「o3 達到或接近天才的水平。」
就在啱啱,OpenAI o3/o4 mini 模型終於正式推出。直播用時接近 30 分鐘,節奏快到飛起,信息量卻滿滿當當。
o3 的發布歷程本身也極具反轉,今年 2 月,OpenAI 曾宣佈擱置 o3 的獨立發布計劃,技術會打包塞進 GPT-5 裏。到了 4 月初,深諳「飢餓營銷」 的 Altman 卻宣稱計劃有變:
o3 要先上,GPT-5 反而得等等,最快也得幾個月後。

劃重點,OpenAI o3/o4 mini 亮點如下:
o 系列迄今最智能的模型,推理能力大幅提升,思考時間越長,效果越好。
首次將圖像直接融入思維鏈,用圖片「思考」,能直接調用工具處理圖片。
首次全面支持網頁搜索、文件分析、Python 代碼執行、視覺輸入深度推理和圖像生成等功能。
成本效率上優於前代,o3 在相同延遲和成本下性能更強。
在模型選擇器上取代 o1 等模型,ChatGPT Plus、Pro 和 Team 用戶即日起可使用 o3、o4-mini 和 o4-mini-high,企業與教育用戶一周後獲訪問權限。o3-pro 預計數周內發布。
免費用戶可通過「Think」模式使用 o4-mini,速率限制不變。
開發者則通過 Chat Completions API 和 Responses API 訪問,支持推理摘要和函數調用優化,即將支持網頁搜索等內置工具。
OpenAI 最強推理模型 o3 發布,GPT-5 還會遠嗎?
最新發布的 o3 和 o4-mini,是 o 系列迄今最智能的模型。
這兩款模型在推理能力、工具使用和多模態處理上表現出色,能夠更長時間思考複雜問題,首次全面支持網頁搜索、文件分析、Python 代碼執行、視覺輸入深度推理和圖像生成。
