DeepSeek利潤神話背後:大廠AI的焦慮和自救
作者 | 定焦One 王璐
AI似乎成了大廠的“救命稻草”。
無論財報裏的亮點數據,還是隔三岔五的利好信息,都離不開AI。
比如在百度2024年這份喜憂參半的財報中,高光時刻基本都是AI給的:
文心大模型日均調用量持續高速增長,一年增長33倍至16.5億。百度文庫付費用戶超4000萬,位居全球第二、中國第一。
阿里也憑藉着AI在開年來了三連擊:
先是受DeepSeek影響,同爲開源大模型的阿里通義千問(Qwen)受到關注;接着發佈的最新模型Qwen2.5-Max,被評價爲性能超越DeepSeek V3;隨後又宣佈與蘋果就AI業務達成合作,股價猛漲。
不過,DeepSeek出圈 近40天以來,大廠AI承受的焦慮多過收穫,畢竟各家都投入了大量人力、物力、財力,最後一鳴驚人的卻是一個初創團隊做出的產品。這兩天,DeepSeek還首次公開了爆炸性消息——其成本利潤率高達545%(理論收益),利潤理論上可達每天346萬元。
在種種衝擊之下,大廠紛紛改變路線,一邊打不過就加入,紛紛宣佈接入DeepSeek,一邊將自家大模型從閉源轉向開源,甚至不惜自斷一條商業化路徑,將C端產品免費。
可是,這波操作,真能治好大廠的AI焦慮症嗎?
大廠AI,做得怎麼樣了?
在DeepSeek出現前,大廠做AI的路線是高舉高打、重投入,圍繞自身優勢做產品。
大模型被視爲AI行業的基礎設施,互聯網大廠(百度、騰訊、阿里、字節、快手等)、消費電子廠商(華爲爲代表)、智能語音廠商(科大訊飛等),都推出了自研大模型。相比“AI六小虎”這類初創公司,大廠的優勢在於具備更雄厚的資金和人才儲備。
從AI行業整體技術迭代速度,以及各家的公開信息來看,大廠大模型在底層技術上沒有根性本差別,但在入場時間、模型定位、市場策略上有所不同,具體區別如下:
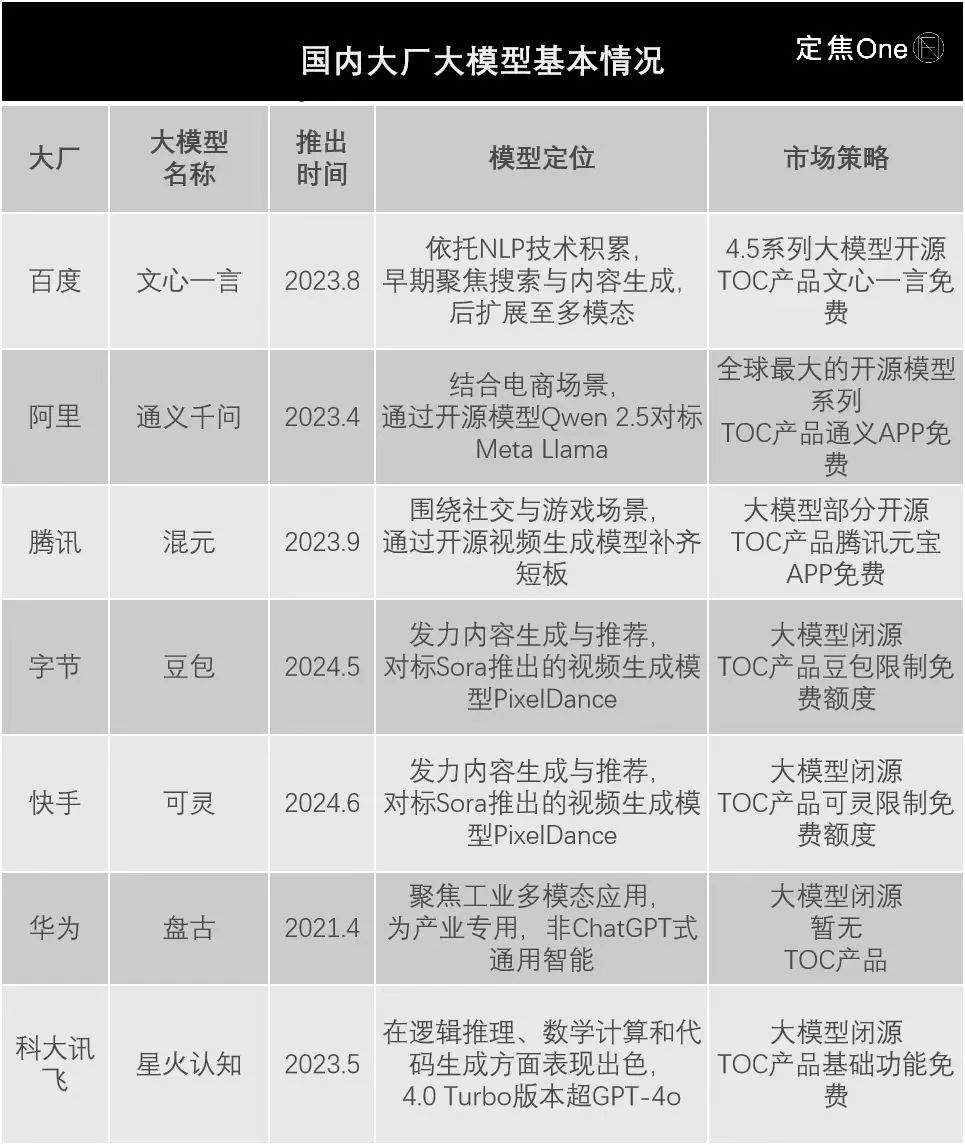
這三大不同,在一定程度上代表的是大廠早期對AI的態度和定位。
比如大模型發佈的時間,“早”代表的是該大廠在相關技術領域有較早佈局和技術積累,且反應較快,但風險是技術尚未完全成熟,投入的技術研發和市場推廣費用相對更高。
從上表來看,華爲最早,但需要注意的是,雖然其底層也是基於Transformer架構,但與ChatGPT式對話完全不同,屬於AI大模型在“產業專用”方向(ChatGPT式爲通用智能)。如果聚焦通用智能大模型,則是百度最早行動,在2023年3月便啓動了文心一言大模型的邀測(非全面開放)。
不過,推出時間早晚並不是衡量模型好壞的核心要素。
大廠的業務佈局決定着大模型的應用方向,也造就了不同大模型定位,從技術上挖掘,其來源於各家的訓練數據。
百度文心一言主要靠互聯網文本數據;阿里通義千問爲文本、圖片、音頻等多模態數據;騰訊混元爲社交網絡和用戶行爲數據;字節豆包約50%-60%來自字節的自有業務(抖音、今日頭條)數據;華爲盤古大模型則是用了包含工業、氣象、文圖、圖像在內的各類數據。
