
「超前一步是瘋子,超前半步是天才。」
作者丨西西
編輯丨陳彩嫺

過去兩年,關於大模型的討論視角很少從商湯這樣成立不過十年、資源與技術積累正當青壯年的人工智能公司出發。造成這一現象的主要原因是兩個技術周期的迥異:
2023 年之前,商湯的人工智能技術路徑以計算機視覺模型為主,不同於 ChatGPT 為代表的新技術浪潮:以自然語言處理為主、大規模參數模型為核心。一個是視覺、一個是語言,在外界看來兩個賽道還沒有發生直接的關係。
然而,DeepSeek R1 的發布讓一切變得「戲劇性」:ChatGPT 之後,各個大語言模型廠商在卷 GPT-4 的路上狂奔兩年後幾乎所有努力被 V3 與 R1 抹平。當語言方向的基礎模型出現新的 SOTA,所有人都面臨兩個選擇:要麼以 DeepSeek 為靶子、繼續卷最強語言大模型,要麼尋找差異化的競爭點。
且不說 DeepSeek 的目標是 AGI、下一代基礎模型未必只卷語言,單從數據源來看,根據權威研究機構 EPOCH AI 的調查(如下圖),用於訓練大語言模型的文本數據正在迅速接近危機點;據預測,到 2028 年,語言大模型的訓練數據集將用完互聯網的所有可用文本數量。
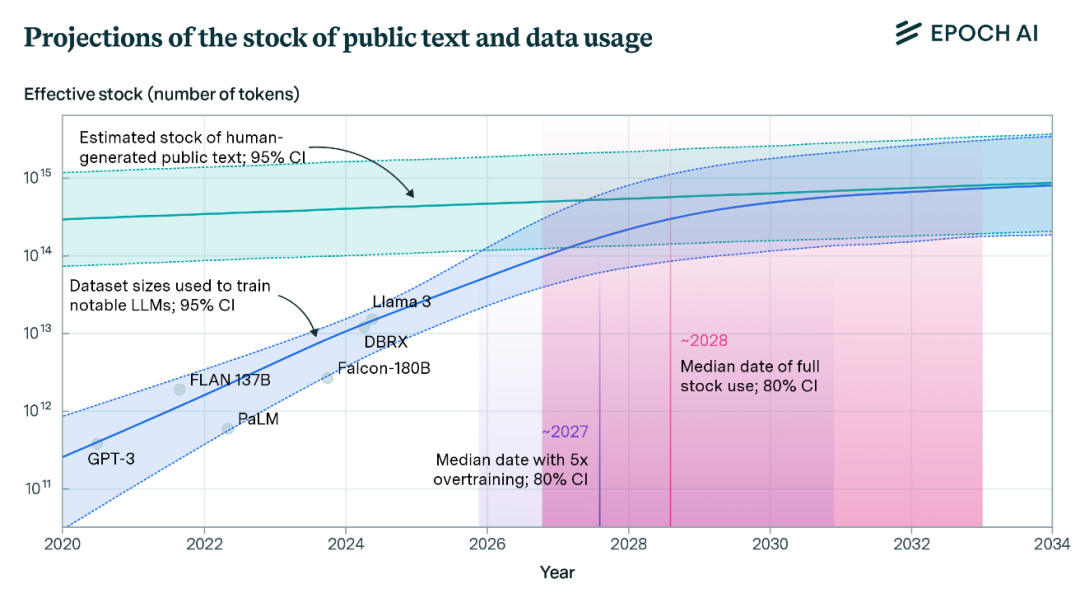
與此同時,近日語言大模型也逐漸體現出性能隨參數規模加大提升的邊際效益遞減趨勢。因此,相比大語言模型的競爭,更多頂尖團隊將目光看向了邁向 AGI 的下一階段:多模態大模型。繼 GPT-4o 後,OpenAI、谷歌與 Meta 等科技巨頭陸續發布了 GPT-4.5、Gemini 2.0/2.5 Pro 與 Llama 4 等數個性能強大的多模態基礎模型。
當語言與視覺融合漸成趨勢,商湯的過去與人工智能的未來聚首,其在國內大模型市場格局中的角色也逐漸變得更加舉足輕重:
除了商湯大裝置與過去十年所積累的行業落地經驗,商湯在基礎模型的研究上也逐漸佔據優勢,經過兩年的投入努力,不僅彌平了文本的差距,而且在最新的多模態大模型中厚積薄發。
據商湯 4 月 10 日的發布,其新一代 6000 億多模態大模型「日日新 Sense Nova V6」 在多模態綜合能力上可以向 GPT-4.5 與 Gemini 2.0 Pro 看齊、甚至略微超過。不僅如此,商湯還引入長思維鏈,率先將多模態與深度思考結合了起來。
事實上,商湯從 2024 年年中就開始探索原生融合的多模態大模型,並早已在今年的 1 月 10 號、R1 發布並爆火前登上 SuperCLUE 和 OpenCompass 兩大權威排行榜榜首,成為大語言與多模態能力的「雙冠王」。
前有商湯大裝置領先半步,後有原生多模態大模型厚積薄發,商湯在大模型這波浪潮中的綜合競爭力或許被嚴重低估了。
01
是落後,還是領先?
