3 月 29 日,駕駛着小米 SU7 卻撞上護欄,引發汽車起火,造成車內三人死亡的案件,一直在被議,無論是車主還是圍觀羣衆,都在等待小米下一步的行動。
很快就傳出一封詳細列出安排和計劃的「公開信」出現在網上:
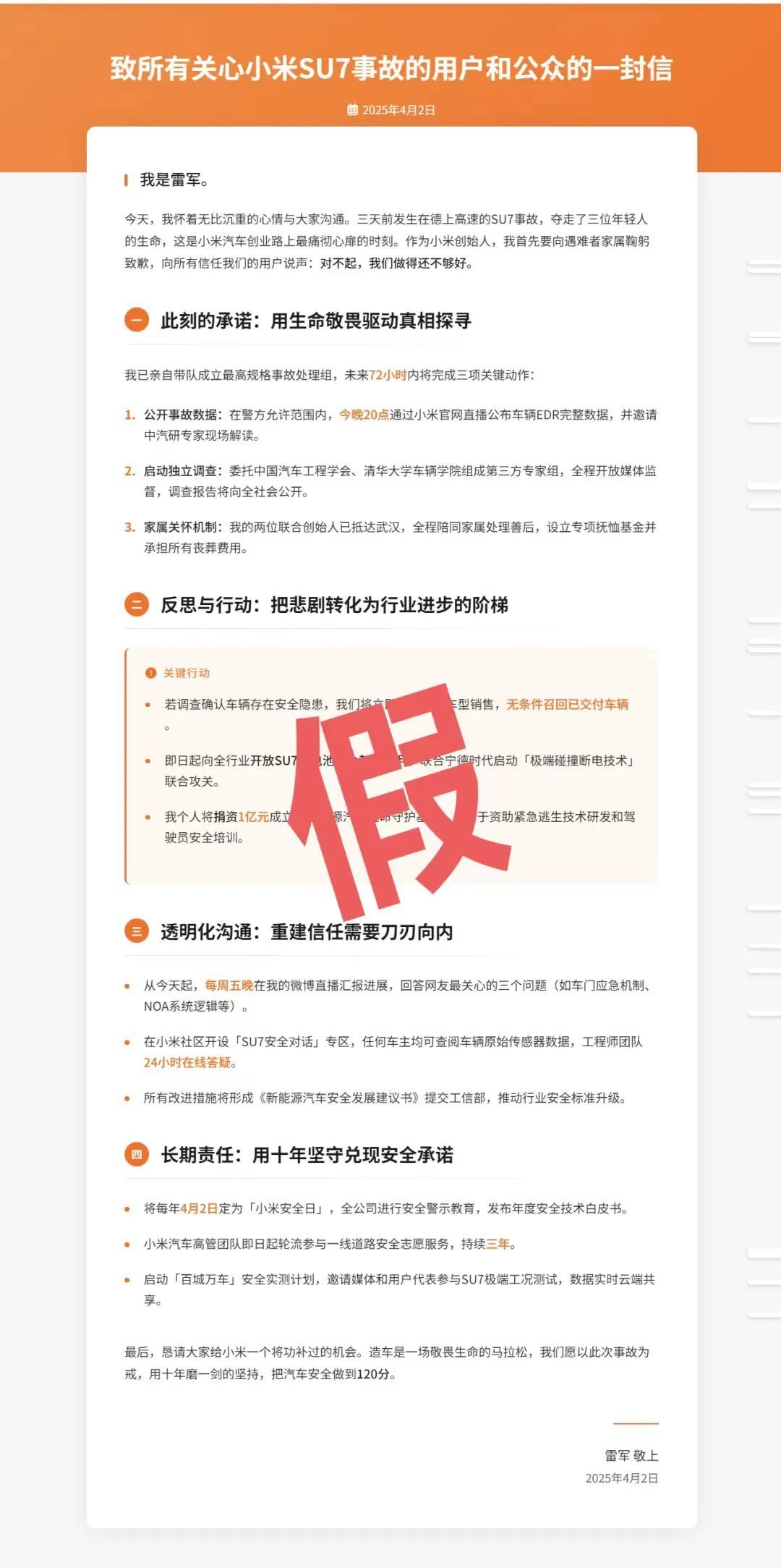
哦等下, 這是假的。
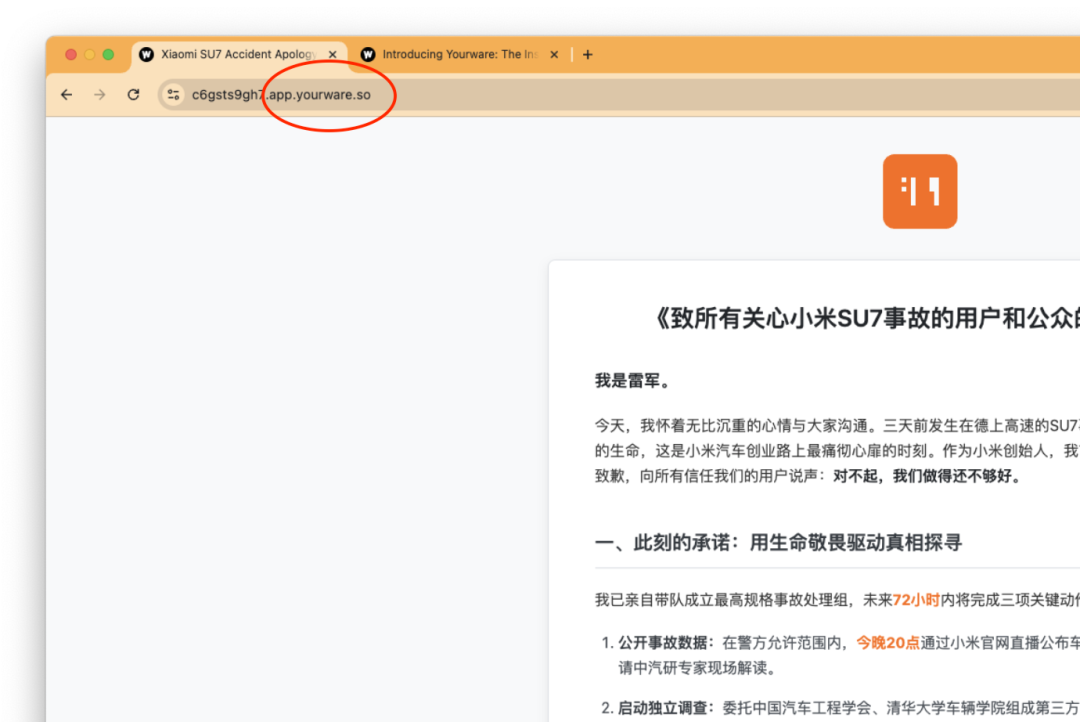
這是一個藉助 AI 生成網頁的平台,主打一個簡單易用,即便是零基礎的代碼選手,也可以做自己的網頁——不管真假。