這也讓各家大模型的優勢場景不同,比如文心一言在長文本處理和多語種對話上佔優;混元在社交場景更勝一籌;豆包在生成內容和精準推薦上更爲領先;通義千問在電商推薦場景響應更快;盤古執行速度和泛化能力出色,能高效應對大規模任務。
不難發現,各家大模型的優勢領域都有着其核心業務的影子。
最後看市場策略,在一定程度上反映的是,大廠對自身能力和行業趨勢的判斷,外界可大致觀察到的內容分爲兩塊,開閉源與TO C產品是否免費。
字節、快手、訊飛、華爲目前還在堅持閉源,百度、騰訊、阿里則選擇大部分開源。在TO C應用上,百度、騰訊、阿里選擇了免費路線,字節、快手、訊飛多爲提供有限次數的免費額度。
開源的甜頭已經被阿里喫到,開源AI平臺Hugging Face發佈的最新開源大模型榜單顯示,排名前十的開源大模型全部是基於阿里通義千問的衍生模型。
在TO C產品中,堅持免費的豆包在一年中漲勢最猛。根據AI產品榜顯示,2025年1月,豆包在國內千萬月活俱樂部中排名第一,爲7861萬,遠超其他大廠應用。
不過,大家更好奇的是大廠大模型整體能力的排名。據多位從業者分析,目前大廠的頂級大模型以閉源爲主,在信息不完全透明的情況下,判斷各家能力並非易事。
弗若斯特沙利文在《2024年中國大模型能力評測》報告中指出,百度文心一言、騰訊混元、阿里通義千問等大廠大模型都位於第一梯隊,認爲它們在技術能力上較爲全面,用戶量也相對較大。但哪家整體能力更爲出色,沒有給出明確判斷。
AI軟件工程師覃相表示,各家在技術架構和訓練數據等方面都存在差異,比如從技術架構來看,模型規模和參數量是衡量大模型複雜程度和能力的重要指標。一般來說,規模越大、參數越多,模型的學習能力和表達能力就越強。比如,DeepSeek-R1被稱作參數上的巨無霸,高達6710億的參數打造了一個龐大的知識儲備庫。
他表示,從這一維度判斷,在大廠裏的大模型中,具有深度推理能力的大模型,比如文心一言在一衆大廠中能力更強。但如果看垂直領域的能力,文心一言便比不上通義千問,畢竟後者開發並上線了基於自身的8個垂直領域模型。
總之,各家大模型的優勢都不一樣,很難有一家在各個維度上都碾壓其他家。
DeepSeek出圈40天,大廠四大轉變
DeepSeek的出現,促使大廠重新審視自身的AI戰略佈局,結合各家最新動態及從業者的說法,具體有四大轉變。
一是從閉源到開源,這也是最重大的轉變。
不止一位從業者指出,DeepSeek的火爆離不開開源。
之前國內外對大模型開閉源的討論一直沒有停過,百度董事長李彥宏曾是閉源的忠實支持者,認爲無論保持技術領先性還是商業模式,閉源都強於開源。
覃相從技術角度分析,開源意味着核心代碼公開,競爭對手可快速復現技術路徑,大廠早期選擇閉源主要是爲了保護知識產權和商業壁壘(如OpenAI早期未開源GPT-3)。
但他發現,在DeepSeek的帶動下,大廠已經轉變了方向,更傾向於通過生態綁定(如騰訊混元開源視頻模型,吸引開發者使用其雲服務)實現長期收益,而不像之前那樣單純依賴技術保密。