一個不爭的事實是:在第一個十年成立的人工智能算法公司中,經過兩年的大模型技術革新,商湯是極少數能夠迅速轉彎、從視覺算法跨越到大模型技術周期並保持算法創新生命力的 AI 公司之一,手持兩大通行證——大裝置與日日新。
2023 年大模型風靡初始時,商湯憑藉大裝置拿到了大模型的入場券,在業內創下不到一個月就構建起服務於大模型訓練的千卡集羣,不僅使商湯在龐大算力上的投入有所回報、開始盈利,還為商湯在後續趕超基礎模型的研究上贏得了時間。
如果說商湯的大裝置領先行業至少 3 年,日日新的正式發布比行業最早晚 1 年,將算力與算法協同、再考慮商湯在過去十年所積累的商業化實戰經驗來看,事實上商湯大模型的綜合實力大約領先行業 1-2 年。而在商湯陸續發布原生融合多模態大模型日日新 SenseNova V6 後,這一差距又被拉長至少半年。
為什麼這麼說?
因為當前原生多模態大模型的技術難度仍極高,而商湯的日日新 V6 已能達到對標國際頂尖多模態大模型 GPT-4.5 與 Gemini 2.0 Pro 的水平。
雖說過去兩年海內外發布了大量的多模態模型成果,但真正能夠在輸入與輸出端同時做到文字、語音、圖像、視頻等至少兩個模態數據融合,並完成從感知、理解、推理到決策、生成等任務環節的多模態大模型還寥寥無幾。
這要求從底層架構、高質量數據清洗到上層算法的整體創新,如 Transformer 雖擅長文本的長序列表達、卻久有說法認為其在多模態乃至空間智能中有待提升,且暫無暴力出奇跡的先例,最新案例可參考 Meta 發布的 Llama 4、即使投入巨大也提升甚微。
目前多模態模型的廣泛研究方法大體可以分為兩條路線:一條是從語言模型出發,在語言模型的基礎上疊加其他的語音、圖像等模態;另一條則是從視覺出發,在圖像或視頻的基礎上疊加語言、語音、視覺等模態。此外,多模態研究在終局上也有追求 AIGC 與追求 AGI 之分,這決定了多模態模型的研究天差地別。
當前多模態模型仍以百億參數規模為主,這背後的原因主要是兩點:一是多模態大模型所消耗的算力要比純語言大模型更大;其次,當多模態模型的參數規模上升到千億級別後,不同模態之間的數據融合、讓彼此相得益彰而非此消彼長的難度也變得更大。
有研究團隊曾向雷峯網描述過這樣的一個研究難題:當他們嘗試從百億文本模型擴大到超五千億多模態模型後,後加入的圖像、視頻與語言數據出現了拉低文本數據表現的現象。由此可見,要獲得一個多模態數據規模擴大到數千億、且多個模態之間能相互「提攜」的高水平原生多模態大模型,難度極高。
據商湯科技聯合創始人、執行董事及人工智能基礎設施和大模型首席科學家林達華介紹,商湯從 2024 年 5 月 GPT-4o 發布後就開始堅信多模態大模型是未來,於是迅速開始研究。一開始商湯也是採取傳統的「核心模態+次要模態」路線,但會出現一個模態削弱另一個模態的問題,沒有達到 1+1>2 的效果,之後投入大量時間攻堅兩個以上模態之間的橋接技術,12 月訓練出「雙冠王」驗證了他們的原生融合路線。