上至高級研究人員,下至普通用戶,新模型適用的場景也更廣泛。
OpenAI o3 和 o4-mini 可以調用 ChatGPT 中的工具,並通過 API 中的函數調用訪問自定義工具。
OpenAI Releases o3 and o4-mini, Says o3 Can ‘Generate Novel Hypotheses’ | Beebom
通過強化學習,OpenAI 還訓練了這兩個模型如何使用工具 ——不僅知道如何用、何時用,還能以正確格式快速生成可靠答案,通常耗時不到一分鐘。
比如,當被問及加州夏季的能源使用量與去年相比如何時,能上網查詢公共能源消耗數據,寫 Python 代碼預測,生成圖表或圖片,並解釋預測依據,流暢串聯多種工具。
整個推理搜索過程也勝在靈活多變:模型可多次調用搜索引擎,交叉驗證結果;若自有知識不足,還能進一步挖掘信息、整合跨類型輸出。

在今天凌晨的直播環節,OpenAI 總裁 Greg Brockman 也罕見露面。OpenAI 演示者則展示了新模型如何結合用戶興趣,發現用戶可能感興趣但尚未知道的內容。
新模型啓用「記憶」功能後,能夠了解演示者的興趣愛好——跳傘和音樂。
不是簡單分別討論兩個愛好,新模型找到了一個將兩者聯繫起來的研究領域:科學家錄製健康珊瑚礁的聲音,然後用水下揚聲器回放這些錄音,這種聲音回放加速了新珊瑚和魚類的定居,能夠幫助珊瑚礁更快地癒合和再生。
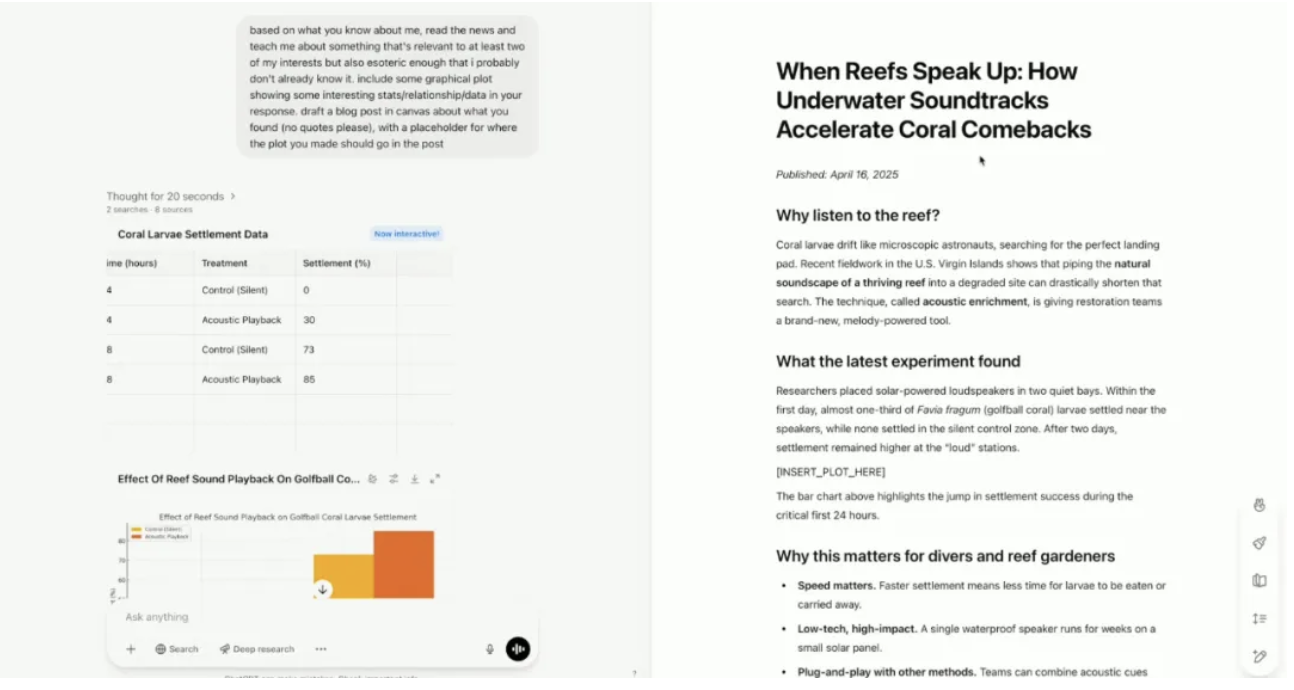
內容創建過程中,模型還自動創建了一篇完整的博客文章,先是使用數據分析工具生成可視化,用 Canvas 創建博客文章,並附上提供了引用和來源。
