作者丨青橙財經 青風
DeepSeek爆火之後如何與之相處?這是擺在每個大模型廠商面前無法迴避的問題。
騰訊、百度等選擇了快速擁抱,在其旗艦AI產品中相繼接入滿血版DeepSeek-R1,借勢收穫了不少新用戶;字節豆包、阿里通義、月之暗面Kimi、智譜清言等選擇正面對抗,在自研大模型中增加「深度思考」模式;零一萬物更為果斷,在大模型「六小龍」中首家宣佈放棄超大參數預訓練,未來全面轉向ToB業務。
3月31日,百度給出了一個新的答案。在昨日舉行的新一期百度AI DAY上,文小言宣佈完成品牌煥新與功能升級。升級的核心點是,在此前接入DeepSeek-R1的基礎上,新版文小言進一步開放,將百度自研的文心X1、文心4.5等最新模型與DeepSeek-R1、可靈等第三方模型進行深度融合,並支持自動識別用戶需求、自動選擇最適合的模型完成任務,還升級了語音大模型、圖片問答、AI生圖生視頻等多模態能力。

*圖源互聯網
這意味着什麼呢?之前,為了寫一段小紅書的種草文案,新媒體運營人員要用DeepSeek-R1;創作一張海報,要用國外的Midjourney或者國內的百度文心;製作一段宮崎駿風格的動畫,要用快手旗下的可靈AI或者OpenAI旗下的Sora;聲音克隆可能要用海螺AI;求解一道高等數學題,幼兒園小朋友十萬個為什麼的語音聊天,可能還是「鴿了好久」的GPT-4o更可用……
大模型技術越來越先進,但也越來越細分。人們處理日常問題,可能就需要下載和使用不同的大模型產品及衆多的細分版本,需要分別花錢充值,更麻煩的是國外產品使用起來極其不便,中文適配也差。
新版文小言的策略是,一個應用就可以完成衆多不同類型的任務。它既可以做深度思考,完整展示思維鏈,也可以進行連續任務執行,還因為升級了多模態能力,能與用戶進行更自然、更高效的交互。而且,它還從「手動檔」升級為「自動檔」,將任務扔進來即可,不需要用戶操心具體該使用哪個專精模型。
