Grok-3才發布3天,就陷入作弊風波。
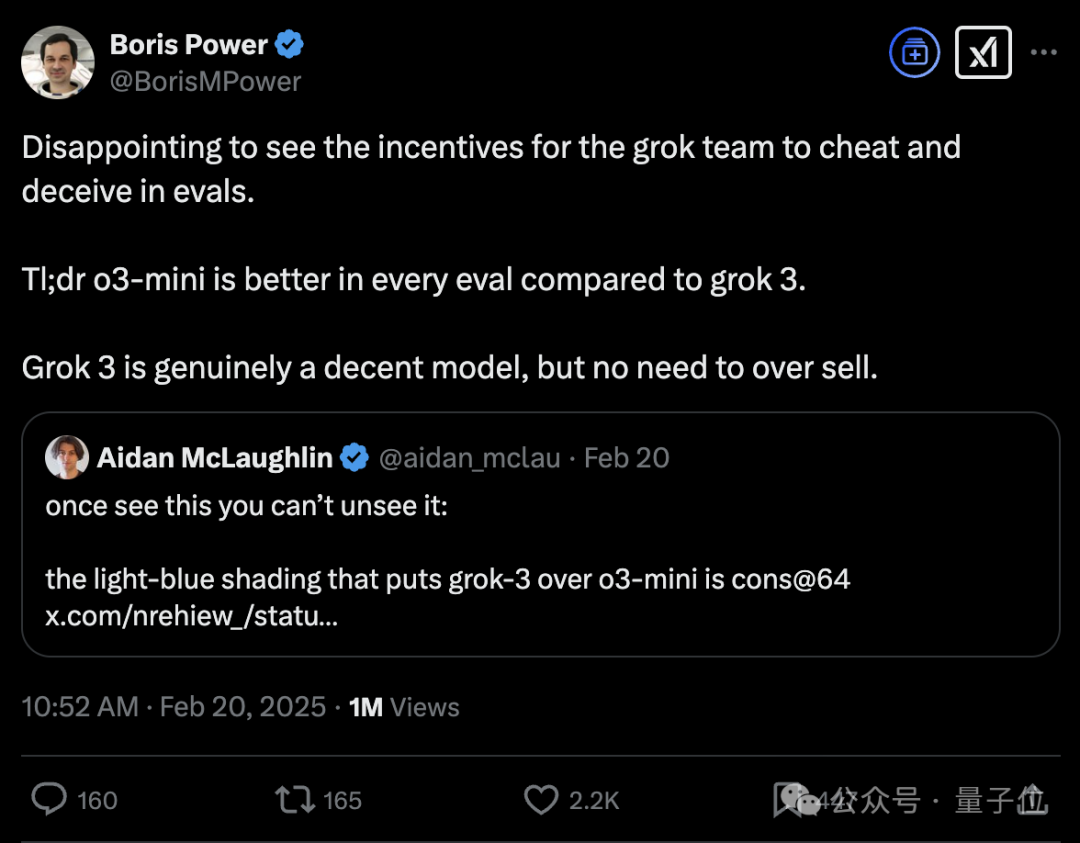
隔壁OpenAI應用主管火速掀桌:每次評估中o3-mini都要比Grok-3好,看到Grok團隊作弊真是令人失望。
咋回事?