如今百度已經宣佈文心大模型4.5系列將於2025年6月底全面開源。截至目前,百度、阿里、騰訊的大部分模型都已經開源或者宣佈開源。
二是業務重點從TO B轉向“雙線並行”。
覃相解釋,大模型變現主要有三種方式:增值服務、數據變現、合規服務,其中增值服務佔比最大,靠的是企業級定製與API調用收入。他透露,百度文心一言企業版年費超千萬元,阿里雲通義千問爲政企客戶提供定製化客服系統,單項目合同額可達數億元。
也就是說,大廠當前盈利仍主要依賴B端,但近期很多大廠開始重視TO C應用的推廣,改爲TO B、TO C“雙線並行”。
例如騰訊加大對元寶的宣傳,一方面將其接入到微信九宮格,擁有了強流量入口,另一方面多渠道打廣告,除了在騰訊生態產中做推廣外,抖音、B站、知乎也做了大量投放。
根據App Growing數據顯示,在2月廣告投放強度前20中的AI工具中,大廠AI產品都有上榜(華爲沒有TOC產品未在其中)。其中花錢最多的便是騰訊元寶,今年2月,其投放金額佔比達到了總金額的46%,快趕上過去9個月的總和,超過了字節的豆包。
另外,阿里也大規模招聘TO C業務相關人才。
從業者認爲,可能是DeepSeek的開源+API低價給大廠TO B業務帶來了更大壓力,進而想在TO C上找到更多商業化出路。
方向轉變之三是TO C應用從收費變爲免費。
DeepSeek好用且免費,在它大火後,國內百度的文心一言、國外OpenAI將露面的GPT-5,都宣佈將免費對用戶開放。
“目的在於拉攏更多用戶,提高市場佔有率。”覃相表示,更多的用戶反饋可以進一步優化模型性能,從而提升B端服務能力,收取更高的企業定製模型費。
轉變之四是從重投入到降本打價格戰。
在過去幾年的“百模大戰”中,國內外AI大模型公司砸出了幾十億甚至上百億美元,而DeepSeek僅以557.6萬美元的GPU成本,就訓練出了與OpenAI o1能力不相上下的DeepSeekR1模型,這讓大廠開始反思。
不止一位從業者表示,大廠降本從去年下半年就已經開始,但DeepSeek的出現加速了這一趨勢。
覃相能明顯感覺到,從去年開始,大模型的競爭已經從“技術爲先”轉向爲“成本+生態”。比如去年1月豆包1.5Pro發佈的API價格就大幅下降,12月字節又將視覺模型價格降幅打到85%,推動行業進入“釐時代”。
今年2月,兩位老百度人還因爲大模型價格“隔空交戰”,百度智能雲事業羣總裁沈抖在百度智能雲事業羣組(ACG)全員會上指出,國內大模型行業存在“惡意價格戰”並點名豆包,隨後字節火山引擎總裁譚待在朋友圈回應,指出降價是技術進步的必然結果。
DeepSeek也沒閒着,剛宣佈完API優惠期結束,2月26日又宣佈“限時降價”,每日00:30-08:30,DeepSeek-V3降至原價的50%,DeepSeek-R1低至25%,降幅最高達75%。
大廠的壓力更大了。
免費、開源,大廠能否贏回主場?
