编辑:编辑部 JhY
【新智元导读】斯坦福大学最新AI进展!开源STORM&Co-STORM系统,只需填写主题,就可以全面整合资源,避开信息盲点生成高质量长文。
AI写作神器,竟被斯坦福开源了!
在OpenAI与Perplexity绞尽脑汁去动谷歌搜索的蛋糕时,斯坦福研究团队却“于无声处响惊雷”,一鸣惊人推出了支持避开信息盲点、全面整合可靠信息、从头写出维基长文的STORM&Co-STORM系统。
背后模型是由必应搜索,以及GPT-4o mini加持。
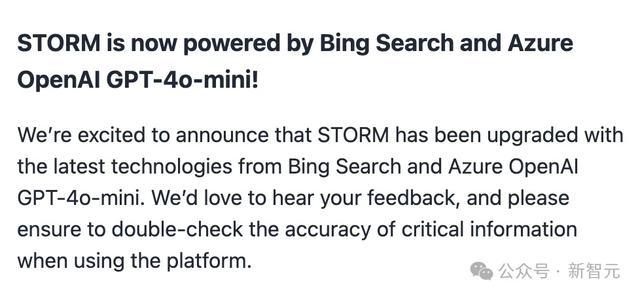
简单来讲,STORM&Co-STORM系统分为两部分。
STORM通过让“LLM专家”与“LLM主持人”进行多角度问答,以此从提纲,到段落与文章的迭代式生成。
Co-STORM则是能够通过让多智能体之间互相对话并生成可交互的动态思维导图,以避免遗漏掉用户没注意到的信息需求。
该系统只需输入英文主题词,就能生成有效整合了多源信息的高质量长文(如维基百科文章)。

体验链接:https://storm.genie.stanford.edu/
进入主页,可以自选模式STORM和Co-STORM。
给定主题后,STORM便可以在3分钟内就形成如下演示中的一篇“形神兼备”的结构化高质量长文。

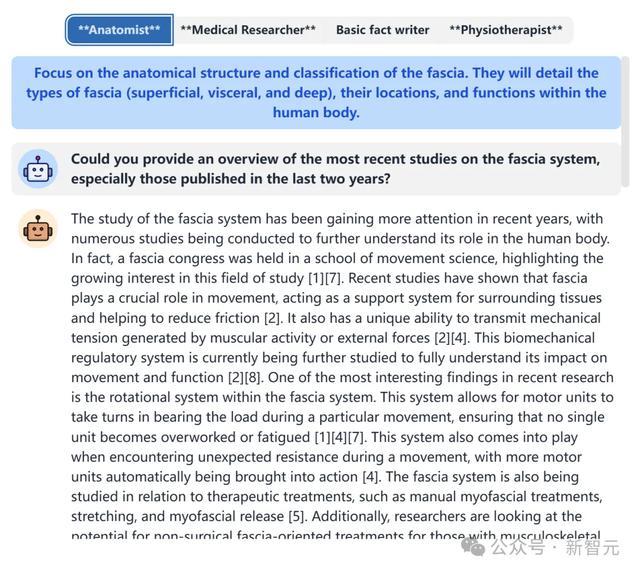
我们也可以在给出的文章上面点击“See BrainSTORMing Process”来获取如下图所示中,不同LLM Role的头脑风暴过程。
在“发现”栏中,还可以参考当前其他学者生成的一些文章,以及聊天的示例。
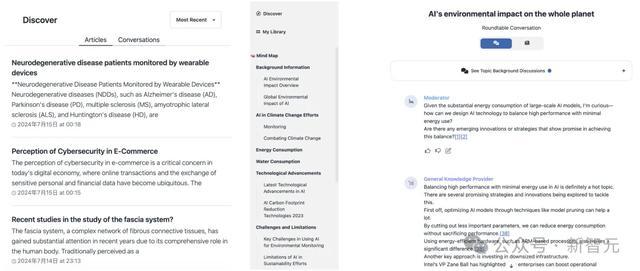
另外,个人生成的文章和聊天记录,都可以在侧边栏My Library中找到。
系统一经发布,大家纷纷上手体验,许多人惊叹道,STORM & Co-STORM实在让人眼前一亮!
