
作者|硅星人Pro 張瀟雪
在開源上我們站在了歷史的錯誤一方。
這是Sam Altman對DeepSeek衝擊做出的最新回應。
OpenAI從來都是主動出擊,這一次因DeepSeek而被動調整了它自己的節奏,甚至第一次在開源權重的問題上,有了動搖。
一切都發生的太快了。
o3-mini全線開放,免費用,可聯網
在DeepSeek壓力之下, OpenAI今天凌晨突然宣佈,其最新推理模型o3-mini全面上線。
而且居然一改往日藏着掖着的調性,一次性向所有人開放了o3-mini在ChatGPT和API中的使用權限,包括免費用戶。
不僅支持聯網,也終於捨得展示思考過程了。
o3-mini 於去年底的技術直播中首次亮相,是 OpenAI 推理系列中最新、最具性價比的小型 AI 模型,在科學、數學和編程領域表現出色,同時兼具低成本和低延遲優勢。
強度模式上,o3-mini提供了低、中、高三種選擇,用戶可根據需求在快速響應和深度思考之間靈活調整。只是o3-mini 尚不支持視覺任務,需要進行視覺推理時仍要調用o1。
此次發布,ChatGPT Pro 用戶可無限制訪問 o3-mini;Plus 和 Team 用戶每日消息限制從 o1-mini 的50條提升至150條;免費用戶也可通過選擇「Reason」模式或重新生成回覆來體驗新模型(具體消息限制未說明)。所有付費用戶還可在模型選擇器中選擇 「o3-mini-high」,以獲得需要更長時間響應的更高智能版本。
此前曾被社區貼臉對比DeepSeek有而 OpenAI 沒有的深度思考 + 聯網功能,這次也高亮加入:所有用戶均可選擇 「Search + Reason」 組合,利用搜索功能查找帶有相關網絡資源鏈接的最新答案。
來到開發者這邊。即日起,API 使用等級 3-5 的開發者可在Chat Completions API、Assistants API 和 Batch API 中調用o3-mini。OpenAI稱它是自己首款支持函數調用、結構化輸出和開發者消息的小型推理模型,可直接用於生產環境。
變快變便宜,但仍不如DeepSeek實惠
速度與效率方面,o3-mini 相較於o1具備更快的響應速度和更高的計算效率。測試結果顯示,o3-mini推理速度比o1-mini快24%,將平均響應時間從10.16秒縮短至7.7秒。此外,o3-mini 的首個token生成時間也比o1-mini快2500毫秒,為用戶提供更加流暢的交互體驗。
而面對「模型界拼多多」DeepSeek,OpenAI也不得不加入了價格戰。官方表示,自 GPT-4 推出以來,OpenAI 已將每 token 價格下調 95%。
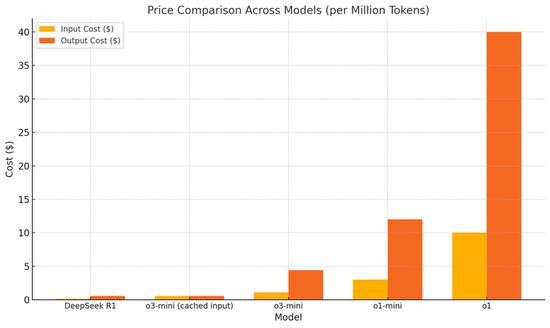
最新的定價方案中,o3-mini輸入每百萬tokens收費$1.10,輸出每百萬tokens收費$4.40,在使用緩存輸入的情況下,費用可以減半至每百萬tokens $0.55。
這個價格相比之前有了顯著下降,比o1-mini低63%,比完整版o1更是降低了93%。然而即便如此,與DeepSeek R1輸入和輸出費用分別為每百萬tokens $0.14和$0.55相比,仍然明顯偏高。
