如果有一個會思考但是不會做事的 AI
還有會做事但是不會思考的 AI。
你會選哪個?
如果讓我來選,我會說:why not both?
今天在中關村論壇智譜 Open Day 上,智譜發布了 AutoGLM 沉思——首個帶有沉思能力的桌面端 agent。
這是第一個存在於電腦桌面的,能先思考在做事,且做的過程中不斷思考的 agent。
拋給它一個問題,它會逐步分解問題,然後在你面前(或者你不看着它也行)打開一個又一個瀏覽器標籤頁,自己上去搜索、查找、記錄、匯總、分析信息,最終為你生成一份經過充分查證和深度思考的結果報告。
如果你還不知道這是個什麼東西,簡單前情提要一下:
AutoGLM 是智譜推出的 Agent 產品,能夠實現對手機螢幕和電腦瀏覽器的操作。重點在於實現方式是前台的圖形界面 (GUI),而不是後台的應用接口 (API)。你可以理解為 AutoGLM 學習人類通過「手眼並用」的方式,直接在用戶界面上進行操作。這和市面上絕大多數基於 API 的 agent 產品有着明顯的交互方式區別。
而沉思能力,正如字面意思,讓 AI 可以一邊想、一邊搜,自主解決開放式的、訓練語料不包含的問題,模仿深度思考和展現深度研究的能力。智譜在今年 3 月初拿到新一輪孖展的時候就對外預告正在研發沉思,而這個功能的開關也已經在該公司開發的「智譜清言」(ChatGLM) 大模型產品裏上線了。
而在 AutoGLM 沉思的身上,智譜獨特的 GUI agent 功能,和人們最追捧和愛用的沉思能力,終於實現了融合。
AutoGLM 沉思背後的模型基座,也在本次 Open Day 上正式發布:
GLM-4-Air-0414 基座模型,具有 320 億參數量,但性能足以對標 DeepSeek-V3、R1 (670B)、Qwen 2.5-Max 等更大參數量的模型。
但因為參數量更少,GLM-4-Air0414 可以快速執行 agent 類工作,為 agent 的能力提升以及大規模落地應用提供基礎,也一定程度上確保了終端用戶的試用體驗。
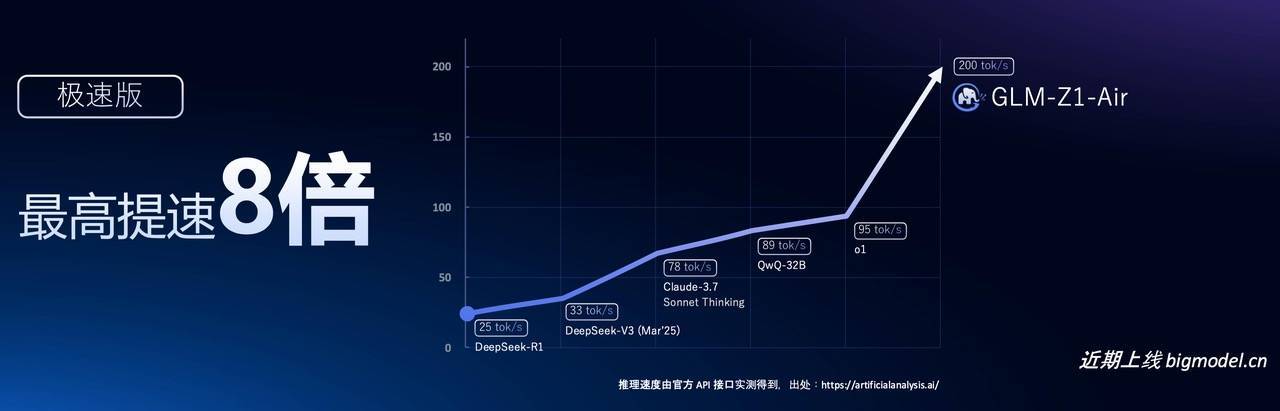
智譜還發布了 GLM-Z1-Air 推理模型,相比 DeepSeek-R1(激活 37B)推理速度提升了 8 倍,而成本降低到只有後者的三十分之一。
這也是一個可以在消費級顯卡上運行的推理模型,能夠顯著提高開發者的使用體驗。
智譜還基於 GLM-Z1 模型,使用自進化強化學習方式,訓練了一個新的沉思模型 GLM-Z1-Rumination,能夠實時聯網搜索、動態調用工具,深度分析和自我驗證。這個沉思模型能夠自主理解用戶需求,在複雜任務中不斷優化推理、反覆驗證與修正假設,使研究成果更具可靠性與實用性。
也就是說:AutoGLM 沉思的基礎模型架構是這樣的:
中層推理和沉思模型 GLM-Z1-Air、GLM-Z1-Rumination
