對人類而言,溝通至關重要。然而,全球有數以萬計的人因腦損傷而無法實現正常交流。
腦損傷是指腦組織的異常,可由神經系統疾病或創傷性腦損傷(TBI)引起,導致各種神經功能缺損。此前發表在《柳葉刀神經病學》的研究顯示,2021 年 全球有超過 30 億人患有神經系統疾病 ,如中風、阿爾茲海默症、腦膜炎、癲癇和自閉症譜系障礙等。此外,全球每年也約有 6900 萬人遭受着因道路交通事故等導致的創傷性腦損傷。
能否「修復」損傷的大腦,對於改善人類的日常生活和工作至關重要,且意義重大。
今天,Meta 公布了兩項重磅研究,他們聯合認知科學和神經科學頂尖研究機構巴斯克認知、大腦和語言中心(BCBL), 採用非侵入式方法利用 AI 解碼大腦語言、並進一步理解人類大腦如何形成語言 。這兩項突破性的研究成果也 使得高級機器智能 (Advanced Machine Intelligence, AMI) 更加接近實現 。
據介紹,第一項研究成功地通過非侵入式方法解碼了腦部活動中句子的生成,準確 解碼了多達 80% 的字符 ,也就是說可以完全通過大腦信號重建想表達的完整句子;第二項研究則詳細介紹了 AI 如何幫助理解這些大腦信號,並 闡明大腦如何有效地將思想轉化為一連串的文字 。
這不僅有助於幫助無法溝通的患者恢復語言能力,也幫助科學家加深對大腦處理語言和認知過程的理解,推動精度更高、更安全可靠的 腦機接口(BCI)的開發 。
01 從大腦活動到文本輸出:依靠非侵入式方法解碼
目前的方法表明,可以通過神經假體向 AI 解碼器輸入指令信號來恢復交流。然而,當前的立體定向腦電圖和皮層腦電圖等侵入式腦記錄技術需要神經外科干預,且難以推廣,非侵入式方法又通常受到其記錄信號的噪聲複雜性的限制。
在 第一項研究中 ,Meta 團隊提出了一種非侵入式方法來解碼大腦活動中的句子生成,並在 35 名腦部狀態健康的志願者中證明了其有效性。
他們 訓練了一個新的 AI 模型 ,可以解碼來自腦電圖(EEG)或腦磁圖(MEG)的句子 ,參與者則在 QWERTY 鍵盤上輸入簡短的句子。該 AI 模型可以解碼參與者用 MEG 記錄輸入的多達 80% 的字符,平均字符錯誤率(CER)為 32% ,大大優於傳統的 EEG(CER:67%)。對於表現最佳的參與者,該模型實現了 19% 的 CER,並且可以完美解碼訓練集之外的各種句子。
具體實驗設計如下:
參與者坐在投影螢幕前,MEG 和 EEG 分別距離眼睛 100 釐米和 70 釐米,鍵盤放在一個穩定的平台上。M/EEG 傳感器與鍵盤之間的距離為 70 釐米,確保參與者能以自然的姿勢打字。 每次實驗包括三個步驟:閱讀、等待、鍵入 。
