
作者|程茜
編輯|心緣
智東西2月25日報道,啱啱,DeepSeek開源周第二彈發布,第一個用於MoE模型訓練和推理的開源EP通信庫,發布不到一小時,GitHub Star數已上千。
DeepEP是為混合專家(MoE)和專家並行(EP)量身定製的通信庫,其提供高吞吐量且低延遲的全對全GPU內核,這些內核也被稱為MoE調度與合併。
高性能:支持用於節點內和節點間通信的NVLink和RDMA,以及用於非對稱域帶寬轉發的優化內核;
低精度運算:FP8支持;
延遲敏感推理:提供使用純RDMA的低延遲內核,以最大限度地減少推理解碼的延遲;
通信-計算重疊:引入基於鉤子的方法,不會佔用任何流式多處理器(SM)資源;
自適應路由和流量隔離:支持低延遲內核自適應路由,支持虛擬通道流量隔離。
其中,為了與DeepSeek-V3論文中提出的組限制門控算法(group-limited gating algorithm)保持一致,DeepEP提供了一組針對非對稱域帶寬轉發進行優化的內核,例如將數據從NVLink域轉發到RDMA域。這些內核能夠實現高吞吐量,使其既適用於訓練任務,也適用於推理預填充任務。此外,它們還支持流式多處理器(SM)數量控制。
對於對延遲敏感的推理解碼任務,DeepEP包含了一組採用RDMA技術的低延遲內核,以最大程度地減少延遲。該庫還引入了一種基於鉤子的通信與計算重疊方法,這種方法不會佔用任何流式多處理器(SM)資源。
DeepSeek指出,DeepEP的實現可能與DeepSeek-V3論文中略有不同。
GitHub地址:https://github.com/deepseek-ai/DeepEP
具體性能方面:
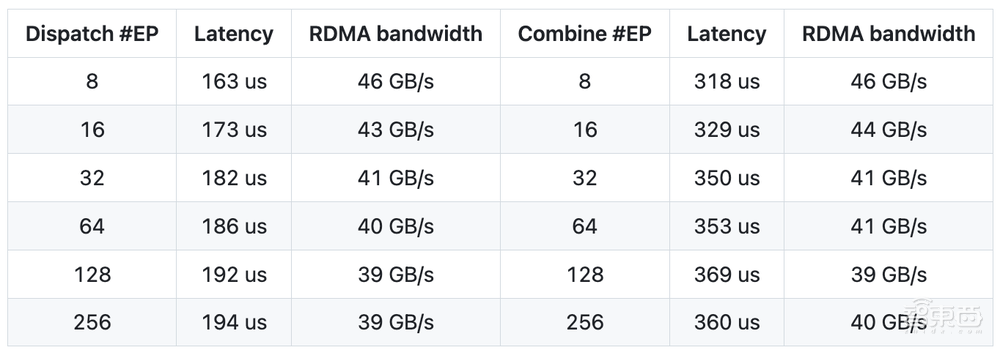
在H800(NVLink的最大帶寬約為160 GB/s)上測試常規內核,每台設備都連接到一塊CX7 InfiniBand 400 Gb/s的RDMA網卡(最大帶寬約為50 GB/s),並且遵循DeepSeek-V3/R1預訓練設定(每批次4096個Tokens,7168個隱藏層單元,前4個組,前8個專家(模型),使用FP8格式進行調度,使用BF16格式進行合併)。

在H800上測試低延遲內核,每台H800都連接到一塊CX7 InfiniBand 400 Gb/s的RDMA網卡(最大帶寬約為50 GB/s),遵循DeepSeek-V3/R1的典型生產環境設定(每批次128個Tokens,7168個隱藏層單元,前8個專家(模型),採用FP8格式進行調度,採用BF16格式進行合併)。
快速啓動要求:

下載並安裝NVSHMEM依賴項:

開發:
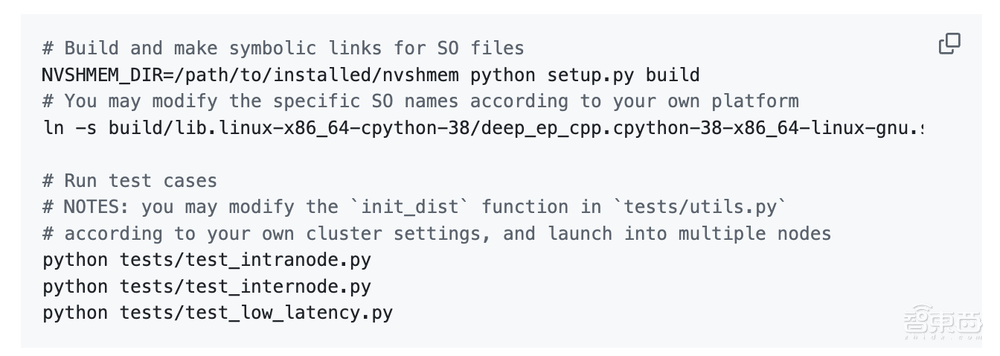
安裝:

網絡配置:

接口和示例:

DeepSeek發布的推文一小時瀏覽量高達12萬,評論區下方開發者們直接進入誇誇誇模式:
「DeepSeek在MoE模型方面所實現的優化程度頗高,而MoE模型因其規模和複雜性而向來極具挑戰性。DeepEP能夠藉助像NVLink和RDMA這類尖端硬件,如此精準地處理相關任務,並且還支持FP8格式,這着實令人驚歎。」

「對NVLink和RDMA的支持,為大規模的MoE模型帶來了變革性的影響。看來DeepSeek又一次突破了AI基礎設施的極限。」
還有人直接做了表情包:「跟着鯨魚找到魚。」
結語:深度探索開源宇宙DeepSeek還有三彈重磅發布
從帶飛GPU推理速度的FlashMLA到開源EP通信庫,DeepSeek開源周第二大重磅發布再次點燃AI圈的熱情。本周後續,DeepSeek還將開源三個代碼庫,或許會與AI算法優化、模型輕量化、應用場景拓展等相關,涵蓋多個關鍵領域。
期待接下來的三場技術盛宴,向開源者們致敬。