
編者按:芯事重重「算力經濟學」系列研究,聚焦算力、成本相關話題的技術分析、產業穿透,本期聚焦ASIC芯片自研與產業鏈研究。本文系基於公開資料撰寫,僅作為信息交流之用,不構成任何投資建議。
作者:由我、蘇揚
編輯:鄭可君
DeepSeek帶動推理需求爆發,英偉達的「算力霸權」被撕開一道口子,一個新世界的大門逐漸打開——由ASIC芯片主導的算力革命,正從靜默走向喧囂。
日前,芯流智庫援引知情人士的消息,稱DeepSeek正在籌備AI芯片自研。相比這個後起之秀,國內大廠如阿里、百度、字節們更早就跨過了「自研」的大門。
大洋彼岸,OpenAI自研芯片的新進展也在年初釋出,外媒披露博通為其定製的首款芯片幾個月內將在台積電流片。
此前更是一度傳出Sam Altman計劃籌集70000億美元打造「芯片帝國」,設計與製造通喫。此外,谷歌、亞馬遜、微軟、Meta也都先後加入了這場「自研熱潮」。
一個明顯的信號是——無論DeepSeek、OpenAI,還是中國公司和硅谷大廠,誰都不希望在算力時代掉隊。而ASIC芯片,可能會成為他們跨越新世界大門的入場券。
這會不會「殺死」英偉達?或者,會不會「再造」第二個英偉達?現在還沒有答案。
不過可以明確的是,這場轟轟烈烈的「自研浪潮」,其上游的產業鏈企業已經「春江水暖鴨先知」,例如給各家大廠提供設計定製服務的博通,業績已經「起飛」:2024年AI業務收入按年240%,達到37億美元;2025Q1AI業務營收41億美元,按年增77%;其中80%來自ASIC芯片設計。
在博通的眼裏,ASIC芯片這塊蛋糕,價值超過900億美元。
01
從GPU到ASIC,算力經濟學走向分水嶺
低成本是AI推理爆發的必要條件,與之相對的是——通用GPU芯片成了AI爆發的黃金枷鎖。
英偉達的H100和A100是大模型訓練的絕對王者,甚至連B200、H200也讓科技巨頭們趨之若鶩。金融時報此前援引Omdia的數據,2024年,英偉達Hopper架構芯片的主要客戶包括微軟、Meta、Tesla/xAI等,其中微軟的訂單量達到50萬張。
但是,作為通用GPU的絕對統治者,英偉達產品方案其「硬幣的另一面」已逐漸顯現:高昂的成本與冗餘的能耗。
成本方面,單個H100售價超3萬美元,訓練千億參數模型需上萬張GPU,再加上網絡硬件、存儲和安全等後續的投入,總計超5億美元。根據滙豐的數據,最新一代的GB200 NVL72方案,單機櫃超過300萬美元,NVL36也在180萬美元左右。
可以說,基於通用GPU的模型訓練太貴了,只不過是算力不受限制的硅谷,仍然偏向於「力大磚飛」的敘事,資本支出並未就此減速。就在日前,馬斯克旗下xAI,不久之前公布的Grok-3,訓練的服務器規模,已經達到了20萬張GPU的規模。
騰訊科技聯合硅兔賽跑推出的《兩萬字詳解最全2025 AI關鍵洞察》一文提到,超大規模數據中心運營商預計2024年資本支出(CapEx)超過 2000億美元,到2025年這一數字預計將接近2500億美元,且主要資源都將傾斜給人工智能。
能耗方面,根據SemiAnalysis的測算,10萬卡H100集羣,總功耗為150MW,每年耗費1.59TWh的電量,按0.078美元/千瓦時計算,每年電費高達1.239億美元。
對照OpenAI公布的數據,推理階段GPU的算力利用率僅30%-50%,「邊算邊等」現象顯著,如此低效的性能利用率,在推理時代,確實是大材小用,浪費過於嚴重。
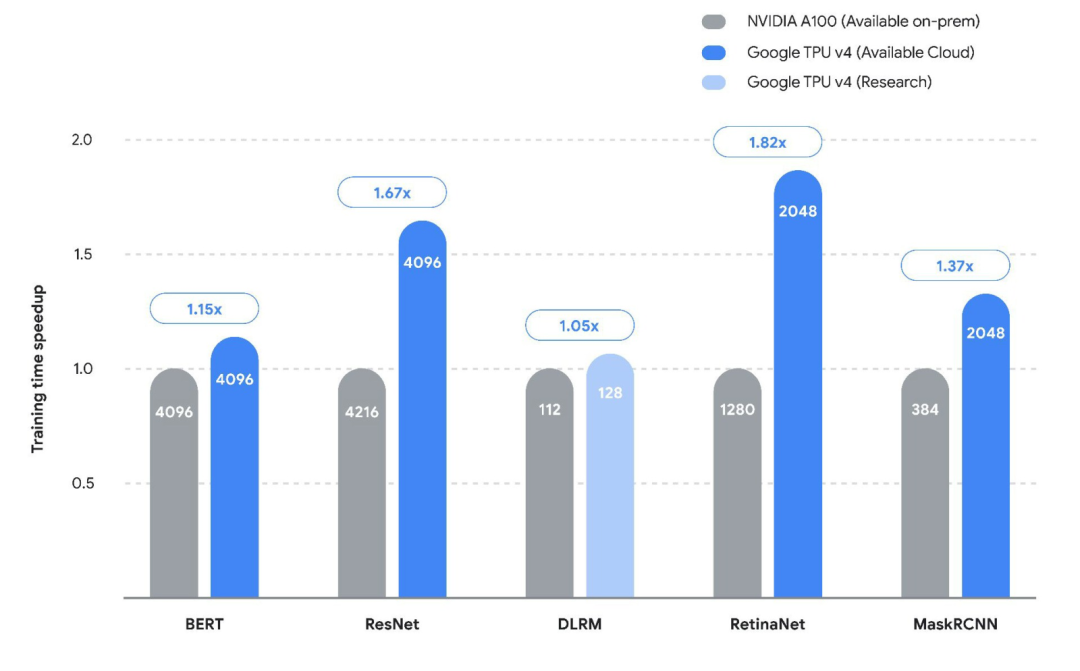
