新浪科技訊 3月10日上午消息,由原華為天才少年稚暉君(彭志輝)創立的智元機器人今日發布,首個通用具身基座大模型GO-1。
據悉,該模型開創性地提出了Vision-Language-Latent-Action (ViLLA) 架構,該架構由VLM(多模態大模型) + MoE(混合專家)組成,其中VLM藉助海量互聯網圖文數據獲得通用場景感知和語言理解能力,MoE中的Latent Planner(隱式規劃器)藉助大量跨本體和人類操作視頻數據獲得通用的動作理解能力,MoE中的Action Expert(動作專家)藉助百萬真機數據獲得精細的動作執行能力,三者環環相扣,實現了可以利用人類視頻學習,完成小樣本快速泛化,降低了具身智能門檻,併成功部署到智元多款機器人本體。(文猛)
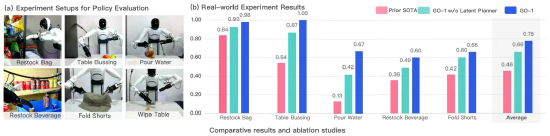
據悉,相比已有的最優模型,GO-1平均成功率提高了32%(46%->78%)。其中,在執行「Pour Water」(倒水)、「Table Bussing」(清理桌面) 和 「Restock Beverage」(補充飲料) 任務表現尤為突出。
海量資訊、精準解讀,盡在新浪財經APP
責任編輯:尉旖涵