
DeepSeek火爆出圈以來,其引發的蝴蝶效應還在加劇。
昨天(2月13日),百度官宣,文心一言將於4月1日0時起全面免費,所有PC端和App端用戶均可體驗文心繫列最新模型,以及超長文檔處理、專業檢索增強、高級AI繪畫、多語種對話等功能。
此外,文心一言即將在官網、App端上線的深度搜索功能,也將從4月1日起免費開放使用。

圖/百度官微
再到今天(2月14日),百度再次宣佈,未來幾個月,百度將陸續推出文心大模型4.5系列,並於6月30日起正式開源。
值得注意的是,同樣是在這兩天,從OpenAI到谷歌,也加大了大模型的開放力度,宣佈了旗下大模型產品免費開放的消息。
OpenAI也有望走向開源。據悉,目前OpenAI內部正討論公開AI模型的權重等事宜。
AI巨頭步調一致走向開源開放,釋放出了一個強烈信號:
大模型狂奔兩年後,大模型技術在B、C兩端的落地範式,湧現出了新變化,對大模型廠商提出了更高的要求——他們不僅要走在大模型技術的最前沿,也要在大模型應用爆發前夜,加速探索出大模型落地的降本路徑,率先搶跑。
百度文心大模型的開源開放,正是基於上述兩點。
一邊,過去兩年的大模型浪潮裏,百度是投入力度最大、技術迭代最快、B端產業落地和C端應用探索最廣、最深的AI企業之一。
截至2024年11月,文心一言的用戶規模為4.3億,文心大模型日均調用量超過15億次,較2023年增長了超過30倍。
另一邊,從模型推理到模型訓練,百度已經通過技術創新實現了成本的有效降低。
而當百度、OpenAI、谷歌等AI巨頭率先轉向,當更大限度的技術、生態開放成為產業共識,AI技術普惠,正加速照進現實。
01 從To C到TO B,開源開放為什麼成了大模型產業的必經之路?
引領此輪大模型開放開源潮的,不只百度一家。
2月6日,OpenAI宣佈ChatGPT Search向所有人開放,用戶無需註冊,來到OpenAI官網首頁就可以直接使用搜索功能。同一天裏,谷歌也宣佈,向所有人開放其最新的Gemini 2.0模型,包括Flash、Pro Experimental和Flash-Lite三個版本。
再到昨天,百度宣佈免費開放後,OpenAI快速跟進。 薩姆·奧爾特曼在社交媒體X上宣佈,OpenAI新的GPT-5大模型將對ChatGPT免費用戶無限量開放,不過更高智能版本的GPT-5仍需付費使用。
巨頭們統一擺出開放姿態,原因不難理解。
過去兩個多月裏,DeepSeek投向大模型產業的石子不斷泛起漣漪。DeepSeek-v3呈現出的大模型訓練上的低成本、DeepSeek-R1在模型推理上的低成本,以及DeepSeek應用所呈現出來的在思維邏輯、中文、編程等方面的驚豔能力,快速助推其成為春節前後最受全球矚目的AI公司。

而其展現出來的,以低算力成本復現先進模型的可能性、DeepSeek應用的爆發,某種程度上印證了一點:
大模型產業,當前已經進入到了需要開源開放的新階段。
客觀來看,開源和閉源,這兩條不同的技術路線並非完全對立,只是在產業發展的不同時期,會呈現出不同的特徵。
比如早期的模型開源更像是營銷,Meta旗下的Llama選擇了半開源,只開源了部分參數和配置文件,但這一定程度上反而會影響模型的可驗證性和可信度。
