來源 機器之心
深夜,OpenAI 發布了 o 系列模型的最新成果 o3 和 o4-mini。該系列模型經過訓練,會在響應之前進行更長時間的思考。
OpenAI 表示,這是他們迄今為止發布的最智能模型,也標誌着 ChatGPT 能力的巨大飛躍。
這次新發布的推理模型能夠像智能體一樣使用並組合 ChatGPT 中的每一個工具 —— 這包括搜索互聯網、用 Python 分析上傳的文件和其他數據、深入推理視覺輸入,甚至生成圖像。

至關重要的是,這些模型經過訓練,能夠推理何時以及如何使用工具,以在正確輸出格式下產生詳細且深思熟慮的答案,通常在不到一分鐘的時間內解決更復雜的問題。這使得它們能夠更有效地應對多面性問題,邁向一個更具自主性的 ChatGPT,獨立為你執行任務。
OpenAI CEO 山姆・奧特曼表示,o3 和 o4-mini 功能非常強大,尤其擅長多模態理解,並且可以組合使用 ChatGPT 中的所有工具。另外,o4-mini 的價格非常划算。
從今天開始,ChatGPT Plus、Pro 和 Team 用戶可以在模型選擇器中看到 o3、o4-mini 和 o4-mini-high,取代 o1、o3‑mini 和 o3‑mini‑high。ChatGPT Enterprise 和 Edu 用戶將在一周內獲得訪問權限。
免費用戶可以在提交查詢之前,在編輯器中選擇‘Think’來試用 o4-mini。所有計劃的速率限制與之前的模型組保持不變。
此外,OpenAI 預計將在幾周內發布 o3‑pro,並提供全面的工具支持。目前,Pro 用戶仍然可以訪問 o1‑pro。
開發者現在也可以通過‘Chat Completions API’和‘Responses API’使用 o3 和 o4-mini(部分開發者需要驗證其組織才能訪問這些模型)。 Responses API 支持推理摘要,能夠在函數調用周圍保留推理 token 以提高性能,並且即將在模型推理中支持內置工具,例如網頁搜索、文件搜索和代碼解釋器。
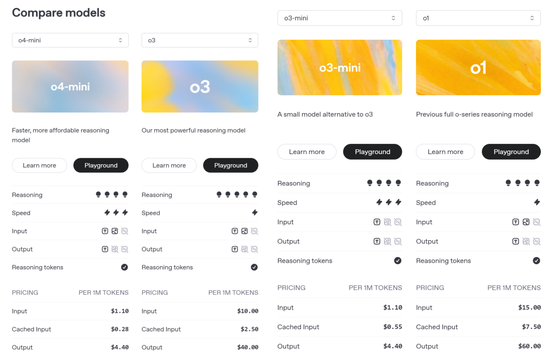
至於 API 價格,o3 比 o1 全方位(輸入、cached 輸入和輸出)降低,o4-mini 也比 o3-mini 部分降低。
新模型強在哪裏?