性能超o1,採用「審慎對齊」技術
OpenAI在官方博客中展示了o3-mini在多個領域相比o1和o1-mini的性能提升。
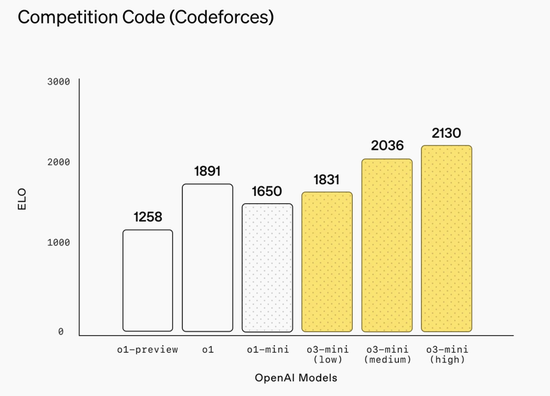
數學推理方面,o3-mini於AIME 2024數學競賽中表現優異。使用高推理強度時,其準確率達到87.3%,全面超越o1。即便在低推理強度模式下,其表現也能與o1-mini比肩。
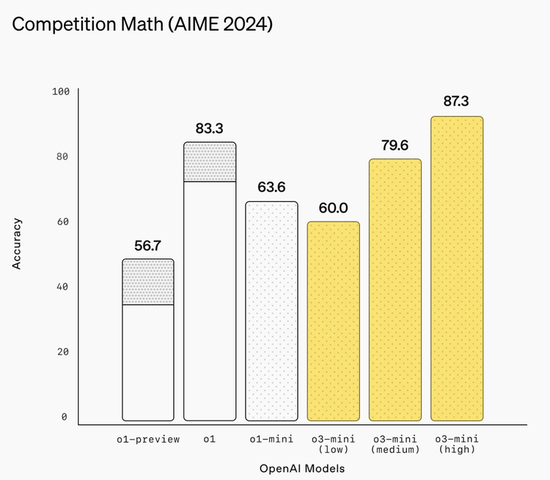
在科學領域評測中,o3-mini的高推理強度模式在PhD級科學問題(GPQA Diamond)上達到79.7%的準確率,顯著優於前代模型。在生物、化學和物理等高難度學科問題上,其高推理強度模式的表現與o1相當。
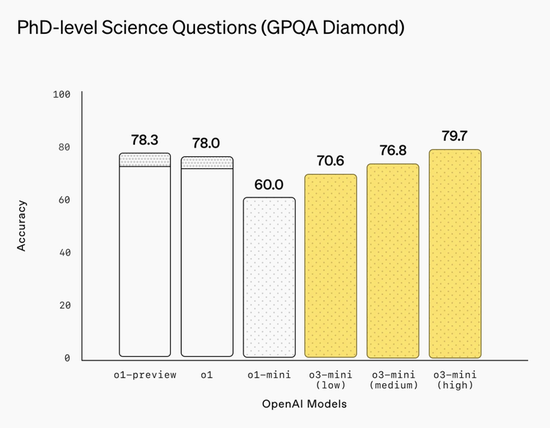
編程能力方面,o3-mini這次展現出了肉眼可見的顯著優勢。在Codeforces編程競賽中,其高推理強度模式獲得2130的Elo評分,遠超前代模型,即使最低推理強度也與o1持平。在SWEbench-verified軟件工程測試中,高推理強度模式達到49.3%的準確率。在LiveBench編程任務中,中等推理強度已超越o1-high,高推理強度模式則更是大幅領先。
在一般知識評估中,o3-mini全面超越o1-mini。同時,人類偏好測試顯示,56% 的專家更傾向於選擇 o3-mini 的回答,認為其更準確且邏輯性更強。此外,o3-mini 在處理現實世界高難度問題時,主要錯誤率下降了 39%,凸顯了其在複雜任務中的可靠性。
安全性方面,OpenAI表示在o3-mini的安全性工作上取得了重要進展。最顯著的是採用了他們開發的審慎對齊」(deliberative alignment)技術,讓o3-mini能在回答用戶問題前,主動對安全規範進行推理思考。這種方法使其在應對各種安全挑戰和越獄測試時的表現明顯優於GPT-4o。
為確保安全性,o3-mini採用了與o1同樣嚴格的流程,包括準備度評估、外部紅隊測試 等多個環節。評估結果顯示,o3-mini 的總體風險等級被評為 「中等」,其中在說服力、危險物質、模型自主性等方面風險為中等,而在網絡安全領域的風險則為低。通過強化 「思維鏈」推理能力,o3-mini 在處理潛在風險場景(如非法建議和偏見回應)時達到了目前的最高安全水平。

值得注意的是,隨着模型能力的不斷提升,OpenAI也意識到了潛在風險的增加。為此他們建立了完善的安全評估和防護體系,確保只有經過安全處理且風險達到中等或更低的模型纔會被部署。
奧特曼領銜,OpenAI團隊上陣Reddit開版答疑
o3-mini發布後,OpenAI CEO Sam Altman帶領首席研究員Mark Chen、首席產品官Kevin Weil、工程副總裁Srinivas Narayanan、API 研究主管Michelle Pokrass,和o3-mini團隊研究主管Hongyu Ren,上陣Reddit和網友們來了場互動Q&A。

下面是幾個讚好排名靠前的問題:
問題1:我們能看到所有的思維tokens嗎?