“你只需输入一个主题,它就会搜索数百个网站,然后把主要发现写成一篇文章。关键是每个人都可以免费使用!”
网友Josh Peterson更是利用STORM,第一时间去结合NotebookLLM自动生成了播客。
具体流程是这样的:使用STORM生成4篇文章,然后将其中2篇提交给GPT-4o分析并提出后续主题。最后再把它们添加到NotebookLM里,一期有声的播客就做好了。
网友Pavan Kumar则是认为STORM揭示了一个重大趋势:“ 就算是没有博士学历,也可以创作出现阶段博士生才能有的成果。而将来一年的课程内容也足以媲美如今4-7年才能修读到的课程内容。”
STORM协助从头写出维基好文
论文链接:https://arxiv.org/pdf/2402.14207
传统长文写作(如维基百科文章)需要大量人工进行写作前的准备,包括资料搜集和大纲构建,而目前的生成式写作方法通常忽略这些步骤。
但是这也意味着生成文章往往面临着信息角度覆盖不周到,文章内容不够充实的问题。
而STORM可以通过多个LLM-Role互相提问与回答来让文章内容所涉及的角度更加详实周全。
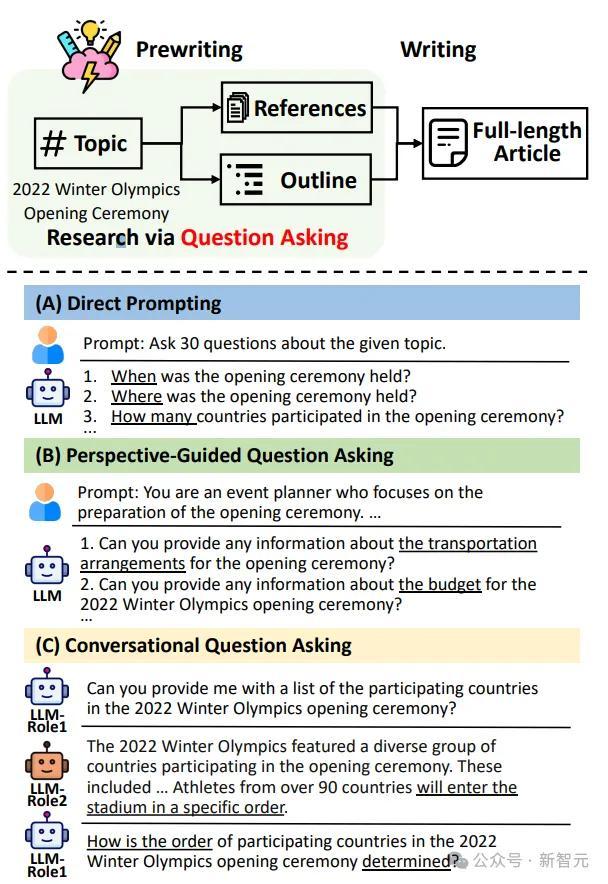
如下图所示,STORM系统分为三大阶段:
1. 多视角问题生成:
- 为了覆盖主题的不同方面,系统引入多角色模拟(如专家、普通用户),并生成视角引导的问题
- 图(A)显示了简单问题生成的效果有限,图(B)演示了通过视角引导问题生成的多样性提升
2. 大纲生成与完善:
- 使用模型的内置知识生成初步大纲。
- 系统通过对话(图C)模拟提问并完善大纲,使其更具深度
3. 全文生成:
- 基于大纲逐节生成文章,利用检索到的信息增加内容可信度和引用
从给定的主题入手,STORM系统通过查阅相关的维基百科文章(步骤1-2)来确定涵盖该主题的各种视角。
接着,它会模拟这样一场对话:一方是维基百科撰写者,其会依据给定视角提出问题,另一方则是基于可靠网络来源的专家(步骤3-6)。
根据LLM的固有知识, 从不同视角收集到的对话内容, 最终精心编排了写作大纲(步骤7-8)。