谷歌此前公布的TPU V4與A100針對不同架構模型的訓練速度
性能領先、價格昂貴,效率不佳,外加生態壁壘,過去一年業內都在喊「天下苦英偉達久矣」——雲廠商逐漸喪失硬件自主權,疊加供應鏈風險,再加上AMD暫時還「扶不起來」,諸多因素倒逼巨頭開始自研ASIC專用芯片。
自此,AI芯片戰場,從技術競賽轉向經濟性博弈。
正如西南證券的研究結論,「當模型架構進入收斂期,算力投入的每一美元都必須產出可量化的經濟收益。」
從北美雲廠商最近反饋的進展看,ASIC已體現出一定的替代優勢:
● 谷歌:博通為谷歌定製的TPU v5芯片在Llama-3推理場景中,單位算力成本較H100降低70%。
● 亞馬遜:3nm製程的AWS Trainium 3,同等算力下能耗僅為通用GPU的1/3,年節省電費超千萬美元;據了解,亞馬遜Trainium芯片2024年出貨量已超50萬片。
● 微軟:根據IDC數據,微軟Azure自研ASIC後,硬件採購成本佔比從75%降至58%,擺脫長期被動的議價困境。
作為北美ASIC鏈的最大受益者,博通這一趨勢在數據中愈發顯著。
博通2024年AI業務收入37億美元,按年增240%,其中80%來自ASIC設計服務。2025Q1,其AI業務營收41億美元,按年增77%,同時預計第二季度AI營收44億美元,按年增44%。
早在年報期間,博通指引2027年ASIC收入將大爆發,給市場畫了3年之後ASIC芯片將有望達到900億美元的市場規模這個大餅。Q1電話會期間,公司再次重申了這一點。
憑藉這個大的產業趨勢,博通也成為全球繼英偉達、台積電之後,第三家市值破1萬億美元的半導體公司,同時也帶動了海外對於Marvell、AIchip等公司的關注。
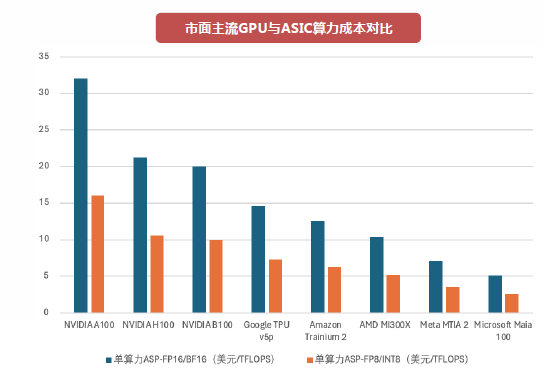
圖:市面主流GPU與ASIC算力成本對比 資料來源:西南證券
不過,有一點需要強調——「ASIC雖好,但也不會殺死GPU」。
微軟、谷歌、Meta都在下場自研,但同時又都在搶英偉達B200的首發,這其實說明了雙方之間不是直接的競爭關係。
更客觀的結論應該是,GPU仍將主導高性能的訓練市場,推理場景中由於GPU的通用性仍將是最主要的芯片,但在未來接近4000億美元的AI芯片藍海市場中,ASIC的滲透路徑已清晰可見。
IDC預測,2024-2026年推理場景中,ASIC佔比從15%提升至40%,即最高1600億美元。
這場變革的終局或許是:ASIC接管80%的推理市場,GPU退守訓練和圖形領域。真正的贏家將是那些既懂硅片、又懂場景的「雙棲玩家」,英偉達顯然是其中一員,看好ASIC斷然不是唱空英偉達。
而新世界的指南,是去尋找除英偉達之外的雙棲玩家,如何掘金ASIC新紀元。
02
ASIC的「手術刀」:非核心模塊,通通砍掉
錦緞在《DeepSeek的隱喻:GPU失其鹿,ASIC、SoC們共逐之》一文中詳解過SoC,而CPU、GPU用戶早已耳熟能詳,FPGA應用市場小衆,最為陌生的當屬ASIC。
特性 |
CPU |
GPU |
FPGA |
ASIC |
定製化程度 |
通用 |
半通用 |
半定製化 |
全定製化 |
靈活性 |
高 |
高 |
高 |
低 |
成本 |
較低 |
高 |
較高 |
低 |
功耗 |
較高 |
高 |
較高 |
低 |
主要優點 |
通用性最強 |
計算能力強,生態成熟 |
靈活強較高 |
能效最高 |
主要缺點 |
並行算力弱 |
功耗較大,編程難度較大 |
峯值計算能力弱,編程難度較難 |
