處理數百小時超長視頻,單張3090就夠了?!
這是來自香港大學黃超教授實驗室發布的最新研究成果——VideoRAG。

具體而言,VideoRAG可以在單張RTX 3090 GPU (24GB)上高效處理長達數百小時的超長視頻內容。這意味着只需要一張普通的顯卡,就能一口氣完整觀看一部《黑悟空》這樣的長視頻。
此外,VideoRAG還擁有創新的多模態檢索機制。
它採用了動態知識圖譜構建和多模態特徵編碼的技術,將視頻內容濃縮為基於多模態上下文的結構化知識表示。這不僅支持複雜的跨視頻推理,還能夠精準地進行多模態內容檢索。
而且,為了推動該領域的進一步發展,研究團隊還發布了LongerVideos基準數據集。
該數據集涵蓋了160多個長達數小時的視頻,為未來的研究提供了寶貴的支持。
更多具體內容如下。
突破傳統文本RAG跨模態侷限
儘管RAG (Retrieval-Augmented Generation) 技術通過引入外部知識顯著提升了大語言模型的性能,但其應用場景仍侷限於文本領域。
視頻作為一種複雜的多模態信息載體,涵蓋視覺、語音和文本等異構特徵,其理解與處理面臨三大關鍵挑戰:
多模態知識融合:傳統文本RAG方法難以有效捕捉視頻中的跨模態交互,特別是在建模視覺動態特徵(如目標運動軌跡)與語音敘述之間的時序關聯方面存在侷限;
長序列依賴建模:現有方法往往通過視頻截斷或關鍵幀提取來簡化處理,這不可避免地導致動作連續性損失,造成上下文割裂,影響跨視頻知識整合的效果,難以保持長時視頻的語義連貫性;
規模化檢索效率:在大規模視頻庫場景下,現有方法在檢索速度與結果質量間存在明顯權衡,且多依賴單一模態(如語音轉錄文本)進行檢索,未能充分利用視覺語義信息。
為突破上述限制,團隊提出創新性RAG框架VideoRAG,通過雙通道架構實現以下技術創新:
1、圖譜驅動的跨模態知識關聯:構建動態演化的語義網絡,將視頻片段映射為結構化知識節點,有效捕捉並建模跨視頻語義關聯;
2、有效的多模態上下文編碼:建立視覺-文本聯合表徵空間,保留細粒度時空特徵表示,顯著增強視頻內容理解能力;
3、適應混合檢索方法:融合知識圖譜推理與視覺特徵匹配,突破計算資源限制,實現低顯存消耗下的百小時級視頻精準檢索。
基於首個超長跨視頻理解基準數據集LongerVideos的全方位評估表明,VideoRAG在超長視頻內容理解任務上展現出卓越性能,為教育知識庫構建、影視內容分析等實際應用場景提供了極具潛力的解決方案。
VideoRAG框架設計
VideoRAG創新性地融合多模態知識索引與知識驅動檢索機制,實現對視頻中視覺、音頻及語義信息的高效捕捉、系統化組織與精準檢索。
該框架突破了傳統視頻長度限制,支持對理論上無限時長的視頻輸入進行智能分析,為超長視頻理解領域開創了新範式。
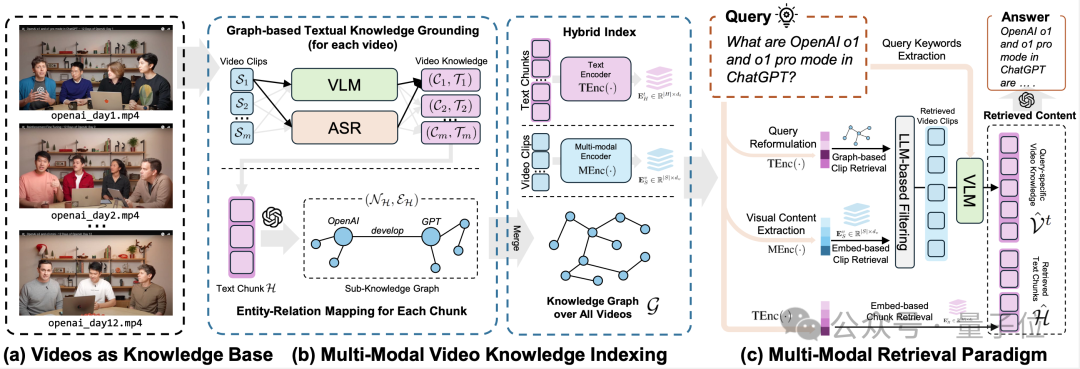
雙通道多模態視頻知識索引:突破傳統範式
視頻作為複雜的多模態信息載體,融合了視覺、音頻及文本等多維度信息,其處理難度遠超傳統文本。