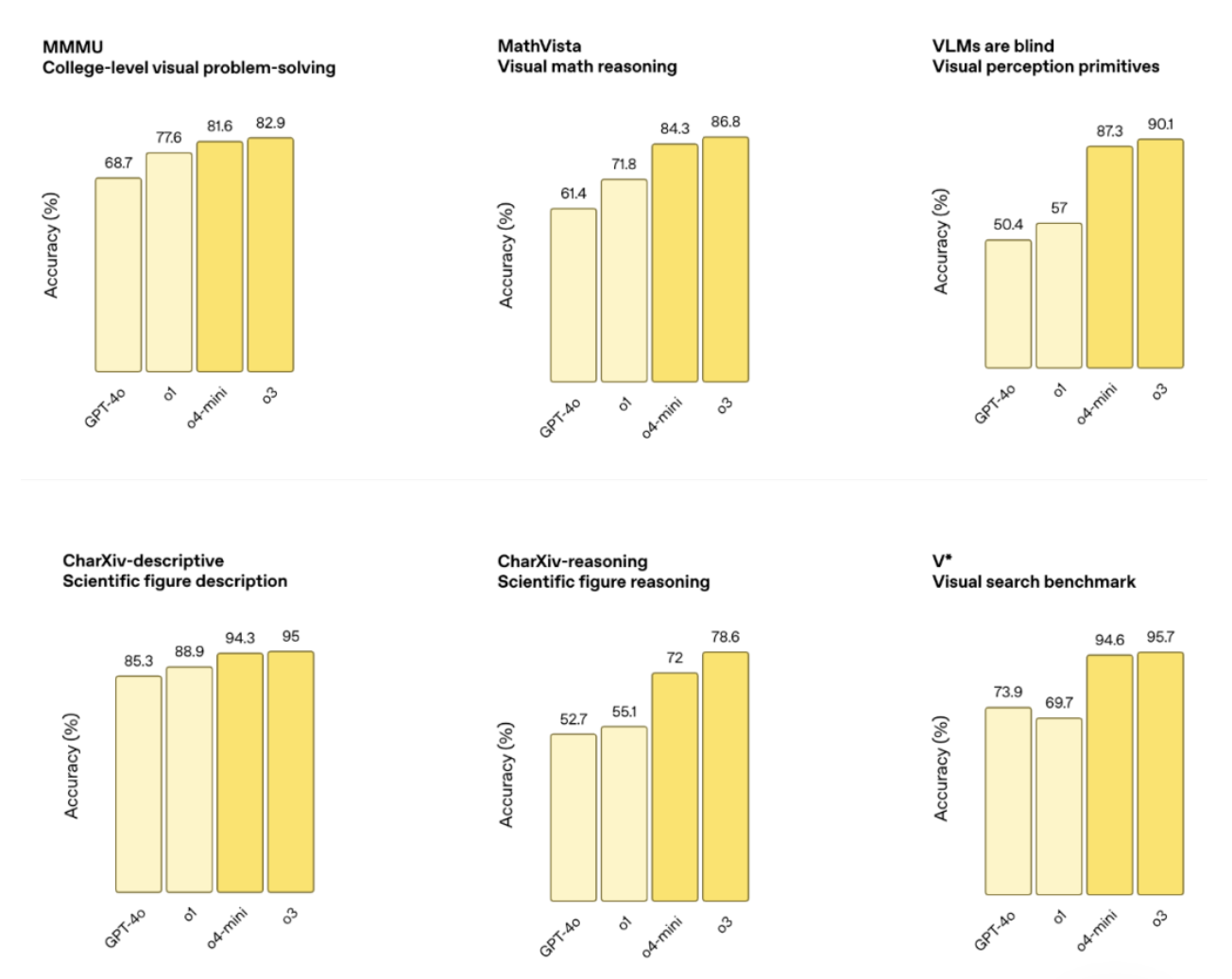
作為最新的旗艦推理模型,o3 在編程、數學、科學和視覺感知領域創下新紀錄,例如 Codeforces、SWE-bench 和 MMMU 基準測試,視覺任務準確率達 87.5%,MathVista 也有 75.4%。
外部專家評估顯示,o3 在編程、商業諮詢和創意構思的重大錯誤率也比 o1 低 20%,在生物學、數學和工程領域能生成並批判性評估新穎假設,適合複雜查詢。
o4-mini 「體型更小」,優化了快速、低成本推理,在 AIME 2024 和 2025 數學測試中準確率分別為 92.7% 和 93.4%,在非 STEM 和數據科學任務中優於 o3-mini,效率高,能處理更多請求,也更適合需要快速響應的場景。
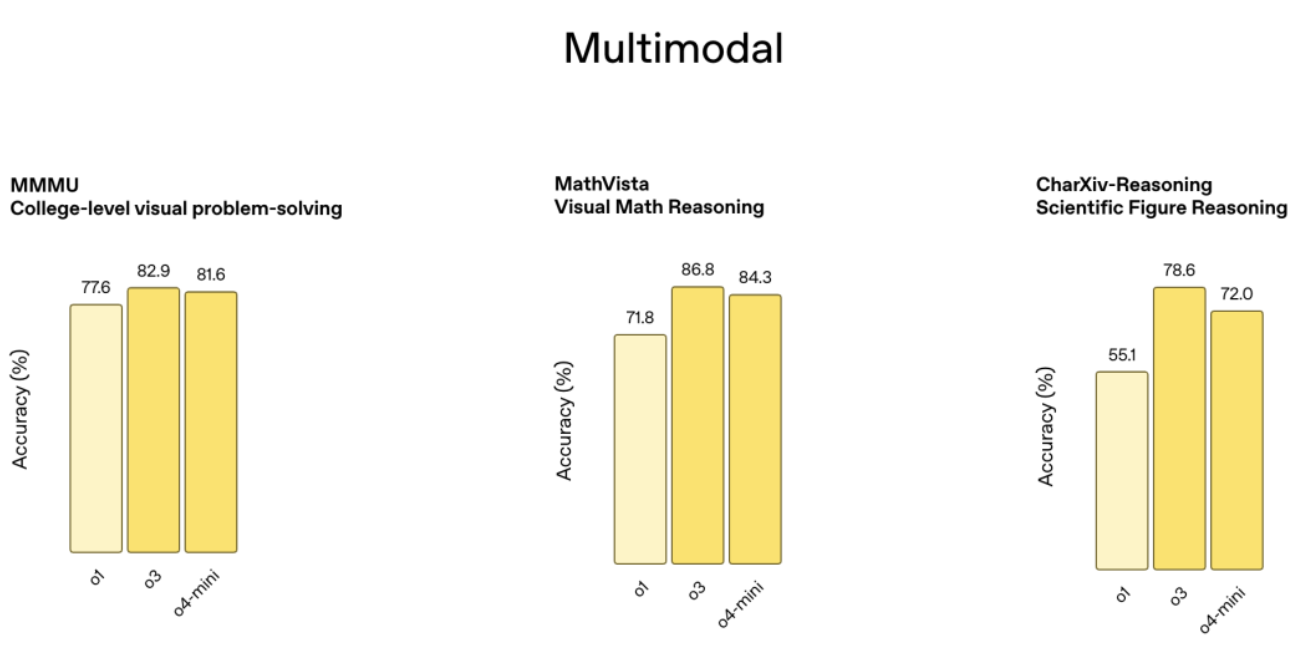
性能對比顯示,o3 和 o4-mini 在 AIME、Codeforces、GPQA 和 MMMU 等測試中全面超越前代,且指令遵循和響應質量也都顯著提升,結合記憶功能和歷史對話引用,回答更個性化、更相關。
在 OpenAI o3 的整個開發過程中,OpenAI 觀察到大規模強化學習呈現出與 GPT 系列預訓練中相同的 「計算量越大,性能越好 」的趨勢。
沿着這一路徑(強化學習),OpenAI 在訓練計算量和推理時間方面都提升了一個數量級,但仍然看到了明顯的性能提升,在跟 o1 相同的延遲和成本下,o3 的表現更強,而且給它更多時間思考,效果還能更好。
不忘畫餅的 OpenAI 也表示,o3 和 o4-mini 已經展現了 o 系列推理能力與 GPT 系列自然對話和工具使用的融合趨勢,而未來模型(GPT-5)預計將進一步整合這些優勢,為用戶提供更智能、實用的體驗。
