熱點欄目
客戶端
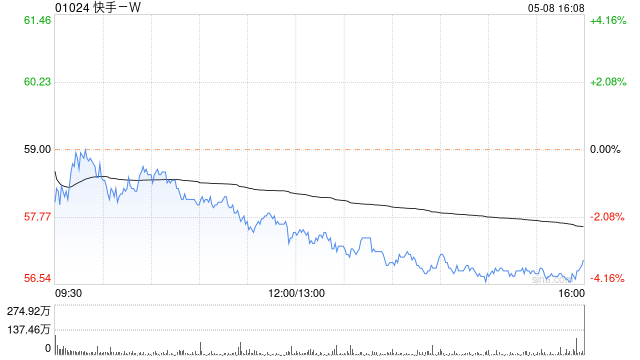
快手-W(01024)早盤上漲3.47%,現報52.20港元,成交額7.68億港元。
4月23日,快手Kwaipilot團隊發布全新大模型訓練方法SRPO並宣佈開源。該方法僅用 GRPO 1/10的訓練成本,在數學與代碼雙領域基準測試中實現性能突破:AIME2024 得分50,LiveCodeBench 得分41.6,成為業界首個在兩大專業領域同時復現DeepSeek-R1-Zero 的方法。
快手 Kwaipilot 團隊在最新研究成果《SRPO: A Cross-Domain Implementation of Large-Scale Reinforcement Learning on LLM》中提出了一種創新的強化學習框架 —— 兩階段歷史重採樣策略優化(two-Staged history-Resampling Policy Optimization ,SRPO),這是業界首個同時在數學和代碼兩個領域復現 DeepSeek-R1-Zero 性能的方法。
通過使用與 DeepSeek 相同的基礎模型(Qwen2.5-32B)和純粹的強化學習訓練,SRPO成功在AIME24和LiveCodeBench基準測試中取得了優異成績(AIME24 = 50、LiveCodeBench = 41.6),超越了DeepSeek-R1-Zero-32B 的表現。更值得注意的是,SRPO 僅需 R1-Zero 十分之一的訓練步數就達到了這一水平。
海量資訊、精準解讀,盡在新浪財經APP
責任編輯:盧昱君