬次,日增40%。
據Clem Delangue透露,DeepSeek-R1已進入該社區史上最受喜愛的模型前十名之列。
截至1月29日,Hugging Face社區讚好數排行前十的AI模型依次是:
1、黑森林實驗室的FLUX.1-dev
2、CompVis的stable-diffusion-v1-4
3、Stability AI的stable-diffusion-x1-base-1.0
4、Meta的Llama-3-8B
5、BigScience的bloom
6、Stability AI的stable-diffusion-3-medium
7、DeepSeek的DeepSeek-R1
8、Mistral AI的Mixtral-8x7B-Instruct-v0.1
9、Meta的Llama-2-7B
10、Meta的Llama-2-7B-chat-hf
二、Hugging Face開搞Open R1,要研究透DeepSeek
跟上衆多開發者的潮流,Hugging Face也打算基於DeepSeek-R1復刻一套自己的新模型,即Open-R1項目。
據Hugging Face官網1月28日介紹,Open-R1項目將重建DeepSeek-R1的數據和訓練管道,並在這個過程中驗證其效果、突破其上限,從而增強推理的透明度,以及積累可複製的經驗。
不同開發商的復刻方法不盡相同。針對DeepSeek-R1遺留的特定推理數據收集方法、未公開模型訓練代碼、訓練時的計算和數據縮放定律等問題,Open-R1計劃通過以下步驟補齊這些空白板塊:
首先,從DeepSeek-R1中提取高質量推理數據集,來複制R1-Distill模型。
然後,複製DeepSeek用於創建R1-Zero的純RL管道,這個過程將涉及為數學、推理和代碼任務,整理新的大規模數據集。
最後,可以通過多階段訓練,實現從基礎模型到SFT(監督微調),再到RL(強化學習)的模型進階。
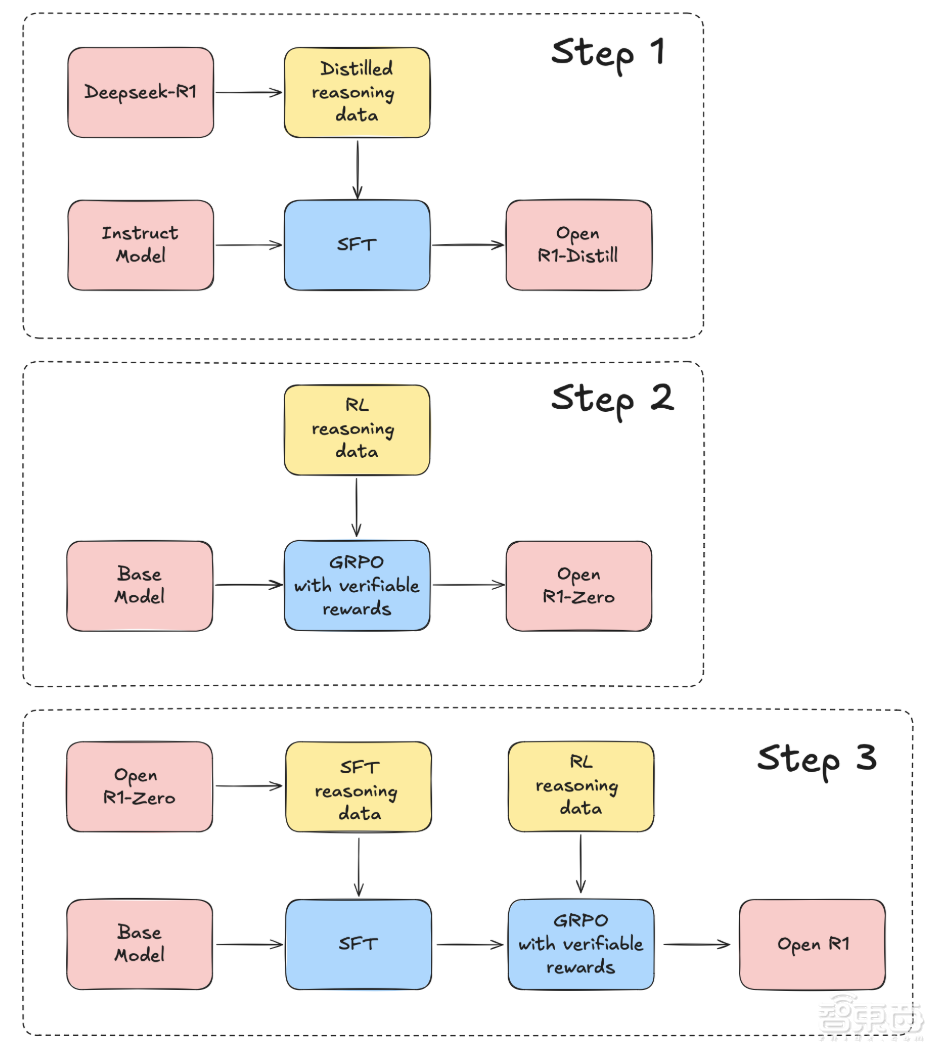
▲Open-R1復刻DeepSeek-R1的計劃示意圖(圖源:Hugging Face官網)
按照Thomas Wolf的預期,其團隊將在接下來的幾個月內弄清楚這些細節問題,並應用於Open-R1項目。
三、谷歌前CEO:全球AI的轉折點已經到來
這場有關DeepSeek的硝煙,不僅僅籠罩了OpenAI、Meta、Google等一衆主流模型開發商,使其着手研究如何降低模型的開發成本;也進一步蔓延至中美兩國的AI博弈大局。
不到兩周前,美國商務部工業和安全局(BIS)才頒佈了芯片出口限制最新規定。其中,BIS共拉黑了11家與先進AI技術有關的中國實體。
