
自 2019 年起,讓 AI 模型變得更強大的方法層出不窮。一種是使用更多訓練數據,擴大模型規模;另一種則是針對什麼是優質答案給出更精準的反饋。而在去年年底,谷歌和其他人工智能公司開始採用第三種方法——推理。
近日,谷歌發布首個混合推理模型 Gemini 2.5 Flash,該版本以 Gemini 2.0 Flash 為基礎,在推理能力方面進行了重大升級,同時兼顧了速度和成本。
該模型引入了谷歌所謂的「思考預算」機制,允許開發人員指定在生成響應之前應分配多少計算能力用於推理複雜問題。有效解決了當今人工智能市場的一個根本矛盾:更復雜的推理通常以更高的延遲和更高的價格為代價。
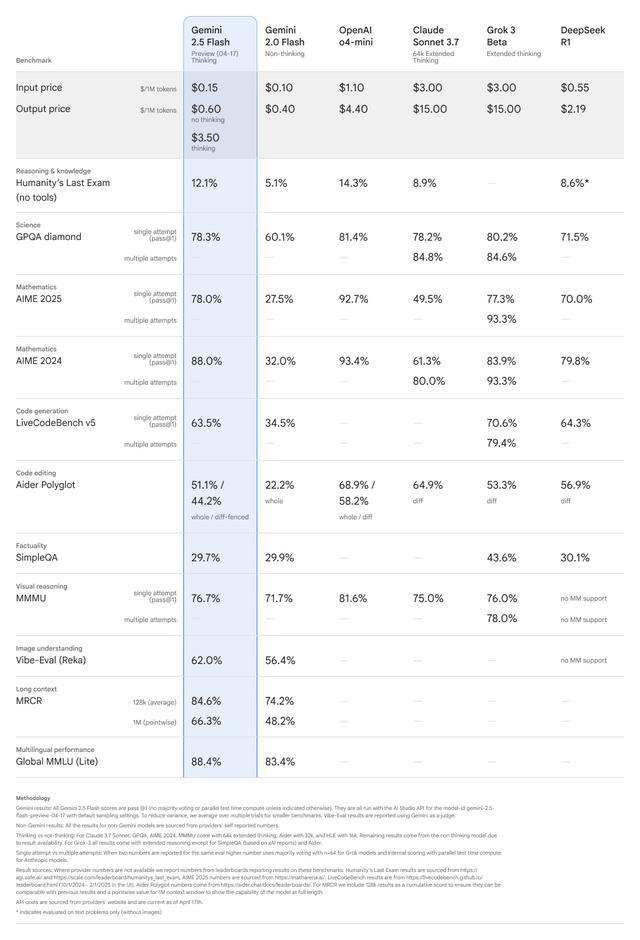
使用 Gemini 2.5 Flash 時,開發者每百萬 token 的輸入成本為 0.15 美元。輸出成本則根據推理設定而存在顯著差異:關閉思考功能時每百萬 token 為 0.60 美元,而啓用推理功能時則每百萬 token 為 3.50 美元。
推理輸出的近六倍價格差異反映了「思考」過程的計算強度,其中模型在生成響應之前會評估多種潛在路徑和考慮因素。思考預算可以從 0 調整到 24,576 個 token,作為最大限制而非固定分配。據谷歌稱,該模型會根據任務的複雜性智能地確定使用多少思考預算,從而在不需要複雜推理時節省資源。
谷歌聲稱,Gemini 2.5 Flash 在關鍵基準測試中展現出極具競爭力的性能,同時保持了比其他同類產品更小的模型規模。在「人類最後一次考試」(一項旨在評估推理和知識的嚴格測試)中,2.5 Flash 的得分為 12.1%,優於 Anthropic 的 Claude 3.7 Sonnet(8.9%)和DeepSeek R1(8.6%),但略低於 OpenAI 近期推出的 o4-mini(14.3%)。該模型在知識問答(GPQA)和數學(AIME 2025/2024)等技術基準上也取得了優異的成績。
DeepMind 首席研究科學家 Jack Rae 表示:「我們一直在推動模型思考。」這類模型旨在通過邏輯推理解決問題,為得出答案會花費更多時間。隨着 DeepSeek R1 模型在今年早些時候推出,推理模型受到了廣泛關注。它們對人工智能公司頗具吸引力,因為通過訓練現有模型以務實方式解決問題,能提升現有模型性能,公司也就無需從頭構建新模型。
當 AI 模型在查詢上投入更多時間和精力時,運行成本也會更高。推理模型排行榜顯示,完成一項任務的成本可能高達 200 美元。人們期望這些額外投入的時間和資金,能幫助推理模型更好地應對諸如代碼分析、從大量文檔中收集信息等具有挑戰性的任務。
Google DeepMind 首席技術官 Koray Kavukcuoglu 認為:「對某些假設和想法思考得越深入,模型就越有可能找到正確答案。」但事實並非總是如此。Gemini 產品團隊負責人 Tulsee Doshi 指出,模型確實存在過度思考的問題,他特別提到了 Gemini Flash 2.5。此次發布的模型中包含一個滑塊,開發人員可通過它調節模型的思考程度。