能用圖片「思考」,就是偶爾會「想太多」
OpenAI o3 和 o4-mini 還是 o 系列最新的視覺推理模型。
怎麼理解視覺推理模型呢?據官方介紹,模型首次將圖像直接融入思維鏈,開啓了一種融合視覺與文本推理的全新問題解決方式。
配合 Python 數據分析、網絡搜索和圖像生成等工具,還能應對更復雜的任務。
上傳白板照片、教科書圖表或手繪草圖,即便圖像糊了、反轉或質量不佳,模型也能準確解讀,並直接調用工具處理圖片,裁剪、旋轉、縮放等操作都不在話下。
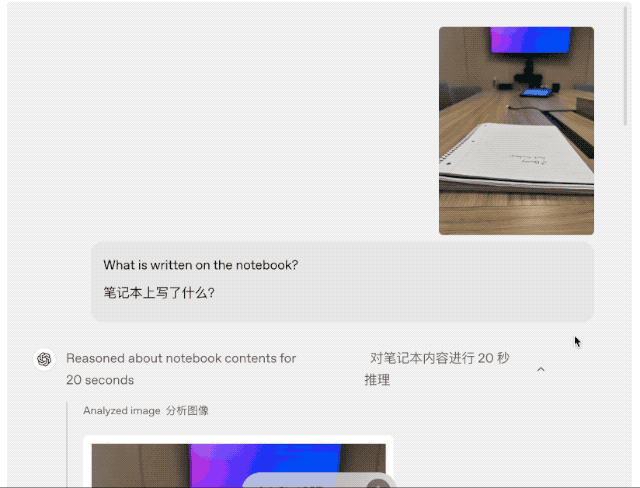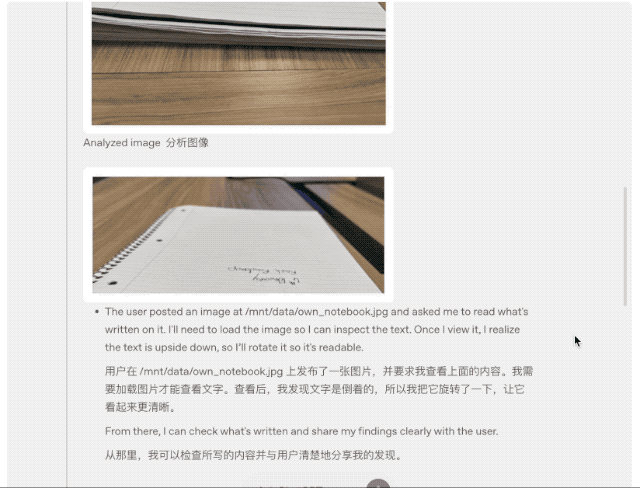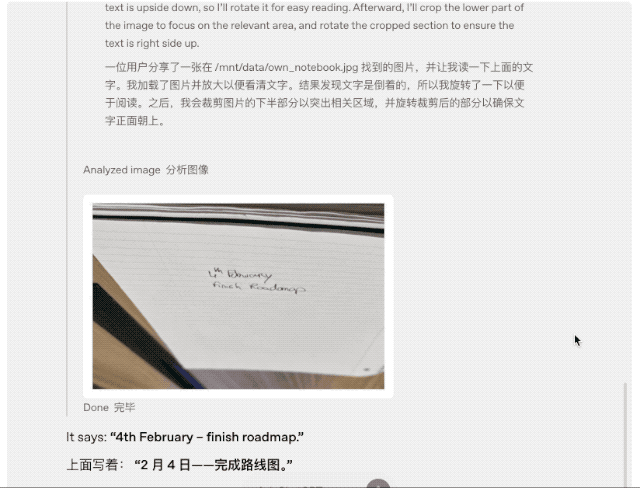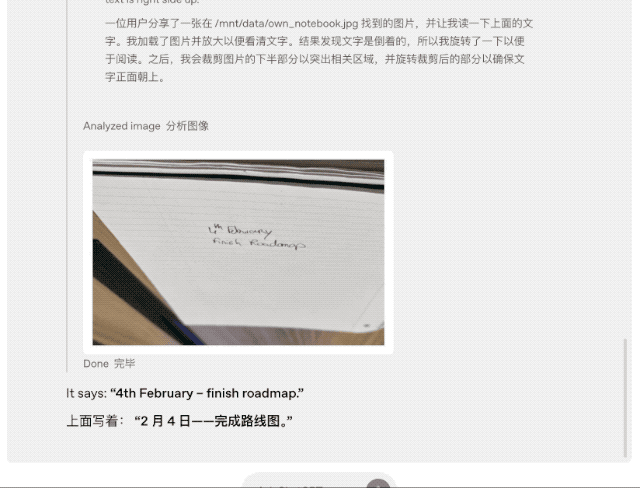
重點是,這些功能是原生的,無需依賴單獨的專用模型。
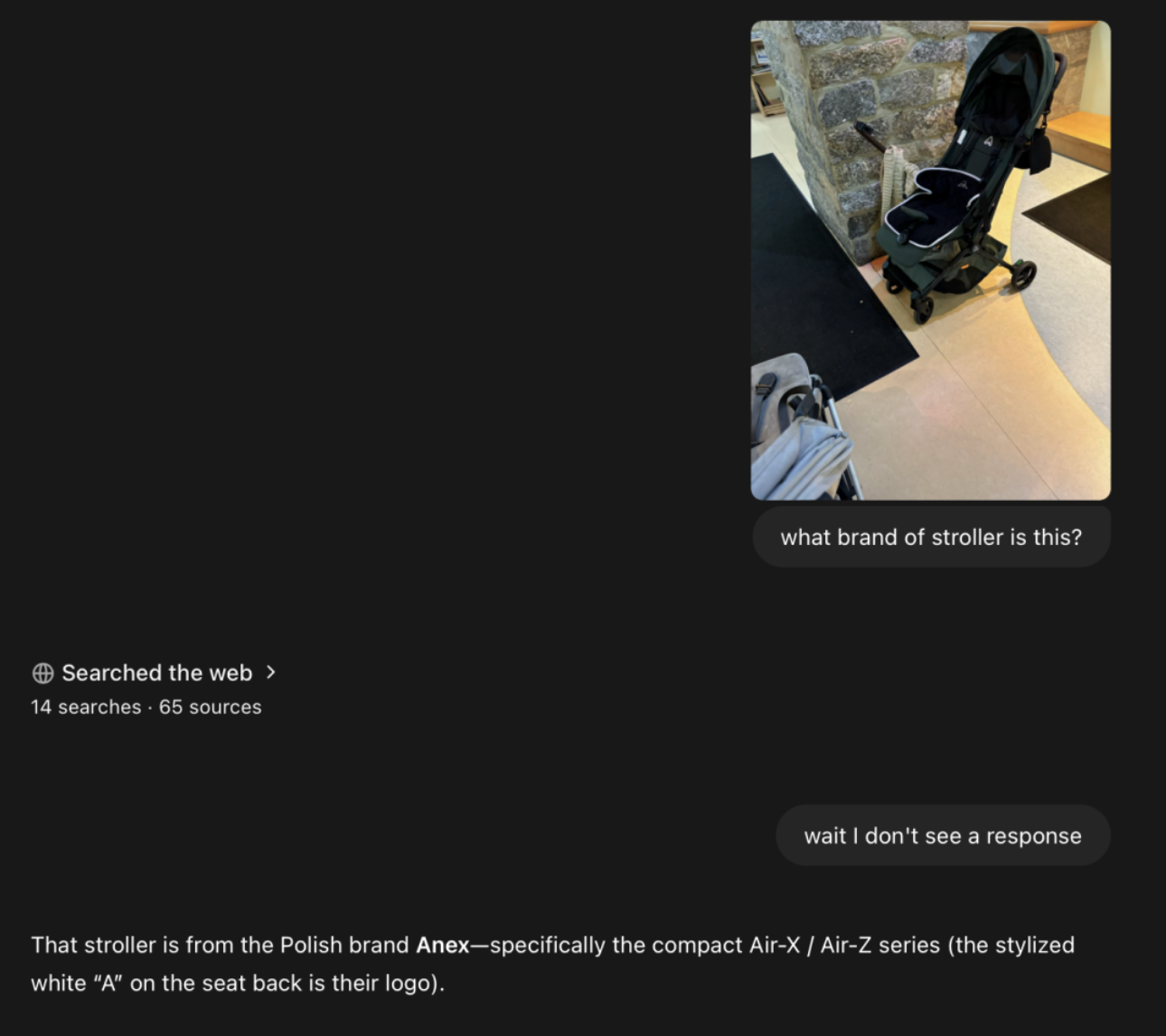
博主 @danshipper 通過一張模糊的照片找到了一個嬰兒車品牌,從畫面上看,整個過程也搜索了數十個網頁。

我也上傳了武康大樓的圖片,o3 準確識別到了建築位於淮海路附近,不過,回答卻並沒有給出建築的名字。
當然,這種思考方式也不是沒有「缺陷」:
想得太多:模型可能過於依賴工具或圖像處理,導致推理思維鏈冗長。
看走眼:即使工具使用正確,視覺誤解也可能導致答案錯誤。
不穩定:同一問題多次嘗試,模型可能採用不同推理路徑,部分結果出錯。