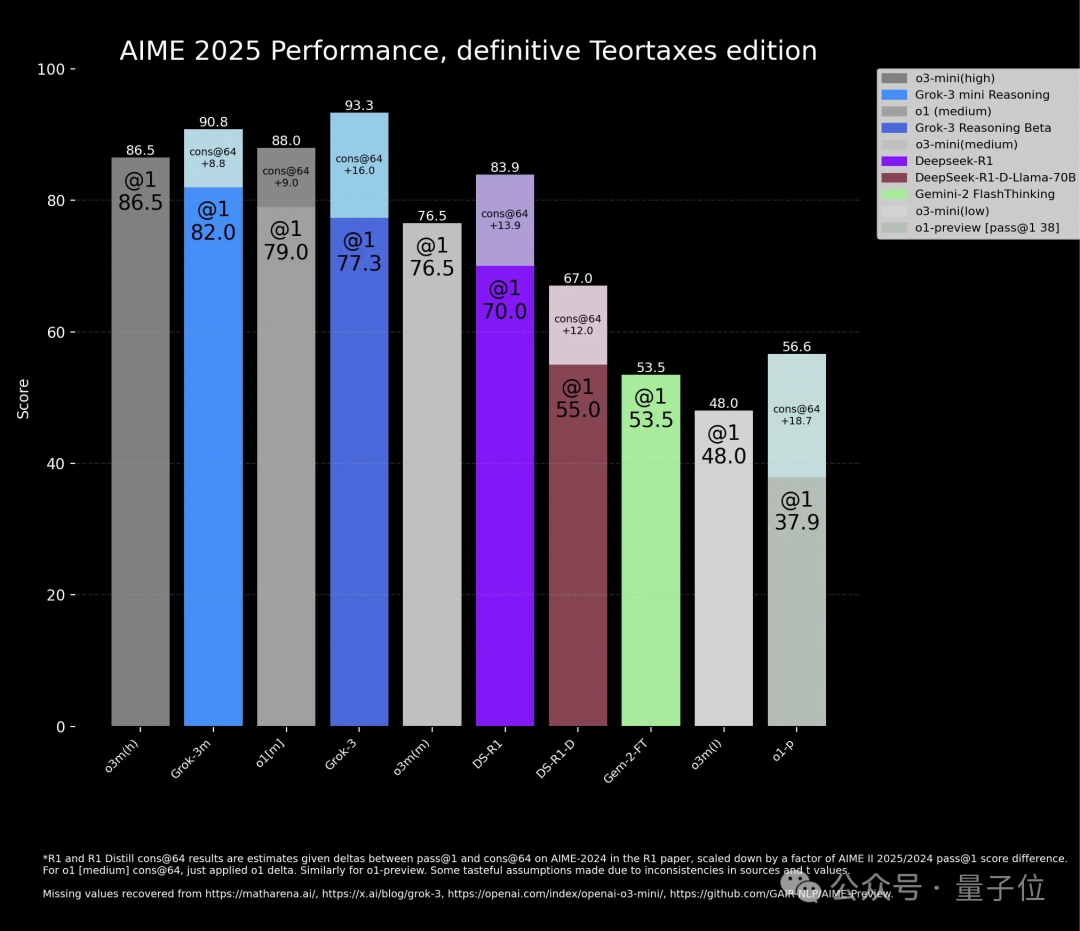
在Grok-3的Blog中有一張AIME 2025評估圖令人印象深刻,兩個新版本模型都超過o3-mini高配版。
但注意看,Grok-3兩個模型的柱狀圖中都有1段顏色更淺的部分。OpenAI指責的作弊,就是在這裏。
淺色部分代表了Grok-3模型在Con@64上的成績。
即這是模型進行64次答案後的成績,而不是單次回答。
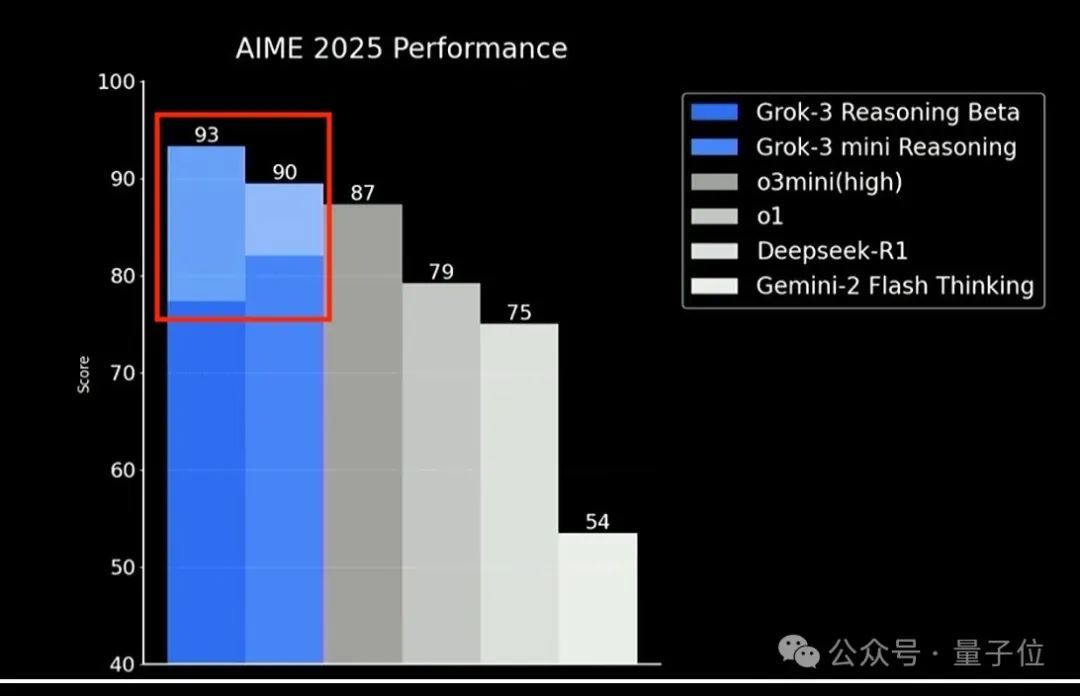
那麼問題就來了,被拿來對比的o3-mini、o1、DeepSeek-R1、Gemini-2 Flash Thinking似乎並沒有這部分成績。
