「DeepSeek有效地駁斥了頻繁出現的在訓練方面‘他們撒謊了’的言論。」
舊金山人工智能行業解決方案提供商 Dragonscale Industries 的首席技術官 Stephen Pimentel在X上如是評論DeepSeek「開源周」。
「是的。以及關於5萬張H100的虛假傳聞(也被駁斥了)……」全球諮詢公司DGA Group合夥人、中美技術問題專家Paul Triolo也附和道。
DeepSeek「開源周」從2月24日至2月28日,共持續5天。會陸續開源5個項目。
過去三天的開源項目分別是:
l Day1:FlashMLA,針對英偉達Hopper架構GPU的高效MLA(多頭潛在注意力)解碼內核;
l Day2:DeepEP,首個用於MoE(混合專家)模型訓練和推理的開源EP(專家並行)通信庫;
l Day3: DeepGEMM,支持稠密和MoE模型的FP8計算庫,可為V3/R1的訓練和推理提供強大支持。
剛進行到第三天,「開源周」已經讓懷疑DeepSeek在訓練成本上「撒謊」的人噤聲了。因為每個開源項目都在向世界展示DeepSeek極致壓榨英偉達芯片的功力。
還有什麼比「貼臉開大」更能打敗質疑的呢?

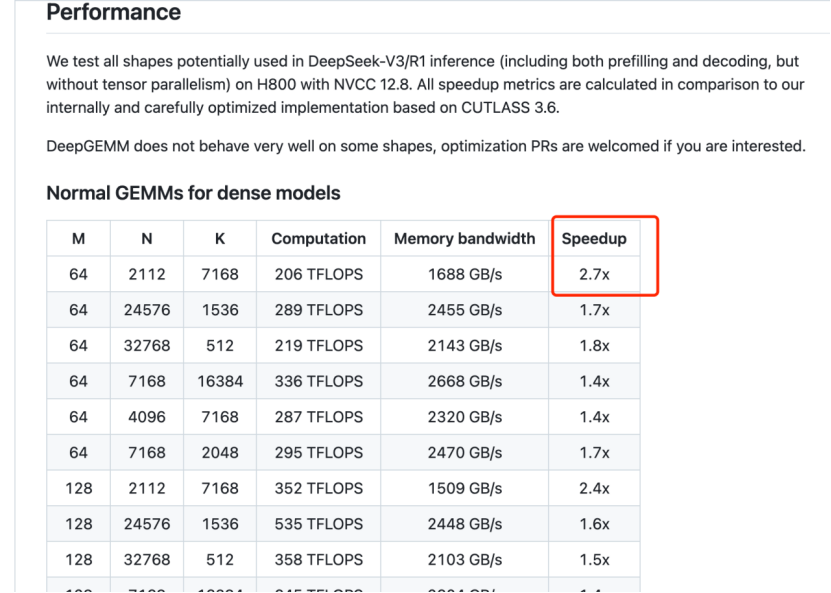
我們先來看看DeepSeek最新開源的DeepGEMM,只能說,在壓榨英偉達芯片、AI性能效率提高這方面,DeepSeek已經出神入化。
這是當初團隊專門給V3模型用的,現在就這麼水靈靈地開源了,要不怎麼說DeepSeek的誠意實在感人呢。
在GitHub上發布不到10個小時,就已經有2.6千個星星了。要知道一般來說,在GitHub上獲得幾千星星就已經算很成功了。

「DeepGEMM像是數學領域的超級英雄,快過超速計算器,強過多項式方程。我嘗試使用DeepGEMM時,現在我的GPU在計算時以每秒超過1350 TFLOPS(萬億次浮點運算)的速度運轉,好像已經準備好參加AI奧運會了!」一位開發者興奮地在X上表示。