現有的文本RAG方法在處理視頻數據時面臨三大根本性挑戰:視覺動態特徵提取、時序依賴性建模以及跨模態語義交互。針對這些挑戰,VideoRAG創新性地提出雙通道架構,實現了對長視頻的高效組織與智能索引,同時保持了多模態內容的語義完整性:
基於知識圖譜的多模態語義對齊
視覺-文本映射:在視覺語義建模環節,本框架採用精細化的視頻分段策略,將視頻流按時序均勻劃分為連續片段。為平衡計算效率與信息完整性,每個片段通過智能採樣算法提取不超過10個代表性關鍵幀。
隨後,藉助先進的視覺語言模型(VLM),自動生成高質量的自然語言描述,實現對視頻畫面中物體、動作語義及場景動態等多維度特徵的系統性捕捉。
音頻語義轉換與融合
在音頻處理模塊,系統部署了高性能的語音識別(ASR)技術,精確提取視頻中的對話內容與旁白信息。
通過創新的語義融合機制,將音頻文本信息與視覺描述進行深度整合,構建統一的跨模態語義表示體系,有效保留了視聽信息的語義完整性。
跨視頻知識網絡構建
基於LLMs識別實體關係,動態合併多視頻語義節點,形成全局知識網絡,確保跨視頻內容的一致性與關聯性。
多模態上下文編碼
為實現跨視頻的語義關聯,框架基於大語言模型(LLMs)設計了動態知識圖譜構建機制。
系統自動識別並提取視頻內容中的核心實體與關係信息,通過智能合併算法動態融合多個視頻的語義節點,最終形成結構化的全局知識網絡。
這一創新設計確保了跨視頻內容的語義一致性,作為後續內容檢索的基礎。
混合檢索範式:多維度視頻理解
VideoRAG創新性地融合文本語義與視覺內容的雙重匹配機制,通過深度語義理解與多模態信息融合,實現了超高精度的視頻片段檢索。該框架包含三大核心技術模塊:
1)知識驅動的語義匹配模塊: 基於知識圖譜的高級語義理解機制,系統執行多層次的智能檢索流程。
首先進行查詢意圖重構,隨後通過實體關係網絡進行精準匹配,繼而完成相關文本塊的智能篩選,最終定位目標視頻片段。這種層級化的檢索策略確保了語義理解的深度與準確性。
2)跨模態視覺內容匹配引擎: 系統採用先進的語義轉換技術,將用戶查詢智能轉化為標準化的場景描述。
通過專用多模態編碼器,實時生成視頻片段的高維特徵向量表示,並基於創新的相似度計算算法,實現精確的跨模態內容匹配。這一設計顯著提升了視覺語義檢索的準確性。
3)基於大語言模型的智能過濾機制: 框架整合了先進的大語言模型(LLMs)技術,對檢索結果進行多維度的相關性評估與智能篩選。
通過深度語義理解,有效過濾低相關性內容與噪聲信息,確保系統輸出高質量、準確度的回答。這種智能過濾機制提升了檢索結果的可靠性。
響應生成:雙階段深度理解框架
在成功檢索到相關視頻片段後,VideoRAG通過創新性的雙階段內容理解與生成機制,實現高質量的智能問答:
基於大語言模型的語義理解與關鍵詞提取。系統首先對用戶查詢進行深度語義分析,智能提取核心關鍵詞與意圖特徵。
這些高價值的語義信息隨後與精選的視頻關鍵幀一起,輸入到先進的視覺語言模型(VLM)中,生成富含視覺細節的場景描述。這種融合式的處理方法顯著提升了系統對視覺內容的理解深度。