使用簡單,交互方式自然,性能強大,功能豐富,這不就是人們所期待的AI助手的發展方向嗎?對百度這個AI老兵來說,至少意味着找到了一條與新生力量的開放相處之道:優勢互補,相互協作。
01「補齊DeepSeek的多模態短板」
人們到底需要什麼樣的AI大模型?還是史蒂夫·喬布斯的話最有道理,「用戶根本不知道想要什麼,直到你展示給他看。」
在2023年大模型出現的早期階段,衆廠商比拼的是長文本處理能力,月之暗面、百川智能、零一萬物等廠商輪番競技,最長上下文輸入長度從20萬攀升至30萬、40萬字;2024年初,Sora橫空出世,5月份GPT-4o正式發布,讓人們驚呼科幻走進現實,AI生圖、AI視頻等多模態能力的發展貫穿全年始終;2025年初,DeepSeek-R1憑藉強大的推理能力和極致性價比,攪動整個科技行業,將人們的關注重新拉回文字形態的通用大模型。
但在DeepSeek全面普及之後,人們發現,在圖片與拍照、視頻與攝像、語音輸入與輸出等與AI更自然的交互方面,仍然沒有得到很好地滿足。最近,GPT-4o升級,上線了「用嘴P圖」功能,「吉卜力風」圖片刷爆AI圈,讓千千萬萬設計師們人人自危。再次證明,多模態能力一直留存在人們潛意識的需求菜單裏,且需求巨大。
DeepSeek固然強大,但在多模態方面存在明顯的短板,僅限於在圖片和拍照中識別裏面的文字。可以說,DeepSeek的輸入輸出全部都是文字的。騰訊元寶接入了DeepSeek-R1,但只是解決了DeepSeek官方應用「服務器繁忙」的問題,也沒有帶來多模態的增益價值。

*圖源文小言
而新版文小言將百度兩大新模型文心大模型X1和4.5與DeepSeek-R1滿血版,進行了多模型融合調度。用戶可以隨意切換使用,或者更省事地選擇「自動模式」。百度這兩個新模型在推理和多模態方面各有側重。
文心X1與DeepSeek-R1類似,都是深度思考模型,但文心X1是宣稱「首個」能自主調用比如繪圖等各種工具的,可以完成⼀些連續任務。它利用遞進式強化學習訓練方法、基於思維鏈和行動鏈的端到端訓練、多元統一的獎勵系統等技術,推理輸出直接可以圖文混合呈現。