研發時間長,技術風險高 |
應用場景 |
較少用於AI |
雲端訓練和推理 |
雲端推理,終端推理 |
雲端訓練和推理,終端推理 |
圖:算力芯片對比 資料來源:中泰證券
那麼,都說ASIC利好AI推理,究竟它是一個什麼樣的芯片?
從架構上來說, GPU這樣的通用芯片,其侷限在於「以一敵百」的設計——需要兼顧圖形渲染、科學計算、不同的模型架構等多元需求,導致大量晶體管資源浪費在非核心功能模塊。
英偉達GPU最大的特點,就是有衆多「小核」,這些「小核」可以類比成獵鷹火箭多台發動機,開發者可以憑藉CUDA多年積累的算子庫,平穩、高效且靈活地調用這些小核用於並行計算。
但如果下游模型相對確定,計算任務就是相對確定的,不需要那麼多小核來保持靈活性,ASIC最底層的原理正是如此,所以也被稱為全定製化高算力芯片。
通過 「手術刀式」精準裁剪,僅保留與目標場景強相關的硬件單元,釋放出驚人的效率,這在谷歌、亞馬遜都已經在產品上得到了驗證。

谷歌TPU v5e AI加速器實拍
對於GPU來說,調用它們最好的工具是英偉達的CUDA,而對於ASIC芯片,調用它們的是雲廠商自研的算法,這對於軟件起家的大廠來說,並不是什麼難事:
● 谷歌TPU v4中,95%的晶體管資源用於矩陣乘法單元和向量處理單元,專為神經網絡計算優化,而GPU中類似單元的佔比不足60%。
● 不同於傳統馮·諾依曼架構的「計算-存儲」分離模式,ASIC可圍繞算法特徵定製數據流。例如在博通為Meta定製的推薦系統芯片中,計算單元直接嵌入存儲控制器周圍,數據移動距離縮短70%,延遲降低至GPU的1/8。
● 針對AI模型中50%-90%的權重稀疏特性,亞馬遜Trainium2芯片嵌入稀疏計算引擎,可跳過零值計算環節,理論性能提升300%。
當算法趨於固定,對於確定性的垂直場景,ASIC就是具有天然的優勢,ASIC設計的終極目標是讓芯片本身成為算法的「物理化身」。
在過去的歷史和正在發生的現實中,我們都能夠找到ASIC成功的力證,比如礦機芯片。
早期,行業都是用英偉達的GPU挖礦,後期隨着挖礦難度提升,電力消耗超過挖礦收益(非常類似現在的推理需求),挖礦專用ASIC芯片爆發。雖然通用性遠不如GPU,但礦機ASIC將並行度極致化。
例如,比特大陸的比特幣礦機ASIC,同時部署數萬個SHA-256哈希計算單元,實現單一算法下的超線性加速,算力密度達到GPU的1000倍以上。不僅專用能力大幅提升,而且能耗實現了系統級節省。
此外,使用ASIC可精簡外圍電路(如不再需要PCIe接口的複雜協議棧),主板面積減少40%,整機成本下降25%。
低成本、高效率,支持硬件與場景深度咬合,這些ASIC技術內核,天然適配AI產業從「暴力堆算力」到「精細化效率革命」的轉型需求。
隨着推理時代的到來,ASIC成本優勢將重演礦機的歷史,實現規模效應下的「死亡交叉」——儘管初期研發成本高昂(單芯片設計費用約5000萬美元),但其邊際成本下降曲線遠陡於通用GPU。
以谷歌TPU v4為例,當出貨量從10萬片增至100萬片時,單顆成本從3800美元驟降至1200美元,降幅接近70%,而GPU的成本降幅通常不超過30%。根據產業鏈最新信息,谷歌TPU v6預計2025年出貨160萬片,單片算力較前代提升3倍,ASIC的性價比,還在快速提升。
這又引申出一個新的話題,是否所有人都可以湧入自研ASIC大潮中去?這取決於自研成本與需求量。