多模態知識整合與答案生成。在第二階段,系統調用先進的大語言模型(如GPT4或DeepSeek),將檢索到的多模態信息與用戶查詢進行深度融合。
通過專門優化的提示工程,模型能夠綜合利用文本語義、視覺特徵和上下文信息,生成既包含豐富視覺細節,又具備深層語義理解的高質量回答。這一設計確保了系統響應的準確性、完整性和連貫性。
實驗驗證
團隊在業界首個超長跨視頻理解基準數據集LongerVideos上,對VideoRAG框架進行了系統性的性能評估與實驗驗證。評估工作涵蓋三大關鍵維度:
(1) 與主流RAG框架的對比實驗
通過與當前主流的檢索增強生成系統(包括NaiveRAG、GraphRAG和LightRAG)進行全面對比,深入驗證了VideoRAG在視頻理解與信息檢索方面的技術優勢。
(2) 與當前視覺模型的性能對標
針對支持超長視頻輸入的大規模視覺模型(LLaMA-VID、NotebookLM、VideoAgent),進行了詳盡的性能對比。
(3) 深入的模型組件分析
通過系統性的消融實驗(包括移除知識圖譜組件-Graph、視覺理解模塊-Vision),結合典型案例分析,深入考察了各核心組件對系統整體性能的貢獻。
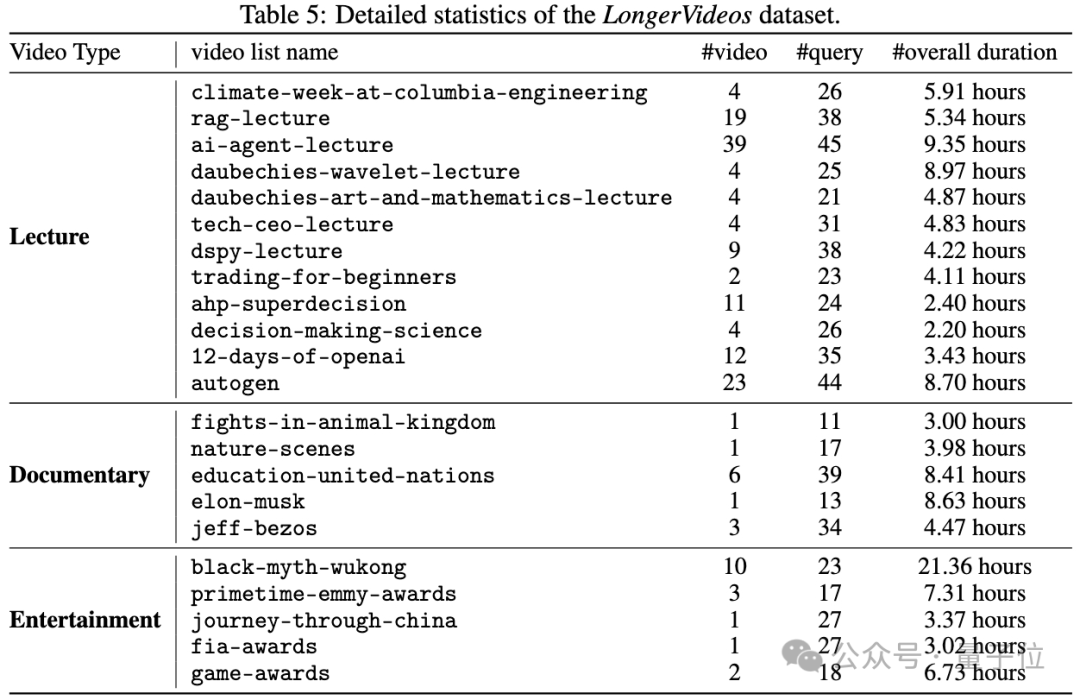
LongerVideos超長視頻理解基準測試數據
LongerVideos是首個專注於超長視頻理解的綜合性基準數據集,收錄了總計164個高質量視頻,累計時長突破134小時。
該數據集經過精心策劃,系統性地涵蓋了學術講座、專業紀錄片和綜合娛樂節目三大核心應用場景,既確保了內容的多樣性與代表性,也為跨視頻推理能力的評估提供了堅實基礎。
相較於現有視頻問答基準數據集普遍存在的侷限性(如單視頻時長不足1小時、場景單一等),LongerVideos實現了顯著的技術突破。
通過延長單個視頻的時間跨度,並支持複雜的跨視頻語義理解與推理,該數據集為超長視頻理解技術的發展提供了更加全面、科學的評估基準。
這些創新特性不僅彌補了現有評估體系的不足,更為相關技術的進步提供了重要的測試數據集。
此外,團隊設計了一套的雙層評估框架,通過定性與定量相結合的方式,系統性地驗證VideoRAG的性能表現:
勝率評估:採用基於大語言模型的智能評估方案,通過部署GPT-4-mini作為專業評判器,對比分析不同模型生成的答案質量。
定量評估:在勝率評估的基礎上,建立了嚴格的定量評估體系。通過預設標準答案並採用精細的5分制評分標準(1分代表最低質量,5分代表最優表現),實現了評估結果的可量化與可比較性。
評估框架涵蓋五個核心維度:
1、內容全面性(Comprehensiveness):衡量答案對相關信息的覆蓋範圍與完整度;
2、用戶賦能性(Empowerment):評估答案在提升用戶理解力與決策能力方面的效果;
3、回答可信度(Trustworthiness):考察答案的準確性、細節充實度及與常識的協調性;
4、分析深度(Depth):驗證答案在解析問題時的深入程度與洞察力;
5、信息密度(Density):評估答案在保持精練性的同時傳遞有效信息的能力。

