1.23

智识学研社新年科学演讲现场
编者按
过去几年是AI发展突飞猛进的几年,2024年,诺贝尔物理学奖和化学奖更是破天荒地颁给了AI领域的科学家。
然而,即使拿下了诺贝尔奖,我们也很难将这些年AI的进展单纯归结为科学上的胜利,它更像是一个工程上的奇迹。当下业界甚至学界广泛追随和信仰的Scaling Laws,本质上仍是“大力出奇迹”:相信更多数据、更大算力、更大参数能给模型带来更高的性能。
与此同时,AI系统内部的运作机制依然是一个巨大的黑箱,从神经网络的表征学习到决策逻辑的可解释性,核心的科学问题仍未得到根本性解答。AI虽然对传统科学贡献良多,但它本身的科学原理却仍在迷雾之中。
在智识学研社2025年新年科学演讲上,香港大学计算与数据科学研究院院长马毅教授提醒,在讨论人工智能甚至通用智能(AGI)之前,我们首先要了解什么是智能,智能背后的数学原理是什么?过去十年,在机器智能这个领域,“术”的层面取得了长足的进步,但是“道”的层面还有很长的路。在现在这个时间节点上,科学变得非常重要。
以下为马毅新年演讲全文,全文共9301字。
● ● ●

毋庸置疑,这十年来人工智能技术突飞猛进,进展日新月异,甚至超出了很多人的想象。不光是学术界,还有产业,乃至政府、社会都变得非常关心这件事。技术发展很快,但是对智能的科学问题、数学问题,乃至后面的计算问题,并没有界定得很清楚。
自古以来,中国的哲学中一直有“道”和“术”的概念。那么在科技这个领域,术是工程技术,千变万化;但是道,思想、科学理论的本质问题,大道至简。过去十年,在机器智能这个领域,“术”的层面取得了长足的进步,但是“道”的层面恐怕还有很长的路要走。
今天大会的主题是‘AI for science’,我想在今天强调一个观点,就是——可能“智能就是科学,科学就是智能”。
过去几年,我们团队一直在研究智能到底是什么,智能的背后有没有严格的数学问题,有没有非常严谨的计算基理。这是我们想搞清楚的。

爱因斯坦说过一句话,这句话是在讲science。Everything should be made as simple as possible,but not any simpler(凡事力求简洁,但不能过于简化)。意思是所有的事情都应该解释得尽可能的简单到不能再简单。这个标准是什么呢?要简化,把世界的规律用最简单的方式找到;但是不能再简单,再简单就解释不了现象。这两句话在我看来是科学的本质,也是智能的本质。
刚才韩院士也提到,对于未来会怎么样,大家现在都很焦虑。一个古老的智慧是——欲知未来,先知过去。
01
从生物演化视角重新思考智能
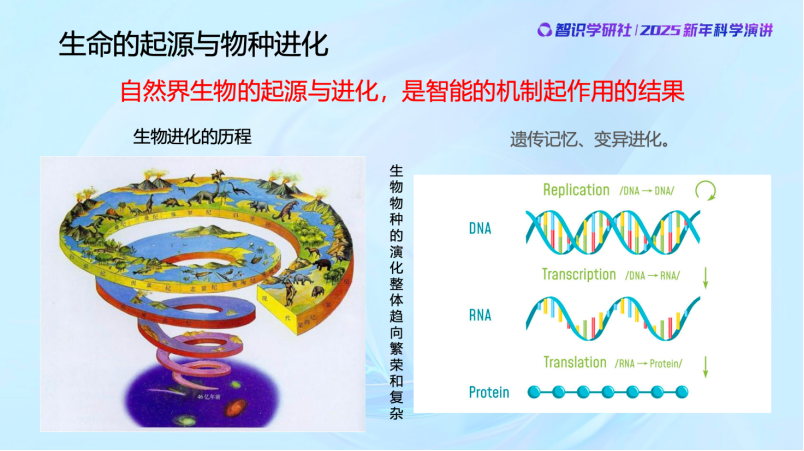
最近几年,我和团队做了一些跨学科的合作研究,我们的智能研究本身也越来越深入,这让我强烈地感受到——自然界生物的起源与进化是就是智能机制起作用的结果,甚至可以认为——生命的本质就是其智能的演进。智能是生命的更底层的机制,而生命形式只是智能的载体。