文心大模型4.5是百度自主研發的新一代原生多模態基礎大模型,在多模態交互、理解方面更強,原生模型聯合預訓練能實現更深層次的模態融合。拍圖解題,文生圖,讓圖片動起來,AI語音聊天,都可以很好地實現。
其語音大模型此次也進行了全新升級,使用起來頗有亮點,比如它支持方言對話、複雜知識問答及隨時打斷等場景,用戶可進行語音知識問答或趣味角色扮演。
百度語音首席架構師賈磊透露,該模型是百度在業界首個推出、基於全新互相關注意力(Cross-Attention)的端到端語音語言大模型。在語音場景滿足一定交互指標下,大模型調用成本比行業平均降低50%-90%,推理響應速度極快,將語音交互等待時間壓縮至1秒左右,極大提升了交互流暢性。
02「更多場景更多玩法」
藉助多模型融合和多模態理解,新版文小言帶來更多的用戶真實存在的AI使用場景和更大的想象空間。
像上面提到的,動畫愛好者如果想製作一段視頻,往往要先用DeepSeek生成提示詞,再用Midjourney文生圖,再拿到可靈AI中做圖生視頻。現在文小言可以一條龍解決了。比如讓愛因斯坦彈吉他,邊彈邊跳。

*圖源文小言,愛因斯坦彈吉他AI視頻(GIF)
還有個非常常見的場景,家裏客廳裝修,有一整扇落地窗,想參考幾個不同的風格設計。用白話給文小言輸入提示詞後,文心X1會進行深度思考,然後調用搜索、畫圖等多種工具,最後生成多張效果圖,每張都附有該風格的設計說明,圖文混排輸出,清晰明瞭。
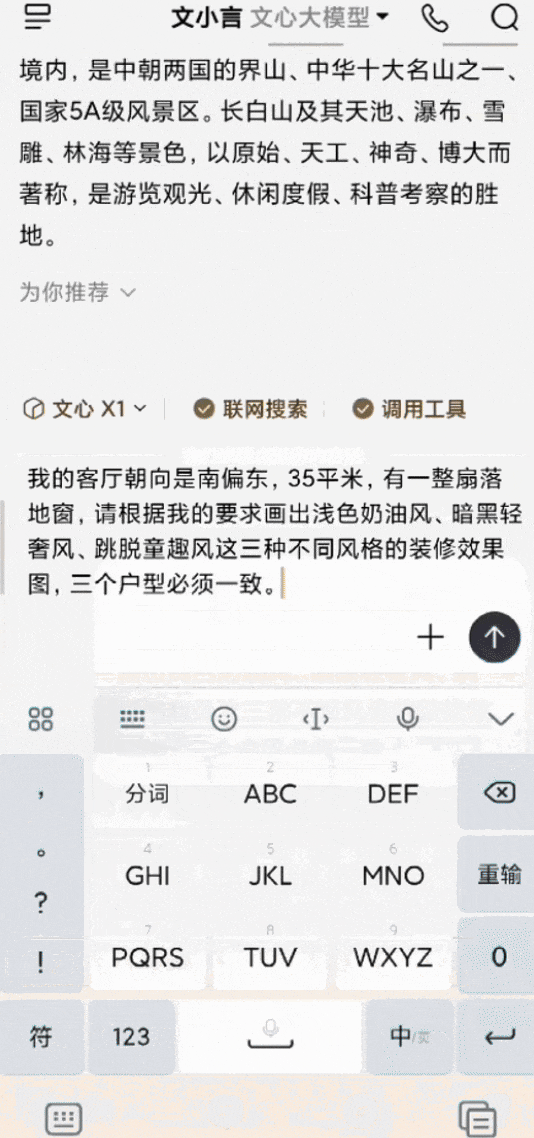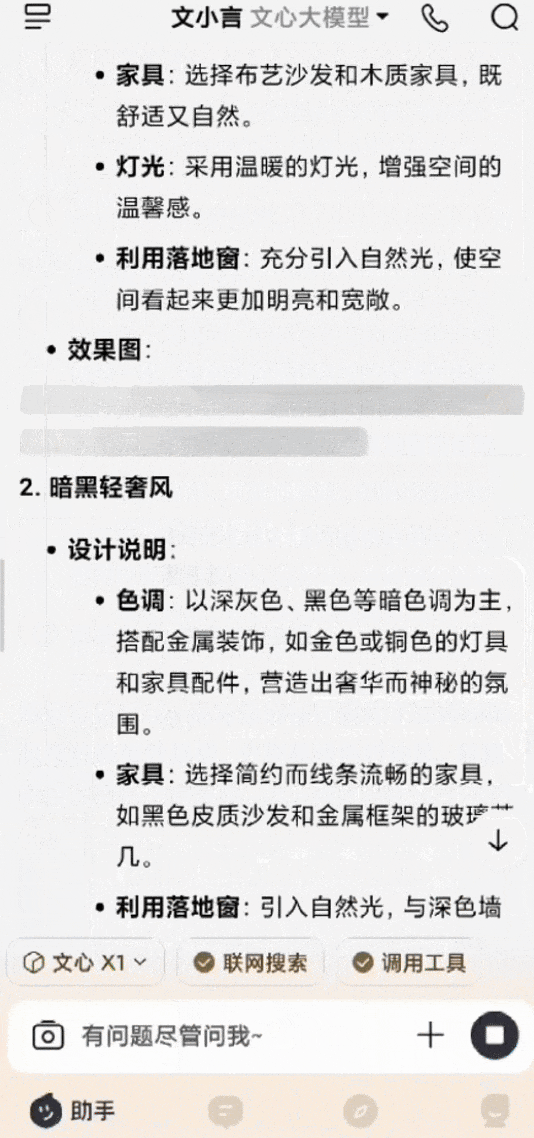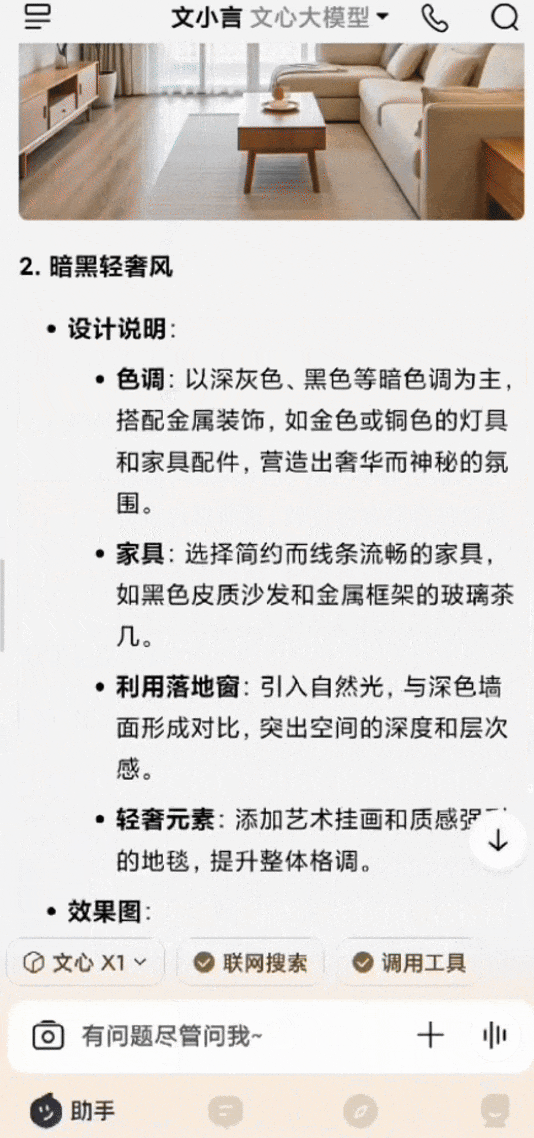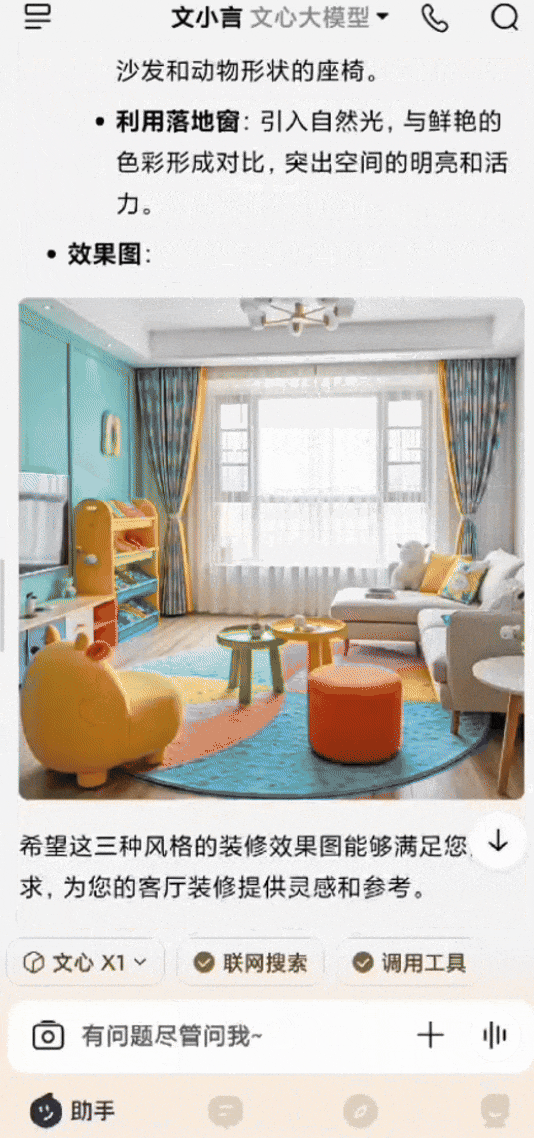