綜合從業者的說法,在四大變化中,目前對大廠影響最大的是開源和免費。
先來看開源。
大模型領域專家劉聰指出,在DeepSeek沒露面前,無論國外的OpenAI,還是國內大廠,要麼選擇全部閉源,要麼選擇開源部分大模型(非最好版本),DeepSeek則是將其最厲害的推理大模型DeepSeek-R1也選擇了開源,這是從業者非常興奮的點。
不過,開源也面臨着一些收益損失和技術風險。
人工智能博士微涼表示,開/閉源代表的是間接/直接變現兩種商業模式和開發思路。國內大廠的典型開源代表是阿里通義千問大模型,通過給廠家做適配進一步促成商業上的合作,此舉是基於自身生態做出的選擇。
但很多大廠起初做大模型的定位是技術主導,將其視爲生產力,比如OpenAI、百度、華爲、科大訊飛,大模型訂閱費是很重要的一塊收入來源,選擇開源肯定會影響到收益。
開源還會面臨惡意攻擊和社區維護風險。比如在代碼公開下,惡意攻擊者可以通過分析代碼尋找漏洞,從而對使用這些模型的系統進行攻擊。
後續的社區維護也是個問題。覃相表示,開源需要持續投入資源維護開發者社區(如提供文檔、技術支持、版本更新),否則可能導致技術生態分散。他解釋,若開發者自行修改代碼並衍生出多個分支(如Linux的分支Ubuntu、CentOS),會加大統一技術標準的難度,導致“技術碎片化”。
部分從業者直言,即便大廠開源,對他們的吸引力也有限。
開源的目的是吸引技術開發者和合作公司,讓大家使用其大模型進行技術迭代和應用開發,但微涼博士認爲,“目前各家開源有打廣告嫌疑。”
“開源能看到的是大模型的推理方法和參數權重,但更重要的數據篩選方法和模型訓練技巧,各家都沒有放開,這也導致普通開發者很難去做技術迭代。”他表示。
值得注意的是,開源不等於全免費,使用者還要履行大模型提供商的開源協議,其中便包含“付費條款”。
比如微涼博士會用阿里通義千問大模型做一些AI應用,利用千問將技術跑通後,若想進一步做企業定製化微調和適配,便需要聯繫工作人員。他還透露,開源協議也會有公司規模等限制條款,比如員工人數達到一定數量時,就需要付費。
再來看免費帶來的影響。
大廠採取免費策略的目的是想快速佔領C端市場,比如突出代表便是一直對用戶免費的豆包,QuestMobile數據顯示,截至2025年2月9日,豆包週日均(以2月3日-2月9日這一週爲週期,計算平均每天的活躍用戶數)活躍用戶數爲1845萬,僅次於DeepSeek,高於Kimi、文小言、通義、元寶。
不過免費的意義有多大,從業者還拿不準。這既因爲用戶對chatbot這類工具的忠誠度很低,也因爲國內用戶的付費意識並不強。
“即便是需要付費的AI生成視頻工具,國內大部分應用也靠提供免費積分來吸引用戶使用。”一位從業者表示,他覺得豆包能在一衆同類通用型AI產品中跑出來,除免費外,和字節強大的市場推廣也分不開。
覃相認爲,DeepSeek的鯰魚效應倒逼大廠從技術競賽轉向成本與生態的綜合較量, 開源、免費策略是一把應對競爭與生態構建的“雙刃劍” ,即便這些措施短期內會降低自身收益,也不得不爲。
DeepSeek引發的鮎魚效應,還未結束。
免責聲明:投資有風險,本文並非投資建議,以上內容不應被視為任何金融產品的購買或出售要約、建議或邀請,作者或其他用戶的任何相關討論、評論或帖子也不應被視為此類內容。本文僅供一般參考,不考慮您的個人投資目標、財務狀況或需求。TTM對信息的準確性和完整性不承擔任何責任或保證,投資者應自行研究並在投資前尋求專業建議。
熱議股票
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10