蘋果的研究人員開源了最新通用多模態視覺模型AIMv2,有300M、600M、1.2B和2.7B四種參數,整體能耗很低,可以適用於手機、PC等不同類型的設備。
與傳統視覺模型不同的是,AIMV2 使用了一種創新的多模態自迴歸預訓練方法,將視覺與文本信息深度融合,為視覺模型領域帶來了新的技術突破。
簡單來說,就是AIMV2 不再侷限於僅處理視覺信息的傳統模式,而是將圖像和文本整合為統一的序列進行預訓練。在這個過程中,圖像被劃分為一系列不重疊的Patches,形成圖像token序列。
文本則被分解為子詞令牌序列,然後將兩者拼接在一起。這種獨特的拼接方式使得文本令牌能夠關注圖像令牌,實現了視覺與文本信息的交互融合。
例如,在處理一張風景圖片和相關描述文字時,AIMV2可以通過這種融合方式更好地理解圖片中的元素與文字描述之間的對應關係,包括圖片中的山脈、河流等元素與文字中提及的自然景觀特徵的關聯。

開源地址:https://github.com/apple/ml-aim
Huggingface地址:https://huggingface.co/collections/apple/aimv2-6720fe1558d94c7805f7688c
AIMV2技術架構
在以往的研究中,專家模型被設計來最大化特定任務的性能,而通用模型則能夠被部署在多個預定義的下游任務中,僅需最小的調整。
但隨着大語言模型GPT系列的成功,預訓練模型已成為自然語言處理領域的主流範式。這些模型通過生成預訓練或對比學習等方法,學習了大量的語言表示。在機視覺領域,儘管生成預訓練在語言模型中佔據主導地位,但在視覺模型中的表現卻落後於判別方法。
AIMV2的核心技術在於其多模態自迴歸預訓練框架。這一框架將圖像和文本整合到一個統一的序列中,使得模型能夠自迴歸地預測序列中的下一個標記,無論它屬於哪種模態。

在預訓練階段,AIMV2使用一個因果多模態解碼器,首先回歸圖像塊,然後以自迴歸的方式解碼文本標記。這種簡單的方法有幾個巨大技術優勢:AIMV2易於實現和訓練,不需要非常大的批量大小或特殊的跨批次通信方法;
AIMV2的架構和預訓練目標與LLM驅動的多模態應用非常吻合,可以實現無縫集成;AIMV2從每個圖像塊和文本標記中提取訓練信號,提供了比判別目標更密集的監督。
訓練流程與測試數據
在預訓練目標方面,AIMV2定義了圖像和文本領域的單獨損失函數。文本領域的損失函數是標準的交叉熵損失,用於衡量每一步中真實標記的負對數似然。圖像領域的損失函數是像素級的迴歸損失,模型預測的圖像塊與真實圖像塊進行比較。
整體目標是最小化文本損失和圖像損失的加權和。這種損失函數的設計旨在平衡模型在圖像和文本兩個領域的性能,同時鼓勵模型學習到能夠準確預測兩個模態的表示。
AIMV2的預訓練過程涉及到大量的圖像和文本配對數據集。這些數據集不僅包括公開的DFN-2B和COYO數據集,還包括蘋果公司的專有數據集HQITP。這些數據集的結合為AIMV2提供了豐富的預訓練數據,使其能夠在多種下游任務中表現出色。
預訓練過程中,圖像被劃分為非重疊的圖像塊,文本序列被分解為子詞,然後這些序列被連接起來,允許文本標記關注圖像標記。這種處理方式使得AIMV2能夠處理不同分辨率和長寬比的圖像,提高了模型的靈活性和適應性。
在性能測試方面,AIMV2在多個領域展現出了卓越的性能。在圖像識別方面,AIMV2在ImageNet-1k數據集上達到了89.5%的準確率,這還是在凍結模型主幹的情況下完成的。
此外,與其他視覺語言預訓練基線模型相比,AIMV2 同樣展現出了高度競爭的性能。例如,在ViT-Large容量下,AIMV2 在大多數基準測試中優於OAI CLIP,並在 IN-1k、iNaturalist、DTD和 Infographic 等關鍵基準測試中超越了DFN-CLIP 和 SigLIP。
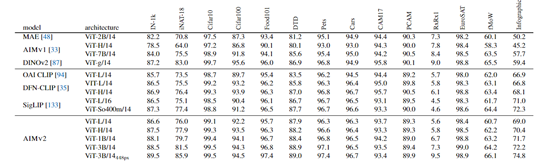
值得注意的是,AIMV2 在訓練數據量僅為 DFN-CLIP 和 SigLIP 的四分之一(12B vs. 40B)的情況下,仍能取得如此優異的成績,且訓練過程更加簡便、易於擴展。
此外,AIMV2在開放詞彙對象檢測和指代表達理解等任務上也表現出色,顯示出其在多模態任務中的廣泛適用性。
本文素材來源蘋果,如有侵權請聯繫刪除