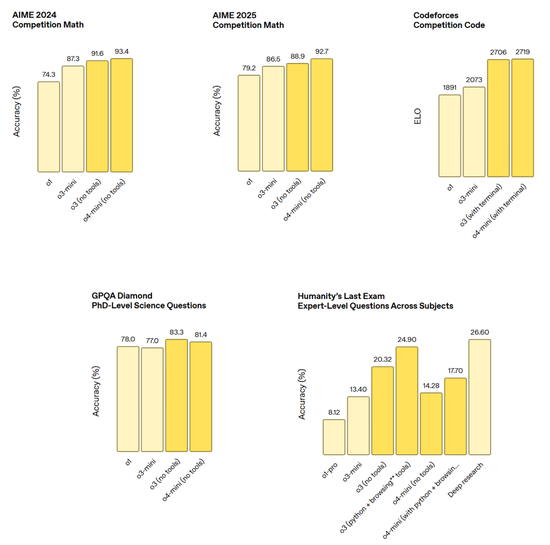
o3 是 OpenAI 最強大的推理模型,它推動了編程、數學、科學、視覺感知等領域的前沿發展。o3 在 Codeforces、SWE-bench(無需構建自定義模型專用框架)和 MMMU 等基準測試中創下了新的 SOTA(最佳性能)。
o3 非常適合需要多方面分析且答案可能並非顯而易見的複雜查詢,並在分析圖像、圖表和圖形等視覺任務中表現尤為出色。在外部專家的評估中,o3 在困難的現實任務中比 o1 犯的重大錯誤少 20%,尤其是在編程、商業 / 諮詢和創意構思等領域表現出色。
早期測試人員強調了 o3 作為思想夥伴的分析嚴謹性,並強調了其生成和批判性評估新假設的能力,尤其是在生物學、數學和工程學領域。
OpenAI o4-mini 是一款小型模型,專為快速、經濟高效的推理而優化,它以其尺寸和成本實現了卓越的性能,尤其是在數學、編程和視覺任務方面。
o4-mini 是 AIME 2024 和 2025 基準測試中表現最佳的模型。在專家評估中,它在非 STEM 任務以及數據科學等領域的表現也優於其前身 o3-mini。得益於其高效性,o4-mini 支持的使用限制遠高於 o3,使其成為解決需要推理能力的問題的強大高容量、高吞吐量解決方案。
外部專家評估人員認為,得益於智能化的提升和網絡資源的引入,o3 和 o4-mini 都比前代模型展現出了更佳的指令遵循能力,以及更實用、更可驗證的響應。