在 12 月那版融合模型的基礎上,商湯繼續 Scale Up,實現了新一代原生融合多模態大模型 SenseNova V6,參數規模 6000 億,且根據官方評測數據披露,V6 不僅在綜合多模態任務上對標 GPT-4.5 與 Gemini 2.0 Pro,且在純文本任務上也能比擬 DeepSeek V3(看下圖左表)、推理能力比擬 GPT-o1(下圖右表):
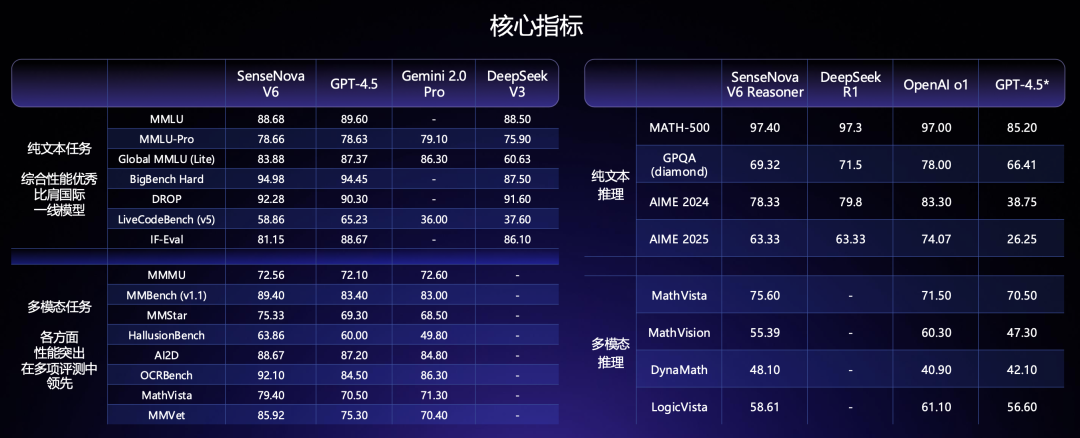
注:谷歌 Gemini 2.5 Pro 才發布不到一個月,各項指標還未有公開評測分數,暫且不計
V6 的主要技術創新性體現在兩塊:一塊是多模態的關鍵橋接,在模型的預訓練階段就已經將文本、語音、視頻和圖像等數據融合在一起訓練,使不同模態之間相輔相成,在同一個上下文窗口對齊;另一塊則是對 DeepSeek 核心思想的借鑑與先前半步,具體表現為多模態的長思維鏈構造與輸出端的融合 RL(強化學習)。
DeepSeek 目前仍以文本為主,而商湯從頭到尾都是以開發多模態大模型為核心,因此在深度思考與強化學習的技術上也以多模態為母體,率先探索了多模態模型的長思維鏈構造。
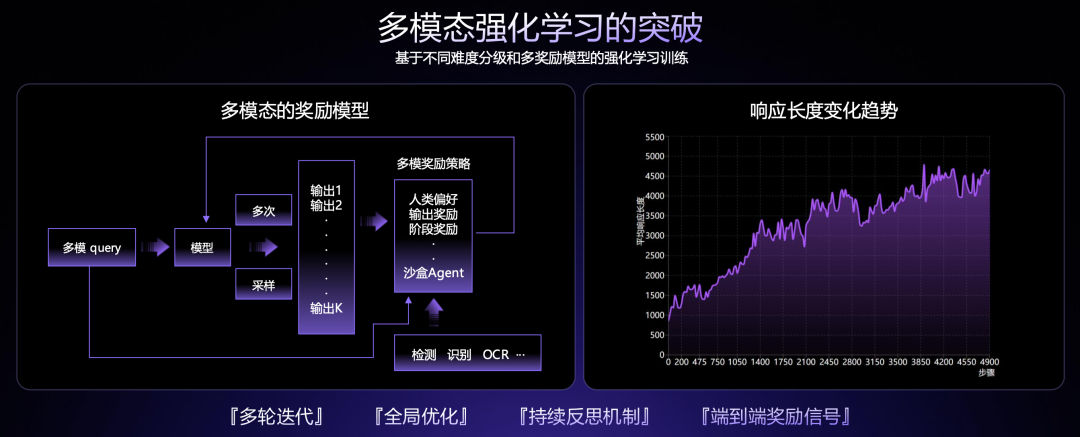
據了解,目前商湯通過智能體生成的思維鏈總儲備已經超過 1000 萬條,日日新 V6 能夠生成長達 64K 的高質量思維鏈,這意味着商湯的多模態大模型在解答用戶的提問前就已經能夠進行超過 6 萬字的深度思考,發展全局記憶。
商湯的獨特之處是,在構建思維鏈的過程中,每一步都會利用前一步的圖文多模態信息、以及綜合的推理情況來進行下一步思考推理。換言之,V6 的每一步推理都有一個形象的思維與一個邏輯的思維混合——這也是與純語言思維鏈的一大不同之處。
而此前無論是人類的成長路徑還是大模型的迭代進程,都表明了:多模態數據不僅能彌補純語言大模型的數據瓶頸,且多模態模型的學習效率更高。
據林達華坦言,V6 並沒有完全消除大模型的幻覺問題,而是通過輸入端的數據質量嚴格把關與輸出端的融合 RL 來緩解幻覺問題。相比 DeepSeek R1,V6 的獎勵信號會更豐富,包含結果獎勵、RLHF 獎勵以及通過視覺理解判斷模型語言描述與圖像視頻是否一致等;同時在模型的思考過程中分階段進行基於事實、而非獎勵的強化學習。
在多模態大模型的訓練上,由於大裝置與大模型的緊密協同,商湯日日新 V6 的訓練與推理也進行了極大的效率優化。
據商湯科技聯合創始人、大裝置事業羣總裁楊帆介紹,商湯自己去訓練 DeepSeek 模型的訓練效率,比原廠發布出來的指標還要好。商湯大裝置可以達到每卡每秒 1600+ 個 token,DeepSeek 官方報告所披露的數據是 1500+ token。
