周二,OpenAI發布了最新的文生圖模型。該公司稱,已「把目前最先進的圖像生成器整合到GPT-4o模型裏」,這讓圖像生成「不僅畫面精美,而且頗具實用價值」。
此前版本的ChatGPT雖具備圖像生成能力,但在融合多種廣泛概念以可靠地創建圖像方面,存在不足。
OpenAI首席執行官Sam Altman將此次發布形容為「創作自由度達到了新高度」。
有哪些新升級?
OpenAI在新聞稿中介紹,GPT-4o的圖像生成功能十分強大。它能準確渲染文本,精確依照提示操作,還能利用4o自身的知識庫以及聊天上下文。
這讓用戶能更輕鬆地生成符合設想的圖像,通過視覺效果更高效地溝通。
具體體現在以下幾個方面:
文本融入更出色:GPT-4o如今能夠在生成的圖像中添加文字,並且確保文字清晰易讀、位置恰當,進一步豐富圖像內涵。

上下文理解能力增強:基於上下文信息,GPT-4o可以生成連貫一致的圖像。舉例來說,當用戶設計視頻遊戲角色時,在後續的優化與嘗試過程中,該角色的外觀能在多次生成中保持一致。


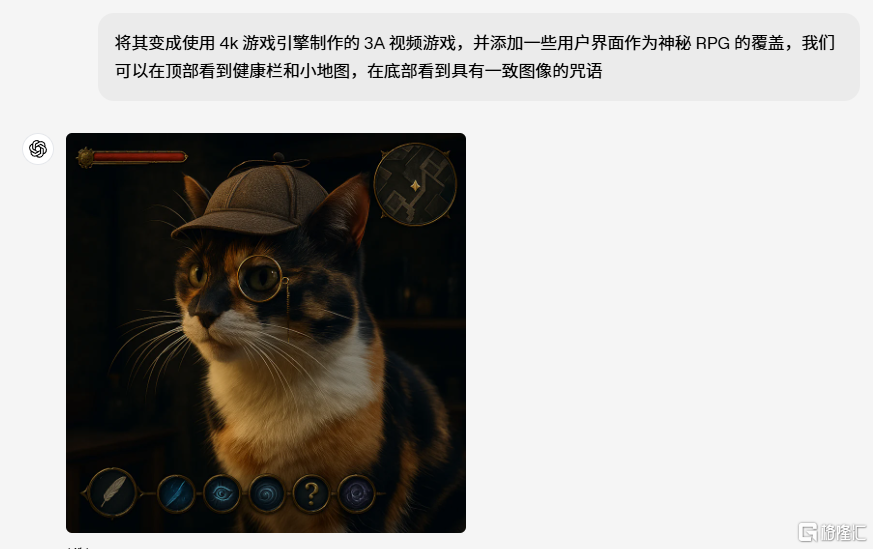
可繪製物品數量更多:GPT-4o能響應更詳細的提示,十分注重細節。其他競爭對手的AI圖像生成器在繪製大約5-8個物體時就會遇到困難,而GPT-4o可以精準繪製用戶指定的多達20種不同物品。


情境學習更智能:GPT-4o能以上傳的圖像作為參考,生成與之相似的圖像。
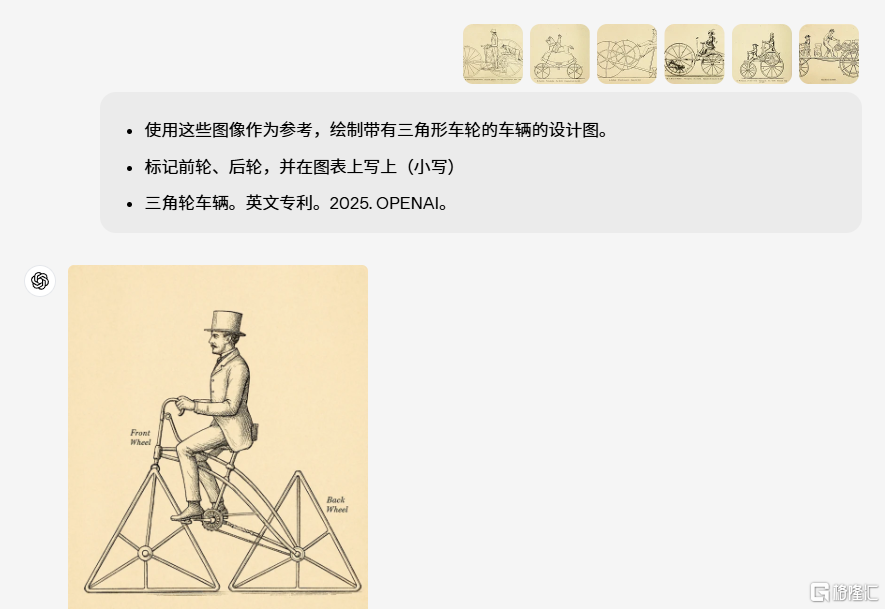
知識運用更直觀:GPT-4o能夠將知識在文本和圖像間建立聯繫,從而構建出一個更智能、高效的知識模型。

照片風格更豐富:通過對多種圖像風格的圖像進行學習訓練,GPT-4o既能生成,也能將圖像轉換為多種風格,從手繪草圖到高分辨率的照片寫實風格都不在話下。

此外,GPT-4o的圖像生成在商業應用領域也展現出巨大潛力。在品牌設計方面,它能生成帶有精準文本的徽標、海報以及廣告;教育領域,可創建科學圖表、信息圖以及歷史圖像用於教學;遊戲開發中,能保證角色在不同設計迭代中保持形象一致。
「文本生成領域的巨大飛躍」
OpenAI宣佈,從周二起,新版ChatGPT將面向ChatGPT Plus、Pro、Team以及免費版用戶開放使用。該公司還透露,該功能也將很快向Enterprise、Edu用戶開放,並通過應用程序編程接口(API)提供服務。
回顧來看,2022年底,初代ChatGPT驚豔亮相,它憑藉對海量互聯網文本的深度分析,能夠回答問題、創作詩歌以及生成計算機代碼,但無法生成圖像。
大約一年後,OpenAI才推出了可以生成圖像的新版ChatGPT,即DALL-E,不過那時ChatGPT和DALL-E是相互獨立的系統。
此次更新意味着,OpenAI把圖像生成工具從DALL-E更換為GPT-4o。
OpenAI研究員GabrielGoh表示:「這是一項全新的技術。我們不再將圖像生成和文本生成分開處理,而是希望把它們融合在一起。」不僅如此,該模型還被集成到OpenAI的視頻生成平台Sora中,進一步拓展了多模式功能。
獨立人工智能顧問AllieK.Miller在X平台上發文稱,這是「文本生成領域的巨大飛躍」,也是她所見過的「最出色的」人工智能圖像生成模型。
不過,儘管GPT-4o取得了顯著進步,但仍然面臨一些挑戰。
比如存在裁剪問題,大型圖像有時可能會被裁剪得過緊;在非拉丁文字的文本準確性方面,某些非英語字符可能無法正確顯示;對於小文本中的細節保留不足,高度詳細或小字體的文本可能會失去清晰度;編輯精度也有待提升,修改圖像的特定部分可能會意外影響到其他元素。不過,OpenAI正在積極採取措施,通過持續優化模型來解決這些問題。