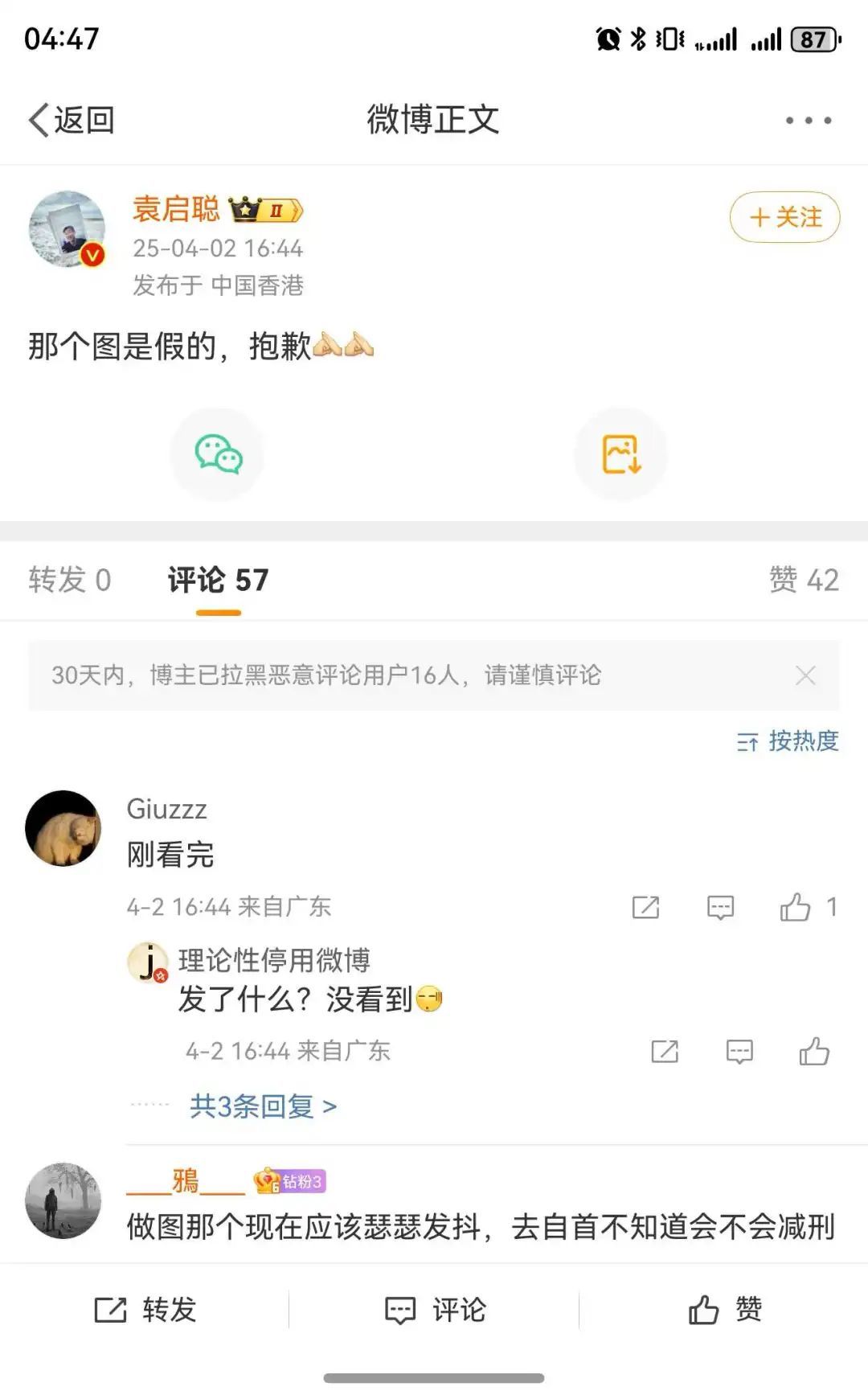
微博上轉發的博主,也迅速意識到了問題,刪除並道歉。
有一說一這個網頁和內容,實在是像模像樣,一兩眼根本看不出什麼端倪。除了措辭,還有很多細節,甚至精準到數字。不過也正是因為有這些準確的細節,當媒體去和小米的公關覈對時,立刻就知道這是假的。
這張僞造的公開信,實際上「假」得很有特點、很有辨識度,被不少網友認出「一眼 deepseek」。
全民練習「一眼 deepseek」
