◇ 作者:誠通證券證券投資部 陳彥如
中國人民大學統計學院 程敬雨
◇ 本文原載《債券》2025年2月刊
摘 要
隨着債券市場擴容,地方債已躍升為市場中的第一大品種,日益引發關注,本文探討了金融科技在地方債利差分析中的應用。一級市場方面,通過K-Means聚類算法對地方債投標加點數據進行分類,揭示了不同地區和不同期限地方債的聚類特徵,促進信用風險識別和地方債收益率曲線構建。二級市場方面,運用GARCH模型對10年期地方債利差進行時序分析,精準捕捉地方債利差的波動性,為投資者和政策制定者提供了深入的市場分析視角和數據支持。
關鍵詞
地方債 信用利差 K-Means 聚類算法GARCH模型
引言
經過多年的發展,地方政府債券(以下簡稱「地方債」)現已成為中國債券市場現存規模最大的債券品種。對發行主體而言,地方債在推動穩增長、促投資、保民生、擴內需等方面發揮着重要作用;對投資者而言,其因明確的資金投向、穩定的收益預期以及稅收優惠政策等多重優勢,逐漸獲得投資者青睞,成為了固定收益領域的核心資產標的。
同時,管理制度的建設不斷強化,持續提高地方債市場公開化、規範化水平。自2009年啓動發行以來,地方債發債模式先後經歷了「代發代還」和試點省市「自發代還」階段,地方債的還本付息由財政部負責,背後隱含國家信用擔保。2014年5月,《2014年地方政府債券自發自還試點辦法》發布,開創了地方政府自主發債新紀元。2015年《中華人民共和國預算法》中,我國賦予了地方政府適度舉債孖展的權限,正式建立起了「借、用、管、還」相統一的地方債管理機制,地方債利差的波動由此展開。
地方債利差,指地方債的一級發行利率或二級交易利率與同期限國債(無風險資產)利率之間的差異,反映了投資者購買地方債時希望獲得的信用風險溢價和流動性補償。地方債利差受多種因素影響,包括地方政府的財政狀況、債務水平、經濟增長預期、市場流動性狀況以及宏觀經濟環境等。簡言之,地方債利差是投資者對地方政府信用風險的量化表達,相關研究可以幫助投資者更好地評估和管理投資組合風險,促進資本的有效配置;政策制定者可以利用這些信息來調整財政政策,促進區域經濟的均衡發展,對於維護金融穩定和推動實體經濟持續健康發展具有重要意義。
傳統的信用利差量化研究方法通常基於發行主體差異,構建宏觀因子模型來刻畫信用溢價。然而,地方債利差具有區域性差異小和波動性不強的特點,使得宏觀因子模型在捕捉地方債利差動態時的解釋力不足,實際應用受限。本文藉助金融科技工具,以2020—2023年的地方債利差數據為研究樣本,首先探討了K-Means聚類算法在地方債投標加點分析中的應用,通過無監督學習方法揭示不同地區和期限地方債的聚類特徵,運用GARCH模型對地方債利差進行時序分析,評估和預測市場動態,並在文末討論了金融科技在地方債市場分析中的賦能作用。
研究方法與模型
(一)K-Means聚類在地方債投標加點分析的應用
一級發行時,以投標加點衡量地方債利差,其計算方式為:地方債的票面利率減去相應期限國債在發行前5個工作日的估值平均值,最終結果以點子(BP)為單位表示。本文通過對地方債投標加點數據進行分類,從而幫助投資者和政策制定者更好地理解市場結構、評估信用風險、優化投資決策,並為地方債的定價和發行提供數據支持。
1. 樣本選擇
本文以2020—2023年發行的8156只地方債發行數據構建結構化的數據庫,數據來源為萬得(Wind)。按發行年份分成四組,每組中按照地區和期限進行整理,例如,「2020年」組中,「北京市、1年期」為一個樣本數據。上述債券共組合成819個樣本數據,其中2020年189個,2021年204個,2022年216個,2023年210個。每個數據樣本由以下四個特徵構成,即每個樣本為1個四維向量,以描繪地方債加點數據的特徵輪廓。