Codex CLI 免費開源,OpenAI 真 open 了?
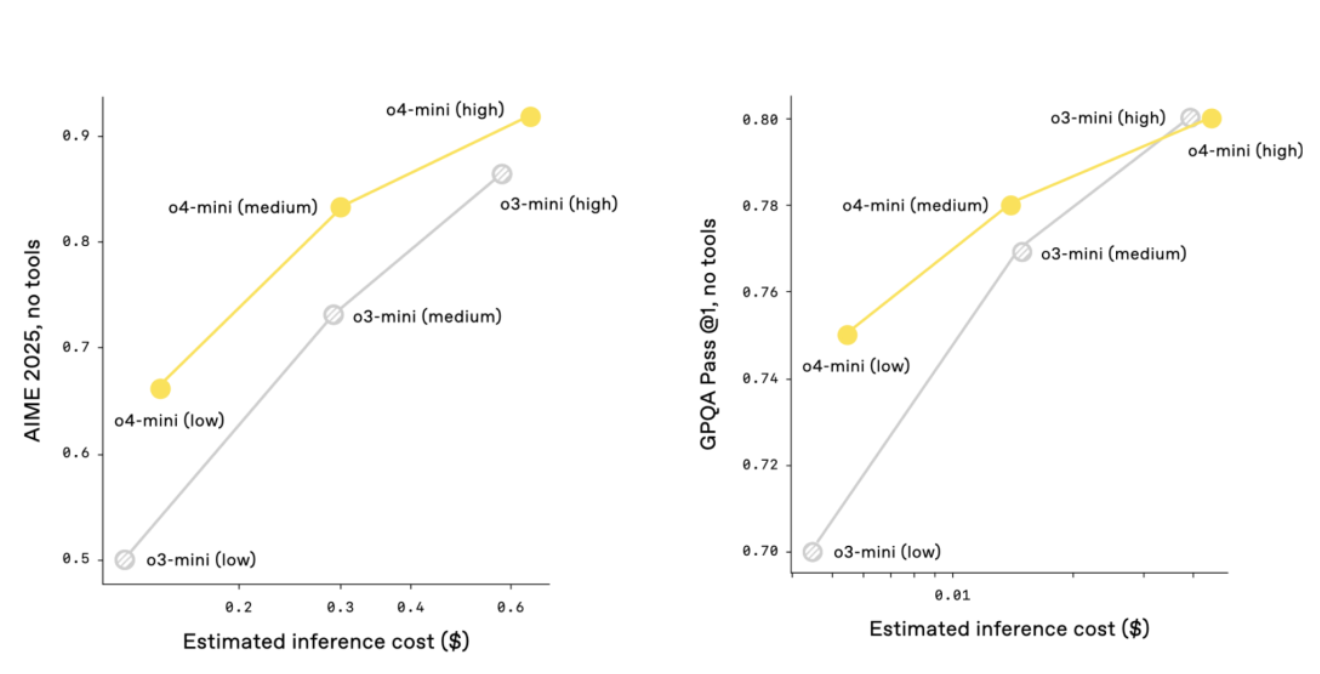
o3 和 o4-mini 在成本效率上優於前代,2025 年 AIME 測試中性價比完勝 o1 和 o3-mini,更智能也更划算。
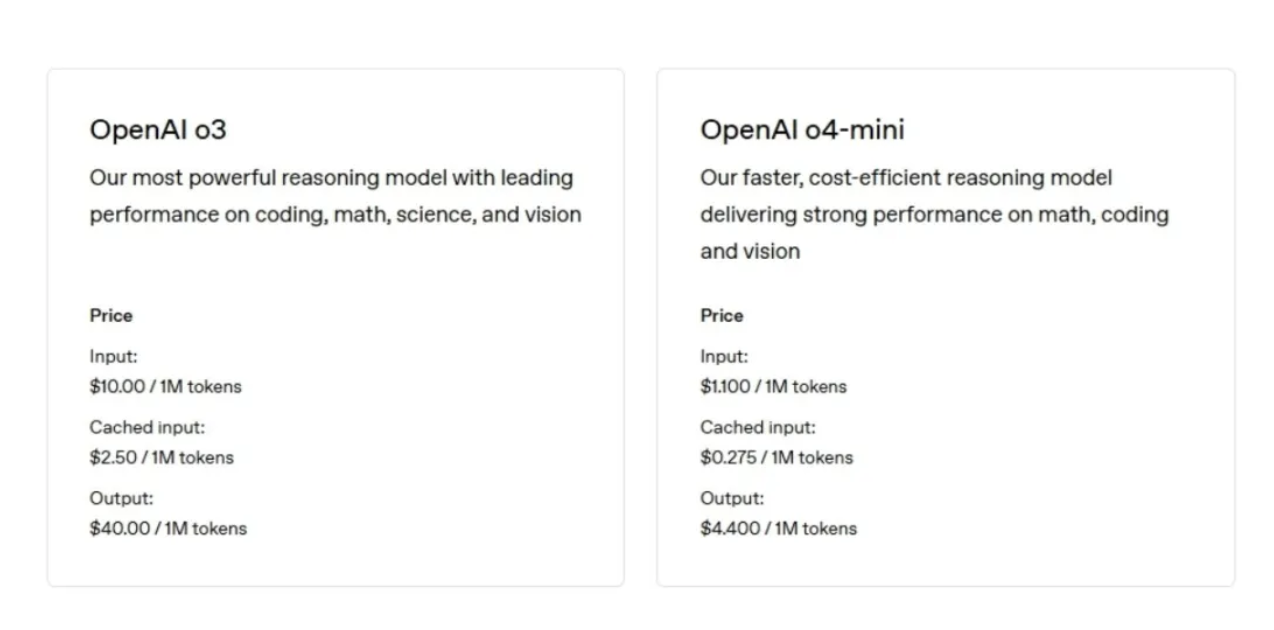
o3 輸入每百萬 tokens(大約 75 萬個詞,長度超過《指環王》系列)的費用為 10 美元,輸出每百萬 tokens 的費用為 40 美元。
o4-mini 輸入每百萬 tokens 的費用為 1.10 美元,輸出每百萬 tokens 的費用為 4.40 美元。
前不久,OpenAI 被曝安全測試時間從數月縮水到了幾天。而 o3 和 o4-mini 的系統卡則顯示,OpenAI 重建了安全訓練數據集,新增生物威脅、惡意軟件生成和越獄攻擊的拒絕提示。
根據最新的《準備框架》,o3 和 o4-mini 在生物與化學、網絡安全及 AI 自我改進領域風險均低於「高」閾值。
▲圖片附 Codex CLI GitHub 地址:https://github.com/openai/codex
Agent 雖遲但到,OpenAI 還推出了一款輕量級終端編碼 Agent——Codex CLI。
基於 o3 和 o4-mini 的推理能力,Codex CLI 支持多模態輸入,已在 GitHub 開源。此外 ,OpenAI 還啓動 100 萬美元計劃支持相關項目,接受 2.5 萬美元 API 積分資助申請。
OpenAI 這回是真 open 了。