RAG綜合性能評估:VideoRAG的技術優勢
實驗結果顯示,VideoRAG在所有評估維度和視頻類型中均展現出顯著優勢,全面超越了包括 NaiveRAG、GraphRAG和LightRAG在內的現有RAG方法。
這一卓越表現主要源於兩大核心技術創新:首創的知識圖譜索引與多模態上下文編碼融合機制,精準捕獲視頻中的動態視覺特徵與深層語義信息;以及創新的混合多模態檢索範式,通過有機結合文本語義匹配與視覺內容嵌入檢索,顯著提升了跨視頻檢索的精確度。
與NaiveRAG相比,本系統在內容全面性(Comprehensiveness)和用戶賦能性(Empowerment)方面表現卓越,這得益於其先進的知識索引架構和強大的跨視頻信息整合能力。
實驗證明,VideoRAG的創新架構能夠更有效地處理和整合跨視頻的複雜信息,為用戶提供更加全面和深入的答案。
在與GraphRAG和LightRAG的對比中,VideoRAG在視覺-文本信息對齊和查詢感知檢索等關鍵技術指標上均實現突破,使生成的答案在上下文連貫性和理解深度方面獲得顯著提升,成功引領知識驅動型視頻問答技術的新發展。
這些技術優勢充分證明了VideoRAG在處理複雜視頻理解任務時的卓越能力。

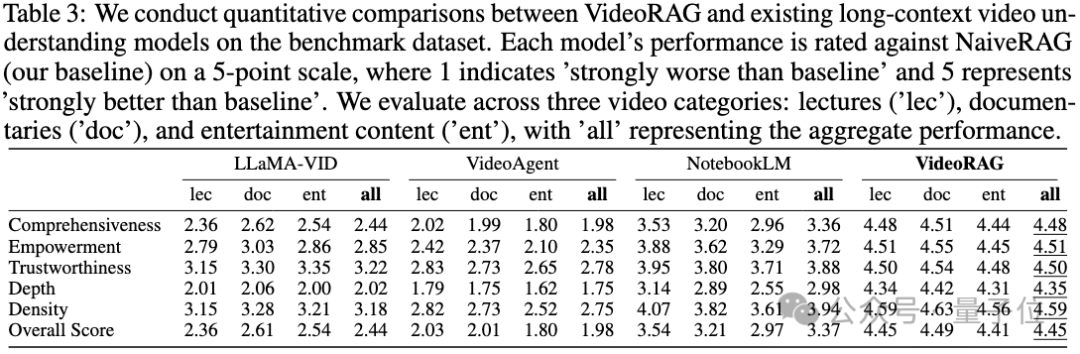
與長視頻理解模型的性能對比
VideoRAG在所有維度和視頻類型上性能均顯著超越LLaMA-VID、NotebookLM和VideoAgent等主流長視頻模型。這種全方位的性能優勢,充分體現了本系統在處理超長視頻內容時的技術的優勢。
通過創新性地引入圖增強的多模態索引和檢索機制,VideoRAG成功突破了傳統LVMs在處理長視頻時面臨的計算瓶頸。這一機制不僅能高效處理跨視頻的知識連接,更可以準確捕捉複雜的信息依賴關係,在性能上顯著超越了LLaMA-VID等現有模型。
相比僅依賴單一模態的基線模型(如專注於視覺的VideoAgent和側重語音轉錄的NotebookLM),VideoRAG展現出優異的多模態信息融合能力。
系統通過精細的跨模態對齊機制,實現了視覺、音頻和文本信息的深度整合,為超長視頻內容理解提供了更全面、更深入的分析能力。
消融實驗分析
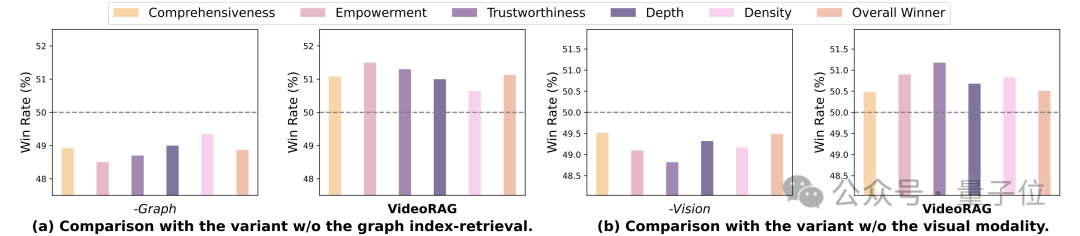
為系統評估VideoRAG框架中多模態索引和檢索機制的有效性,團隊設計了兩組對照實驗。
實驗通過移除核心功能模塊,構建了兩個關鍵變體:變體1(-Graph)移除了基於圖的索引-檢索管道,變體2(-Vision)則去除了多模態編碼器中的視覺索引和檢索組件。
這種針對性的模塊消融設計,使團隊能夠精確評估各核心組件的貢獻度。
圖索引機制的作用。變體1(-Graph)的實驗結果顯示,移除圖形模塊後系統性能出現顯著下降。
這一現象有力證實了基於圖的索引-檢索機制在處理複雜視頻內容時的關鍵價值。該機制不僅能有效捕捉跨視頻間的深層關聯,更在構建視頻知識依賴網絡方面發揮着不可替代的作用。