模型在一個問題上耗時過長,不僅會增加開發人員的運行成本,還會加重人工智能的環境負擔。Hugging Face 的工程師 Nathan Habib 對推理模型的廣泛應用進行了研究,他表示過度思考的現象十分普遍。他指出,在急於展示更智能的人工智能的熱潮中,企業們不管什麼情況都想用推理模型,就像手裏拿着錘子,看什麼都像釘子。實際上,OpenAI 在 2 月份宣佈推出新模型時表示,這將是該公司最後一個非推理模型。
Habib 稱,對於某些任務,推理模型的性能提升「有目共睹」,但對許多其他人工智能的普通用戶而言並非如此。即便將推理應用於合適的問題,也可能出現狀況。他提到一個例子,一個領先的推理模型在處理有機化學問題時,一開始表現尚可,但推理過程中卻突然 「崩潰」:不斷重複 「等等,但是……」。最終,它在這項任務上花費的時間遠超非推理模型。在 DeepMind 負責評估雙子座模型的 Kate Olszewska 也表示,谷歌的模型同樣可能陷入循環。
谷歌推出的新「推理」滑塊就是為了解決這一問題。目前,該功能並非面向 Gemini 的消費者版本,而是供開發應用程序的開發人員使用。開發人員可以為模型處理某個問題時設定計算能力預算,如果某項任務無需太多推理,就可以調低 「思考程度」。開啓推理功能後,模型的輸出成本大約會提高 6 倍。
設定這種靈活性的另一個原因是,目前還難以確定何時需要更多推理才能得到更好的答案。Jack Rae 表示:「很難界定什麼樣的任務最適合深度思考。」像編碼(開發人員可能會將數百行代碼粘貼到模型中尋求幫助)、生成專業研究報告這類任務,很明顯需要深度思考,開發人員可能會調高「思考程度」,並認為為此付出的成本是值得的。不過,還需要進行更多測試並收集開發人員的反饋,才能確定在哪些情況下中低 「思考程度」的設定就足夠了。
Habib 表示,對推理模型的鉅額投資表明,提升模型性能的傳統模式正在發生改變。他說:「規模定律正在被取代。」如今,企業們更傾向於認為,讓模型思考更長時間,比單純擴大模型規模能帶來更好的效果。多年來,人工智能公司在推理(即模型實際生成答案時)上的投入明顯高於模型訓練,並且隨着推理模型的興起,這一支出還會加速增長。同時,推理過程產生的碳排放也越來越多。
即便推理模型持續佔據主導地位,谷歌也並非一枝獨秀。去年 12 月和今年 1 月,DeepSeek 發布的成果引發股市市值下跌,因為它宣稱能以較低成本打造強大的推理模型。該模型被稱為「開放權重」模型,也就是說,其內部設定(即權重)是公開的,開發人員無需付費使用谷歌或 OpenAI 的專有模型,就能自行運行。
那麼,既然像 DeepSeek 這樣的開放模型表現如此出色,為什麼還有人選擇使用谷歌的專有模型呢?Kavukcuoglu 表示,在編碼、數學和金融領域,人們對模型的準確性和精確性要求極高,期望模型能理解複雜情況。他認為,無論是否開源,只要能滿足這些要求的模型就能脫穎而出。在 DeepMind 看來,這種推理將成為未來人工智能模型的基礎,這些模型將代表你行動,為你解決問題。
他還提到:「推理是構建智能的關鍵能力。模型開始推理的那一刻,就具備了一定的自主性。」
原文鏈接:
https://www.technologyreview.com/2025/04/17/1115375/a-google-gemini-model-now-has-a-dial-to-adjust-how-much-it-reasons/