回答(Sam Altman):是的,我們將很快展示一個更有幫助和詳細的版本。感謝r1提醒我們。
問題2:你們會考慮發布一些模型權重和發表一些研究嗎?
回答(Sam Altman):這個還在討論中。我個人認為在這個問題上我們站在了歷史的錯誤一方,需要找出一個不同的開源策略。不過不是所有OpenAI的人都同意這個觀點,而且目前這也不是我們最高優先級。
問題3:完整版o3什麼時候發布?
回答(Sam Altman):我估計超過幾周,少於幾個月。
問題4:語音模式會更新嗎?這是GPT-5o的一個重點嗎?GPT-5o的大致時間表是什麼?
回答(Sam Altman):語音模式更新即將到來!我想我們會直接叫它GPT-5而不是GPT-5o。目前還沒有時間表。
問題5:你們會推出基於4o的圖像生成器嗎?
回答(Kevin Weil):是的!我們正在開發。而且我認為這值得等待。
問題6:你們計劃在未來推理模型中會添加文件附件功能嗎?
回答(Srinivas Narayanan):正在開發中。推理模型未來將能夠使用包括檢索在內的不同工具。
補充回答(Kevin Weil):我只想說,我迫不及待想看到帶工具使用的推理模型了:)
問題7:Stargate的成功對OpenAI的未來有多重要?
回答(Kevin Weil):非常重要。我們看到的一切都表明,計算能力越多,我們就能建立更好的模型,並製造更有價值的產品。我們現在同時在兩個維度上擴展模型——更大的預訓練和更多的強化學習/strawberry訓練,這兩者都需要計算資源。為數億用戶提供服務,並且隨着我們轉向更多為您持續工作的智能產品,這些也都需要計算資源。因此可以將Stargate視為我們的工廠,將算力/GPU轉化為令人驚歎的產品。
目前,大部分評論區羣衆表示喜聞樂見,「打起來了,愛看,多發!」

編程軟件Cursor算是手快的,最新兩條推文相繼宣佈DeepSeek模型和o3-mini都已經整合進來,但對平台的開發人員們仍然最愛Claude Sonnet「表示很驚訝」。
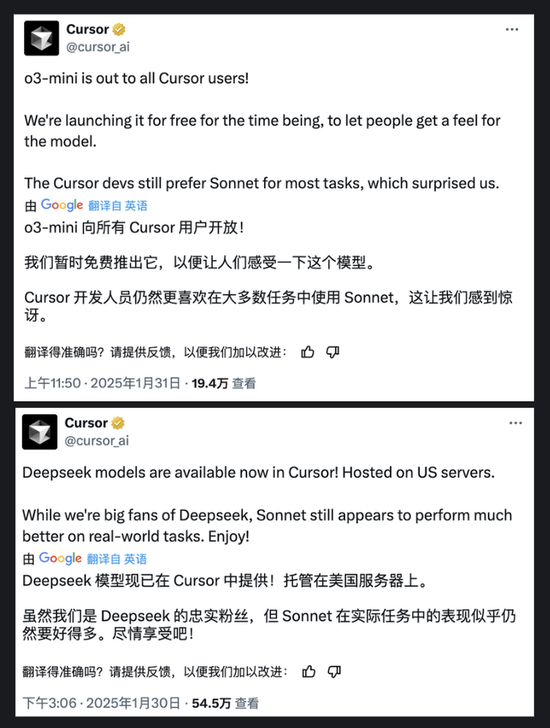
當然也有人表示,既然DeepSeek已經免費提供這些尖端AI技術了,為什麼要花錢升級GPT呢?
就像Lex Fridman說的,「OpenAI o3-mini是一個很好的模型,但DeepSeek R1的性能相似還更便宜,並且展示推理過程(目前大家反映o3-mini並沒像奧特曼說的那樣看到思維鏈顯示)。
儘管更好的模型將會出現(迫不及待地想看 o3pro),但‘DeepSeek 時刻’是真實存在的。我認為 5 年後它仍將作為科技史上的關鍵事件被人們銘記。」

責任編輯:韋子蓉