国内大模型圈迎来神仙打架,OpenAI一觉醒来惊呼变了天?
1月20日,DeepSeek没有任何预兆地发布了DeepSeek-R1模型。不到两个小时,Kimi k1.5新模型随即发布。模型之外,还都附带上了详细的技术训练报告。
两款推理模型,全面对标OpenAI o1,在多项基准测试中获得了打平和超越o1的好成绩。DeepSeek-R1文本推理模型出厂即开源、可商用,Kimi k1.5同时支持文本和视觉推理,同样各项指标拉满,成为首个实现o1完整版水平的多模态模型。
中国大模型界“双子星”一夜间卷到海外,给了硅谷“亿点点”震撼。社交平台X上多位业界和学界大佬下场转发、点赞DeepSeek-R1与Kimi k1.5的帖子。
英伟达AI科学家Jim Fan第一时间发帖总结两者的相同点和差异性,评价所发表的论文是“重磅”级别。
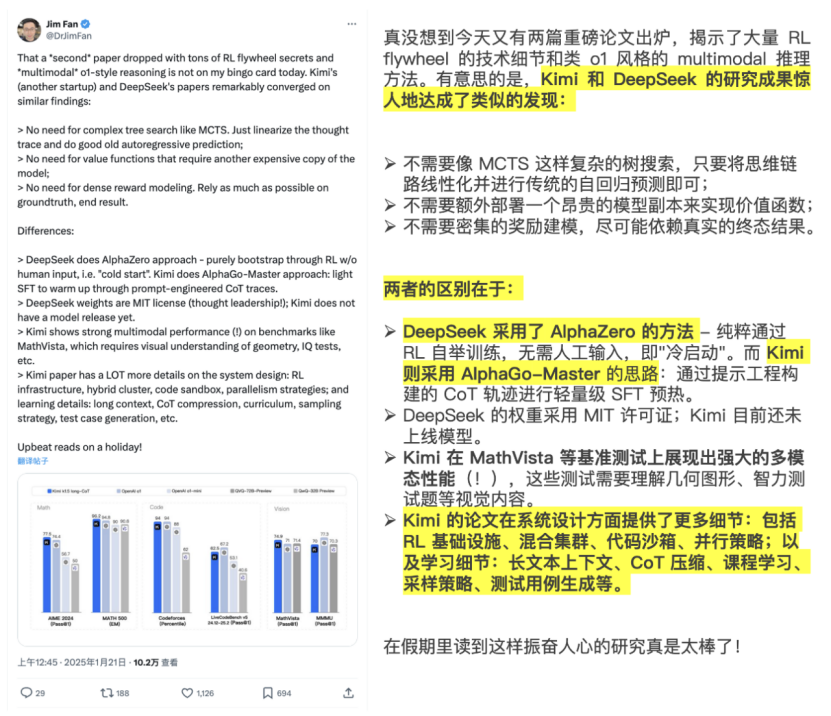
(图源:X)
(图源:X)
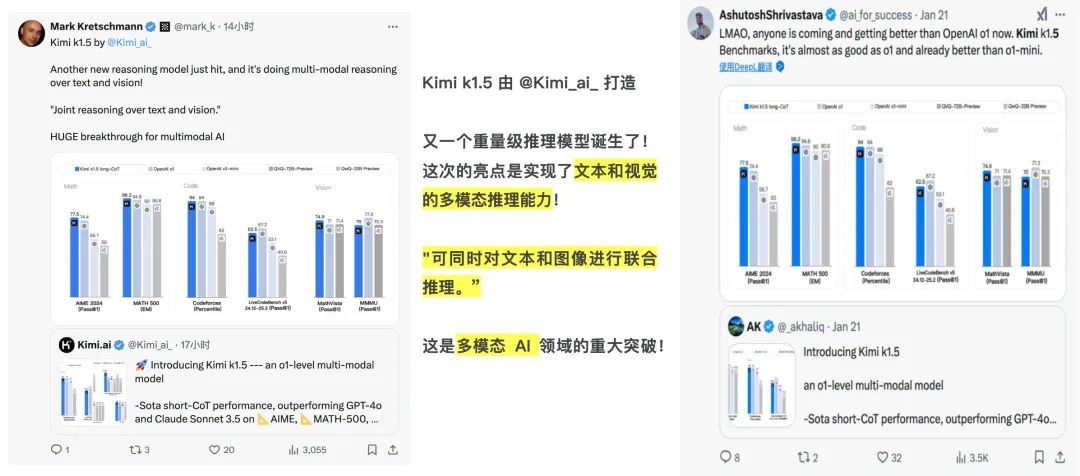
多位AI技术大V对Kimi k1.5给予肯定,有人发表评论称“又一个重量级模型诞生了,亮点是文本和视觉的多模态推理能力,这是多模态AI领域的重大突破”。有人将其与OpenAI o1相比较,感叹OpenAI是否已经被拉下了神坛,“越来越多的模型正在打败OpenAI o1”?
