IT之家 4月15日消息,蘋果公司昨日(4月14日)發布博文,披露其AI隱私保護核心技術細節,重點介紹差分隱私和合成數據在Apple Intelligence中的應用。
差分隱私守護AI進化
以生成Genmoji表情為例,用戶選擇共享設備分析數據時,系統會通過隨機噪聲算法,收集高頻指令(如「戴着牛仔帽的恐龍」),但不會記錄頻次過低的個性化指令,且所有數據與設備ID完全脫綁。
具體實現中,設備端會隨機返回真實指令片段或干擾信號,只有某條指令被數百設備同時提交後,系統纔會識別。這種機制已幫助優化多實體組合表情的生成準確率,且全程不觸及IP地址等敏感信息。
合成數據破解長文本難題
面對郵件摘要等涉及長文本的功能,蘋果研發了專有合成數據方案。首先由大語言模型批量生成虛擬郵件(如「明早11:30打網球嗎?」),將其轉換為包含主題、語言特徵的數字向量(embedding)。IT之家附上蘋果官方博文演示圖如下:
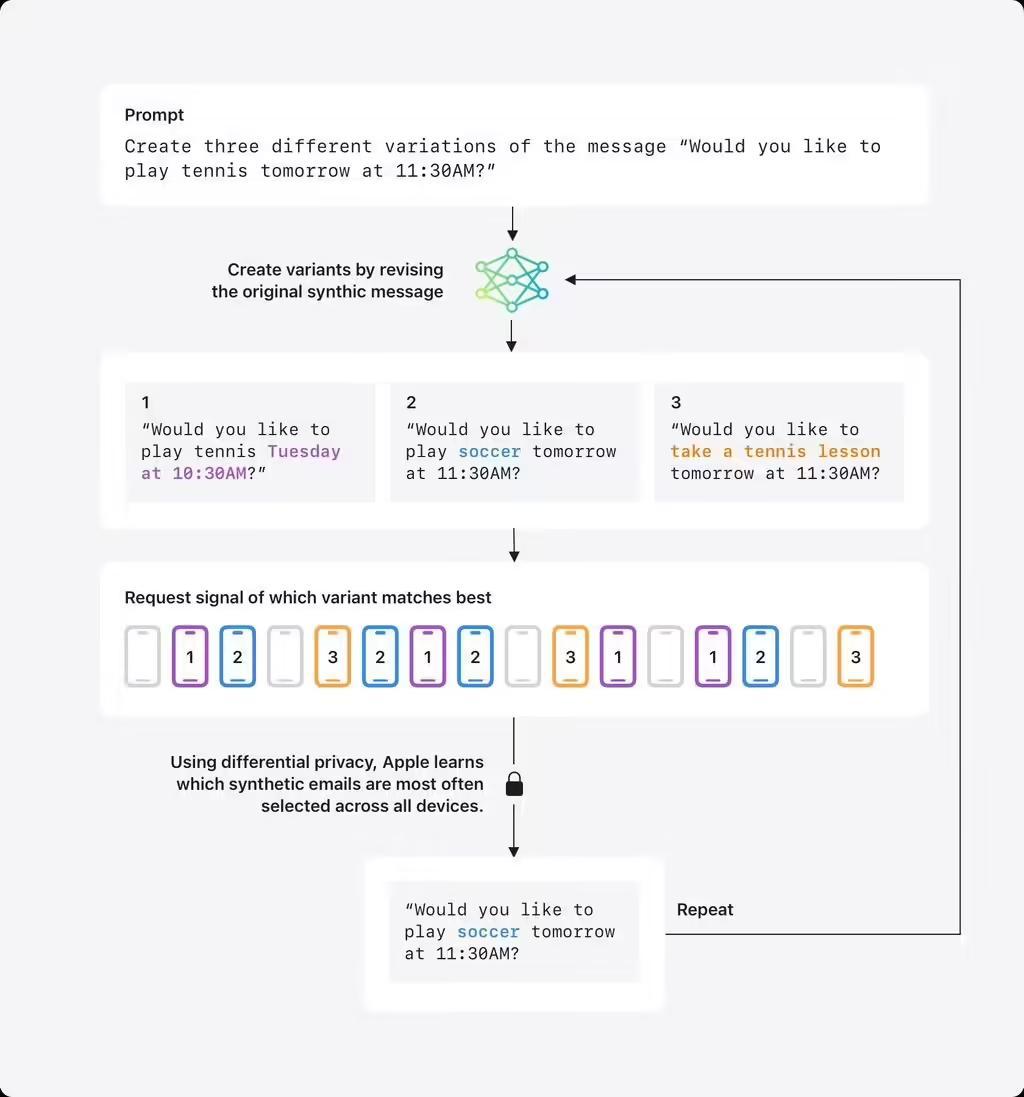
參與計劃的設備會在本地計算真實郵件的向量,通過差分隱私技術匿名反饋最接近的合成向量類型。經過多輪迭代,系統最終獲得能反映真實郵件分佈規律的合成數據集,但全程不接觸原始郵件內容。目前該技術已在測試版郵件摘要功能中驗證效果,未來還將應用於寫作助手等場景。
隱私原則貫穿技術演進
蘋果在博文中強調,Apple Intelligence所有模型訓練均採用去標識化數據,會預先過濾社交安全號等敏感信息。
即將發布的iOS 18.5等系統中,差分隱私和合成數據技術將擴展至Image Wand圖像處理、記憶相冊生成等十餘項功能。蘋果強調,即使用戶啓用設備分析計劃,其個人數據也始終加密存儲在本地,公司僅獲取經數學驗證的羣體趨勢報告。