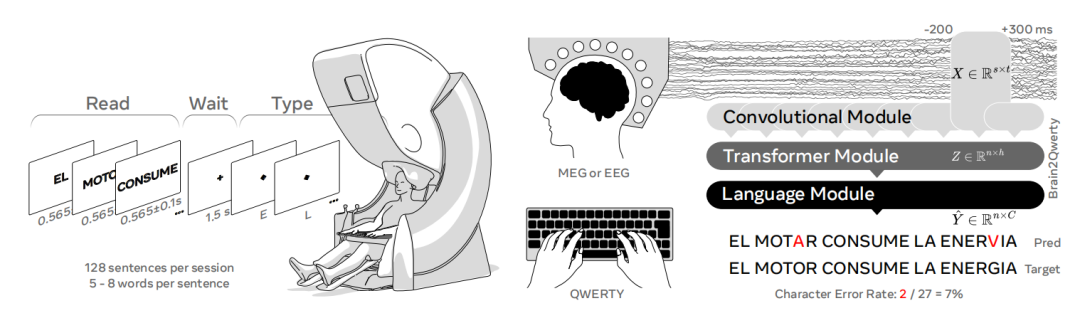
圖|鍵入實驗設計
首先,準備好的句子在參與者面前的螢幕上逐詞顯示,以黑色大寫字體呈現在 50% 灰色背景上,持續時間在 465 至 665 毫秒之間,單詞之間沒有間隔。其次,在每個句子的最後一個單詞消失後,螢幕上會顯示一個黑色的固定十字,持續 1.5 秒,參與者被要求在 1.5 秒內記住這個句子。當十字從螢幕上消失後, 參與者開始憑記憶輸入句子 。
在打字過程中,螢幕上不會顯示任何字母,但有最低限度的視覺反饋,即每按一次鍵,螢幕中央的黑色小方塊就順時針旋轉 10 度,有助於在不呈現按鍵輸入的情況下發出成功按鍵的信號,從而確保參與者最小化眼球運動。
參與者儘可能準確地鍵入句子,不使用空格糾錯,同時將注意力集中在螢幕中央,使用大寫字母且不帶重音。每次測試包括 128 個不重複的陳述性句子(西班牙語),每句話包含 5 到 8 個單詞,由定語、名詞、形容詞、介詞和動詞組成。在 EEG 中,參與者共輸入了 4000 個句子和 146000 個字符;在 MEG 中,共輸入了 5100 個句子和 193000 個字符。
接下來,他們對深度學習架構 Brain2Qwerty 進行了訓練,以解碼這些 M/EEG 信號中的單個字符 。Brain2Qwerty 則通過三個核心階段從大腦活動中解碼文本:(1) 一個卷積模塊(convolutional module),輸入的是 500 毫秒窗口的 M/EEG 信號;(2)一個在句子層面上訓練的 transformer 模塊(3)一個預訓練的語言模型 ,用來糾正 transformer 模塊的輸出。性能評估使用的是句子層面的 CER。

圖|參與者輸入與基於 MEG 解碼的文本結果(標紅為錯誤部分)
他們評估了平均字符錯誤率 ,結果顯示,Brain2Qwerty 在 MEG 和 EEG 上的錯誤率分別為 32±0.6% 和 67±1.5% ,反映了不同記錄設備之間的巨大差異,表現最好和最差的 EEG 受試者在不同句子中的 CER 分別為 61±2.0% 和 71±2.3%,表現最好和最差的 MEG 受試者在各句子中的 CER 分別為 19±1.1% 和 45±1.2%。
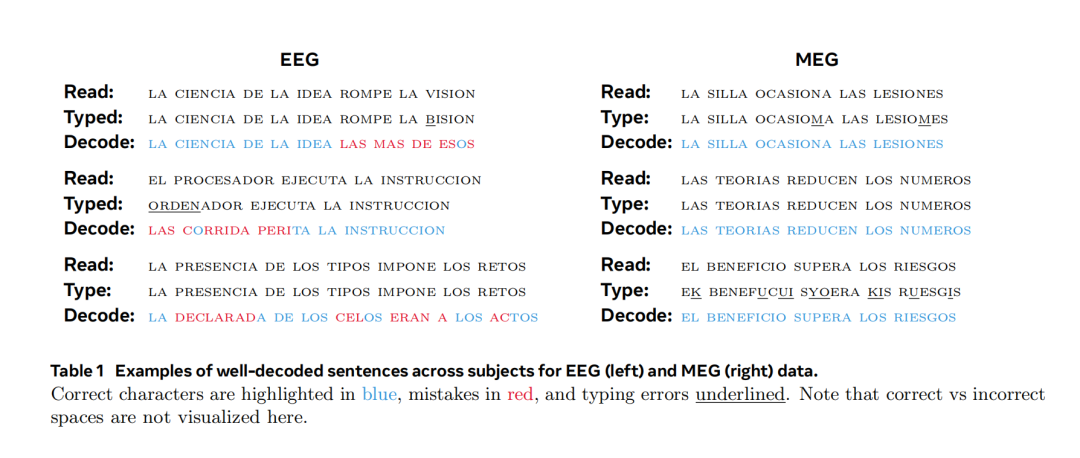
圖|解碼錶現較好的 EEG 和 MEG 文本對比,正確解碼字符標為藍色,錯誤為紅色
那麼,相比於經典的基線架構,Brain2Qwerty 的性能如何呢?