(图源:X)
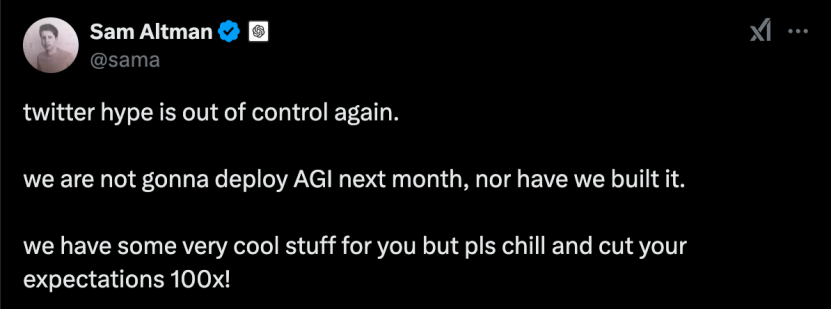
面对来自中国的“攻擂者”,挤牙膏式释放期货的OpenAI首席执行官Sam Altman在个人账号发布帖子抱怨媒体炒作AGI,让网友降低期待值,“下个月不会部署AGI,也不会构建AGI”。没想到,反而激怒了网友,被讽刺“贼喊捉贼”。
AI世界正在发生一些变化,DeepSeek-R1和Kimi k1.5验证了强化学习(RL)思路的可行性,开始挑战OpenAI的绝对领先地位。
同时,中国本土模型挑战不可能性,实现换道超车,也是对国内大模型行业的一次精神鼓舞。未来,中国AI企业仍有机会打破硅谷的技术垄断,走出中国自主技术路线。
真正的满血o1来了
继去年11月发布的k0-math数学模型,12月发布的k1视觉思考模型之后,连续第三个月升级,Kimi带来了K系列强化学习模型Kimi k1.5。

按照Kimi k系列思考模型路线图,k0到kn进化是模态和领域的全面拓展。k0属于文本态,聚焦于数学领域;k1增加了视觉态,成为了OpenAI之外首个多模态版的o1,其领域扩展至物理、化学;此次升级的k1.5仍是多模态,这也是Kimi模型突出特点之一,在领域上则由数理化升级到代码、通用等更加常用和广阔的领域。
从基准测试成绩看,k1.5多模态思考模型实现了SOTA(state-of-the-art)级别的多模态推理和通用推理能力。
国内外宣传达到o1水准的模型很多,但是从数据来看,目前只有Kimi和DeepSeek发布的模型才是真正满血版的o1,其他各家发布的模型还在o1-Preview的水平——差距有30%-40%。
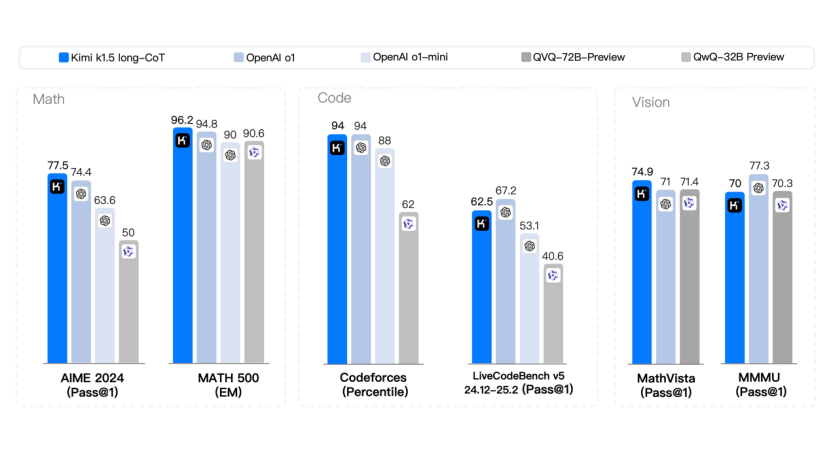
以OpenAI o1为基准,其数学水平得分74.4分,编程水平得分67.2分,并且支持多模态。按此标准审视国内已发布的推理模型,阿里QVQ、智谱GML、科大讯飞星火和阶跃星辰Step系列模型与实际o1水平仍有一定距离。DeepSeek和Kimi模型在数学水平上均超过了OpenAI,编程水平接近o1水准。但跟DeepSeek相比,Kimi支持多模态视觉推理,而DeepSeek只能识别文字,不支持图片识别。
具体来看,在short-CoT(短思考)模式下,Kimi k1.5超越了其他一切模型。其数学、代码、视觉多模态和通用能力,大幅超越了全球范围内短思考SOTA模型 GPT-4o和Claude 3.5 Sonnet的水平,领先达到550%。