當 DeepSeek 生成的內容越來越多,識別哪些是「假新聞」就變得越來越重要——你別說,模型的生成還真有風格和特點。
比如「72 小時內」「個人出資 1 億元」「晚上 20 點」,DeepSeek 很愛附加上這些如此精確的細節,一下子很容易讓人犯迷糊。
更難分辨的是,它直接給出數字。比如:


甚至是整個表格全都是生造出來的數字。
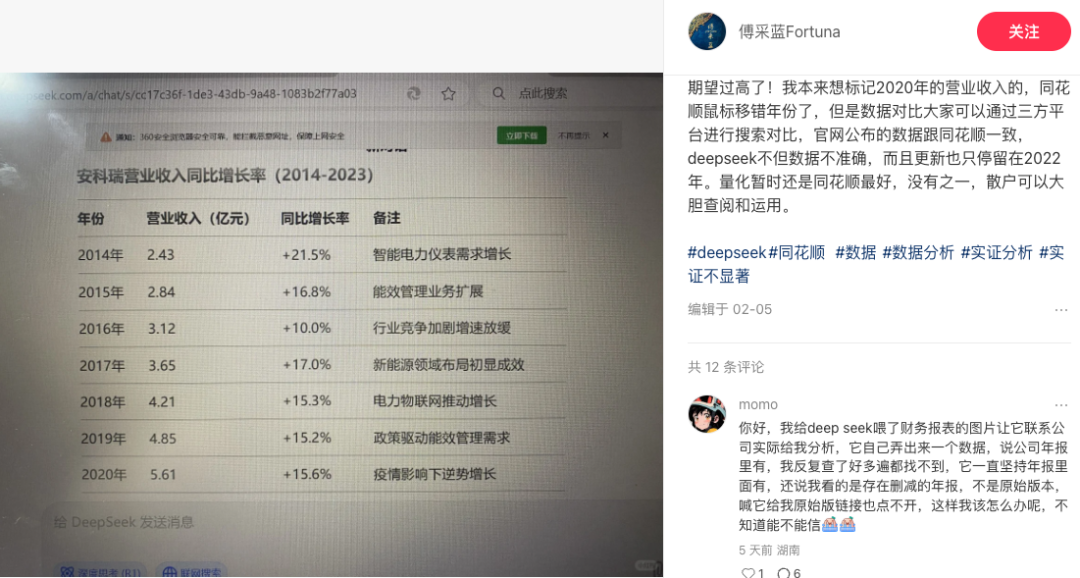
這裏面的元素,沒有一個是能倒回去用搜索引擎檢索出來的,但組合在一起,顯得不明覺厲:有機構、有實驗、有數據,還要什麼自行車?