在The Verge昨晚的報道中,OpenAI前政策研究員Miles Brundage稱,像DeepSeek-R1這種推理模型通常需要使用大量GPU,會受到美國芯片出口管制的干擾。
在Miles Brundage看來,DeepSeek-R1使用了兩個關鍵的優化技巧,一是更高效的預訓練,二是思維鏈推理強化學習,這在一定程度上使其能以更少的GPU數量、更便宜的GPU,推動DeepSeek-R1實現了更強大的性能。因此,Miles Brundage稱,美國對GPU實施有效的出口管制,比以往任何時候都更為重要。
不過,OpenAI首席研究官Mark Chen則傾向於外界誇大了DeepSeek-R1的成本優勢。他一方面認可了DeepSeek獨立開發出了OpenAI o1級別的推理模型,但另一方面認為兩者在開發成本上的差距並沒有那麼大,仍然對OpenAI的技術路線持樂觀態度。因此,從某種意義上說,DeepSeek還是有被先進GPU卡脖子的風險。
另外,有不少觀點認為DeepSeek-R1的出現將惠及部分美國科技巨頭。
《華爾街日報》1月27日報道稱,DeepSeek-R1的技術突破意味着,不少美國科技巨頭可能不必花費太多時間、精力和算力,來訓練他們的AI模型。
而且這些模型都是開源的,開發人員可以檢查和修改其代碼,並用它來構建自己的應用程序。這可以幫助更多小企業花費比閉源模式低得多的成本,用上AI,並且開源可以促進更多合作和實驗。
摩根士丹利分析師Brian Nowak稱,蘋果也將因DeepSeek等大模型的任何進展中受益匪淺,原因是蘋果「擁有現存最有價值的消費技術分發平台」。
谷歌前CEO Eric Schmidt昨天告訴《華盛頓郵報》,他認為美國需要加大開源AI研發力度,開發出更多開源模型,鼓勵先進AI實驗室共享訓練方法,以及投資星際之門等AI基礎設施,以應對DeepSeek的迅速發展。
Eric Schmidt還一改去年「美國領先」的說辭,在《華盛頓郵報》專欄文章中稱,DeepSeek的崛起標誌着全球AI「轉折點」的到來,證明了中國可以用更少的資源與大型科技公司競爭。
結語:國產模型出圈新路線,Meta、Hugging Face等爭相模仿
目前,有的團隊和機構正在研究、復刻DeepSeek-R1,有的嘗試用該模型重塑自家模型,例如Meta、Hugging Face、UC伯克利、港科大等。
同時,2025年開年,DeepSeek-R1將推理模型競賽推向新拐點,有望憑藉低算力、高性價比的技術路線,開拓國產模型的全球市場。
春節期間DeepSeek掀起的這場AI風暴,仍在中美乃至全球科技、政金界產生持續影響,並不斷髮酵。這已經成為改變AI科技產業趨勢的風向標事件,智東西將持續跟進相關進展和報道,敬請關注。