與 OpenAI 之前的推理模型相比,這兩個模型的體驗也更加自然、更具對話性,尤其是在參考記憶和歷史對話的情況下,響應更加個性化和相關。
多模態基準測試(包括 MMMU 大學水平的視覺問答、MathVista 視覺數學推理和 CharXiv-Reasoning 論文圖表推理):

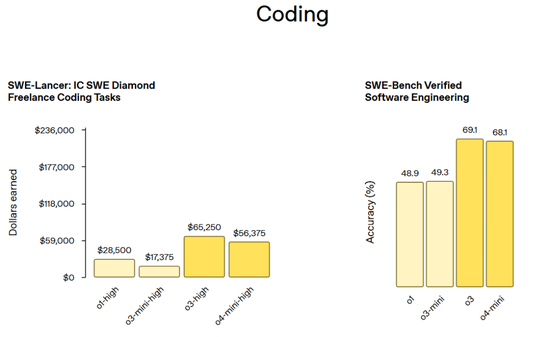
編程基準測試(包括 SWE-Lancer: IC SWE Diamod Freelancer 編程任務和 SWE-Bench Verified 軟件工程任務):
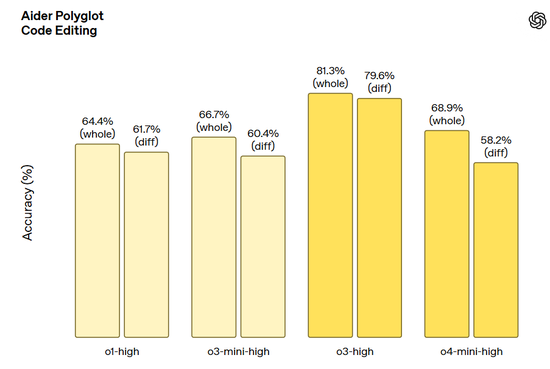
Aider Polyglot 代碼編輯任務:
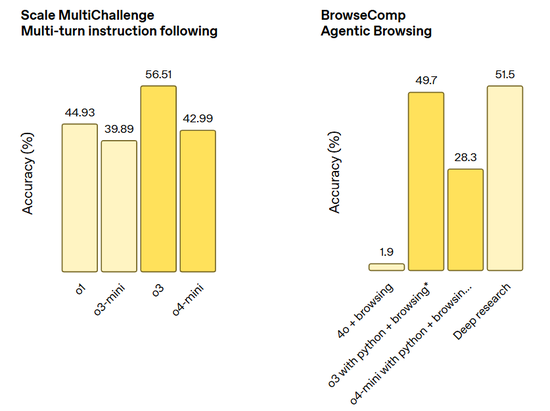
指令遵循和智能體工具使用任務(包括 Scale MultiChallenge 多輪指令遵循和 BrowerComp 智能體瀏覽):
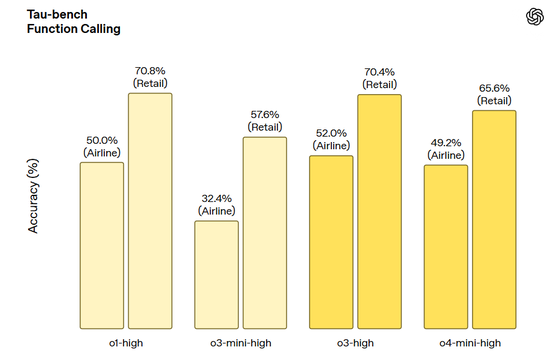
Tau-bench 函數調用:
繼續擴展強化學習,模型掌握工具使用
在 OpenAI o3 開發過程中,OpenAI 觀察到大規模強化學習表現出與 GPT 系列預訓練中觀察到的趨勢相同,即‘計算量越大,性能越好(more compute = better performance)’。