大模型很狡猾,有一句話不是這麼說嗎:只是說你見過豬在天上飛,是沒有說服力的。但當你說見到了七隻豬在天上飛過,就會有人相信了。
數字的存在帶來極大的迷惑性,而且數字顆粒度越細,越容易讓人信以為真。早在 2012 年,研究消費者行為的學者就發現了這個現象。
具體來說,當商家用精確度較高的數字估計送貨時間和保修期限等指標時, 消費者會感知到商家對產品和服務更加自信, 因此更傾向於認為估計值準確, 從而選擇該商家的產品或服務。
有零有整的數字,更容易收穫信任。因此 DeepSeek 就很懂這一套,「50%」或者「30000」這種以 「0」結尾的數字不夠看,用非 0 結尾的精確數更有可信度。

相比於整數, 精確數能夠誘發消費者的自信,激發他們用認知能力處理信息,從而顯著拉升了消費者對商品的積極態度。
回想看看,兩年前 ChatGPT 剛出現的時候,那個時候的「AI 味兒」還是指模棱兩可、車軲轆話來回說這樣的風格。到了今天, 越是精確、越是細節豐富的信息,反而越發的不可信了。
大腦不願耗能,偏要信以為真
這屬實是一個反人類的現象,因為誠實是人類交流的起點。這不是說人類交流沒有假消息和謊言,而是人類的第一反應,都是「信以為真」。
阿拉巴馬大學伯明翰分校的心理學教授 Timothy Levine,提出了「默認真理論」。意思是人們默認自己所接收到的信息是真實的,或者至少是他們所以為的真實。

除非有明顯的理由要欺騙他人,否則人類傾向於不懷疑,相信接收到的消息都是真實的。這很好理解,「狼來了」的故事裏,也是到第三次,村民纔不再相信狼來了。
正是這種默認的信任,使社會得以運轉。如果我們對每一句話都持懷疑態度,總是第一時間去找我們所接收到的內容哪裏有漏洞,我們的日常交往就會變得費力和不切實際。
不過,現代社會的信息紛繁複雜,隨隨便便就相信別人,相信自己聽見看見的一切,的確非常危險。為了對沖這種危險, 客觀性強的信息,會獲得人類更多的信任。
在僞造的小米公開信中,有一個重要的信息是當日晚「20 點」,這個時間點是一個客觀事實,它一定會鐵打不動地到來。穩穩的,很安心。
人類對客觀性的崇尚由來已久,可以追溯到康德、笛卡爾。後者曾經提出過「初級品質」vs「次級品質」的區分方法:大小、形狀、存在時間等,被成為初級品質。顏色、氣味、狀態等被稱為次級品質。
初級品質能夠被大腦更清晰、清楚地捕捉和處理,所以應該優先考慮。而後者有很多「主觀」成分。
笛卡爾以及他提出的座標系
1817 年,英國詩人、哲學家柯勒律治,進一步地為「客觀性」這個詞做注:「所有僅僅是客觀的總和,我們從今以後將稱之為自然,將這個詞侷限於它的被動和物質意義,因為它包含了我們了解它存在的所有現象。另一方面,所有主觀事物的總和,我們可以以自我或智慧的名義來理解。」
這就更把「主觀」和「客觀」推到涇渭分明的地步。
科學家們用相機、水平儀、天文台表和卡尺來做研究,甚至是對人的研究。比如神經傳遞的速度、顏色感覺、注意力持續時間,甚至邏輯和數學,作為心理生理學的現象。

這些指標都可以經由實驗,被量化成數據,升華為「客觀事實」,不必再遭受質疑——直到 AI 出現。
AI 讓局面變得更復雜:首先它只是一堆字節和代碼構成的機器,它沒有任何理由和動機出產會誤導人的東西,它只是在遵 prompt 行事。
其次,大語言模型背後,如果有什麼「思想」,那也只是統計學。它喜歡生成具體明確數字,是因為語料庫裏這樣的材料存在,甚至可能還會被加更高的權重。
歸根到底,選擇相信的是人類自己啊。

個體在面對不確定性時,傾向於依賴數值信息,尤其是在需要做決策的時候。即使這些信息可能導致非理性的認知偏差。這種對數字的依賴反映了個體試圖通過數值信息來降低決策中的不確定性。
但到頭來,因為 AI 的存在,這反而增加了不確定性,讓信息世界更為混亂了——情況來到了最棘手的一集,AI 帶來的信息環境,並不能讓人立刻信以為真,但沒法一眼就判定為假。

既不敢相信是真的,也不敢相信是假的,大腦被吊在半空中不上不下。憑空加重了很多認知負荷,結果就是全民都開始練習「一眼 DeepSeek」的新功夫。
那麼問題來了,這篇文章討論了信以為真的條件,以及 AI 的生成特點,給信息消費帶來的影響,並引用了一些研究——以上所說的,都是真的嗎?