除了大裝置,商湯在自有訓練引擎 SenseParrots 上也搭載了最早跑通千卡訓練的系統。此外,商湯從 2018 年開始用國產芯片進行模型訓練,國產芯片數量至少佔比 20%,V6 的一部分訓練也是在國產芯片上進行的。
在推理上,商湯大裝置採取了 PD 分離、通信計算摺疊、FP8 強化與算子優化等方法進行效率優化,在線服務推理性能超行業平均水平 25%;離線推理方面,與開源方案相比,商湯大裝置在 Prefill 階段提速 5 倍、Decode 階段提速 3.5倍。
DeepSeek 在大語言模型賽道的後來居上已經表明:AGI 的長跑需要算力與算法的綜合能力。而相比純語言模型,多模態大模型無論是訓練還是推理都需要更高的算力,細微的進步累積起來即是長遠的差距。技術無法構建堅不可摧的壁壘,但能贏得利於競爭的時間差。
商湯日日新 V6 在原生多模態大模型與多模態深度思考推理上已領先半步,無疑向大模型行業傳遞了一個信息:
穿越兩個技術周期的商湯,已經坐上了大模型的核心牌桌。
02
更全面的競爭
當商湯在大模型市場上的位置被重新審視,這家相比 BAT 不大、相比初創公司又不小的 AI 小巨頭就顯現了其獨特的競爭優勢。
技術上,AGI 是數據、算法與算力的並駕齊驅。數據層,商湯的日日新多模態大模型已經體現其融合文本、圖像、3D、視頻等多種模態數據的能力;算法與算力層,商湯的十年積累不遜於同時坐擁雲計算與基礎模型的互聯網大廠,但兩者雖有諸多相似,卻仍有本質的不同。
這種不同體現在「終局思維」的本質差異上:互聯網大廠研究基礎模型的最終落腳點往往是打造流量聚集的「Super App」;而商湯從成立第一天開始就是一家「人工智能」公司,其終局目標是參與構建人工智能時代,也因此商湯在大模型的商業落地上沒有 To B 與 To C 的糾結。無論是算法還是算力,商湯都願意成為行業的一個「擺渡人」。
當算法的差距被追平後,技術的星辰大海終歸回落塵埃大地,在大模型的商業化落地上,商湯過去十年在各行各業所積累的經驗天然降維打擊——創業公司還在商場學習走路的時候,商湯已經踩完一遍坑,越過山丘。
與 DeepSeek 不同,商湯對大模型的思考天然不僅是基礎模型的研究突破,還有模型的商業落地。在過去,商湯本身已觸達包括手機、汽車、營銷在內的廣泛業務,基於業務提煉出來的需求也指導了模型能力的優化。
以日日新 V6 為例,商湯追求原生的多模態大模型之餘,同時強調模型的三大能力:推理能力,情感共鳴與實時交互能力,以及長記憶/全局記憶能力。
根據商湯日日新 V6 已接入的場景顯示,在大模型的落地場景中,主流的交互方式不單單是文本,實時視頻通話的流量與十分巨大。與文本類似,視頻交互對長視頻的輸入窗口與模型的長記憶能力有高要求。V6 可以支持長達 10 分鐘的整段視頻輸入,將語音、文字與視頻形成統一的、與時間軸對齊的上下文表達,然後進行深入的理解、分析與推理。
