
作者 | 許麗思
編輯 | 漠影
機器人前瞻2月21日報道,近日,微軟研究院發布了一個多模態AI模型——Magma。Magma是首個能夠在其所處環境中理解多模態輸入並將其與實際情況相聯繫的基礎模型,只要提供一個描述性目標,Magma就能夠制定計劃、執行行動以達成該目標。
Magma以視覺語言(VL)模型為基礎,除了保留傳統的語言和視覺的理解能力(語言智能)外,還解鎖了空間智能的新技能,能夠從多模態輸入(用戶界面截圖、機器人圖像、教學視頻)中理解對象的物理位置、動作的時序邏輯,並在不同環境(數字界面與物理世界)中完成連貫的任務。
值得一提的是,論文的作者中,13位有12位應該是華人。中美AI、機器人競賽的背後,果然還是在美華人和在華中國人之間的較量。

Magma 採用了深度學習架構和大規模預訓練相結合的方法,該模型使用 ConvNeXt-XXL 視覺骨幹處理圖像和視頻,同時使用 LLaMA-3-8B 語言模型處理文本輸入。
Magma 是通過一個包含3900萬個樣本的多樣化數據集進行訓練的,其中包括圖像、視頻和機器人動作軌跡。
這個模型還創新採用了兩項技術:「可標記集」(Set-of-Mark,SoM)和 「軌跡標記」(Trace-of-Mark,ToM)。前者使模型能夠標記 UI 環境中的可操作視覺對象,後者則使其能夠追蹤物體隨時間的移動,提升未來行動的規劃能力。
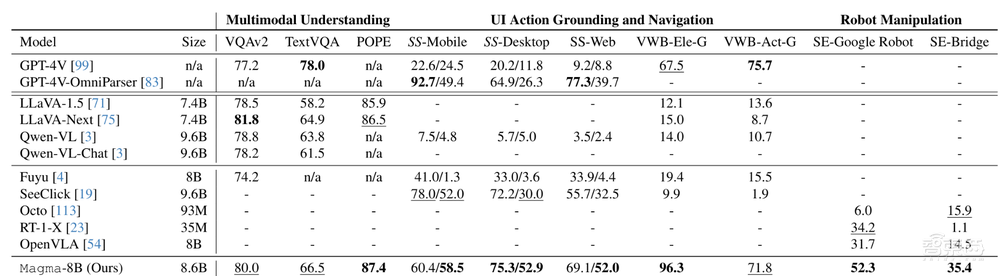
研究團隊對包括ChatGPT在內的多個模型進行了零樣本評估,結果顯示,經過預訓練的Magma模型在未進行任何特定領域微調情況下,是唯一一款能夠執行全範圍任務的模型。
將Magma和OpenVLA這兩個模型應用到WidowX機械臂上,當讓機械臂組裝桌面上的熱狗模型、把蘑菇模型放到盆中、把桌子上的抹布從左邊移動至右邊時,Magma可以讓機械臂比較精確地完成任務,而OpenVLA則在物體抓取、移動上表現略遜色於前者。
Magma應用到WidowX機械臂並經過少樣本的微調後,在分佈內和分佈外泛化任務中,都有着可靠的性能表現。



