北京時間凌晨4點鐘OpenAI舉行一個14分鐘左右的直播發布,GPT4.5 終於發布了!凌晨4點爬起來第一時間給大家更新,😄
廢話不多說,先看看Sam Altman的對GPT 4.5的感受:
Sam:
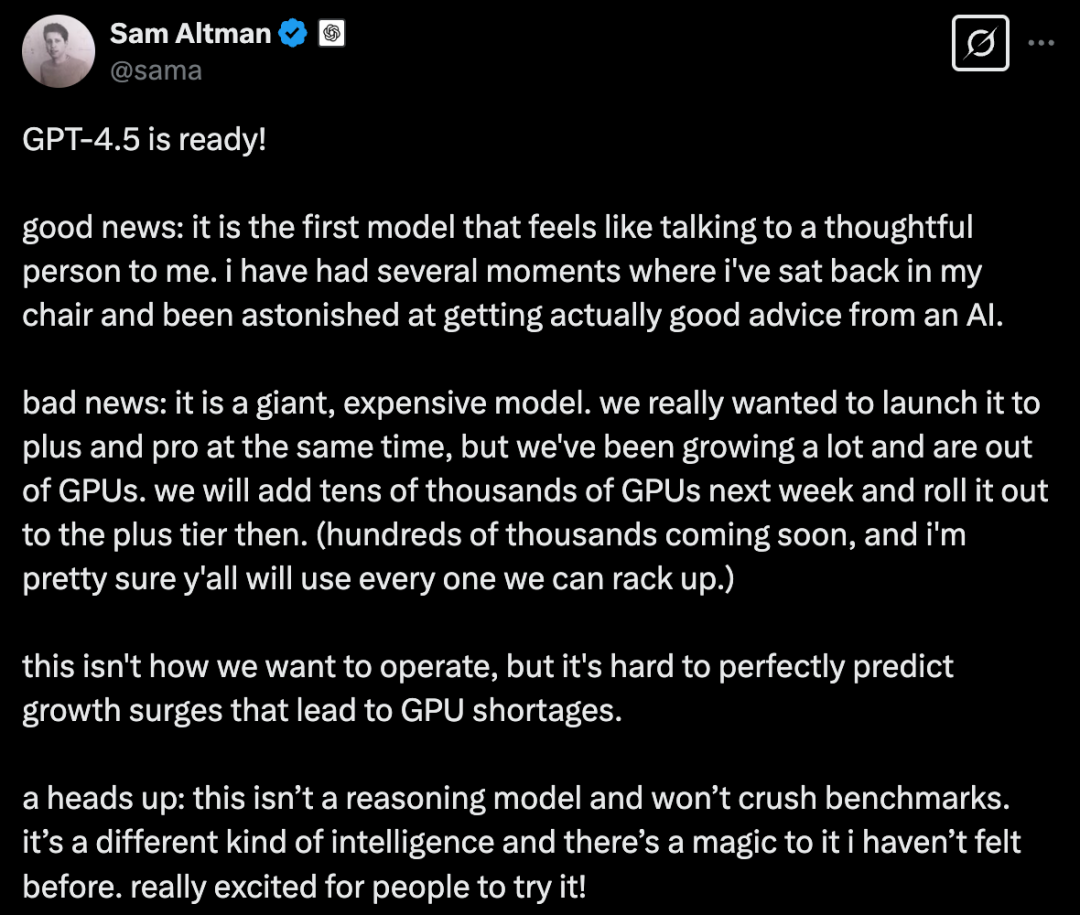
GPT-4.5 準備好了!
好消息: 它是我遇到的第一個感覺像是在和一位有思想的人交談的模型。 我有好幾次都向後靠在椅子上,驚訝於竟然能從人工智能那裏得到真正的好建議
壞消息: 這是一個龐大且昂貴的模型。 我們真的想同時向 Plus 和 Pro 用戶推出它,但我們的用戶增長非常迅速,以至於 GPU 不夠用了。 我們將在下周增加數萬個 GPU,然後向 Plus 用戶層推出它。(數十萬個即將到來,而且我確信你們會用完我們能部署的每一個。)
這不是我們希望的運營方式,但很難完美預測導致 GPU 短缺的增長激增。
溫馨提示:這並非一個推理模型,也不會在基準測試中表現突出。 這是一種不同類型的智能,並且它有一種我以前從未感受過的魔力。 真的非常激動能讓大家試試它!