有人就表示,如果真是如此,那麼Grok-3推理模型只是和o1相當。OpenAI和xAI之間依舊差了9個月。

OpenAI負責模型設計的研究員Aidan McLaughlin更是激情開麥,表示馬斯克發布時說的話極其有誤導性,這會讓人以為淺藍色部分是通過推理實現的成績。
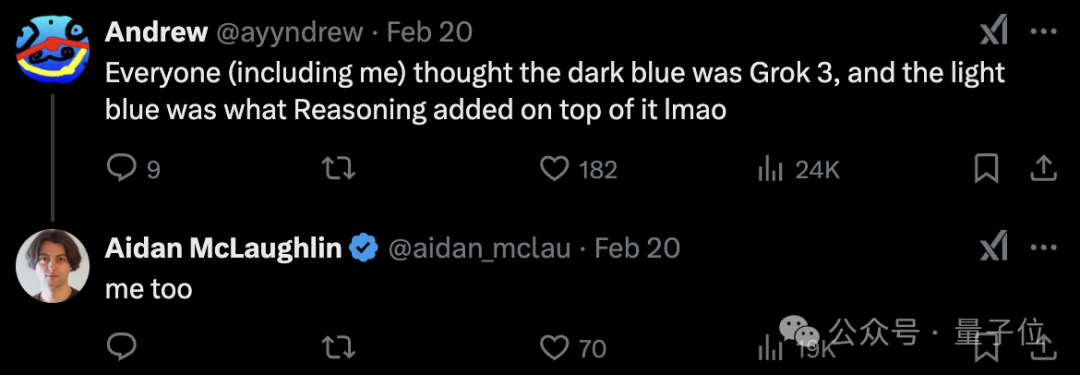
不過值得一提的是,這種模型評估對比方法似乎是OpenAI開了頭。o3-mini的Blog中,也看到了類似形式的評估。
所以,為啥這麼對比不合理?