第一,加點均值映射了地方債相較於基準利率的風險溢價,是投資者對地方債信用風險和市場風險的綜合評估。
第二,加點標準差揭示了債券市場對風險評估的波動程度,其數值的高低直接反映了市場對特定債券風險看法的一致性。
第三,加點與發行規模的相關性係數考量了發行量對債券定價的潛在影響。
第四,加點與票面利率的相關性係數展現了利率絕對水平對相對利差的影響。
以上特徵共同映射出地方債的市場定價、風險程度和供需狀況。
2. 算法選擇:K-Means聚類
本文選擇K-Means算法來實現地方債投標加點的數據分類。K-Means是一種無監督學習領域的聚類方法,基於點與點之間距離的相似度來計算最佳類別歸屬,常用於資產分類。算法的核心是將數據樣本劃分為k個類別(又稱「簇」),通過迭代過程將數據點分配到最近的簇中心(質心),以此來最小化簇內樣本點與簇中心之間的距離總和,即最小化簇內的方差。
本文在每個發行年份中,獨立執行K-Means聚類分析,共執行四次,以下是對單個年份數據進行聚類的詳細步驟。第一步,算法從n個樣本數據中隨機選取k個質心作為初始的聚類中心,質心記為μ1(0),μ2(0),…,μK(0)。第二步,計算每個樣本點xi到質心μj的距離,距離度量方法使用歐幾里得距離(公式1),將每個樣本點分配到最近的質心,得到k個簇。第三步,重新計算每個簇的質心。重複第二步和第三步計算,直到數據點的簇分配結果不再改變,得到最終的簇劃分。本文中,k=4;按發行年份,n依次等於189、204、216、210。
公式1:歐幾里得距離公式
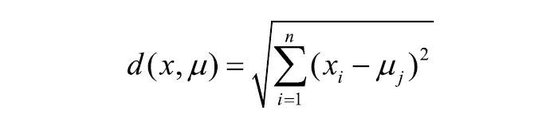
3. 聚類結果分析
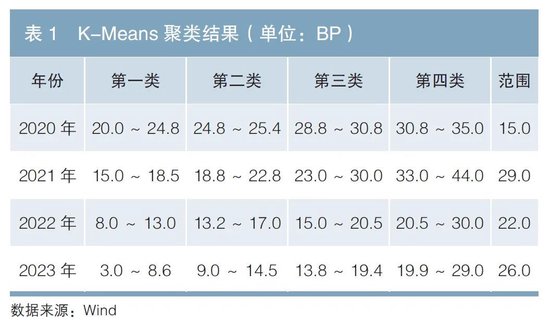
表1展示了四年聚類分析的結果,可以清晰地觀測到發行機制和市場行為隨時間推移的變化。利差等級從第一類過渡到第四類,意味着信用風險溢價的逐步增加以及信用排名的逐級下降。2020年,樣本利差範圍僅為15BP,可見非市場化發行在當時佔據主導地位,信用補償尚未拉開差距。2021年1月1日起,《地方政府債券發行管理辦法》生效,鼓勵具備條件的地區在債務發行中合理設月供標區間,以推動地方債市場化運作,這一階段的第一類利差顯著下降,第二、三類小幅下行,而第四類利差則呈現明顯上升,導致整體利差範圍擴大至29BP。在2022年,各類地方債利差普遍呈現下降趨勢,其中第四類利差下行幅度最為顯著,超過10BP,利差範圍收斂至22BP。2023年,第一類利差繼續顯著壓縮,引領了整體的下行趨勢,第三、四類利差降幅較小,最終整體利差範圍再次擴大至26BP。
本文選擇按年份對數據進行四次聚類,而非對整體數據進行一次性分類,核心目的在於維持地方債利差的時序特徵。通過這種方式,在每一年度內對不同地區和期限的債券進行相對排名,實際上是對當年各類債券表現的相對評估。這樣的分類策略使本文能夠捕捉並分析地方債利差隨時間的動態變化,從而更準確地反映市場在不同時間點對地方債務風險的評估和反應。
4. 地區視角解讀
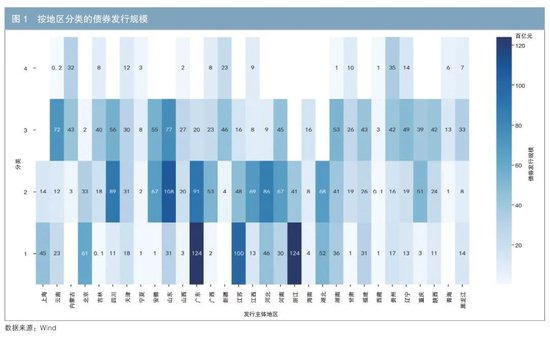