通過重新追溯這一擴展路徑,這次是在強化學習中 ——OpenAI 在訓練計算和推理時間推理能力方面又向前推進了一個數量級,但仍能清晰地看到性能的提升,這驗證了模型的性能會隨着其被允許思考的時間越長而持續提高。在與 OpenAI o1 相同的延遲和成本下,o3 在 ChatGPT 中的性能更高 ——OpenAI 已經驗證,如果讓模型思考更長時間,其性能還會繼續攀升。
OpenAI 還通過強化學習訓練這兩個模型掌握工具使用的能力 —— 不僅教會它們如何使用工具,更讓它們學會判斷何時該使用工具。這種根據目標結果自主調配工具的能力,使它們在開放式場景中表現尤為出色 —— 特別是在涉及視覺推理和多步驟工作流的任務中。正如早期測試者反饋所示,這種提升既體現在學術基準測試中,也反映在實際任務表現上。
根據圖像進行思考
首次,模型能夠在思維鏈中運用圖像進行思考,而不僅僅是看到圖像。這開啓了一類新的問題解決方式,視覺和文本推理終於結合在一起了。無論是上傳的白板照片、教科書圖表或手繪草圖,即使圖像模糊、反轉或質量低下,模型也能對其進行解讀。
與之前的 OpenAI o1 模型類似,o3 和 o4-mini 經過訓練,可以在回答前進行更長時間的思考,並在回覆用戶之前運用較長的內部思維鏈。o3 和 o4-mini 進一步擴展了這一能力,將圖像融入其思維鏈中,通過使用工具轉換用戶上傳的圖像,使其能夠進行裁剪、放大和旋轉等簡單的圖像處理技術。更重要的是,這些功能是原生的,無需依賴單獨的專用模型。