+
底層語言模型 GLM-4-Air-0414
加上工程/產品層的 AutoGLM 工具,就行程了 AutoGLM 沉思的整個技術棧。
智譜也計劃在 4 月 14 日全面正式開源 AutoGLM 沉思背後的所有模型。

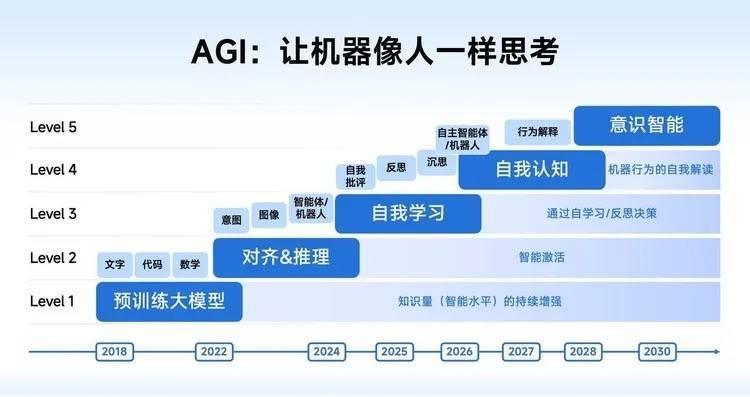
此前智譜曾分享過團隊對於 AGI 路線圖的判斷:如果用自動駕駛層級打比方的話,目前大模型產品大體上獲得了自我學習的能力,接近於 L3;而沉思、反思、自我批評等能力則是 L4 階段。
需要注意的是,目前 AutoGLM 沉思還處於 beta 測試階段。上個周末,APPSO 深度使用了這個產品。從測試結果來看,它在處理複雜工作上的效果確有提高的空間,底層邏輯也需要優化,但作為一個非常新穎的大模型-agent 產品,總體效果已經令人驚豔。
智譜已經踏入了大模型 agent 的 L4 階段,雖然只是進來了半隻腳。
目前 AutoGLM 的沉思功能,目前已經正式上線智譜清言網頁端、PC端和手機 App,免費、不限量地開放。
附上體驗
https://autoglm-research.zhipuai.cn/?channel=chatglm#get_started
當 Agent 有了沉思能力,AI 終於學會自己幹活了?
去年 Anthropic 發布了「Computer Use」,同時展現了足夠的模型能力以及較強的設備交互能力,讓 agent(智能體)的設想終於首次得到實踐。今年 1 月,Anthropic 在美國的最大對手 OpenAI 也通過新產品 Operator,做出對於 GUI agent 理念的演繹。
也是在去年 10 月,智譜和 Anthropic 幾乎同時發布了各自在 agent 方向上的最新嘗試。智譜的 AutoGLM 是第一家國內機構推出的基於 GUI 的 agent 產品。
而今天的 AutoGLM 沉思,不僅將 agent 的執行任務能力帶到了桌面端,更是把工具操作能力、深度研究能力、推理能力和大預言能力進行了首次融合。
這種多重能力驅動的 agent,非常適合信息檢索、提煉、匯總型任務。
這就好比是讓 agent「開車」,過去你得給他一輛車,教他方向盤、油門剎車、檔位怎麼用,甚至告訴它開車和倒車的時候分別要往哪看——而現在,agent 已經可以「自動駕駛」了。
讓它製作一份「不同於網上所有主流路線的日本兩周小衆經典行攻略,要求絕對不去最火的目的地,要小衆景點,但也要評價比較好的。」
AutoGLM 沉思比較準確地拆解了需求,思考邏輯也比較清楚:它首先去搜了最簡單的關鍵詞「日本旅遊」,了解主流路線和景點,然後又去搜索了「日本小衆旅遊景點」之類的關鍵詞——通過這幾個步驟,它在本次對話的記憶內部構建了一個知識庫,也即什麼是主流的,什麼是小衆的。