首先,通過地區視角對聚類結果進行分析,在此過程中,將計劃單列市的數據併入其所屬的省份之中。本文對同一地區內屬於相同利差類別的債券發行規模進行了累加求和,以便更直觀地展現各地區在不同利差類別中的債券發行總量(見圖1)。顏色的深淺程度用來表示各地區債券發行數量,顏色越深意味着更為密集。通過運用基本的統計方法如中位數,可以有效地提取出各地區利差類別的特徵。例如,第一類利差包含北京、上海、廣東、江蘇和浙江,共同展現了經濟發達地區的典型特徵。
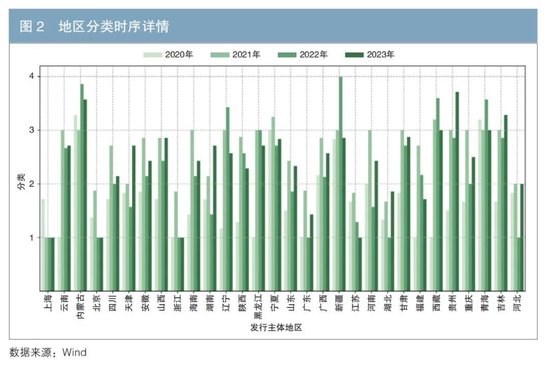
值得關注的是,上述經濟發達地區仍有相當數量的債券被歸入第二類利差。為了從時間維度探究這一現象的原因,本文按照年度對同一地區的利差類別進行了加權平均處理,以債券發行規模為權重,進而繪製出圖2。上述6個發達地區除上海以外,均在2021年集中在第二類,隨後於2022年、2023年恢復至第一類。2021年第一類利差顯著集中在上海地區的債券上。這表明在當年的市場化改革中,上海走在了前列,與其他地區拉開了差距,因而獲得了單獨的利差分類。從圖中可以觀察到各地區的利差類別隨時間呈現出的變化趨勢,這反映了當地信用風險的動態演變以及市場對這些地區信用狀況認可度的相應調整,受篇幅所限不一一分析。
此外,數據底稿顯示,2021年的第一類利差還包括其他地區發行的30年期地方債,這意味着當年30年期地方債率先受到追捧。下面,本文將探討不同地方債利差類別在債券期限這一關鍵維度上的分佈特徵。
5. 期限視角解讀
本文采用箱線圖這一直觀的統計工具,以展示具有相同發行期限的債券分類結果分佈情況(見圖3)。綠色三角形精準地標示了數據的均值所在,藍色的箱體則清晰地界定了上下四分位數的區間範圍,黑色線條延伸至數據的上邊緣和下邊緣,共同展示出數據分佈的中心位置和散佈範圍。
如圖3所示,1年期、2年期和30年期的地方債在利差分類上處於最低水平,這表明它們受到了市場青睞,相較於同期限的國債所需支付的溢價最小。相對而言,10年至20年期的地方債在分類分佈上位於較高水平,這反映了市場對這類期限債券的需求相對較弱,投資者偏好程度不高。圖中位於右上角的菱形圖標代表數據中的離羣點,這揭示了儘管30年期地方債整體上呈現出較低的利差水平,但仍有部分發行數據歸入了第四類利差範疇,即這些債券發行時支付了較高的溢價。
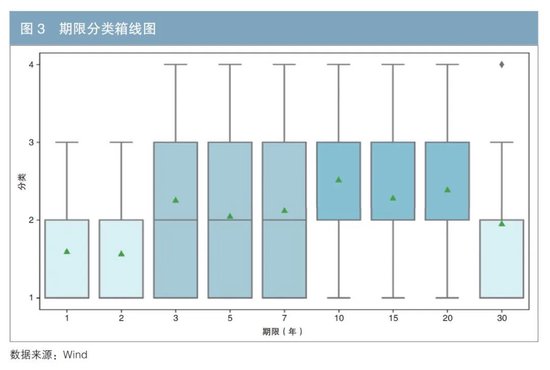
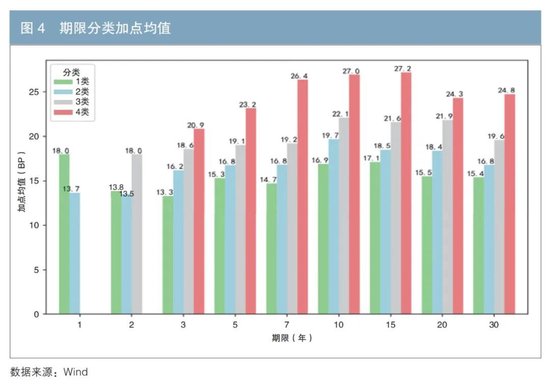
圖4呈現了不同發行期限下,各個利差分類的加點均值情況。其中,1年期地方債券僅涉及第一類和第二類利差,2年期地方債則不包含第四類利差,表明發行這兩個期限的債券在信用排名上普遍較好,與前文的分析結果相吻合。在這兩個期限的債券中,出現了第一類利差的加點均值高於第二類利差的倒掛現象。這一不尋常的結果主要是受2020年非市場化發行的影響,市場定價機制出現一定扭曲,從而影響了利差的分佈格局。
在對3年期、5年期、7年期、10年期債券的分析中,可以觀察到各類別利差的加點均值呈現出隨着債券期限的延長而逐步抬升的趨勢。然而,15年期債券的各類利差加點均值小於10年期。產生這一現象的主要原因在於,10年期地方債的利差基準是10年期國債,即市場上的活躍券種。由於其高度的流動性,該基準債券擁有更低的流動性溢價,從而增加了與它相比較的10年期地方債的利差加點情況。