這種方法為測試時間計算擴展提供了一個新的軸,可以無縫融合視覺和文本推理,這反映在它們在多模態基準測試中的最先進的性能上,標誌着朝着多模態推理邁出了重要一步。
用戶可以通過拍照提問,無需擔心物體的位置 —— 無論是文字顛倒,還是一張照片中存在多個物理問題。即使物體乍一看並不明顯,視覺推理也能讓模型放大查看,從而更清晰地觀察。
舉例來說:問筆記本上寫了什麼,其實這個筆記本上的字體根本看不清,並且字體是顛倒的,這些問題都被 OpenAI o3 在推理過程中一一解決了。

用戶輸入圖片
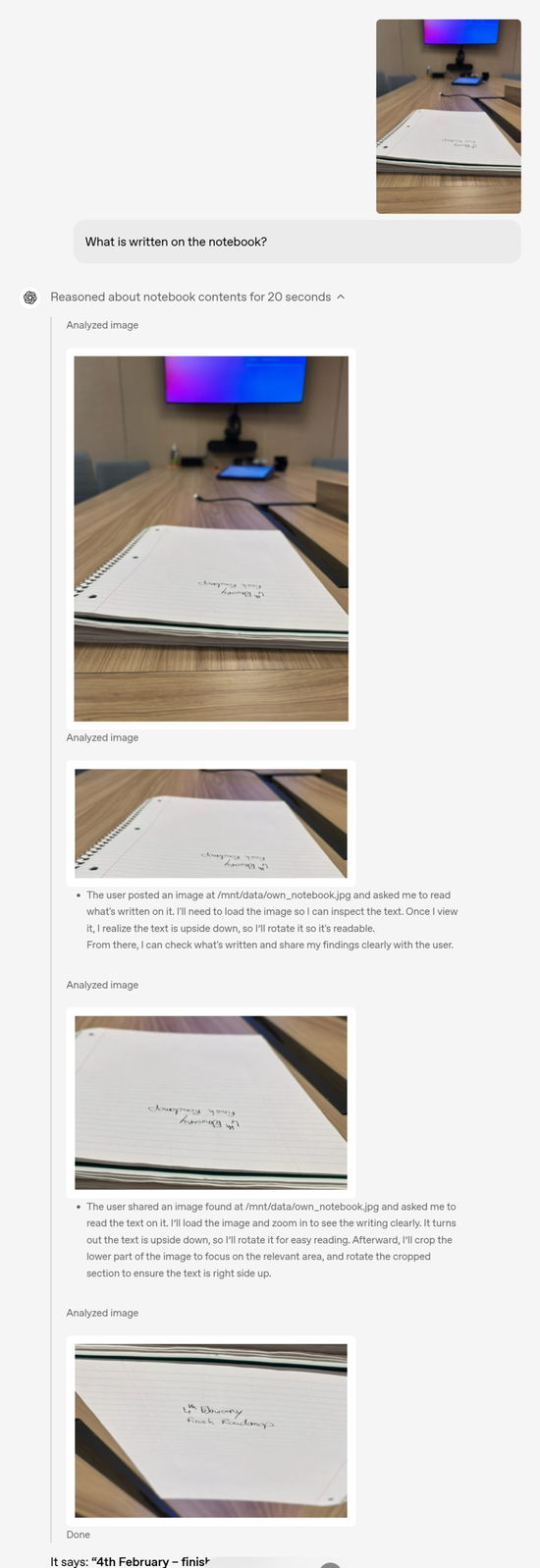
下面的示例是 OpenAI o3 做題過程,我們能看到其清晰的思維鏈過程。
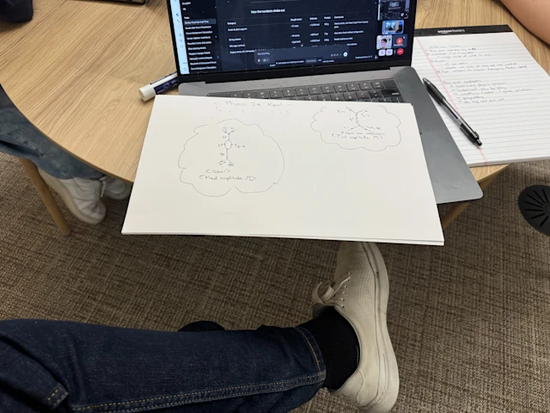
用戶輸入圖片

走迷宮示例:

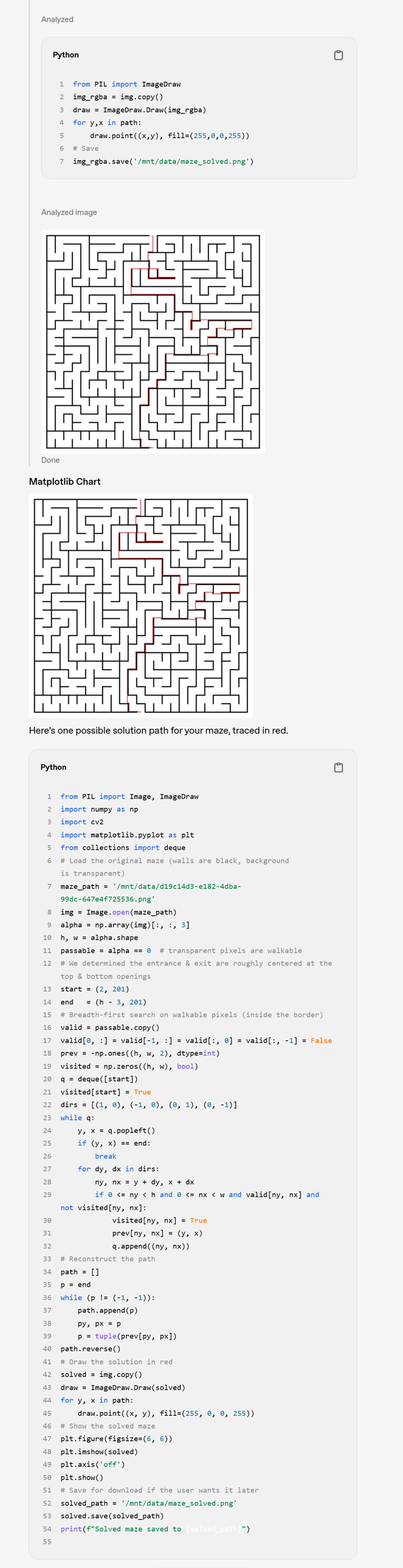
中間省略了較長的思維鏈過程
智能體工具使用
o3 和 o4-mini 可以完全訪問 ChatGPT 中的工具,以及通過 API 中的函數調用訪問用戶自己的自定義工具。這些模型經過訓練,能夠推理如何解決問題,選擇何時以及如何使用工具,從而快速(通常在一分鐘內)以正確的輸出格式生成詳細而周到的答案。