為了解決這個問題,他們 用同樣的方法訓練了線性模型和 EEGNet(一種用於腦機接口技術的流行架構) ,並通過跨受試者的 Wilcoxon 檢驗比較了它們與 Brain2Qwerty 的解碼性能。就 MEG 而言,EEGNet 在手誤率(HER)(p=0.008) 和 CER (p<10-4) 方面均優於線性模型,但就 EEG 而言,EEGNet 僅在 HER 方面優於線性模型(p=0.03)。然而, EEGNet 的效果仍然不如 Brain2Qwerty ,相比之下,Brain2Qwerty 在 EEG 和 MEG 的 CER 上分別提高了 1.14 倍和 2.25 倍。
該項研究結果表明,侵入式和非侵入式方法之間的差距縮小,這也為開發安全的腦機接口開闢了道路。
02 從思想到語言的轉化:層次化的表徵生成
第二項研究旨在理解協調 人類大腦語言生成的神經機制 。
研究說話時的大腦活動對神經科學來說一直極具挑戰性,部分原因是存在一個簡單的技術問題:移動嘴巴和舌頭會嚴重干擾神經成像信號。
為了探索大腦如何將想法轉化為複雜的運動動作序列,Meta 團隊使用 AI 幫助解釋參與者輸入句子時的 MEG 信號。 通過每秒拍攝 1000 張大腦快照,他們能夠精確定位思想轉化為單詞、音節甚至單個字母的準確時刻。
這一研究建立在第一項研究的輸入句子實驗基礎上,為了研究大腦何時以及是否會產生語言表徵的層次結構, 他們從這些信號(X)線性解碼了四個層次表徵的向量嵌入(Y) :上下文詞嵌入(使用 GPT-2),去上下文詞嵌入(使用 Spacy),音節嵌入(使用 FastText)以及字母(使用 One-Hot-Encoder,OHE),使用皮爾遜相關係數評估解碼性能。
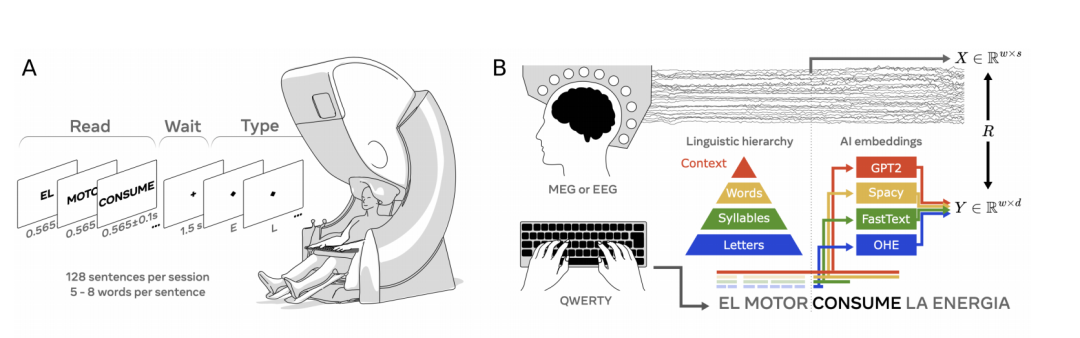
圖|左為實驗設計,右為解碼層次