採用cons@64,o1都能和o3-mini相當
首先明確概念:
cons@64:讓模型生成64個答案,最終採用出現頻率最高的回答。
pass@64:如果64個答案中只要有一個答案正確,模型就得分。
所以有人就說了,問題的關鍵不是xAI不應該使用cons@64;
關鍵在於,如果其他模型只是嘗試了一次,那就不太公平了。
因為blog中並沒有說清楚,所以假定是這種情況。
有AI博主也列出了蒐集到的相關數據,o3-mini在單次回答上的表現更好。
其次,根據o3-mini的blog,o1模型採用cons@64成績,甚至可以和o3-mini打個相當。
這意味着採用cons@64成績是「有優勢」的。
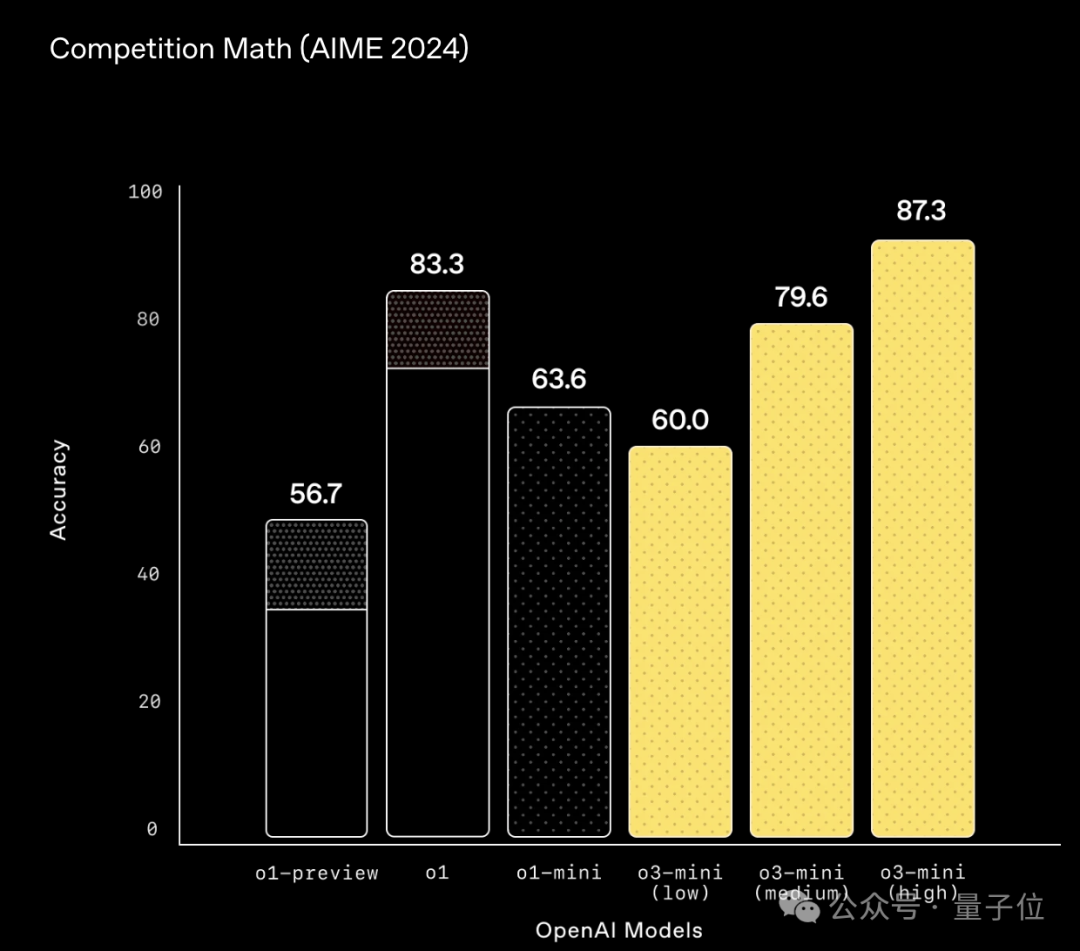
有人也揪着這事不放,但是OpenAI確實沒讓o3-mini用cons@64。

最後,Grok-3發布時的說法似乎有一定誤導性。
有人貼出來了原片段。在被問及評估圖中的淺色部分是什麼時,官方給出的解釋是:
這些模型可以推理、可以思考,可以要求模型思考更長、花更多時間進行測試時推理。這種情況下,這些淺色部分意味着我們只是花費更多時間讓模型解決同一個問題,然後它纔會得出什麼是正確的答案。如果這樣做,模型甚至可以表現得更好。
OpenAI研究員Aidan覺得這段話極具誤導性,他只是說使用更多測試時計算,聽起來像是做更多推理,但其實不是如此。

總而言之,Grok團隊這麼幹確實有點不地道。
喫瓜到這,網友們不免開始蛐蛐:
Grok-3不如o3-mini,馬斯克就會給團隊上壓力。然後想出的好辦法就是在基準測試上做手腳。
以及為啥都不和Claude做對比呢?