例如,用戶可能會問:‘加州夏季的能源使用量與去年相比如何?’ 該模型可以在網上搜索公共事業數據,編寫 Python 代碼構建預測,生成圖表或圖像,並解釋預測背後的關鍵因素,並將多個工具調用串聯在一起。
推理功能使模型能夠根據遇到的信息做出反應和調整。例如,它們可以藉助搜索引擎多次搜索網頁,查看結果,並在需要更多信息時嘗試新的搜索。
這種靈活的策略方法使模型能夠處理需要訪問最新信息的任務,而不僅僅是模型的內置知識、擴展推理、綜合和跨模態輸出生成。
比如在視覺推理任務中,o3 準確地考慮了時間表並輸出了可用的計劃,而 o1 則存在不準確之處,導致某些演出時間出現錯誤。

再比如在科學問答任務中,o3 提供了全面、準確且富有洞察力的分析,分析了最近的電池技術突破如何延長電動汽車續航里程、加快充電速度並推動採用,所有這些都有科學研究和行業數據作為支持。o1 雖然可信且切題,但不夠詳細和具有前瞻性,存在一些小錯誤或過於簡單化。

推進高效(cost-efficient)推理
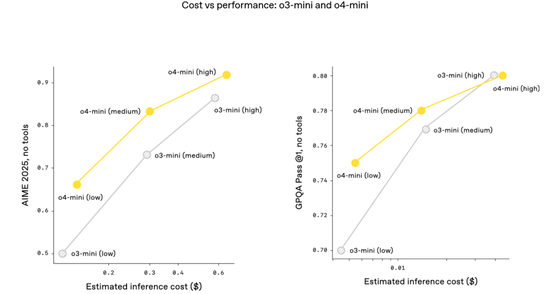
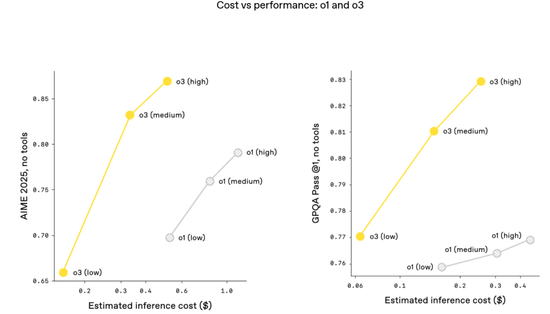
o3 和 o4-mini 是 OpenAI 迄今為止發布的最智能模型,而且它們通常也比其前輩 o1 和 o3-mini 更高效。
例如,在 2025 年 AIME 數學競賽中,o3 的性價比邊界比 o1 有顯著提升;同樣,o4-mini 的性價比邊界也比 o3-mini 有顯著提升。
