作者 | 程茜
編輯 | 心緣
智東西2月27日報道,啱啱,DeepSeek開源周第四彈來襲,豪氣一舉開源三個代碼庫。
DualPipe:一種雙向流水線並行算法,用於V3/R1訓練中的計算-通信重疊;EPLB:用於V3/R1的專家並行負載均衡器;profile-data:訓練和推理框架的分析數據。

DualPipe通過重疊計算和通信來減少訓練的空閒時間,EPLB平衡了工作負載,使得幾乎沒有GPU閒置的情況,
值得一提的是,DualPipe的開發人員中有梁文峯參與。

DeepSeek的評論區開發者們依然持續誇誇誇,有人稱其「打開了最後的封印」。
有人開始稱讚DeepSeek的團隊合作能力。
依然有網友在擔心自己的英偉達股票:

GitHub地址:
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
一、DualPipe:雙向流水線並行算法
DualPipe是DeepSeek-V3技術報告中介紹的一種創新的雙向Pipeline並行算法。它實現了前向和後向計算通信階段的完全重疊,也減少了流水線氣泡。
在兩個方向上,8個PP列和20個微批的DualPipe調度示例,其中兩個被共享黑邊包圍的單元具有相互重疊的計算和通信。

流水線氣泡和內存使用情況比較:

𝐹表示前向塊的執行時間,B表示完全後向塊的執行時間,W表示「權重後向」塊的執行時間,𝐹&𝐵表示兩個相互重疊的前向和後向塊的執行時間。
快速啓動:

注:對於實際應用程序,開發者需要實現一個定製的overlapped_forward_backward方法,以適應特定模塊。
開發要求PyTorch 2.0 and above PyTorch 2.0及以上。
二、負載均衡算法EPLB,涵蓋分層負載平衡和全局負載平衡
開源的另一個代碼庫是EPLB。

當使用專家並行(EP)時,不同的專家被分配到不同的GPU。由於不同專家的負載可能會因當前工作負載而異,因此保持不同GPU的負載平衡非常重要。正如DeepSeek-V3論文中所述,研究人員採用冗餘專家策略,複製重載專家。然後將重複的專家打包到GPU上,以確保不同GPU之間的負載平衡。
此外,由於DeepSeek-V3中使用的組限制專家路由,DeepSeek還嘗試將同一組的專家放置到同一節點,以儘可能減少節點間的數據流量。
為了便於複製和部署,DeepSeek在eplb.py中開源了EP負載均衡算法。該算法計算一個平衡的專家複製和放置計劃的基礎上估計的專家負載。
負載平衡算法有分層負載平衡和全局負載平衡兩種策略,可用於不同的情況。
當服務器節點的數量除以專家組的數量時,其使用分層負載平衡策略來利用組限制的專家路由。首先將專家組均勻打包到節點上,確保不同節點的負載均衡。然後在每個節點內複製專家,最後將複製的專家打包到各個GPU,以確保不同的GPU負載平衡。分層負載均衡策略可以在預填充階段使用,專家並行規模較小。
其他情況下使用全局負載平衡策略,在全局範圍內複製專家,而不考慮專家組,並將複製的專家打包到單個GPU。該策略可用於專家並行度較大的解碼階段。
接口和示例:負載均衡器的主要功能是eplb.rebalance_experts。
下面的代碼演示了一個兩層MoE模型的示例,每層包含12個專家,每層引入4個冗餘專家,在2個節點上放置16個副本,每個節點包含4個GPU。

三、在DeepSeek Infra中分析數據
最後一個是DeepSeek訓練和推理框架的分析數據。
使用PyTorch Profiler捕獲分析數據。下載後,開發者可以通過在Chrome瀏覽器中導航到Chrome://跟蹤(或在Edge瀏覽器中導航到edge://跟蹤)來直接將其可視化。他們模擬了一個絕對平衡的MoE路由策略來進行性能分析。
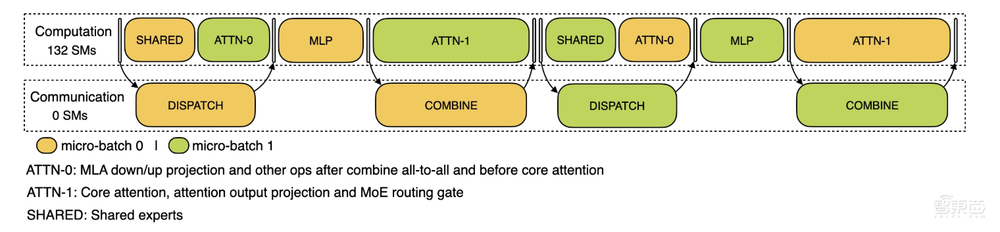
訓練配置文件數據展示了其在DualPipe中針對一對單獨的向前和向後塊的重疊策略。每個塊包含4個MoE層。並行配置與DeepSeek-V3預訓練設定對齊:EP 64,TP 1,4K序列長度。為了簡單起見,在分析期間不包括PP通信。

推理過程,對於預填充,該配置文件採用EP 32和TP 1(與DeepSeek V3/R1的實際在線部署一致),提示長度設定為4K,每個GPU的批量大小為16 K令牌。在我們的預填充階段,我們利用兩個微批來重疊計算和所有對所有的通信,同時確保注意力計算負載在兩個微批之間平衡-這意味着相同的提示可以在它們之間分割。
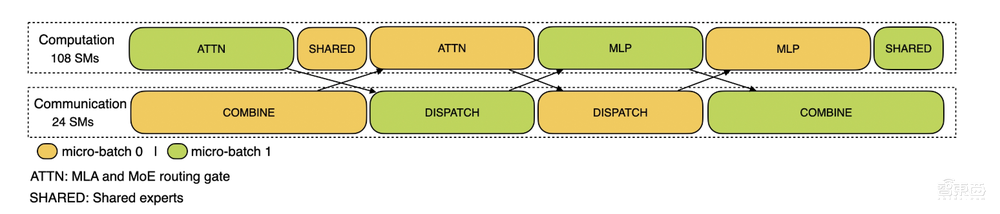
對於解碼,該配置文件採用EP 128,TP 1和4K的提示長度(與實際在線部署配置密切匹配),每個GPU的批量大小為128個請求。與預填充類似,解碼也利用兩個微批進行重疊計算和全對全通信。然而,與預填充不同,解碼期間的全對全通信不佔用GPU SM:在發出RDMA消息後,所有GPU SM被釋放,並且系統在計算完成後等待全對全通信完成。