視覺處理能力的作用。變體2(-Vision)的實驗數據同樣呈現出性能的大幅下滑,充分說明了視覺信息處理對於視頻理解的重要性。
這一結果強調了多模態上下文融合在提升系統整體性能方面的關鍵作用,突顯了視覺模塊作為VideoRAG框架核心組件的重要地位。
視頻理解的案例分析
1、查詢設定與數據來源
本案例選取了極具代表性的查詢:」The role of graders in reinforcement fine-tuning」,基於OpenAI 2024年發布的12天系列視頻(總時長3.43小時)進行分析。
目標信息主要集中在第2天的內容中,這種複雜的跨視頻查詢場景為系統性能評估提供了理想的測試環境。
2、VideoRAG的檢索表現
實驗結果展示了VideoRAG卓越的信息檢索和整合能力。
系統準確定位並提取了第2天視頻中的核心內容,包括評分員的基本定義、評分系統的運作機制以及具體的評分示例。通過多維度的信息聚合,VideoRAG成功構建了一個全面、準確且具有充分證據支持的專業回答。
3、系統性能對比分析
與LightRAG的對比結果凸顯了VideoRAG在處理深度技術內容方面的顯著優勢。
儘管兩個系統都能夠提供評分系統的基礎概念解釋,但VideoRAG在評分員評分機制的技術細節闡述上明顯更勝一籌。
相比LightRAG給出的表層描述,VideoRAG提供了更深入、更專業的技術解析,體現了系統在處理複雜專業內容時的獨特優勢。

本案例研究通過案例分析,再次驗證了VideoRAG在三個核心技術維度的卓越性能:
1、知識圖譜構建能力
系統展現出優異的知識圖譜構建能力,不僅能精確捕獲視頻內容間的複雜關聯關係,更能構建起完整的知識依賴網絡,為深度理解提供了堅實基礎。
2、多模態檢索精度
在多模態信息檢索方面,VideoRAG實現了高度精確的檢索效果,能夠準確定位和提取跨模態的關鍵信息,充分體現了系統在處理複雜信息檢索任務時的技術優勢。
3、跨視頻信息整合
系統在處理和整合來自多個超長視頻的關鍵信息時表現出色,通過先進的信息融合機制,實現了複雜視頻內容的高效處理和準確理解。

VideoRAG: 技術創新與未來展望
突破性技術架構
VideoRAG通過開創性的雙通道索引架構,成功實現了跨視頻知識的深度關聯與細粒度視覺特徵的精確保留。這一創新設計不僅突破了傳統視頻理解的侷限,更為複雜場景下的知識圖譜構建開闢了新途徑。
先進檢索機制
系統創新性地提出混合檢索範式,通過有機融合語義匹配與內容嵌入技術,顯著提升了多模態信息的對齊精度。這種先進的檢索機制為處理複雜的跨模態視頻內容提供了更可靠的技術支持。
標準化評估體系
通過建立LongerVideos基準,VideoRAG為長視頻理解研究提供了一個規範化的評估平台。這一基準的建立不僅推動了領域研究的標準化發展,也為後續技術突破提供了可靠的驗證基礎。
未來發展方向
展望未來,VideoRAG將重點拓展兩大關鍵領域:實時視頻流處理能力的增強,以及多語言支持體系的構建。這些創新探索將進一步擴展視頻知識的應用邊界,釋放更大的視頻理解技術潛力。
— 完 —