研究結果表明, 大腦在產生語言時採用層次化的過程,首先生成上下文表徵,然後依次生成詞彙、音節和字母表徵 ,證實了語言理論的層次預測:大腦會產生一系列表徵,產生每個單詞之前的神經活動以上下文、單詞、音節和字母級表徵的連續上升和下降為標誌,並 逐漸將它們轉化為無數的動作 ,例如鍵盤上的實際手指運動。
此外,這項研究還揭示了大腦如何連貫而同時地表達連續的單詞和動作。研究結果表明,大腦 使用一種「動態神經代碼」 ——一種特殊的神經機制,它可以 鏈接連續的表達 ,同時在很長一段時間內保持每個表達。
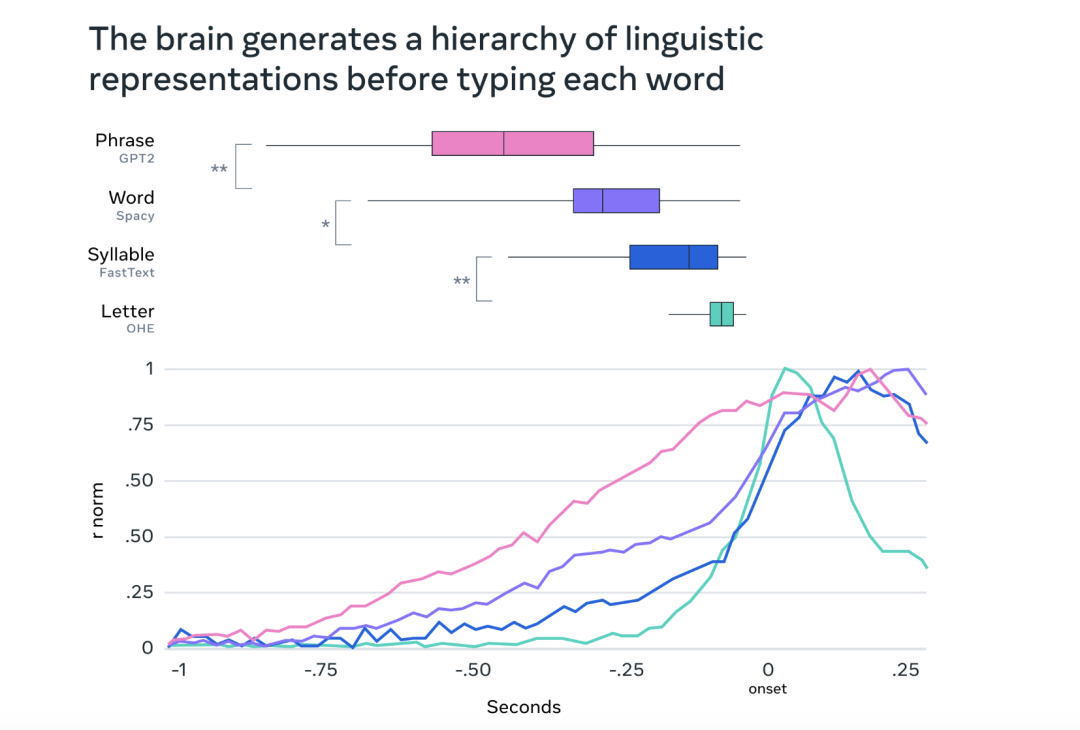
圖 | 輸入每個單詞前大腦產生的語言表徵層次
然而,Meta 團隊也表示,這些研究也存在一些侷限性。
例如,當前的 解碼性能仍不夠完善 ,線性解碼算法可能無法捕捉大腦活動的複雜性,需要更復雜的解碼算法;且還不適用於實時解碼,需要開發實時架構。在實用層面上,MEG 要求受試者處於磁屏蔽室中並保持靜止。此外,使用打字任務來探究語言產生的神經機制,可能無法完全反映自然語言產生的神經機制,研究也主要在健康的參與者中進行, 還需要進一步研究在腦損傷患者中的適用性 。
03 催生「無障礙交互」新範式
交流是人類活動的重要內容,用技術解決交流能力失去或缺陷的問題,一直是科技先驅關注的前沿。
近年來,全球腦機接口技術正在快速跨越科幻與現實的邊界。例如,侵入式腦機接口技術已在運動控制和語言解碼等方面取得突破,馬斯克的 Neuralink 公司利用 Link 芯片,使癱瘓患者能以意念操控機械臂完成複雜動作;而腦機接口與 AR/VR 融合的多模態交互技術也在不斷發展,Synchron 公司通過腦機接口操控 Apple Vision Pro 的案例,為消費級應用帶來了無限遐想。同時, 非侵入式腦機接口技術因無需手術、低風險的特點,更適合大規模應用 ,也取得了顯著進步。
此外,AI 模型的引入有望徹底提升解碼效率和優化醫療決策, 未來或能借助 LLM 實時解析腦電信號,將零散的神經活動轉化為連貫語言 ,甚至實現與外部 AI 系統的直接交互,從而 催生「無障礙交互」新範式 。
對此,你怎麼看呢?