更普遍地講,OpenAI 預計,在大多數實際應用中,o3 和 o4-mini 也將分別比 o1 和 o3-mini 更智能、更經濟。
安全
模型能力的每一次提升都意味着安全性的相應提升。對於 o3 和 o4-mini,OpenAI 徹底重建了安全訓練數據,在生物威脅(生物風險)、惡意軟件生成和越獄等領域添加了新的拒絕提示。
這些更新的數據使 o3 和 o4-mini 在 OpenAI 的內部拒絕基準測試(例如指令層次結構、越獄)中取得了優異的表現。
除了模型拒絕方面的出色表現外,OpenAI 還開發了系統級緩解措施,以標記前沿風險領域的危險提示。與之前在圖像生成方面的工作類似,OpenAI 訓練了一個推理 LLM 監控器,它基於人工編寫且可解釋的安全規範。當應用於生物風險時,該監控器成功標記了 OpenAI 人工紅隊演練活動中約 99% 的對話。
OpenAI 還採用迄今為止最嚴格的安全程序對這兩種模型進行了壓力測試。根據 OpenAI 更新的應急準備框架,他們根據該框架涵蓋的三個跟蹤能力領域(生物和化學、網絡安全以及人工智能自我改進)對 o3 和 o4-mini 進行了評估。
根據評估結果,OpenAI 確定 o3 和 o4-mini 在所有三個類別中均低於該框架的‘高’閾值。
關於更多 o3 和 o4-mini 的信息,大家可以參考 OpenAI 完整的模型系統卡。