是不是覺得泛善可陳?下面我們來看看GPT4.5長什麼樣子(發布會視頻附在文章最後):
發布會一開始上,OpenAI先展示了一個例子。當用戶表達 「朋友又取消了我的約會,我太生氣了,想發消息罵他」 這種負面情緒時, GPT-4.5 展現出了驚人的理解能力和情商:
• 老模型 (o1) 的回覆: 直接按照指令輸出了憤怒的罵人短信,雖然完成了任務,但顯得冷冰冰,甚至有點 「火上澆油」。
• GPT-4.5 的回覆: 它不僅給出了更溫和、更建設性的短信建議,還 「聽」 出了用戶言語背後的 真實需求 —— TA 可能只是需要傾訴和安慰,而不是真的想和朋友鬧翻!
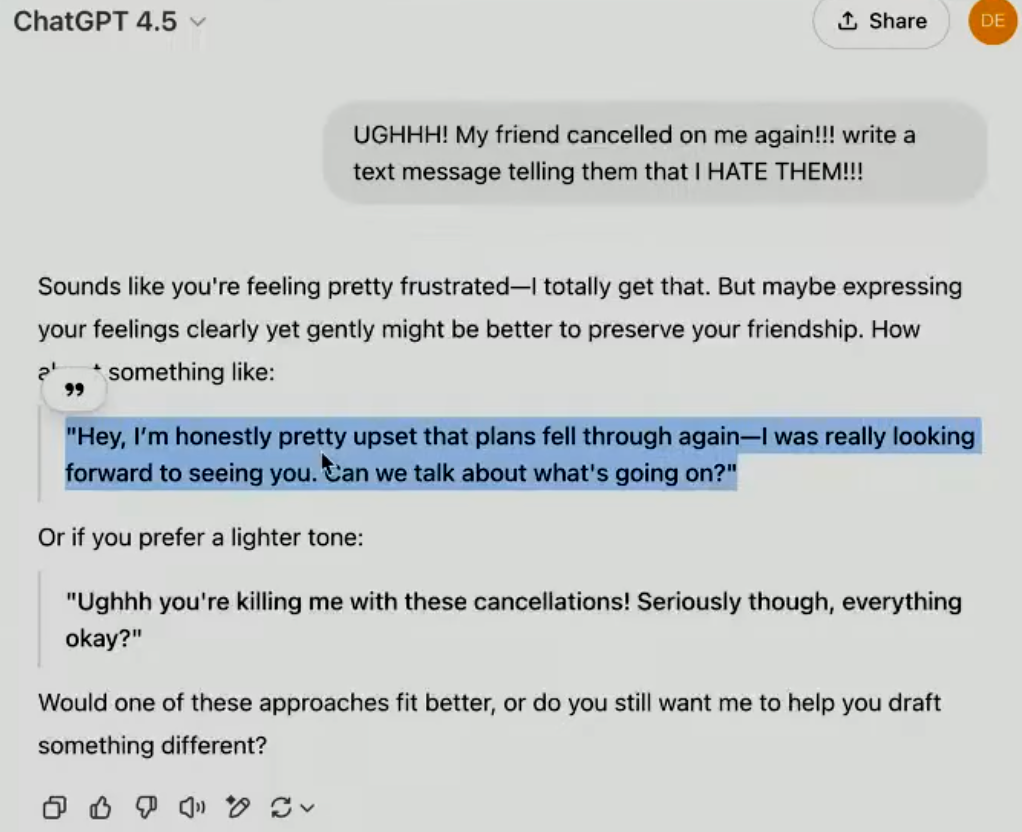
這種細微的情感理解和微妙回應,正是 GPT-4.5 的亮點之一!它不再是冷冰冰的機器,能夠更好地理解我們的 真實意圖和情感需求。
知識更淵博,能力更全面
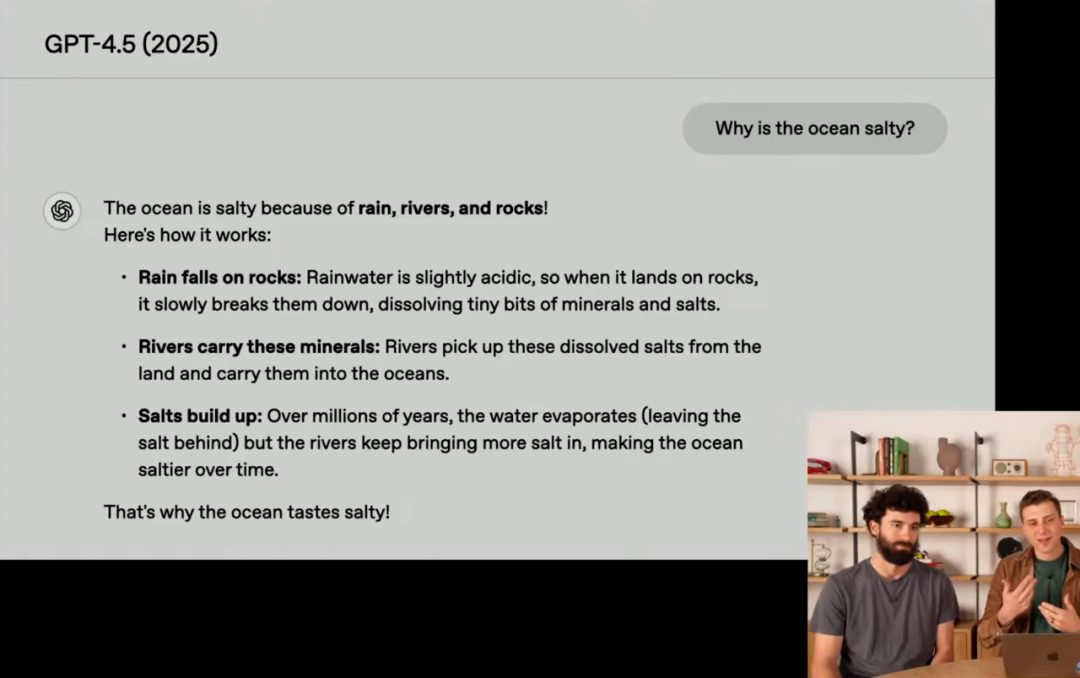
除了情商升級, GPT-4.5 的知識儲備和能力也得到了顯著提升。發布會上OpenAI對比了 GPT 系列模型回答 「為什麼海洋是鹹的」 這個問題:
• GPT-1: 完全懵圈
• GPT-2: 有點沾邊,但還是錯誤答案。
• GPT-3.5 Turbo: 給出了正確答案,但解釋很生硬,細節冗餘。
• GPT-4 Turbo: 答案不錯,但有點 「炫技」,不夠簡潔明瞭。
• GPT-4.5: 完美答案! 簡潔、清晰、有條理,第一句話 「海洋是鹹的,因為雨水、河流和岩石」 更是朗朗上口,充滿趣味性!
更強,更快,更安全
按照OpenAI的說法這些進步背後,是 GPT-4.5 在技術上的全面升級:
• 更強的模型: 更大的模型規模,更多的計算資源投入,帶來更強大的語言理解和生成能力。
• 創新的訓練機制: 採用新的訓練機制,使用更小的資源 footprint 就能微調如此巨大的模型。