按照7nm工藝的ASIC推理加速卡來計算,涉及IP授權費用、人力成本、設計工具、掩模板在內的一次流片費用等,量級可能就在億元的級別,還不包括後期的量產成本。在這方面,大廠更具有資金優勢。
目前,像谷歌、亞馬遜這樣的雲廠商,因為有成熟的客戶體系,能夠形成研發、銷售閉環,自研上擁有先天的優勢。
Meta這種企業,自研的邏輯則在於內部本身就有天量級的算力需求。今年初,扎克伯格就曾透露,計劃在2025年上線約1GW的計算能力,並在年底前擁有超過130萬張GPU。
03
「新地圖」價值遠不止1000億美元
僅僅是挖礦需求就帶來了近100億美元的市場,所以當博通2024年底喊出AI ASIC市場空間700-900億美元的時候,我們並不意外,甚至認為可能這個數字都保守了。
現在,ASIC芯片的產業趨勢不應當再被質疑,重點應該是如何掌握「新地圖」的博弈法則。
近千億美元的AI ASIC市場中,已經形成清晰的三大梯隊——「制定規則的ASIC芯片設計者和製造者」 、「產業鏈配套」、「垂直場景下的Fabless」。
第一梯隊,是制定規則的ASIC芯片設計者和製造者,他們可以製造單價超過1萬美元的ASIC芯片,並與下游的雲廠商合作商用,代表玩家有博通、Marvell、AIchip,以及不管是什麼先進芯片都會受益的代工王者——台積電。
第二梯隊,產業鏈配套,已經被市場關注到的配套邏輯包括先進封裝與更下游的產業鏈。
● 先進封裝:台積電CoWoS產能的35%已轉向ASIC客戶,國產對應的中芯國際、長電科技、通富微電等。
● 雲廠商英偉達硬件方案解耦帶來的新硬件機會:如AEC銅纜,亞馬遜自研單顆ASIC需配3根AEC,若2027年ASIC出貨700萬顆,對應市場超50億美元,其他還包括服務器、PCB均是受益於相似邏輯。
第三梯隊,是正在醞釀的垂直場景的Fabless。ASIC的本質是需求驅動型市場,誰能最先捕捉到場景痛點,誰就掌握定價權。ASIC的基因就是定製化,與垂直場景天然適配。以智駕芯片為例,作為典型的ASIC芯片,隨着比亞迪等All in智駕,這類產品開始進入爆發期。
映射全球ASIC產業鏈三大梯隊對應的機會,可以看作是國產的「三把祕鑰」。
受制於禁令的限制,國產GPU與英偉達的差距仍然巨大,生態建設也是一個漫長的路程,但是對於ASIC,我們甚至與海外在同一起跑線上,再結合垂直場景,中國不少Fabless能夠做出更有能效比的產品,前面提及的礦機ASIC、智駕ASIC以及阿里平頭哥的含光、百度的崑崙芯這些AI ASIC。
與之配套的芯片製造,主要依賴中芯國際,中興旗下的中興微等則是新入場的「玩家」,不排除未來他們將與國內廠商合作,上演一場「誰將是中國博通」的戲碼。

左圖為英偉達主要上游供應商,來源Fubon Research ,右圖GB200 NV72L機櫃的總長接近2英里的NVlink Spine銅纜
產業鏈配套部分難度相對較低,對應的服務器、光模塊、交換機、PCB、銅纜,由於技術難度低,國內企業本來競爭力就比較強。與此同時,這些產業鏈企業與國產算力屬於「共生」關係,ASIC芯片產業鏈也不會缺席。
應用場景上,除了反覆提及的智駕芯片和AI推理加速卡,其他國產設計公司的機會,取決於什麼場景能爆發,對應哪些公司又能把握住機遇。
04
結語
當AI從大力出奇跡的訓練軍備競賽,躍進推理追求能效的深水區,算力戰爭的下半場註定屬於那些能將技術狂想,轉化為經濟賬本的公司。
ASIC芯片的逆襲,不僅是一場技術革命,更是一本關於效率、成本和話語權的商業啓示錄。
在這場新的牌局中,中國選手的籌碼正在悄然增加——機會永遠留給準備好的人。