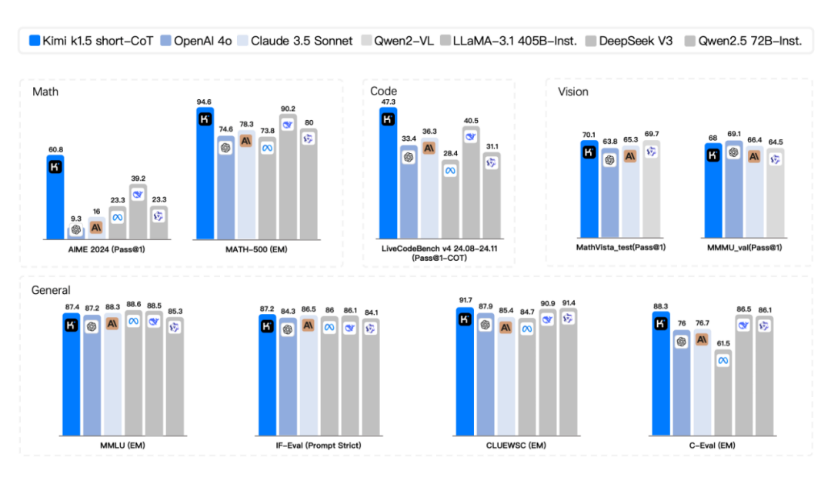
在long-CoT(长思考)模式下,Kimi k1.5的数学、代码、多模态推理能力,也达到长思考 SOTA 模型 OpenAI o1 正式版的水平。在两个数学水平测试(AIME 2024和MATH-500)中打败了o1,在编程水平测试(Codeforces)中与o1打平。这应该是全球范围内,OpenAI之外的公司首次实现o1正式版的多模态推理性能。
Kimi k1.5的修炼秘籍
海内外一起打call,实力水平经得住考验,Kimi是如何修炼成“最强大脑”的?
看完干货满满的技术报告,可以总结归纳为一种训练思路、一个训练方案和一个训练框架。其中,高效推理、优化思路贯穿其中。
受制于数据量的限制,预训练“大力出奇迹”的方法在现实训练中屡屡碰壁,从OpenAI o1起行业内开始转变训练范式,把更多的精力投入到强化学习上。
之前的思路可以理解为“直给”,即人类要主动去“喂”给大模型数据,监督大模型工作,介入大模型的“调教”过程。但强化学习的核心思路是,在没有人过多干预的情况下,让大模型自我学习和进化。
此次Kimi的新模型更新便采用了强化学习的路径,在训练过程中证明,无需依赖蒙特卡洛树搜索、价值函数、过程奖励模型,也能让模型取得不错的性能。
强化学习的思路集中体现在了“Long2Short”训练方案中,这也是Kimi技术报告的亮点所在。按其官方介绍,具体的做法为,先利用较大的上下文窗口,让模型学会长链式思维,再将“长模型”的推理经验转移到“短模型”中,两者进行合并,最后针对“短模型”进行强化学习微调。
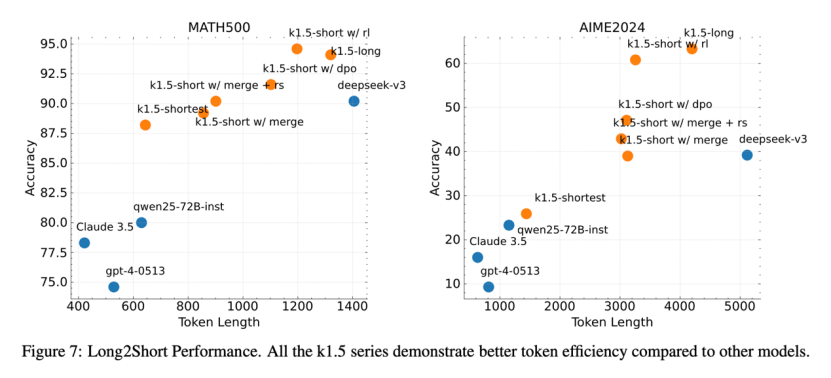
图注:越靠近左上角越好
这种做法的好处在于,可以提升token的利用率以及训练效率,在模型性能和效率中间寻找到最优解。
放到行业内来看,Kimi的“Long2Short”训练方案也是“模型蒸馏”的体现。在这里,“长模型”是老师,而“短模型”是学生,老师传授给学生知识,利用大模型来提升小模型的性能。当然,Kimi也采用了一些方法来提升效率,比如利用“长模型”生成的多个样本,取最短的正解为正样本,生成时间长的为负样本,以此来形成对照组训练数据集。
为了适配强化学习训练,Kimi k1.5专门设计了特殊的强化学习框架,作为基座来支撑整个训练系统。