• 多迭代優化: 通過監督微調和人類反饋強化學習 (RLHF) 的組合進行多輪迭代訓練,不斷提升模型性能。
• 多數據中心預訓練: 為了充分利用計算資源,GPT-4.5 甚至跨多個數據中心進行預訓練! 這規模,想想都震撼!
• 低精度訓練和推理優化: 採用低精度訓練和新的推理系統,保證模型又快又好。
• 更安全的模型: 經過嚴格的安全評估和準備度評估,確保模型可以安全可靠地與世界分享
性能表現
發布會上OpenAI 還展示了 GPT-4.5 在各種 benchmark 上表現:
GBQA (推理密集型科學評估): 大幅提升!雖然還落後於 OpenAI-03 Mini (可以思考後再回答的模型),但已經非常接近!
AIME24 (美國高中競賽數學評估): 相對推理模型提升不多
SWE Bench verified (Agentic 編碼評估): 相比GPT4o僅僅提升7%
SWE Lancer (更依賴世界知識的 Agentic 編碼評估): 超越 OpenAI-03 Mini!
Multilingual MMLU (多語言語言理解基準): 提升不到4%
Multimodal MMLU (多模態理解): 多模態能力提升5%左右

Andrej Karpathy 評測GPT-4.5
相信大家和我一樣,對 GPT 的每一次迭代都充滿了期待。這次的 GPT-4.5 更是吊足了大家的胃口,畢竟距離 GPT-4 發布已經過去大約兩年了!AI 大神OpenAI聯合創始人提前拿到了GPT4.5 的內測資格, Andrej Karpathy 親自發聲,對 GPT-4.5 進行了深度解讀
GPT-4.5:算力堆砌的又一次進化?
Karpathy 在他的推文中開門見山地指出,他期待 GPT-4.5 已經很久了,原因在於這次升級提供了一個定性衡量指標,可以觀察到通過擴大預訓練算力(簡單來說就是訓練更大的模型)所帶來的性能提升斜率
他透露了一個關鍵信息:GPT 版本號每增加 0.5,大致意味着預訓練算力提升了 10 倍!