*圖源文小言,裝修設計示例(GIF)
再比如輔導孩子功課,讓很多家長頭疼,因為很多題目可能自己也不會做。新版文小言中新增了一個「解題老師」,直接對題目拍照,它就可以生成解答。神奇的是,它還有老師講解的視頻,不只給出答案,還給出詳細的做題思路和步驟,用語音和視頻展示娓娓道來。就像個一對一的家教,而且是免費的。這種多模態解題功能的難得之處在於,它不是簡單地給孩子提供答案,而是指導了做題方法,傳統大模型僅通過文字很難達到這種效果。
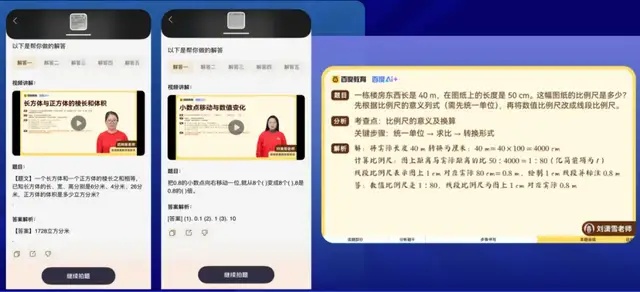
*圖源百度
文小言新的端到端語音模型能夠識別兒童的含糊發音,理解能力更符合兒童的習慣包括快速打斷與響應。比如要求它給孩子講個故事,如果不愛聽,孩子直接打斷要求換一個,文小言能絲滑銜接,不會再出現之前智能語音那種「你說你的,我講我的」的尷尬局面。它還能切換蠟筆小新、孫悟空、熊大熊二等百變音色,更學會了重慶話、河南話、廣西話等多種方言。
03「寫在最後」
⼤模型馬拉松競賽進⼊「深⽔區」,因為用戶真實需求的多樣性,導致未來的競爭不可能再是單⼀模型的能⼒,⽽是如何讓AI能⼒更⾼效、更便捷地觸達⽤戶。
百度在AI大模型領域深耕多年,在AI搜索、檢索增強的文生圖技術(iRAG)、無代碼工具、智能體生態構建等方面積累了很多經驗,尤其是擁有海量的中文語料庫,這比一衆國外產品具備明顯的本地化優勢。
在增強自身能力之外,百度近期也愈發體現出開放升級的姿態。將DeepSeek兩款大模型上架至千帆ModelBuilder平台;宣佈搜索引擎和智能體平台接入DeepSeek;文心一言全面免費;宣佈文心大模型系列開源;如今,文小言新版App又將最新模型與DeepSeek深度融合,多模態能力大幅提高。
文小言採用「模型矩陣+自動調度+生態開放」的策略,試圖構建一條具有持續競爭力的產品護城河。這一趨勢或許將成為未來AI演進的主線。而在這個過程中,用戶體驗得以不斷提升,將是最大的受益者。