這個任務總共做了 20 多次思考。有時候幾次思考之間會有重複,比如搜索的是相同的關鍵詞,訪問了相同或者相似的鏈接等。這有可能是因為單次搜索到的信息不足夠,畢竟沉思/深度搜索的本質其實也是不斷地自我懷疑和推翻,直到達到足夠置信度時候才進入下一步。
APPSO 還注意到它有點過度依賴特定的網站作為信息來源,打開的所有 tab 裏有 90% 都是小紅書和知乎(各一半左右)。反而真正的旅行專業資料庫,比如馬蜂窩、窮遊,或者哪怕是 OTA 平台,它一次沒用過。
如果要做一份真正的小衆攻略,重度依賴小紅書的結果可能並不理想。畢竟能上小紅書的熱門筆記,這個景點應該並不真的小衆。一個真正的小衆景點旅行者,恐怕不想去 momo 們已經去過或者都想去的地方……
APPSO 注意到,AutoGLM 沉思在沉思過後自己提出了「路線規劃合理,不要有無意義的反折」、「行程節奏合理,別太特種兵」之類的要求。
只是實際結果沒有反映它自己提出的這些要求:比如頭幾天在瀨戶內海來回折返,有時候一天內去兩三個相隔一小時以上的地點,略微特種兵;第二周從青森向南到仙台,然後又從仙台飛機向北大跨度飛到了北海道,並且北海道只留了兩天。考慮到日本大跨度旅行基本都靠 JR,票價昂貴,合理的路線應該是順着一個方向不回頭,除非不得不去大城市換車,一般不應該折返。
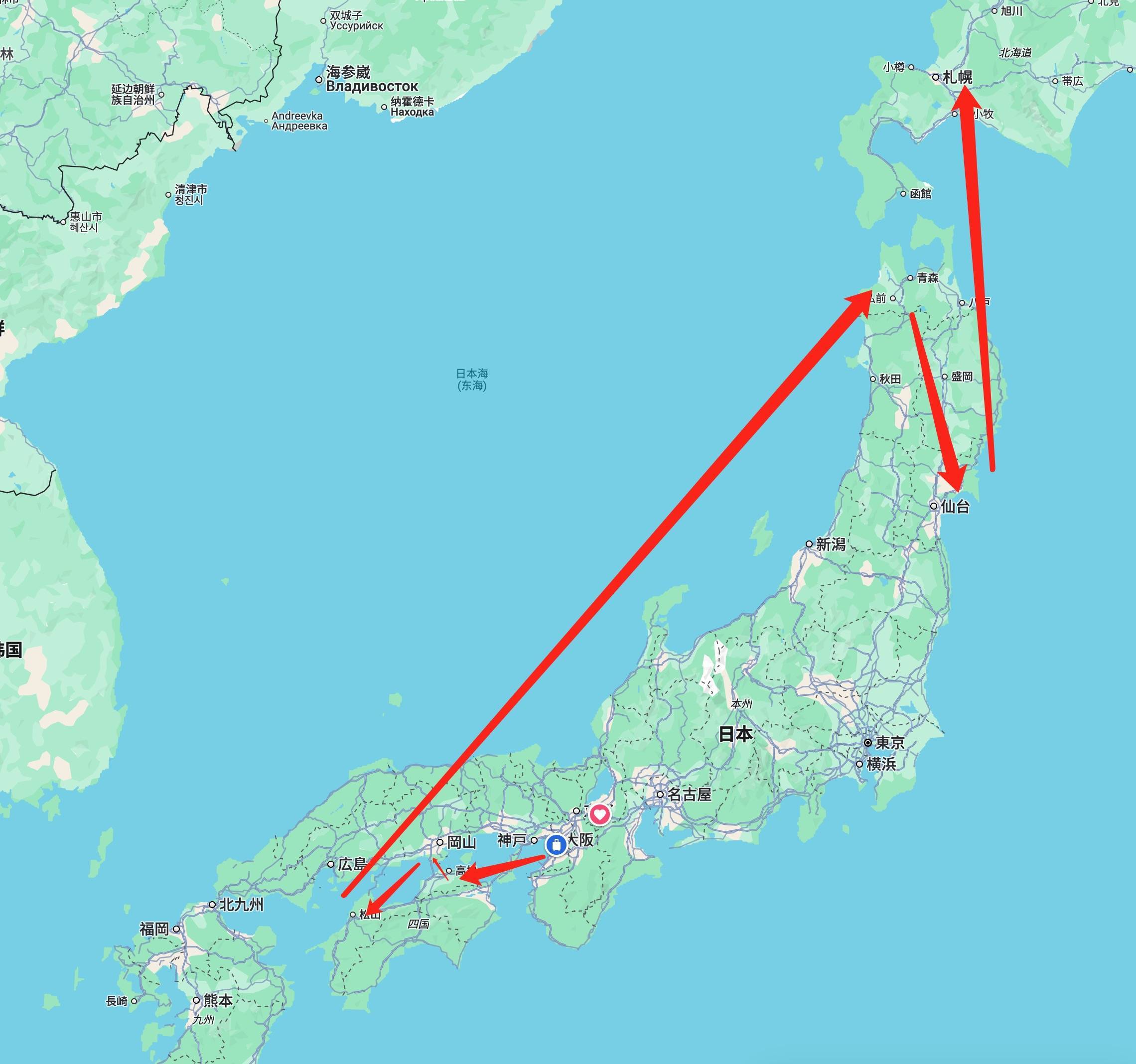
但總體來講,這份攻略是有效的:它呈現了一些提問者未曾考慮過的目的地,也試圖在一次行程裏去到季節、氣候、風格完全不一樣的地方(而不是圍在大東京、富士山、京坂奈區域來回打轉)。
從這個角度,它遵循了提示的要求,並且展現出了深度思考的結果。
就像你不應該直接把 AI 生成的結果直接拿去用一樣,這份攻略提供了一個還算不錯的基礎,讓旅行者可以自行優化具體的目的地、路線和中間的交通方式。旅行不只是上車睡覺下車拍照,還應該兼顧人文和自然,深入當地文化傳統,探索自然景觀,以及至少感受一把在地最有特色的體驗項目。
只要你的期待不是即問即用,AutoGLM 沉思給出的答案是足夠令人滿意的。
點擊查看智譜清言的回答 https://chatglm.cn/share/FQoLp
考慮到 AutoGLM 沉思與其它深度思考型大模型最大的特別之處在於瀏覽器的操控能力,APPSO 也更深入和嚴苛地測試了一下他的 browser use 能力。
讓它做一份關於科創板雲計算公司的研報,看看結果怎麼樣。
正如前一次做旅行攻略一樣,AutoGLM 沉思的「思考過程」是沒有任何問題的。從下圖中可以看到,它:
準確拆解了篩選條件,
明確需要多輪搜索和迭代,
制定了分步驟的計劃,
通過「一般搜索」找到了大概的搜索目標
開始執行分步操作