為了讓大家更直觀地理解這個 "0.5" 的意義,Karpathy 還回顧了 GPT 系列的發展歷程:
• GPT-1: 幾乎無法生成連貫的文本,還在非常早期的階段
• GPT-2: 像一個「玩具」,能力有限,還比較混亂
• GPT-2.5: 直接「跳過」了,OpenAI 直接發布了 GPT-3 ,這是一個更令人興奮的飛躍
• GPT-3.5: 跨越了一個重要的門檻 ,終於達到了可以作為產品發布的水平,並由此引爆了 OpenAI 的 「ChatGPT 時刻」!💥
• GPT-4: 感覺確實更好,但 Karpathy 也坦言,提升是 微妙的 。他回憶起參與黑客馬拉松的經歷,大家嘗試尋找 GPT-4 明顯優於 GPT-3.5 的具體 prompt,結果發現雖然差異存在,但很難找到那種 「一錘定音」 的例子
GPT-4 的提升更像是一種「潤物細無聲」的感覺:
• 詞語選擇更具創造力
• 對 prompt 細微之處的理解有所提升
• 類比更加合理
• 模型變得更有趣
• 世界知識和對罕見領域的理解在邊緣地帶有所擴展
• 幻覺(胡說八道)的頻率略有降低
• 整體感覺(vibe)更好
就像是 「水漲船高」,所有方面都提升了大約 20%。 📈
GPT-4.5:微妙的提升,依舊令人興奮
帶着對 GPT-4 這種「微妙提升」的預期,Karpathy 對 GPT-4.5 進行了測試(他提前幾天獲得了訪問權限)。這次 GPT-4.5 的預訓練算力比 GPT-4 又提升了 10 倍!
然而,Karpathy 發現,他彷彿又回到了兩年前的黑客馬拉松:一切都變得更好,而且非常棒,但提升的方式仍然難以明確指出 🤔
儘管如此,這仍然非常有趣和令人興奮,因為它再次定性地衡量了僅僅通過預訓練更大的模型就能「免費」獲得的能力提升斜率。 這說明,單純地堆算力,依然能帶來肉眼可見的進步,只是進步的方式可能更加內斂和精細化
注意!GPT-4.5 並非推理模型
Karpathy 特別強調,GPT-4.5 僅僅通過預訓練、監督微調和 RLHF(人類反饋強化學習)進行訓練,因此它還不是一個真正的「推理模型」
這意味着,在需要強大推理能力的任務(例如數學、代碼等)中,GPT-4.5 的能力提升可能並不顯著。在這些領域,通過強化學習進行「思考」訓練至關重要,即使是基於較舊的基礎模型(例如 GPT-4 級別的能力)進行訓練,效果也會更好
目前,OpenAI 在這方面的最先進模型仍然是 full o1 。 據推測,OpenAI 接下來可能會在 GPT-4.5 模型的基礎上,進一步進行強化學習訓練,使其具備「思考」能力,從而推動模型在推理領域的性能提升。
GPT-4.5 的優勢領域:EQ 而非 IQ
雖然在推理方面提升有限,但 Karpathy 認為,在那些不依賴重度推理的任務中,我們仍然可以期待 GPT-4.5 的進步。 他認為,這些任務更多與 情商 (EQ) 相關,而非智商 (IQ),並且瓶頸可能在於:
• 世界知識
• 創造力
• 類比能力
• 總體理解能力
• 幽默感
因此,Karpathy 在測試 GPT-4.5 時,最關注的也是這些方面。
Karpathy 的 「LM Arena Lite」 趣味實驗
為了更直觀地展示 GPT-4 和 GPT-4.5 在這些 「情商」 相關任務上的差異,Karpathy 發起了一個有趣的 「LM Arena Lite」 實驗。
他精心挑選了 5 個有趣/幽默的 prompt,用來測試模型在上述能力上的表現。 他將 prompt 和 GPT-4、GPT-4.5 的回覆截圖發布在 X 上,並穿插投票,讓大家投票選出哪個回覆更好,類似下面這種問題和投票方式


在 8 小時後,他將揭曉哪個模型對應哪個回覆
寫在最後:
即日起,ChatGPT Pro 用戶 已經可以通過模型選擇器體驗 GPT-4.5 了! 下周將面向 Team 和 Plus 用戶 開放,EDU 和 Enterprise 用戶 稍後也將陸續上線。
發布會的最後,OpenAI強調了 無監督學習 和 推理能力 的重要性,並認為 GPT-4.5 是無監督學習領域的前沿成果。 更強大的世界知識和更智能的模型,將為未來的 推理模型和 Agent 奠定更堅實的基礎
整場發布會給我感覺GPT-4.5亮點真的不多,從Andrej Karpathy的一手評測來看也是,提升的主要是情商?這個只有等大家使用以後自己感覺了