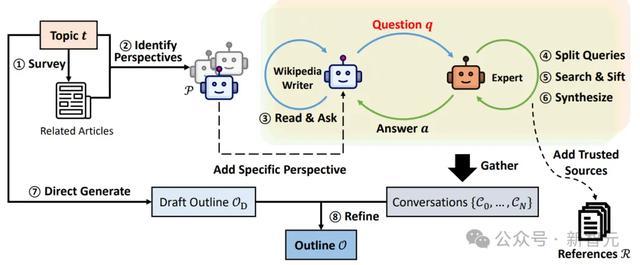
STORM系统自动化写作的整体流程
由于早期的研究采用了不同的设置,并未使用大语言模型(LLM),因此难以直接进行比较。
所以研究者使用了以下三种基于LLM的基线方法:
1. Direct Gen:一种直接提示LLM生成提纲的基线方法,生成的提纲随后用于创作完整的文章。
2. RAG:一种检索增强生成(Retrieval-Augmented Generation)基线方法,该方法通过主题进行搜索,并利用搜索结果与主题一起生成提纲或完整的文章。
3. oRAG(提纲驱动的RAG):与RAG在提纲创建上完全一致,但进一步通过章节标题检索额外信息,以逐章节地生成文章内容。
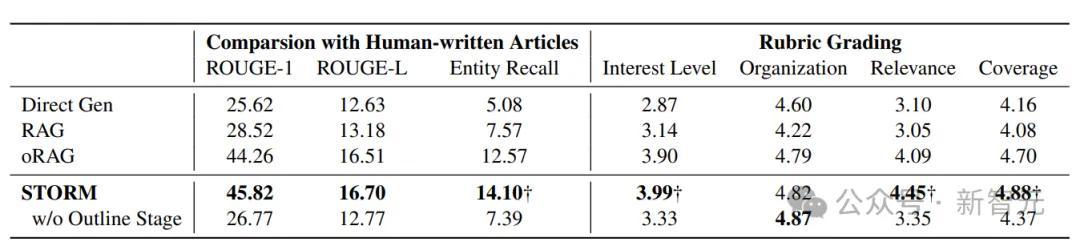
从上表可以发现,利用STORM生成的文章完全不输于人类水平,并且也优于目前LLM生成文章的几种范式,如效果最强的oRAG。
但不可否认的是,STORM生成文章的质量在中立性和可验证性方面仍然落后于经过精心修订的人工撰写文章。
虽然STORM在研究给定主题时发现了不同的视角,但收集的信息可能仍然倾向于互联网的主流来源,并可能包含促销内容。
该研究的另一个局限性是,尽管研究者专注于从零开始生成类似维基百科文章,但他们也仅考虑生成自由组织的文本。而人工撰写的高质量维基百科文章通常包含结构化数据和多模态信息。
因此,目前利用LLM生成文章所面临的最关键的挑战,依然是基于事实去生成拥有多模态结构的高质量文章。
智能体沟通打破人类盲点,显著降低认知负担
对于一些学习任务来讲,在搜集整合信息中,通常会由于个人或搜索引擎偏好而造成信息遗漏,以至于无法触及信息盲点(即未意识到的信息需求)。
研究团队在下列论文中所提出的Co-STORM正是为了改善这一情况,以大幅促进学习效率。

论文链接:https://www.arxiv.org/abs/2408.15232
在学习工作中,使用搜索引擎面临着需要阅览过多的冗余信息,而和Chatbots问答聊天,则又不知道如何进行准确的提问。但是这两种获取信息的方式都无法触及“信息盲点”,况且认知负担还不小。