但到了今年,大模型在度過初步發展階段後,正加速進入AI應用爆發階段,這一階段,開源路線顯然更利於大模型技術傳播,提高採用率。
正如李彥宏所說,「歸根結底,最重要的是應用,而不是使用哪種大模型。不管它是開源還是閉源,更重要的是可以在應用層創造什麼樣的價值。」
比如在B端市場,《2024中國企業AI大模型應用現狀調研報告》指出,AI大模型在企業中的滲透仍處於初期階段,不過有55%已經部署了大模型的企業和機構認為,已經看到了大模型帶來的清晰業務價值。
問題在於,對很多企業尤其是中小企業而言,大模型落地過程中,成本、技術、人才和行業方案,仍然是幾個主要挑戰,他們對AI大模型的投入,依然保持着積極且謹慎的矛盾態度。
IDC在《中國中小企業生成式AI及大模型應用調查》中也提到,採用大型模型和AI技術所需要的在硬件、軟件、培訓和數據處理等方面的成本,也是衆多中小企業面臨的一重挑戰。
再聚焦到C端市場來看,儘管業界還未出現一款真正的超級應用,但用戶對大模型應用的使用習慣正加速養成,全面開放,也是大勢所趨。
也就是說,全面開源開放,才能更好地滿足B端企業客戶、C端用戶源源不斷增長的市場需求。
我們看到,當風向轉變時,百度、OpenAI等大模型頭部玩家,敏銳捕捉到了信號,並率先以更積極的姿態開源、開放。
以百度為例,除了在C端全面開放文心一言,在B端,百度在大模型生態上也在逐步加大開放力度。
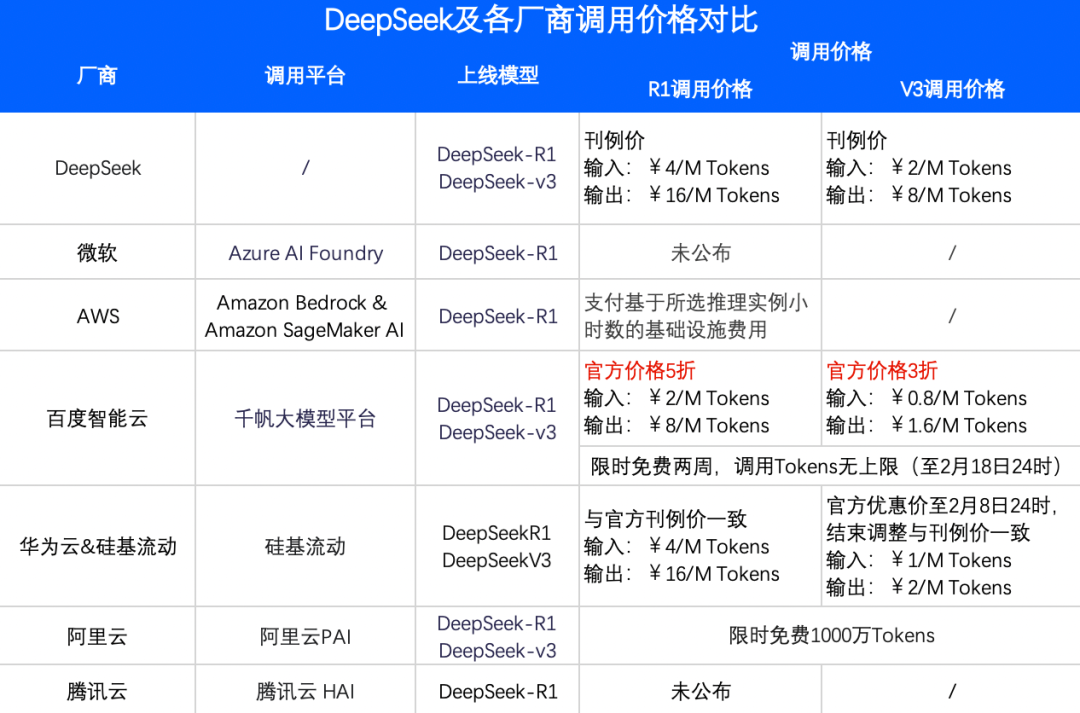
2月3日,百度智能雲官宣,DeepSeek-R1及DeepSeek-V3兩款模型已經上架其千帆ModelBuilder平台。
值得注意的是,百度將這兩款模型的價格打了下來——客戶在千帆ModelBuilder平台上調用這兩款模型的價格,僅為DeepSeek-V3官方刊例價的3折、DeepSeek-R1官方刊例價的5折,同時提供限時免費服務。
另一邊,過去一年裏,文心旗艦大模型的降價幅度也超過了90%,並且主力模型也全面免費,最大限度降低了企業創新試錯的成本。
當然,更重要的是,針對接下來即將推出的最新的文心大模型4.5系列,百度也將在6月30日起正式開源——它將以更積極的姿態面對市場,攜手推動產業發展。
聽潮TI也注意到,從目前釋放出的信息來看,百度的開放姿態,要比OpenAI更加積極——OpenAI考慮開源的,是此前已經發布的AI模型,而百度的開源動作,則是聚焦在接下來即將發布的最新系列模型。
這意味着,面向接下來的大模型AI應用爆發潮,百度已經在提前搶跑。
02 以技術創新為基,百度跑通了大模型技術的降本路徑
「回顧過去幾百年,大多數創新都與降低成本有關,不僅是在人工智能領域,甚至不僅僅是在IT行業。」 2月11日,在迪拜舉行的World Governments Summi2025峯會上,李彥宏如此說道。
在他看來,如果能將成本降低一定數量、一定百分比,意味着生產率也會提高相同的百分比,「我認為,這幾乎就是創新的本質。而今天,創新的速度比以前快得多。」

百度創始人李彥宏,圖/百度官微
李彥宏此番表態背後,如今的百度,已經跑通了大模型技術的降本路徑。而背後的支撐,正是技術創新。
具體來看,從大模型訓練到推理,百度目前的降本效果都較為顯著。