可以看到,其实生命的起源与发展过程就是生物智能发生和发展的过程。最早的时候只有DNA,后来开始有了早期的生命。这些最早的生命个体基本上没有学习和自我进化的能力,几乎可以认为在个体层面没有智能。但群体有智能,群体一步步通过遗传变异和基因的优胜劣汰,代代相传外部世界的知识,从而帮助适应与生存。这种过程现在有一个很流行的名字,就是生物群体在做Reinforcement learning,不是不能进步,但代价很大。
带着这个视角来看今天的大模型,你会发现大模型的进化与上述情况非常相似。现在的 “大模型”完全可以类比 DNA和早期生命阶段,我们对它的内部机制并不完全了解,但试错、竞争、优胜劣汰的过程和现象,如出一辙。早期无数生命快速诞生和消亡,现在的大模型则是百模大战,一将功成万骨枯——同样,这个过程当然也能进步,但代价极大,资源消耗惊人。
到了差不多5亿年前,生物的神经系统和眼睛的出现,让生物个体获取外部信息的能力激增,引发了寒武纪生命大爆发。大脑一定程度上取代了DNA的记忆作用,个体具有了智能。

生物的智能,从基因遗传和自然选择这种物种层面的智能,生物学上我们叫Phylogenetic,进化到个体具有后天学习与适应的智能Ontogenetic,这是智能机制上非常大的跳跃。
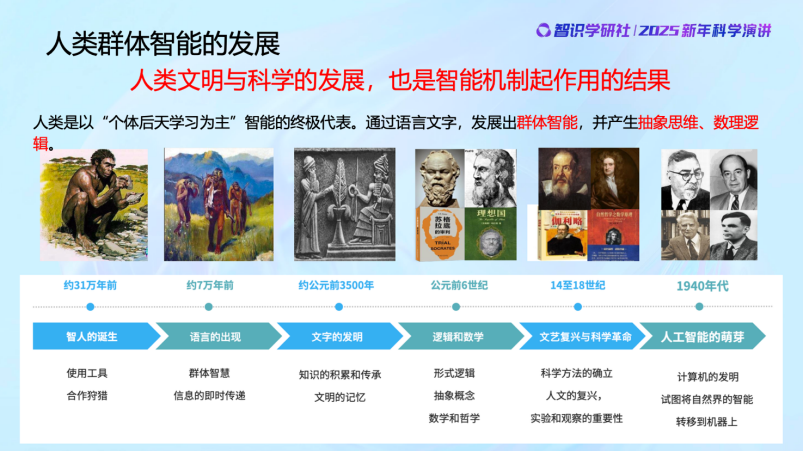
后来人类诞生,相比于此前的生物,人类的大脑高度发达,个体智能得到了极大提高,同时人类群居行为和信息交流又进一步提升了人类的群体智能。不但是人类的个体在学习,而且学习的东西还通过文字和语言在交流并得以在群体中传承,语言文字又取代了DNA的另一部分作用,能够把知识记忆并传下去。
然后到了几千年前,数学与科学的出现又一次大大推动了智能的发展。人类学会了抽象的能力,超越了之前单纯从经验的数据里寻找规律。这期间到底发生了什么?到目前为止大家并不是很清楚,但是我们知道,作用机制从本质上和生物智能的早期机制是非常不一样的。我们做学问一定要把历史搞清楚。
02
智能研究历史:
起源、寒冬与大爆发