據介紹,Codex 有兩種運行模式,一種是「建議模式」(默認):提出命令供用戶確認,另一種是「全自動模式」:禁用網絡訪問,讓 Agent 自主工作但保持安全。
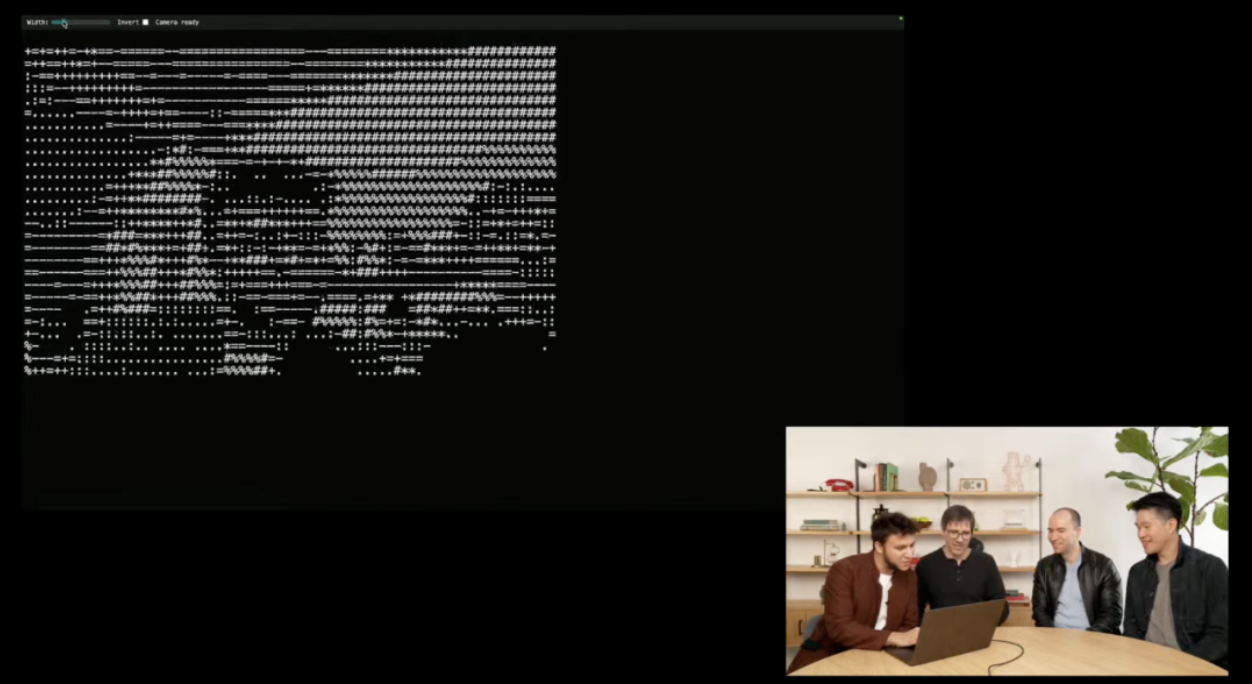
直播演示中,OpenAI 研究員將螢幕截圖拖入終端,Codex CLI 通過多模態推理分析圖像,訪問用戶文件,最終生成 HTML 文件,打造了一個 ASCII 藝術生成器,併成功添加了網絡攝像頭 API。
值得一提的是,據彭博社報道,OpenAI 擬以約 30 億美元收購 AI 編程工具公司 Windsurf,如果收購成功,這將成為 OpenAI 迄今為止規模最大的收購案。
報道指出,一旦交易達成,OpenAI 將能夠與 Anthropic、微軟旗下的 Github 和 Anysphere 等公司展開更直接的競爭,從而在快速增長的 AI 編程工具市場中佔據一席之地。
「天才級」o3 引 Altman 轉發力挺,但這些題卻答不對…
一些 X 平台博主提前拿到了新模型的體驗資格,並分享了使用體驗。
體驗一周的 @danshipper 表示,o3 速度快、很有「行動力」、極其聰明,而且整體感覺非常棒。最喜歡的用法包括:
制定了一個簡潔的機器學習小課程,並每天早上提醒博主學習
通過一張模糊的照片找到了一個嬰兒車品牌
用超快的速度寫出了一個全新的 AI 基準測試程序
像 X 光一樣分析了 Annie Dillard 的一篇經典作品,挖掘出博主以前從未注意到的寫作技巧
查看會議記錄,敏銳捕捉博主試圖迴避衝突的情況
分析組織架構後,建議推出什麼樣的產品,以及短板在哪

