周六,國內AI大模型公司DeepSeek官方賬號在知乎首次發布《DeepSeek-V3/R1推理系統概覽》技術文章,不僅公開了其推理系統的核心優化方案,更是首次披露了成本利潤率等關鍵數據,引發行業震動。
數據顯示,若按理論定價計算,其單日成本利潤率高達545%,這一數字刷新了全球AI大模型領域的盈利天花板。
業內分析指出,DeepSeek的開源策略與成本控制能力正在打破AI領域的資源壟斷。DeepSeek此次「透明化」披露,不僅展示了其技術實力與商業潛力,更向行業傳遞明確信號:AI大模型的盈利閉環已從理想照進現實。
DeepSeek最新發布
3月1日,DeepSeek於知乎開設官方賬號,發布《DeepSeek-V3/R1推理系統概覽》技術文章,首次公布模型推理系統優化細節,並披露成本利潤率關鍵信息。
文章寫道:「DeepSeek-V3/ R1推理系統的優化目標是:更大的吞吐,更低的延遲。」
為實現這兩個目標,DeepSeek的方案是使用大規模跨節點專家並行(EP),但該方案也增加了系統複雜性。文章的主要內容就是關於如何使用EP增長批量大小(batch size)、隱藏傳輸耗時以及進行負載均衡。
值得注意的是,文章還率先披露了DeepSeek的理論成本和利潤率等關鍵信息。
根據DeepSeek官方披露,DeepSeek V3和R1的所有服務均使用H800 GPU,使用和訓練一致的精度,即矩陣計算和dispatch 傳輸採用和訓練一致的FP8格式,core-attention計算和combine傳輸採用和訓練一致的BF16,最大程度保證了服務效果。
另外,由於白天的服務負荷高,晚上的服務負荷低,因此DeepSeek實現了一套機制,在白天負荷高的時候,用所有節點部署推理服務。晚上負荷低的時候,減少推理節點,以用來做研究和訓練。
在最近24小時(2025年2月27日12:00至28日12:00)的統計周期內:GPU租賃成本按2美元/小時計算,日均成本為87072美元;若所有輸入/輸出token按R1定價(輸入1元/百萬token、輸出16元/百萬token)計算,單日收入可達562027美元,成本利潤率高達545%。

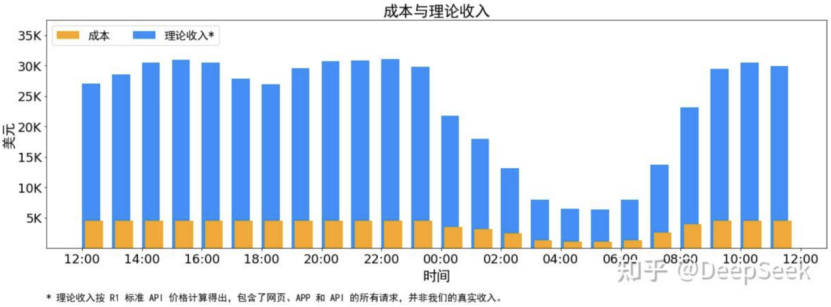
不過,DeepSeek官方坦言,實際上沒有這麼多收入,因為V3的定價更低,同時收費服務只佔了一部分,另外夜間還會有折扣。
DeepSeek的高利潤率源於其創新的推理系統設計,核心包括大規模跨節點專家並行(EP)、計算通信重疊與負載均衡優化三大技術支柱:專家並行(EP)提升吞吐與響應速度,針對模型稀疏性(每層僅激活8/256個專家),採用EP策略擴展總體批處理規模(batch size),確保每個專家獲得足夠的計算負載,顯著提升GPU利用率;部署單元動態調整(如Prefill階段4節點、Decode階段18節點),平衡資源分配與任務需求。
計算與通信重疊隱藏延遲,Prefill階段通過「雙batch交錯」實現計算與通信並行,Decode階段拆分attention為多級流水線,最大限度掩蓋通信開銷。
全局負載均衡避免資源浪費,針對不同並行模式(數據並行DP、專家並行EP)設計動態負載均衡器,確保各GPU的計算量、通信量及KVCache佔用均衡,避免節點空轉。
簡單來說,EP就像是「多人協作」,把模型中的「專家」分散到多張GPU上進行計算,大幅提升Batch Size,榨乾GPU算力,同時專家分散,降低內存壓力,更快響應。
DeepSeek在工程層面進一步壓縮成本。晝夜資源調配:白天高峯時段全力支持推理服務,夜間閒置節點轉用於研發訓練,最大化硬件利用率;緩存命中率達56.3%:通過KVCache硬盤緩存減少重複計算,在輸入token中,有3420億個(56.3%)直接命中緩存,大幅降低算力消耗。
影響多大?
有分析稱,DeepSeek此次披露的數據,不僅驗證了其技術路線的商業可行性,更為行業樹立了高效盈利的標杆:其模型訓練成本僅為同類產品的1%—5%,此前發布的DeepSeek-V3模型訓練成本僅557.6萬美元,遠低於OpenAI等巨頭;推理定價優勢方面,DeepSeek-R1的API定價僅為OpenAI o3-mini的1/7至1/2,低成本策略加速市場滲透。
業內分析指出,DeepSeek的開源策略與成本控制能力正在打破AI領域的資源壟斷。DeepSeek此次「透明化」披露,不僅展示了其技術實力與商業潛力,更向行業傳遞明確信號:AI大模型的盈利閉環已從理想照進現實,標誌着AI技術從實驗室邁向產業化的關鍵轉折。
中信證券認為,Deepseek在模型訓練成本降低方面的最佳實踐,料將刺激科技巨頭採用更為經濟的方式加速前沿模型的探索和研究,同時將使得大量AI應用得以解鎖和落地。算法訓練帶來的規模報酬遞增效應以及單位算力成本降低對應的傑文斯悖論等,均意味着中短期維度科技巨頭繼續在AI算力領域進行持續、規模投入仍將是高確定性事件。
本周以來,DeepSeek開啓「開源周」,給人工智能領域扔下數顆「重磅炸彈」。回顧DeepSeek這五天開源的內容,信息量很大,具體來看:
周一,DeepSeek宣佈開源FlashMLA。FlashMLA是DeepSeek用於Hopper GPU的高效MLA解碼內核,並針對可變長度序列進行了優化,現已投入生產;
周二,DeepSeek宣佈開源DeepEP,即首個用於MoE模型訓練和推理的開源EP通信庫,提供高吞吐量和低延遲的all-to-all GPU內核;
周三,DeepSeek宣佈開源DeepGEMM。其同時支持密集佈局和兩種MoE佈局,完全即時編譯,可為V3/R1模型的訓練和推理提供強大支持等;
周四,DeepSeek宣佈開源Optimized Parallelism Strategies。其主要針對大規模模型訓練中的效率問題;
周五,DeepSeek宣佈開源Fire-Flyer文件系統(3FS),以及基於3FS的數據處理框架Smallpond。
因此,有網友評論稱:「《DeepSeek-V3/R1推理系統概覽》技術文章是‘開源周彩蛋’,直接亮出了底牌!」
至此,DeepSeek「開源周」的連載或許要告一段落了,但DeepSeek後續動作依然值得持續關注。
(文章來源:數據寶)