地址:https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
開源 Codex CLI:終端前沿推理
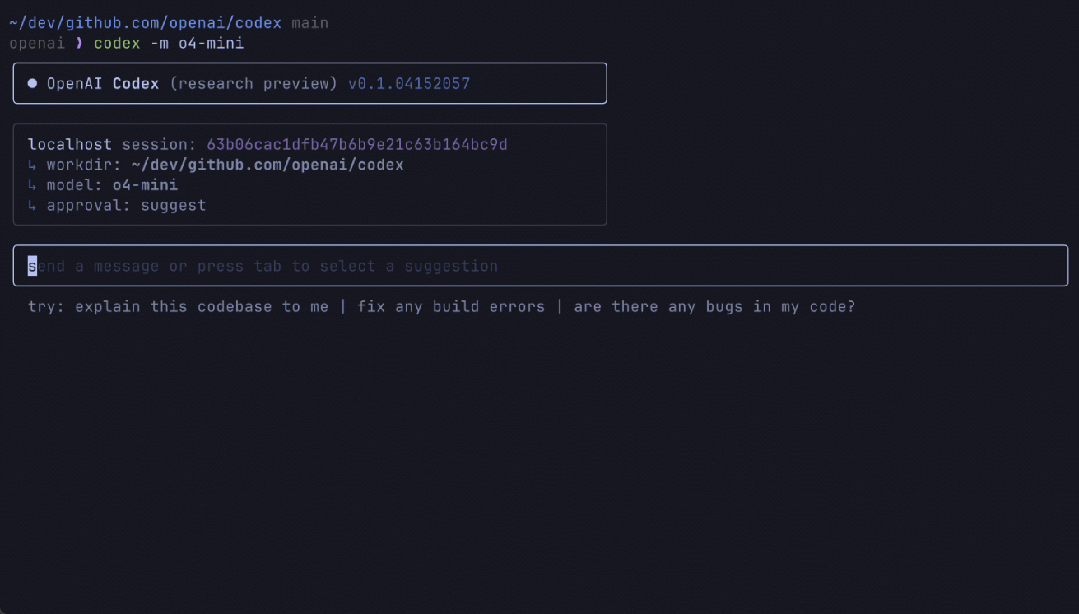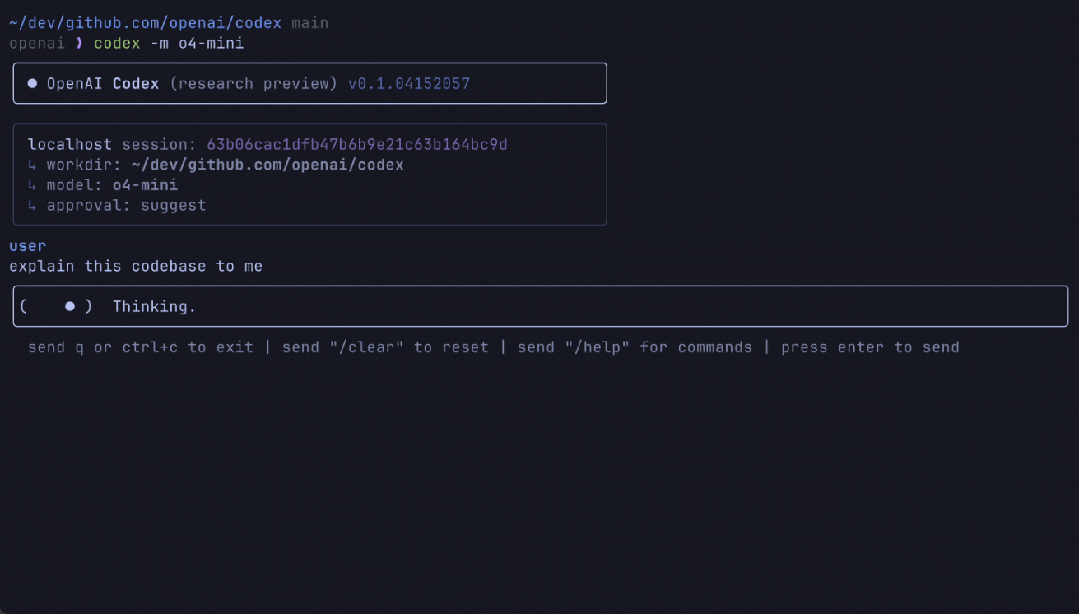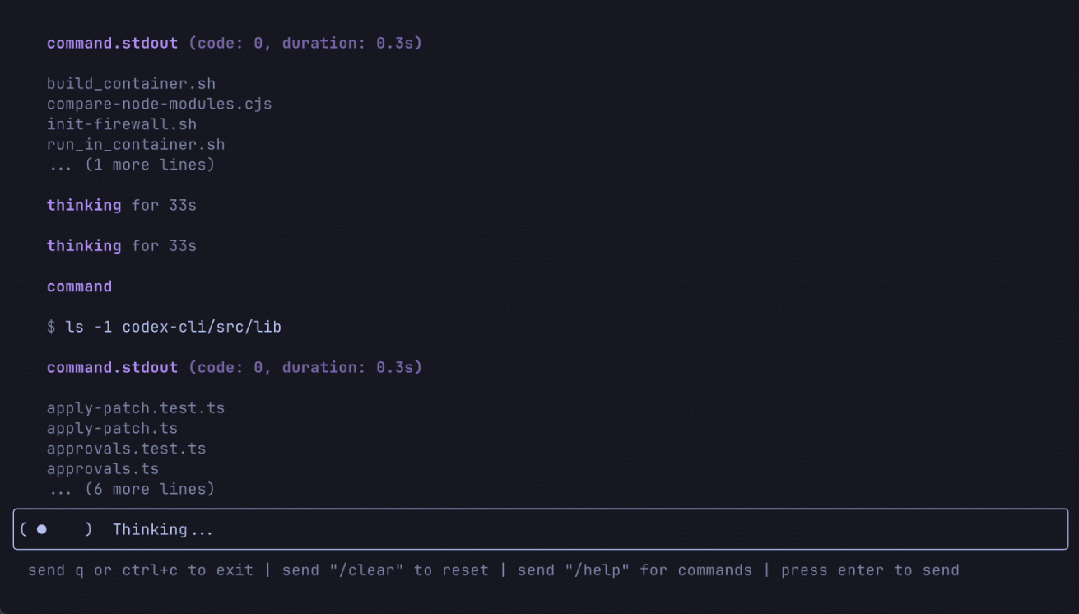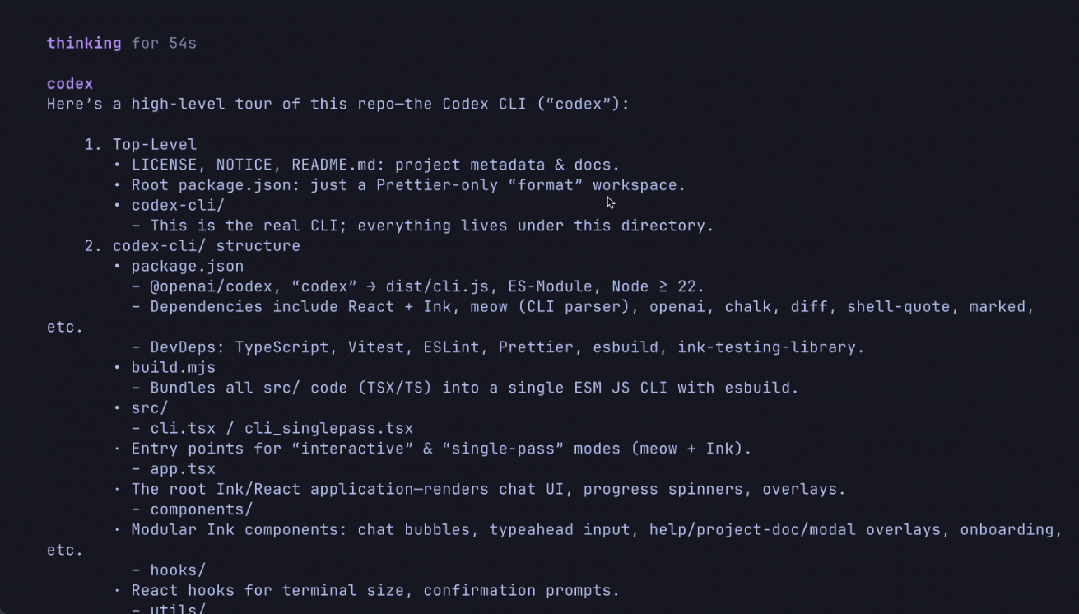
OpenAI 還分享了一項新實驗:Codex CLI,這是一款可在終端運行的輕量級編程智能體。它可以直接在個人計算機上運行,最大限度地提升 o3 和 o4-mini 等模型的推理能力,並即將支持 GPT-4.1 等更多 API 模型。
用戶可以通過將螢幕截圖或低保真草圖傳遞給模型,並在本地訪問代碼,從而從命令行獲得多模態推理的優勢。OpenAI 將 Codex CLI 視為一個將自身模型連接到用戶及其計算機的極簡界面。Codex CLI 現已完全開源。
開源地址:https://github.com/openai/codex
效果如下:
此外,OpenAI 還將啓動一項 100 萬美元的計劃,以支持使用 Codex CLI 和 OpenAI 模型的項目。OpenAI 將以 API 積分的形式評估和接受每 2.5 萬美元的資助申請。
責任編輯:江鈺涵