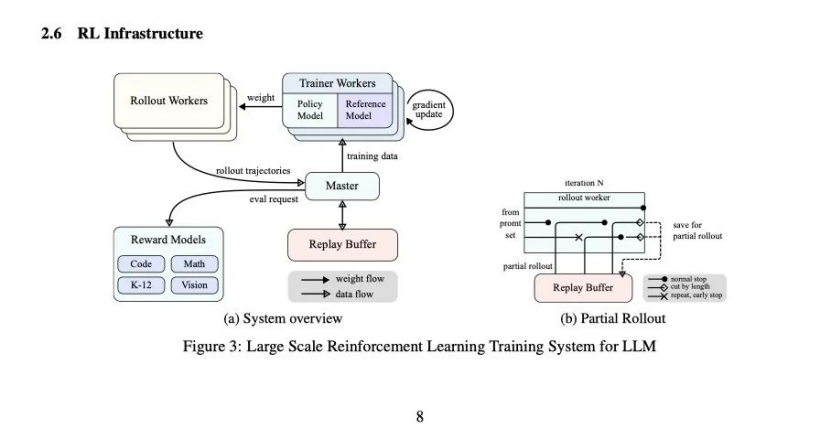
k1.5模型最高支持128k的上下文本长度,如果模型每次都要完成一次完整的思维链生成和推理过程,对于计算资源、内存存储和训练稳定性都会造成影响。因此,Kimi引进了“Partial Rollouts”技术,生成的链路切分为多个步骤,而并非毕功与一役。
底层AI infra的搭建思路,体现了月之暗面在长文本上的积累,如何实现资源最大化和高效是其一直重点解决的问题,现在这种思路又将延续到思维链生成和推理上。
中国“双子星”终结OpenAI神话?
从Kimi和DeepSeek身上,我们或许能看出未来模型训练的几种趋势:对于强化学习训练的投入和资源倾斜将加大;OpenAI o1成为了下一阶段大模型入场的新门槛,技术、资源跟不上意味着掉队;上下长文本技术尤为重要,这将作为能够生成和推理长思维链的基础;Scaling law还没有完全失效,在一些局部,比如长上下文本依然存在并且具有潜力。
中国“双子星”打开了OpenAI的黑箱。此前,OpenAI定义了大模型训练的四个阶段:预训练、监督微调、奖励建模、强化学习。现在,这个范式被打破了,Kimi 和DeepSeek都证明了可以跳过和简化某些环节来提升模型的训练效率和性能。

Kimi和DeepSeek效应是双重的。走出国门,向海外AI圈特别是硅谷证明,持续的专注于聚焦就能出奇迹,中国依然具备竞争科技第一梯队的能力。
OpenAI应该反思,在投入如此资源和拥有高人才密度的情况下,为什么被来自中国的企业在多个方面赶超,这或许将给世界的竞争格局带来微妙的变化。人们不禁要问,OpenAI的先发优势还能持续多久?不仅同一个国家有死对头Anthropic,从其手中拿走了To B的单子,现在还要对来自中国的AI企业保持警惕。
在国内,新的格局似乎已经在变动之中。DeepSeek凭借开源和超越OpenAI性能的模型受到了前所未有的关注,甚至已经开始有人将其纳入“AI 六小虎”的行列之中。
相较于以前,现阶段的Kimi更加明确了从k0到kn的技术路线,尽管其表示“会聚焦在Kimi一个产品上”,但Kimi所承载的已经远远超越了一个普通的AI应用。
Kimi k1.5让月之暗面拿下了下一阶段的入场券,这也让其在未来竞争中掌握更多的主动权。保持一定的领先之后,2025年新的目标是如何活得更好。
新一轮洗牌悄悄开始,谁会先掉队,谁又能先突出重围?