DeepSeek新開源的DeepGEMM究竟是什麼、意味着什麼?
DeepSeek官方介紹DeepGEMM是一個支持密集型和MoE 模型的FP8 GEMM庫:
l 無重度依賴,像教程一樣簡潔;
l 完全JIT(即時編譯)
l 核心邏輯約300行代碼,在大多數矩陣尺寸下優於經過專家調優的內核
l 同時支持密集佈局和兩種MoE佈局
一句話定義:DeepGEMM是一款專注於FP8高效通用矩陣乘法(GEMM)的庫,主要滿足普通矩陣計算以及混合專家(MoE)分組場景下的計算需求。
利用該庫,能夠動態優化資源分配,從而顯著提升算力效率。
在深度學習中,FP8(8位浮點數)可以減少存儲和計算的開銷,但是缺點(特點)也有,那就是精度比較低。如果說高精度格式是無損壓縮,那FP8就是有損壓縮。大幅減少存儲空間但需要特殊的處理方法來維持質量。而由於精度低,就可能產生量化誤差,影響模型訓練的穩定性。
在報告中DeepSeek介紹:「目前,DeepGEMM僅支持英偉達Hopper張量核心。為了解決FP8張量核心積累的精度問題,它採用了CUDA核心的兩級積累(提升)方法。」
而DeepSeek為了讓FP8這種速度快但精度偏低的計算方式變得更準確,利用了CUDA核心做了兩次累加,先用FP8做大批量乘法,然後再做高精度匯總,以此防止誤差累積。既大幅減少空間,同時又保有精度,效率也就由此提升。
JIT(即時編譯)和Hooper張量核心也是絕配。
Hopper張量核心是專門為高效執行深度學習任務而設計的硬件單元,而JIT則意味着允許程序在運行時根據當前硬件的實際情況,動態地編譯和優化代碼。比如,JIT編譯器可以根據具體的GPU架構、內存佈局、計算資源等實時信息來生成最適合的指令集,從而充分發揮硬件性能。
最最最驚人的是,這一切,都被DeepSeek塞進了約300行代碼當中。
DeepSeek自己也說:「雖然它借鑑了一些CUTLASS和CuTe的概念,但避免了對它們模板或代數的過度依賴。相反,該庫設計簡單,只有一個核心內核函數,代碼大約有300行左右。這使得它成為一個簡潔且易於學習的資源,適用於學習Hopper FP8矩陣乘法和優化技術。」
CUTLASS是英偉達自家的CUDA架構,專門給英偉達GPU來加速矩陣計算。畢竟官方出品,它的確非常好用。但它同時也很大很沉,如果手裏的卡不太行,那還真不一定跑得了。
喫不上的饅頭再想也沒用啊,而DeepSeek的極致壓榨哲學就在這裏閃爍光芒了。優化更激進、更聚焦,也更輕。
輕的同時表現也很好,在報告中,DeepSeek表示,DeepGEMM比英偉達CLUTLASS 3.6的速度提升了2.7倍。
還記得DeepSeek在春節時大火,人們使用後都在為其「科技浪漫」風觸動不已。
如今看來,DeepSeek的「科技浪漫」絕不僅僅在最終呈現給用戶的文字當中,DeepGEMM就像一把鋒利的小刀,在英偉達芯片上雕出漂亮的小花,線條簡潔又優雅。

不僅是DeepGEMM,DeepSeek前兩個開源項目也將其「科技美學」體現得淋漓盡致。
第一天,DeepSeek開源了FlashMLA。
用DeepSeek的話說,這是「用於Hopper GPU的高效MLA解碼內核,針對可變長度序列進行了優化。」
略過技術細節,我們來看看FlashMLA如何發揮作用。
首先,在大型語言模型推理時,高效的序列解碼對於減少延遲和提高吞吐量至關重要。FlashMLA針對變長序列和分頁KV緩存的優化,使其非常適合此類任務。
其次,像聊天機器人、翻譯服務或語音助手等應用需要低延遲響應。FlashMLA的高內存帶寬和計算吞吐量確保這些應用能夠快速高效地返回結果。
以及,在需要同時處理多個序列的場景(如批量推理)中,FlashMLA能夠高效地處理變長序列並進行內存管理,從而確保最佳性能。
最後,研究人員在進行新的AI模型或算法實驗時,可以使用FlashMLA加速實驗和原型開發,尤其是在處理大規模模型和數據集時。
還是兩個字:壓榨。在報告當中,DeepSeek表示,這個工具專門針對英偉達H800做優化——在H800 SXM5平台上,如內存受限最高可以達到3000GB/s,如計算受限可達峯值580 TFLOPS。
第二天,DeepSeek開源了DeepEP。
用DeepSeek的話說,這是「首個用於 MoE 模型訓練和推理的開源 EP 通信庫」。
MoE即混合專家(Mixture of Experts),這種架構利用多個「專家」子模型來處理不同的任務。和使用單一大模型處理所有任務不同,MoE根據輸入選擇性地激活一部分專家,從而使模型更高效。
順帶一提,MoE和前文提到的MLA(多頭潛在注意力)正是DeepSeek所使用的降低成本的關鍵先進技術。
而DeepEP當中的EP則是指專家並行(Expert Parallelism),是MoE中的一種技術,讓多個「專家」子模型並行工作。
DeepEP這個庫,可以在加速和改善計算機(或GPU)之間在處理複雜機器學習任務時的通信,特別是在涉及混合專家(MoE)模型時。這些模型使用多個「專家」(專門的子模型)來處理問題的不同部分,而DeepEP確保數據在這些專家之間快速而高效地傳遞。
就像是機器學習系統中一個聰明的交通管理員,確保所有「專家」能夠按時收到數據並協同工作,避免延遲,使系統更加高效和快速。
假設你有一個大型數據集,並且想讓不同的模型(或專家)處理數據的不同部分,DeepEP會將數據在合適的時機發送給正確的專家,讓他們無需等待或造成延遲。如果你在多個GPU(強大的處理器)上訓練機器學習模型,你需要在這些GPU之間傳遞數據。DeepEP優化了數據在它們之間的傳輸方式,確保數據流動迅速而順暢。
即便你不是一個開發者,對以上內容並不完全理解,也能從中讀出兩個字來:高效。
這正是DeepSeek開源周所展現的核心實力——這家公司究竟是怎樣最大化利用有限的資源的。