通過聚類分析,本文提供了一種系統化的方法來解析複雜多維的地方債數據,該方法能夠將具有相似特徵的地方債進行有效分類,揭示出債券間的相互關係和市場行為的深層動因。這不僅可以加深投資者對不同區域債券信用風險的理解,還有助於預測市場趨勢和潛在風險,為投資決策提供了堅實的數據支持。通過深入分析債券期限結構,能夠更有效地理解地方債收益率曲線的形成機制,從而為構建和完善地方債市場的收益率曲線提供堅實的理論基礎和實踐指導。
(二)GARCH模型在地方債利差時序分析中的應用
在二級市場交易中,地方債利差被定義為特定期限的地方債估值收益率與相應期限的國債估值收益率之間的差值,以BP為計量單位。本文對地方債利差數據進行時間序列分析,旨在揭示地方債利差的動態變化模式,並預測未來的市場趨勢。
1. 樣本選擇
本文聚焦10年期品種,選取2020—2023年的日頻地方債利差數據,依次取其對數,構建包含970個觀測點的訓練集,用以訓練模型。為了評估模型的預測準確性,本文選取2024年1月的22個連續日頻數據構成測試集,以驗證模型的預測性能。
2. 模型選擇:GARCH模型
本文采用GARCH(廣義自迴歸條件異方差)模型來刻畫地方債利差的時序表現。金融序列通常具有自相關性和條件異方差性,即金融時間序列的波動性(方差)不是恒定的,而是隨時間變化的。GARCH模型是時間序列分析中用於建模金融數據波動性的一種統計模型。GARCH模型的核心思想是,一個時間序列的波動性是其過去信息的函數,包括過去的波動性和過去的誤差項。這種模型特別適用於金融時間序列數據,如利率、匯率、股票價格等,因為這些數據通常表現出波動聚集現象,即大的價格變動往往會被跟隨一段時間的高波動性,而小的價格變動則伴隨着低波動性。
相較於一般的時間序列預測模型如ARIMA(自迴歸整合移動平均),GARCH模型的優點在於它能夠自動適應時間序列的波動性變化,不需要對波動性進行額外的建模,通過對過去波動的平方進行加權來衡量未來波動的變化趨勢。
3. 模型構建
(1)模型基礎構建
GARCH模型由以下3個部分組成,分別為均值模型、異方差的分佈假定、條件異方差模型。其中,rt是時間序列的觀測值,μ是均值,ϵt是條件誤差項,σt是條件方差,zt是獨立同分布的隨機誤差項,通常假設為標準正態分佈。
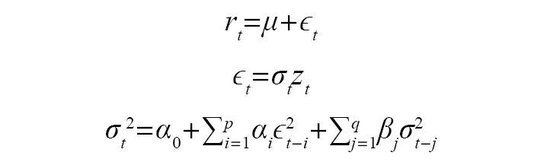
在GARCH模型中,每個時間點變量的波動率是最近p個時間點殘差平方的線性組合,再與最近q個時間點變量波動的線性組合疊加起來得到。其中,α0>0是常數項,αi、βj≥0分別衡量了過去的誤差項平方和過去的條件方差對當前條件方差的影響,∑pi=1αi+∑qj=1βj<1且假定αi、βj滿足一定條件使得ϵt的條件方差隨時間變化是有限的。
(2)殘差序列條件異方差效應檢驗
在應用GARCH模型對金融時間序列數據分析前,進行Portmanteau-Q檢驗和Lagrange-Multiplier(LM)檢驗是至關重要的步驟。Portmanteau-Q檢驗用於檢測時間序列中的自相關性,其原假設是序列中的滯後項自相關係數為零,即序列是純隨機的。如果檢驗得出的p-value低於顯著性水平(通常為0.05),則表明時間序列中存在自相關性,這意味着序列中的觀測值之間存在相關性,而非完全隨機獨立。
LM檢驗用於檢測時間序列模型殘差中的ARCH效應,即自迴歸條件異方差性。ARCH效應的存在意味着序列的條件方差不是恒定的,而是隨着過去的信息而變化。當LM檢驗的統計量顯著高於臨界值,相應的p-value低於顯著性水平時,我們拒絕原假設,認為殘差序列存在自相關,即存在ARCH效應。