不過也有人覺得這事不能一棒子打死,Grok仍舊有很多值得關注的方面。比如Grok-3一個月前才完成預訓練,這只是一個月內基於CoT的後訓練結果,模型還有很大的提升空間。此外xAI正在以行業內最快的速度擴展預訓練計算能力。
以及Grok-3發布後,開發者們已經火速琢磨出了一些有趣的新玩法。
輕鬆開發小遊戲
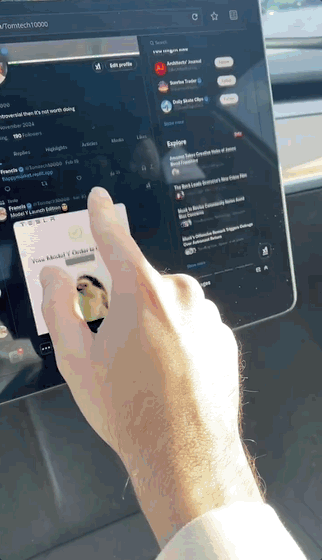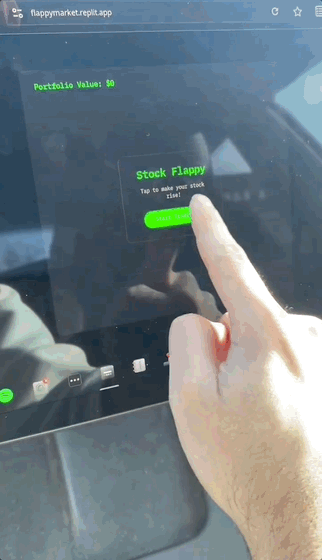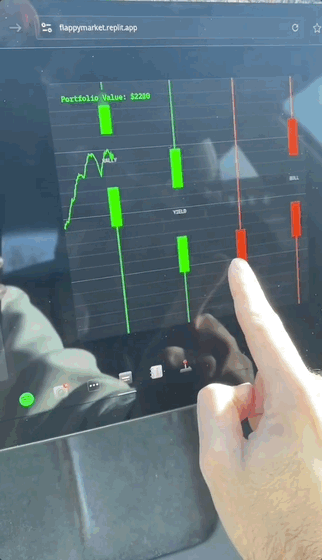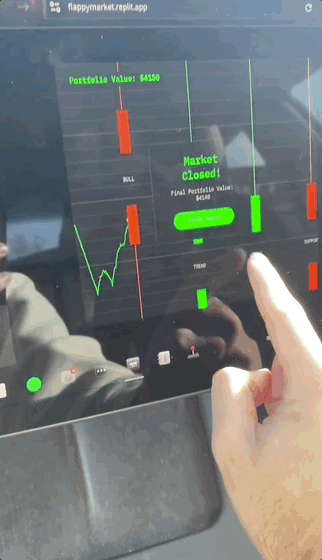
這不,有人就曬出了在特斯拉上完用Replit+Grok開發的小遊戲。
還有曾在微軟深度參與Windows系統開發的大佬Dave Plummer,也用Grok-3復刻了經典的打磚塊遊戲。