先來看訓練成本。百度自研的崑崙芯芯片和萬卡集羣的建成,為大模型訓練提供算力支持,百舸·AI異構計算平台,則可以承載大量數據的處理、超大模型的訓練、高併發業務的推理,為AI任務加速,是更底層的基礎設施。
其中,崑崙芯的性能優勢在於,其能在更少的計算資源下運行大規模模型,進而使得大模型的推理和訓練所需的計算量減少,直接降低算力成本;
大規模集羣的優勢則在於,其可以通過任務並行調度、彈性算力管理等方式,提高計算資源利用率,避免算力閒置,提高單任務的計算效率,降低整體算力成本。 近日,百度智能雲成功點亮了崑崙芯三代萬卡集羣,其是國內首個正式點亮的自研萬卡集羣,百度接下來計劃將進一步擴展至3萬卡。

圖/百度官網
此外,在百舸平台的能力支撐下,百度也實現了對大規模集羣的高效部署管理。
比如其將帶寬的有效性提升到了90%以上、通過創新性散熱方案有效降低了模型訓練的能耗、通過不斷優化並完善模型的分佈式訓練策略,將訓練主流開源模型的集羣MFU(GPU資源利用率)提升到了58%。
再來看模型的推理成本。有業內人士分析稱,這一次文心一言全面開放,背後最大的原因之一,或許正是推理成本不斷降低。
「百度在模型推理部署方面有比較大的優勢,尤其是在飛槳深度學習框架的支持下,其中並行推理、量化推理等都是飛槳在大模型推理上的自研技術。飛槳和文心的聯合優化,可以實現推理性能提升,推理成本降低。」他進一步分析道。
具體來看,百度是中國唯一擁有「芯片-框架-模型-應用」這四層AI技術全棧架構的AI企業,這意味着,百度有着中國最「厚實且靈活」的技術底座,能夠實現端到端優化,不僅大幅提升了模型訓練和推理的效率,還進一步降低了綜合成本。
舉個例子,DeepSeek-R1和DeepSeek-V3在千帆ModelBuilder平台更低的推理價格,正是是基於技術創新——百度智能雲在推理引擎性能優化技術、推理服務工程架構創新,以及推理服務全鏈路安全保障上的深度融合,是把價格打下來的重要原因。
基於上述幾點來看,百度的降本路徑其實尤為清晰——基於自研技術創新,提升大模型在訓練、推理過程中的資源利用率。
我們也看到,遵循這一大模型技術的降本路徑,蘿蔔快跑,也在加速以更低成本落地。
去年5月,蘿蔔快跑發布了全球首個支持L4級自動駕駛的大模型,進一步提升了自動駕駛技術的安全性和泛化性,用大模型的力量讓自動駕駛「更快上路」,處理複雜交通場景的能力,完全不輸Waymo。
再聚焦到蘿蔔快跑第六代無人車,其全面應用了「百度Apollo ADFM大模型+硬件產品+安全架構」的方案,通過10重安全冗餘方案、6重MRC安全策略確保車輛穩定可靠,安全水平甚至接近國產大飛機C919。
值得注意的是,這一過程中,蘿蔔快跑無人車的成本,已經達到或接近業界最低水平。其第六代無人車,比特斯計劃在2026年量產的cybercab成本還要低,甚至是Waymo的1/7。
這某種程度上也加速了蘿蔔快跑的落地進程。
截至目前,蘿蔔快跑已經在北上廣深等十多個城市,以及中國香港開啓道路測試。百度此前透露,蘿蔔快跑累計訂單已經超過800萬單。李彥宏也提到,蘿蔔快跑的L4級自動駕駛安全測試里程累計已超過1.3億公里,出險率僅為人類司機的1/14/。
與此同時,蘿蔔快跑在中國市場更復雜的城市路況下積累的測試里程,也為其開拓中東、東南亞等新興市場埋下了伏筆。
03 應用爆發年,百度的下一步怎麼走?