本文對訓練集進行上述檢驗,兩個檢驗的p值均小於0.05,因此得出結論,地方債利差對數序列不僅表現出自相關性,而且通過了異方差效應的檢驗。這一結果顯示了使用GARCH模型的必要性,因為該模型能夠有效地捕捉和建模時間序列的波動性聚集特徵。
(3)擬合條件異方差模型
均值模型設定為ARMA(1,1)模型(一階自迴歸和一階移動平均),不包括均值;方差模型設定為sGARCH(1,1)模型(對稱GARCH),分佈模型被設定為正態分佈。
使用訓練集數據對模型進行擬合,計算預測值相對實際值的標準分數,計算公式為預測值與實際值之差除以實際值的標準差。結果顯示,該標準分數在絕大多數情況下位於實際值的兩倍標準差的範圍內,這一現象揭示了模型具有出色的擬合能力,可以高精度捕捉數據的本質特徵和趨勢,從而提高預測結果的可靠性和準確性。
(4)模型檢驗
使用上述模型在測試集上進行預測模型的預測精度表現為:均方誤差(MSE)僅為0.000053,均方根誤差(RMSE)控制在0.01的較低水平,顯示出模型預測與實際觀測值之間的偏差較小。此外,決定係數(R²)高達0.94,意味着模型能夠解釋約94%的觀測數據方差,這表明模型對利差變化具有較高的預測準確性和解釋能力。綜合這些指標,可見該模型在預測利差走勢方面表現良好,能夠提供有價值的市場趨勢分析和決策參考。
結論與啓示
本文通過深入分析2020年至2023年期間的地方債發行數據和估值數據,巧妙運用K-Means聚類算法和GARCH模型這兩種先進的金融科技工具,不僅從地區和期限兩個維度細緻解析了地方債利差的動態演變,並且構建了一個精準的時序預測模型,為理解和預測地方債市場提供了新的視角和深刻的洞察。
第一,K-Means聚類算法在地方債投標加點分析中的應用表明,不同地區和期限的地方債存在顯著的聚類特徵。這些聚類結果不僅揭示了市場對地方債信用風險的評估,還反映了市場行為和發行機制的變化,並有利於地方債收益率曲線的構建。隨着市場化改革的深入,地方債利差的變化將更加反映市場對信用風險的真實看法。
第二,GARCH模型在地方債利差時序分析中的應用驗證了其在捕捉金融時間序列波動性方面的有效性。模型的高預測準確性和解釋能力為投資者提供了一個強有力的工具,以評估和管理地方債投資組合的風險。此外,模型結果對於政策制定者在調整財政政策和促進區域經濟發展方面提供了數據支持。
綜上所述,金融科技的應用為地方債市場分析帶來了新的視角和方法。本文通過結合無監督學習和條件異方差模型,不僅能夠更好地理解市場結構和信用風險,還實現了預測市場趨勢,從而為投資決策和政策制定提供科學依據。這些結論和啓示凸顯了金融科技在現代金融市場中的重要性,展現了其在提升市場效率、深化數據分析以及優化投資決策中的關鍵作用。未來,隨着金融科技的進一步發展,期待看到更多創新工具和方法被應用於債券市場的深度分析中,以推動金融市場的持續健康發展。
參考文獻
[1] 李晶. 基於GARCH模型的上證50ETF期權風險對沖策略研究[J]. 經濟問題,2023(3).
[2] 劉方興. 基於GARCH類模型和極值理論的理財產品風險分析[J]. 債券,2024(7). DOI: 10.3969/j.issn. 2095-3585.2024.07.018.
[3] 王建仁,馬鑫,段剛龍. 改進的K-means聚類k值選擇算法[J]. 計算機工程與應用,2019,55(8).
[4] 王森,劉琛,邢帥傑. K-means聚類算法研究綜述[J]. 華東交通大學學報,2022,39(5).
[5] 仉悅.政府幹預對地方債發行利率影響的實證研究[D].太原:山西財經大學,2023.
責任編輯:趙思遠