但是 browser use 的過程實在讓人有點抓頭:AutoGLM 工具一次又一次地試圖打開證監會指定的信息披露網站(巨潮資訊),解析網頁的信息。它順利地找到了網站數據庫的條件篩選工具,但總是無法正常篩選,要麼選不好時間區間,要麼找不到對應板塊的下拉菜單在哪。
APPSO 觀察到,AutoGLM 沉思給每一步驟的定時通常是 3 分 20 秒左右,但如果訪問網站不順利,就會因為操作超時而導致「本輪思考」失敗。
另外,根據 APPSO 之前體驗去年的 AutoGLM 以及其它 GUI agent 產品時,當需要用戶進行登入操作、輸入付款信息、點擊發送按鈕這種敏感性操作的經驗,agent 可以停下來等待用戶操作。而在使用 AutoGLM 沉思的過程中,它的確可以等候用戶登入,但遇到「用不明白網站」的情況,並沒有呼喚用戶接管,而是只會傻傻地等着。

在本次任務中,連續兩輪思考失敗之後,AutoGLM 沉思開始進入一個重新思考-跟之前導致失敗的思考結果一樣-再重新思考的循環過程,一直循環往復了五六次,最後敗下陣來,把目標轉向了知乎。步驟進行到這裏的時候,其實已經算任務失敗了,因為輸入的原始指令是查找和匯總上市公司資料和公告,數據的專業準確性很重要,而知乎並不是一個可靠的上市公司信息披露平台。
經過了好幾次艱難的測試,最後終於吐出了結果:華為、紫光、UCloud 三家公司,雖然都跟邊緣計算有關,但三家的股票代碼都寫錯了,更別提有兩家並沒上科創板。
Agent 「自動駕駛」能力,和路況、駕駛位有很大關係
在其它更「輕鬆」的任務(比如做旅行規劃、遊戲攻略、查找簡單信息等)當中,AutoGLM 工具的 browser use 能力是沒有太大問題的。
但 APPSO 發現,一旦當前網站的視覺設計相對複雜,或者設計的有一些陷阱,AutoGLM 工具就很容易被「使絆子」。
一個最直接的例子就是電商網站。APPSO 給出明確提示,「去淘寶或京東購買一件重磅日系 T 恤」,AutoGLM 沉思制定了宏偉的計劃和明確的分工——然而卻連淘寶首頁的山門都進不去,甚至找不到搜索框在哪裏。而且它似乎被「找不到搜索框」這件事完全阻擋住了,甚至也沒有去看網頁的其它位置——如果它看了的話,肯定會發現相關商品早就出現在首頁推薦裏了。
對於這個測試中發現的意外情況,智譜 CEO 張鵬表示,「點背不能賴社會」,AutoGLM 沉思目前仍在 beta 階段,還有很大的進化空間,而且目前的升級速度也很快(APPSO 在正式發布版上測試淘寶的使用效果已經沒那麼磕絆了)。
張鵬指出,在模型作為服務或作為產品 (MaaS) 的理念下,模型產品自己的能力要像木桶一樣,高且全面。或許現在 AutoGLM 工具的視覺能力還不如人,處理意外情況的能力還不夠,歸根結底可能是泛化能力還不夠,但這些能力的提升並不是模型問題,而是純粹的工程層面——不需要擔心。
從模型底座層面,AutoGLM 沉思也有提升的空間。