「我們生活在一個非常激動人心的時代。在過去,當我們談論摩爾定律時說,每18個月性能會翻倍、成本會減半;但今天,當我們談論大語言模型時,可以說每12個月,推理成本就可以降低90%以上。這比我們過去幾十年經歷的計算機革命要快得多。」 2月11日的那場峯會上,李彥宏如此說道。
事實上,回顧過去一年裏大模型賽道的動態,從價格戰到大模型廠商的路徑分化,到kimi的出圈,到AI Agent的爆發之勢,再到DeepSeek的異軍突起,以及其所帶來的大模型開源開放潮,不難發現:
當下,大模型產業正加速邁入新的周期——技術迭代的速度越來越快了、技術創新的未知想象空間更廣闊了、大模型技術降本的速度更快了、大模型應用的爆發點更近了。
這同時也意味着,從市場競爭的視角來看,大模型廠商接下來的比拼維度,也將更加豐富。
他們既要拼技術創新、拼生態賦能、也要拼開放力度和降本能力、還要拼應用。
不過,參考百度的降本路徑,長遠來看,最核心的比拼,依然聚焦在一點——誰能持續走在大模型技術創新的最前沿。

我們注意到,這也是百度的長期思路。
「創新是不能被計劃的。你不知道創新何時何地到來,你所能做的是,營造一個有利於創新的環境。」李彥宏如此表示。
這對應的是,儘管技術進步和技術創新在不斷降本,百度接下來還是會在芯片、數據中心、雲基礎設施上持續大力投入,來打造出更好、更智能的下一代、下下一代模型。
比如百度還在不斷豐富其大模型矩陣。
目前,文心大模型矩陣中,包括了Ernie 4.0 Turbo等旗艦大模型、Ernie Speed等輕量模型,也包括基於基礎模型生產的系列思考模型和場景模型,以滿足不同應用的需求。
去年三季度,百度還推出了Ernie Speed Pro和Ernie Lite Pro兩款增強版的輕量模型。
再到今年,從已經釋放出的消息看,文心大模型4.5系列、5.0系列也將發布。
另一方面,我們也看到,百度更加積極的開源開放姿態背後,其實繼續延續了此前的理念——加速推動大模型在B端業務場景中的應用進程,以及在C端應用上的探索。
最後,如李彥宏所說,「也許,在某個時刻你會找到一條捷徑,比如說只需600萬美元就能訓練出一個模型,但在此之前,你可能已經花費了數十億美元,用來探索哪條路纔是花費這600萬美元的正確途徑。」
對百度而言,用持續高壓強式的技術投入營造創新環境,其實是一門「笨功夫」,但好在這足夠穩健、足夠踏實,潛在的機會也更大。
一來,此前文心大模型的調用量就已經是國內最高,如今開源之後,其調用量預計將明顯提升,進一步擴大文心大模型的使用範圍;
二來,從大模型生態來看,百度過去已經基於開放姿態建立起了生態優勢。
比如百度早在2016年就推出了開源的飛槳框架;百度的千帆大模型平台,也是當前業內接入模型數量最多的,支持國內外近百家主流模型。
由此可以預見,如今在更大力度推動大模型開源、開放後,在新一輪大模型競爭中,百度已經開始搶跑了。