那如果阅读现有的一些报道呢?这虽然降低了认知负担,但并不支持交互,无法让我们去更进一步的进行深度学习。
而与上述信息获取方式不同,Co-STORM智能体能够代表用户提问,能够多方位地获取新信息,探索到自己的“信息盲点”。然后通过动态思维导图组织信息,并最终生成综合报告。
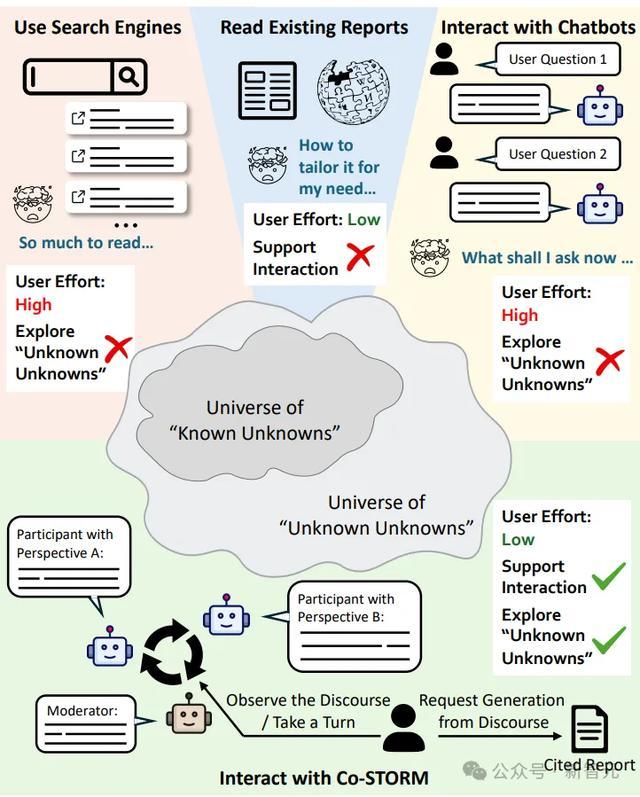
如下图所示,Co-STORM由以下模块组成:
- 多智能体协作对话:由“专家”和“主持人”进行模拟对话,探讨主题各个方面的相关内容。
- 动态思维导图:实时追踪对话内容,将信息按层次组织,帮助用户理解和参与。
- 报告生成:系统基于思维导图生成引用明确、内容翔实的总结报告。
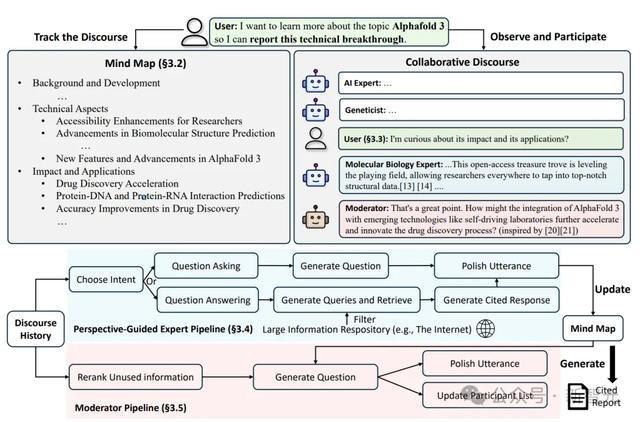
为了更真实地反映用户体验,研究者对20名志愿者进行了人类评估,比较了Co-STORM与传统搜索引擎和RAG Chatbot的表现。结果显示:
1. 信息探索体验:
- Co-STORM显著提升了信息的深度和广度
- 用户发现其能够有效引导探索盲点
2. 用户偏好:
- 70%的用户更喜欢Co-STORM,认为其显著减少了认知负担
- 用户特别认可动态思维导图对跟踪和理解信息的帮助
不过,目前STORM&Co-STORM还仅支持英语交互,未来或许官方团队会将其扩展至拥有多语言交互能力。
最后,正如网友TSLA的感受一样,“我们正生活在一个非凡的时代。今天,不仅所有的信息都变得触手可及,甚至连信息获取的方式也可以完全根据自己的水平量身定制,让学习任何东西都成为可能。”
主要作者介绍

Yucheng Jiang是斯坦福大学计算机科学专业的硕士研究生。
他的研究目标是通过创建能够与用户无缝协作的系统,提升学习能力、决策效率和工作生产力。

Yijia Shao是斯坦福大学自然语言处理(NLP)实验室的二年级博士生,由杨笛一教授指导。
此前,她是北京大学元培学院的本科生,通过与Bing Liu教授的合作,开始接触并从事机器学习和自然语言处理的研究。