自從DeepSeek開啓開源周,就不怎麼見到此前對其發出質疑的人再有什麼評論了。
正如本文開頭引用Pimentel的辣評:「DeepSeek有效地駁斥了頻繁出現的在訓練方面‘他們撒謊了’的言論。」
在去年12月關於V3的技術報告中,DeepSeek表示該模型使用了大約2000塊英偉達H800進行訓練,成本約為600萬美元。這個成本遠低於規模更大的競爭對手,後者動輒就是幾十億、上萬億美元的投入,OpenAI甚至在DeepSeek的R1模型走紅前,啱啱和甲骨文、軟銀攜手宣佈了5000億美元的合資項目。
這也引發了對DeepSeek在開發成本方面誤導公衆的指控。
持有懷疑態度的包括但不限於Anthropic創始人達里奧·阿莫迪(Dario Amodei)、Oculus VR的創始人帕爾默·盧基(Palmer Luckey)。Oculus已經被Meta收購。
盧基就稱,DeepSeek的預算是「虛假的」,而阿莫迪乾脆撰寫檄文呼籲美國加強芯片出口管制,指責DeepSeek「偷偷」用了大量更先進的芯片。
這些批評聲並不相信DeepSeek自己的表態——DeepSeek 在其技術報告中表示,高效訓練的祕訣是多種創新的結合,從MoE混合專家架構到MLA多頭潛在注意力技術。
如今,DeepSeek開源周零幀起手,就從這些技術的深度優化方面做開源。
Bindu Reddy在X上表達振奮的心情:「DeepSeek正在圍繞MoE模型訓練和推理開源極高效的技術。感謝DeepSeek,推動AGI的發展,造福全人類。」Reddy曾在谷歌擔任產品經理、在AWS擔任人工智能垂直領域總經理並,後創辦Abacus AI,是開源路線的信仰者。
有媒體評論道:「對於熱愛人工智能的人來說,FlashMLA就像一股清新的空氣。它不僅關乎速度,還為創造力和協作開闢了新途徑。」
在Github相關開源項目的交流區,不僅有技術交流,也有不少讚美之聲,甚至有中文的「到此一遊」打卡貼。在中文互聯網上,人們已經開始把DeepSeek稱為「源神」。
DeepSeek有自己的難題嗎?當然有,比如商業化這個老大難問題,DeepSeek或許也得面對。但在那之前,它先將壓力給到了對手。
同樣是在Github的交流區,不少人想起了OpenAI,將DeepSeek稱為「真正的OpenAI」。OpenAI已經走上閉源之路好幾年,甚至被戲稱為「CloseAI」,直到DeepSeek出現,OpenAI的CEO山姆·奧特曼(Sam Altman)才終於鬆口,稱在開源/閉源的問題上,自己或許站在了歷史錯誤的一邊。
一周前,他曾經在X上發起投票,詢問粉絲希望OpenAI的下一個開源項目是什麼類型的。
不過到目前為止,這一切都還在承諾中,並未見之於世。
另一邊,馬斯克的xAI,仍然在新一代發布時,開源上一代大模型。啱啱發布了Grok 3,宣佈會開源Grok 2。
與此同時,DeepSeek的開源周,讓更多人擔心起英偉達,這個在AI浪潮中最大的受益者之一。
有人看着DeepSeek的開源項目一個接一個發布,在X上表示:「這是第三天看到我的英偉達股票正在火上烤。」
北京時間2月27日,既是DeepSeek開源周的第四天,是OpenAI放出開源信號的第九天,也是英偉達財報發布的日子。
OpenAI的開源項目會來嗎?英偉達的股價能穩住嗎?DeepSeek還將開源什麼?人工智能戰場上,總是不缺少令人期待答案的問號。