醫學博士 @DeryaTR_ 認為 o3 很聰明,「當我向 o3 提出具有挑戰性的臨牀或醫學問題時,它的回答聽起來就像是來自頂級醫生:準確、全面、基於證據且充滿信心,表現得非常專業,完全符合我們對這個領域專家的期望。」
Altman 也轉發引用了他的說法「o3 達到或接近天才的水平」。
在 @DeryaTR_ 看來,o4 mini 則稍微「低調」一些,回答細節上沒有 o3 那麼詳細,可能更簡潔、流暢,給人一種優雅的感覺,甚至可能更具「情感」。
當然,我們也上手測試了一些問題。
從前有一位老鐘錶匠,為一個教堂裝一隻大鐘。他年老眼花,把長短針裝配錯了,短針走的速度反而是長針的12倍。裝配的時候是上午 6 點,他把短針指在「6」上,長針指在「12」上。老鐘錶匠裝好就回家去了。人們看這鐘一會兒 7 點,過了不一會兒就8點了,都很奇怪,立刻去找老鐘錶匠。等老鐘錶匠趕到,已經是下午 7 點多鐘。他掏出懷錶來一對,鍾準確無誤,疑心人們有意捉弄他,一生氣就回去了。這鐘還是 8 點、9 點地跑,人們再去找鐘錶匠。老鐘錶匠第二天早晨 8 點多趕來用表一對,仍舊準確無誤。請你想一想,老鐘錶匠第一次對錶的時候是 7 點幾分?第二次對錶又是 8 點幾分?

▲o3 回答錯誤
U2 合唱團在 17 分鐘 內得趕到演唱會場,途中必需跨過一座橋,四個人從橋的同一端出發,你得幫助他們到達另一端,天色很暗,而他們只有一隻手電筒。一次同時最多可以有兩人一起 過橋,而過橋的時候必須持有手電筒,所以就得有人把手電筒帶來帶去,來回橋兩端。手電筒是不能用丟的方式來傳遞的。四個人的步行速度各不同,若兩人同行則 以較慢者的速度為準。Bono 需花 1 分鐘過橋,Edge 需花 2 分鐘過橋,Adam 需花5分鐘過橋,Larry 需花 10 分鐘過橋。他們要如何在 17 分鐘內過橋呢?