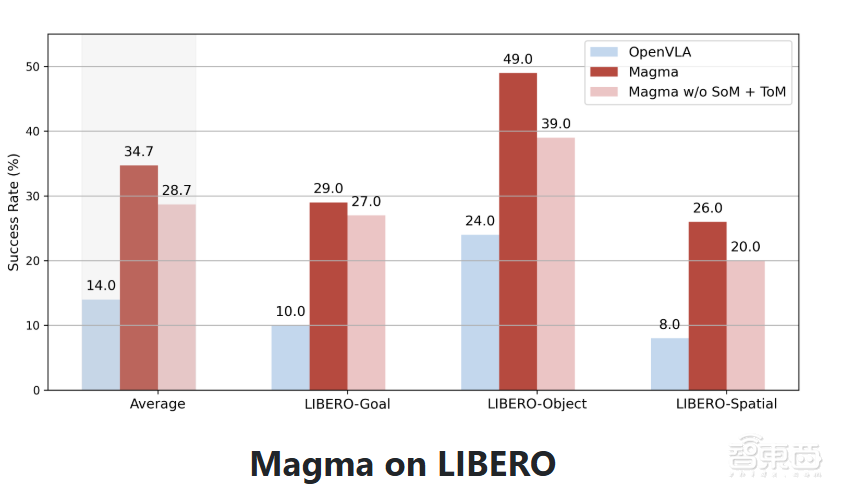
在LIBERO平台上進行的少樣本微調,Magma在所有任務組中都取得了更高的平均成功率。
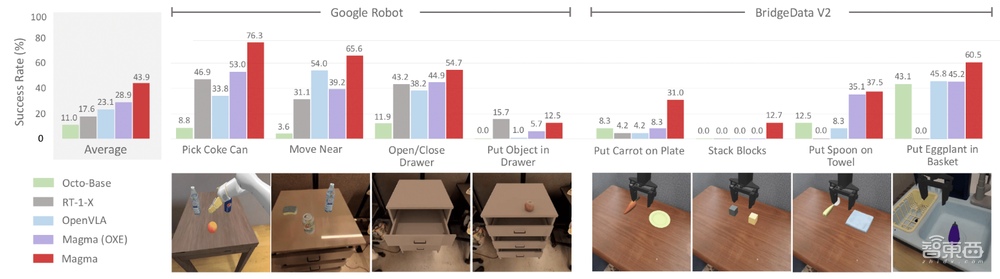
在Google Robots和Bridge上進行的零樣本評估中,Magma模型也展現出了較強的零樣本跨域魯棒性,並在抓取多種不同物品等跨實體操作模擬任務中取得了不錯成績。
處理一些比較有挑戰性的空間推理難題時,雖然Magma的預訓練數據比GPT-4o少得多,但是也可以準確地進行回答。
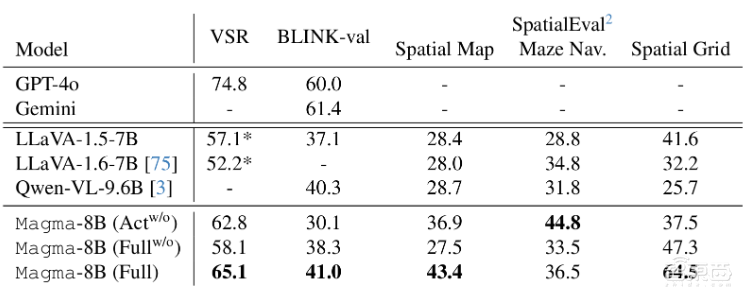
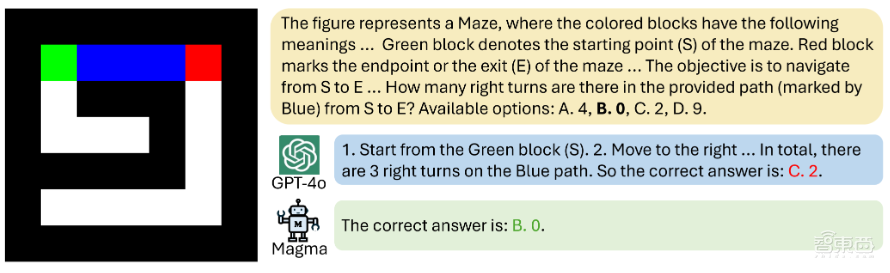
針對多模態理解方面,Magma的表現甚至超越了Video-Llama2和ShareGPT4Video。比如,當給Magma提供一段視頻時,看到有人拿起茶包,它能秒猜下一步要倒熱水泡茶。

Magma成功整合了視覺、語言和行動,在機器人任務操作上表現出了較高的泛化能力。未來,隨着模型研究的不斷深入及模型規模的擴展,Magma也有望為解決更復雜的機器人操作問題提供不錯的解決方案,讓機器人距離真正的落地應用更進一步。
參考鏈接:
https://www.arxiv.org/pdf/2502.13130