在流式交互上,商湯從 GPT-4o 發布後就一直堅持打造多模態的交互入口。在商湯的設想中,通過終端與人類進行多模態交互的大模型必然是輕量化模型、而非 600B 的基礎模型;此外,與人的實時交互對模型情感共情、擬人表達的能力也提出高要求。而據數據統計,商湯是中國除字節外在擬人對話引擎上的第二大供應商。
基於全新日日新原生多模態大模型,商湯提出「一基兩翼」的落地方案:所謂「兩翼」,指的是應用在具身智能、硬件、眼鏡等方向的智能交互,及應用於金融、辦公等領域的生產力工具。
日日新 V6 基礎模型能力的提升,讓 AI 產品的想象空間也有了一個質的飛躍。例如,多模態綜合能力與多模態深度思考推理疊加高情商的擬人交互方式,在數學解題、點讀翻譯、文旅講解、繪本講解等等日常高頻需求的響應中都取得了相較於以往多模態模型更出色的性能表現。

同樣,在具身智能領域,商湯與傅利葉等機器人廠商合作,也探索了 V6 與終端結合的可能性。基於日日新 V6 多模態融合能力,機器人能同時掌握「大腦」、「耳朵」、「眼睛」與「嘴巴」等多個感官,並通過融合信息理解環境、進行深度思考。
而在小浣熊系列,V6 的多模態深度思考與推理能力使辦公小浣熊的任務規劃、數據分析、文檔編輯等能力有了更大幅的提升。小浣熊不僅支持excel、數據庫等結構化數據,還支持word、pdf、txt、圖片等非結構化數據解析,並且支持跨數據源融合解析,在 Tablebench 和 1000+ 數據分析場景評測精度超過 GPT-4o。

根據商湯 2024 年的財報,商湯生成式 AI 的業務收入達到 24 億元,在總收入中的佔比高達 63.7%,按年漲幅超過 100%。
當前大模型在許多場景中的落地還沒有越過產品性價比的生死線。而商湯作為一家沉浮商海多年的「OG」,無論是大裝置與大模型的協同,還是更注重 To B 而非 To C 的商業打法,都死死咬住生存的第一性原理。
以機器人為例。在多模態大模型的進步下,終端的智能只需一個模型就能達到多種能力、而非需要一個多模態模型再加一個語言大模型,性價比更高。
商湯有自己的 C 端應用,但從當前的大模型商業化來看,其重點主要集中在 B 端業務上。從構建人工智能時代的「終局思維」來看,推動更多行業、更多需求轉向「AI-Native」對商湯來說比加大投入追求 SuperApp 更有價值。
目前,商湯日日新已經支撐了包括 WPS、閱文、想法流在內的多個明星 C 端應用。這在一方面可以使技術與商業緊密綁定,同時驅動數據飛輪。
算力、算法、用戶與商業是一套完整的模型體系,任一環節的極速飛轉都會帶動其他幾環的飛躍。在大模型的浪潮中,商湯的啓動飛輪是大裝置與商業積累;日日新大模型系列發布後, 商湯多模態大模型的實力有了極大提升,尤其是 V6 的巨大突破讓算法飛輪也體現出了巨大的潛力。
超前一步是瘋子,超前半步是天才。從大裝置到日日新 V6,商湯都精準預判了每一個技術趨勢、並快速取得里程碑的成就。商湯大模型的下一個巨大飛輪能否由算法主導,絕對值得拭目以待。