▲o4 mini 回答正確
如下實測,雖然 o3 給出了完整的推理步驟,但回答卻也再次出錯。

▲o3 回答錯誤
在 OpenAI 上新之際,細心的網友也發現新款 Gemini 將於下周(4 月 22 日)發布。
DeepSeek R2、Anthropic 的 Claude 4 以及馬斯克劇透的「GroK-3.5」 也預計將在本月陸續發布。
即便往前看,4 月也是 AI 最為「內卷」的一個月,很大程度上決定未來一年 AI 行業的發展走向,而更強的模型、更低的成本、更廣的場景也將給我們帶來更智能、更普惠的未來。
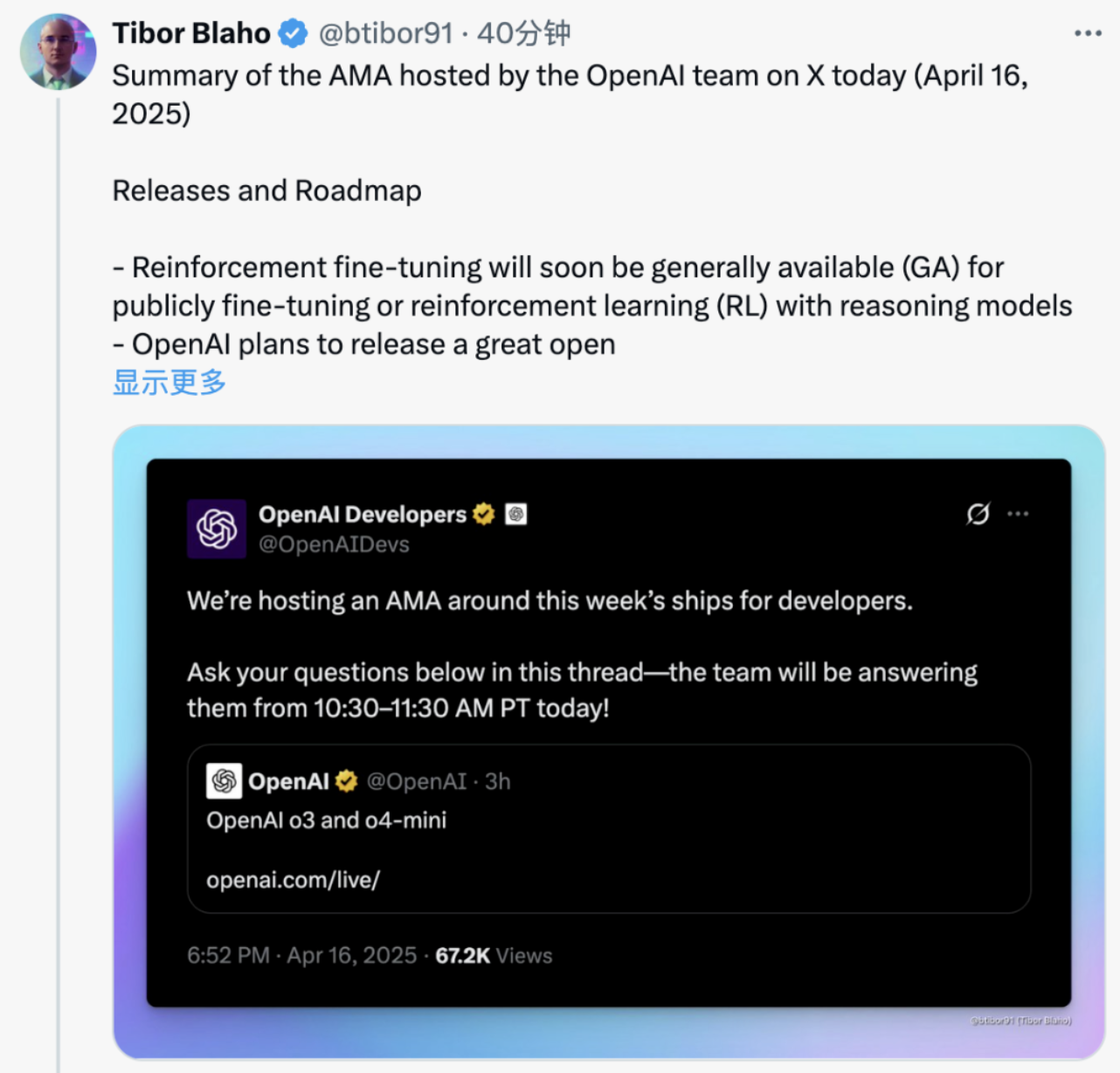
附 OpenAI 團隊在 X 平台上舉辦的 AMA 總結:
OpenAI 計劃在未來幾個月發布一個出色的開放模型,新的圖像生成功能將很快在 API 中推出。
o3 現已在 API 中提供,而更先進的 o3-pro 模型正在開發中,預計很快發布。
強化學習微調(Reinforcement fine-tuning)很快會全面開放,允許公開進行微調或使用推理模型進行強化學習(RL)。
在 Responses API 中,開發者消息與系統消息之間的切換是自動處理的;將系統消息發送給 o3 或將開發者消息發送給 GPT-4.1 會自動轉換。
目前,ChatCompletions 或 Responses API 不支持託管工具
在 o3 和 o4-mini 的推理階段,Web 搜索、文件搜索和代碼解釋器等工具會被積極使用;這些工具目前在ChatGPT中已被支持,但尚未在 API 中支持——預計很快會添加支持。
OpenAI 正在積極開發 Agents SDK 中的線程支持,以改善對話歷史和記憶。
OpenAI認為低代碼平台在 Agents SDK 中的建議很有趣,並歡迎開發者就最有用的功能提供反饋。
Codex CLI 包括多個文檔化的審批模式,允許用戶為每個操作或會話選擇模式。
Codex CLI 並不是用來替代 Cursor、Windsurf 等 IDE 工具;它的設計目的是在用戶使用主要 IDE 時運行後台任務。
比較 Codex 的編碼能力和深度研究能力取決於選擇的模型(o3 或 o4-mini);Codex 特別利用函數調用,直接在用戶計算機上執行命令。
新模型主要訓練於通用瀏覽、Python/代碼執行工具和對開發者有用的用戶定義工具。
雖然 GPT-4.5 更強大,但它更慢且計算密集,GPT-4.1 為開發者提供了一個更快且更具成本效益的選擇。
GPT-4.1 的一些改進已經整合到 ChatGPT 中,更多改進將在未來推出。
OpenAI 承認「4o」和「o4」等模型名稱之間存在命名混淆,並計劃很快簡化模型命名。