經常用大語言模型產品的朋友都知道,提示寫的越具體,規則和邊界設定的越明確,它的效果越好,越有希望生成符合用戶提示的結果。基於大語言模型的 agent 也是一樣。
但是提示不能無限擴展,就好比你招了一個祕書幫你幹活,但你不應該總是每次都把「找誰」、「什麼地點」、「什麼時候」、「去哪」等一切的信息都講清楚,ta 才能勉強順利地幫你搞定一個飯局的準備工作。
大語言模型很強大,但也有它糟糕的地方:只受到文本規則的約束,缺乏真正的實際問題的規劃能力,任務過程中容易被卡住;缺乏足夠長的上下文記憶空間,任務持續時間太長就持續不下去;上一個步驟的錯誤會隨着步驟逐漸放大,直至失敗。
AutoGLM 沉思也是一個基於大語言模型的 agent,即便在 agent 能力上做了很多工作,但仍然難免受到大語言模型的詛咒。思考能力越強,越容易想多、想歪。
從 APPSO 的試用過程中可以看到,除了一些絕對基礎的概念(比如「旅遊」、「T 恤」、「公司」)之外,它並沒有稍微複雜的上層知識。用戶每次發出任何指令,它都要先自己打開瀏覽器,上網學習一遍,明確用戶的所指,在本次對話的有限記憶空間內建立一個知識庫,然後再去進行後續的步驟。
而就它目前最擅長和依賴的那幾個信息來源來看,一旦用戶任務的複雜性、專業性「上了強度」,想要它在用戶可接受的時間(目前官方定的是每任務總共 15 分鐘左右)內,查到真實、準確和有價值的信息,就真的有點勉強了,更別提給到用戶有效的結果(APPSO 的測試中有一半無法輸出完整的結果)。
不過這並不是個太大的問題。
有這樣一個很實際的觀點,可以套用到 AutoGLM 沉思上:
今天的 agent 水平,將它視為「主駕駛」可能能力尚有不足。但它仍然是一個很好的副駕駛 (copilot)。
在 AutoGLM 沉思上,我們看到了足夠的思考能力,也看到了優秀(但確實受制於客觀因素)的 browser use 能力。很顯然,智譜作為中國目前非巨頭公司當中,少數模型能力最強的選手之一,肯定會在這兩個能力上面繼續進步,而且會很快。
自從 APPSO 拿到測試資格,到 AutoGLM 沉思正式發布,中間已經更新了數個版本,在模型基座和瀏覽器操控能力上面都有了改進。
但如果我們想要的是一個真正會思考且能辦事的 agent,我們恐怕需要比現有範式的大語言模型更強大的智能體基座。
而智譜推出的「語言+推理+沉思+行動」的 Agent 框架,儘管產品層面仍然笨拙,但看起來是一個非常明確可行的方向。
誠然,國產大模型和基於大模型的 agent 產品,現階段的目標如果放在「追趕硅谷對手」上可能反而更實際一點。AutoGLM 沉思從操作邏輯和實現目的上,都是明顯區別於目前國內所有同類和近似產品的「新物種」,和 Anthropic、OpenAI 也正在拉近距離。
對於這樣一家非巨頭、脫胎於中國頂級學府的大模型創新領導者來說,大多數的不足都可以被容忍,而看到它在做的事情的獨創性和領導性,才更重要。