他為Windows創建了任務管理器、為Windows完成了對zip文件的支持。
這一次,他展示瞭如何只用幾句話就讓Grok-3開發小遊戲。
提示詞都很簡單:
「來做個彩色版打磚塊怎麼樣」
「讓球自動移動,並讓球每次從球拍上彈起時速度提高 10%」
「很好,球在垂直彈射時會卡住。一開始遊戲是怎麼設計的?do the same」

最後得到的效果是這樣的:
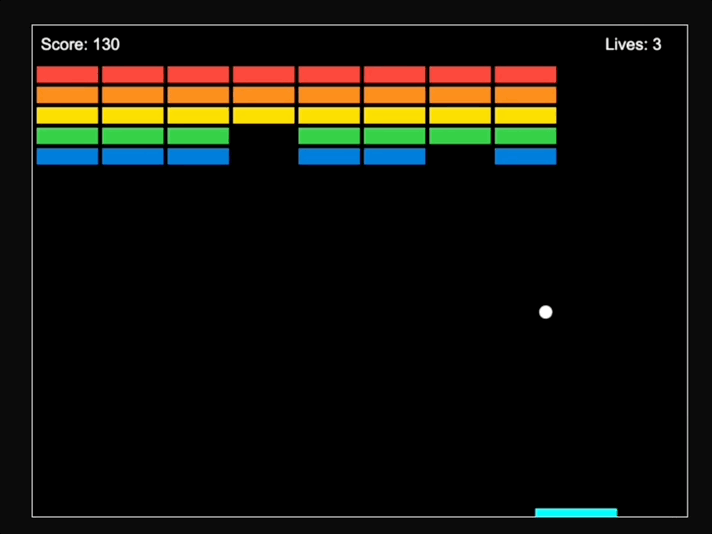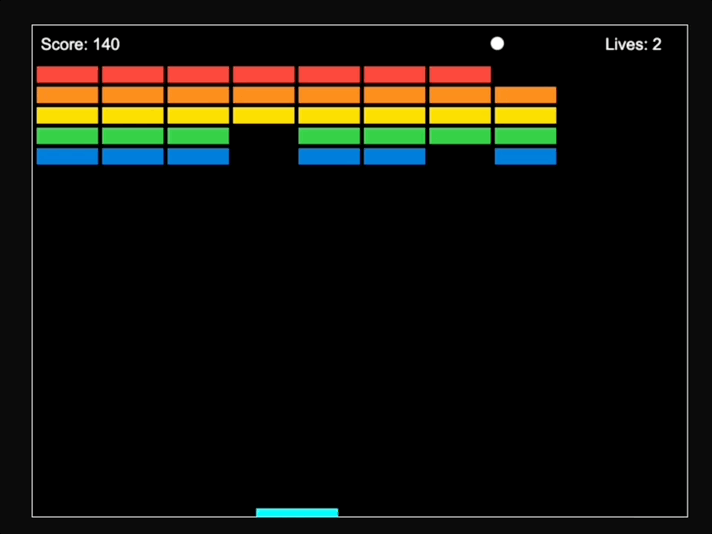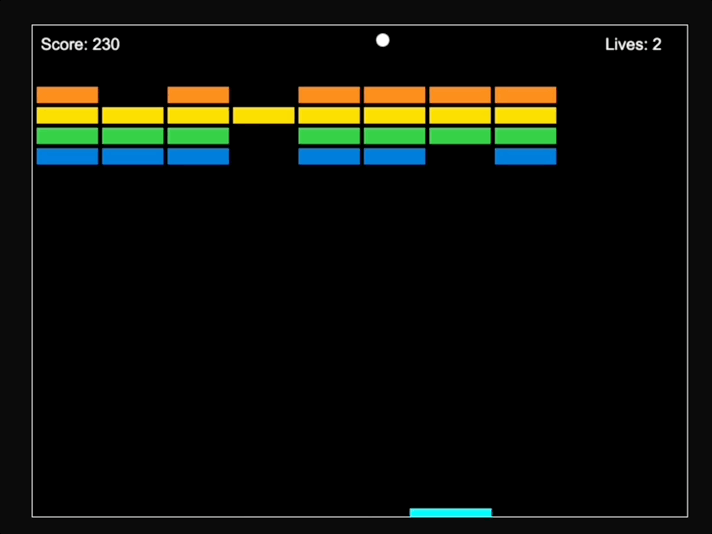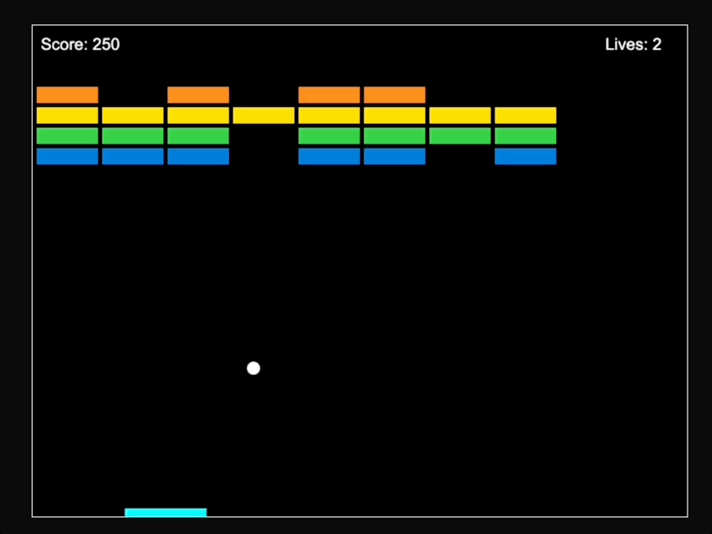
值得一提的是,馬斯克最近證實了成立了AI遊戲工作室的消息,他要讓遊戲再次偉大(doge)。