那么真正开始对智能进行研究,这件事情的起源在哪里?今天一提到智能,大家都说是起源于 1956年(达特茅斯会议定义的)的“AI”,这显然是不正确的。人类对智能机制的深入研究至少可以追溯到上世纪40年代。当时,以诺伯特·维纳为代表的一大批杰出科学家,开始探索机器模拟动物和人类智能的可能性。
他们研究了哪些问题呢?比如研究“一个系统怎么从外部世界学习有用的信息,这些信息怎么组织管理、度量”,他的学生香农创立了信息论;维纳本人研究“动物是如何学习的,反馈、纠错”,这是控制论和系统论;然后是“怎样通过跟外部环境或者对手博弈,不断地提高决策质量”,这是冯·诺伊曼的对策论和博弈论。维纳的思想还直接影响并催生了40年代初沃伦·麦卡洛克和沃尔特·皮茨提出人工神经网络首个数学模型。包括图灵研究计算(computing)如何通过机器实现,他提出图灵测试本质上也是相信人和机器之间的计算机制应该存在着统一性。我们看到,维纳的《控制论》英文名就叫Cybernetics: on Control and Communication in the Animal and the Machine。这些科学家就是想知道动物感知和预测外部世界的能力,以及这种系统的本质和机理到底是什么。对这些科学家来说,他们都坚信——智能背后的数学机制是统一的。一旦找到了并实现了这些机制,动物与机器之间的界限将变得模糊——我们可以将其称为“诺伯特·维纳测试”。
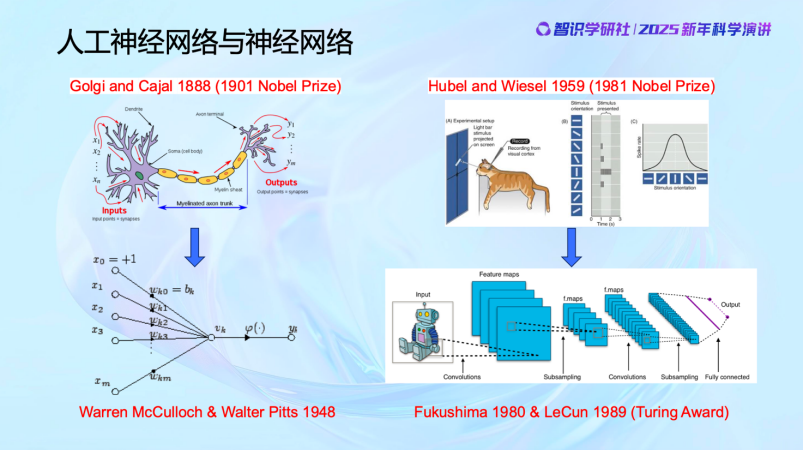
人工神经网络的诞生与发展本身,同样是人类从生物学和神经科学研究中获得灵感的结果。既然动物是一种智能存在性的证明,那么我们就可以去研究神经的工作原理。这促使了神经元的数学模型的诞生,即人工神经元。有了数学模型之后,当时大家比较急,或者说对智能的后续发展开始变得过分乐观,觉得既然掌握了神经元的数学模型,那就可以去构建神经网络,制造感知机,并且去训练它。大家如果去看50年代的《纽约时报》对感知机的报道会发现,我们现在在人工智能上吹的牛当时已经吹过了,比如机器能够自主学习和思考,人类将不再需要劳动等等,这都是50年代神经网络模型出现后的社会讨论。但是后来发现其实不行,不work。
直到80年代,人们才意识到可能还有一些关键因素没有被充分理解,所以又重新开始研究大脑的工作原理,从而诞生了卷积神经网络,这也是1989年的图灵奖。
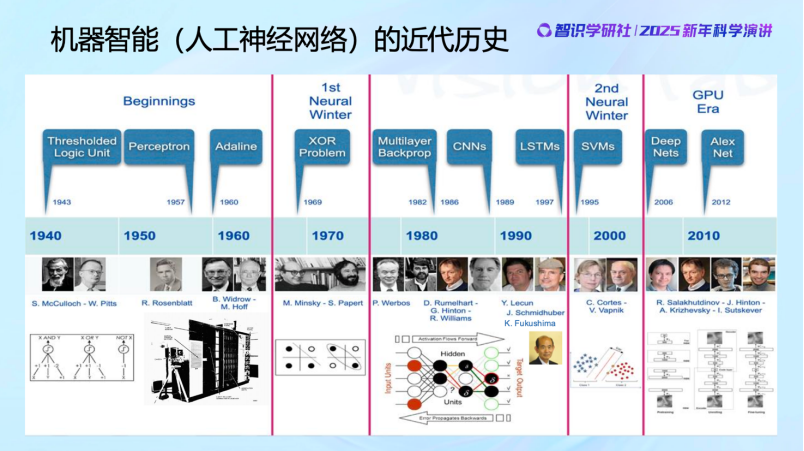
大家可以看到,40 年代之后,有了人工神经元的模型后,开始建立了系统和网络,有了神经网络的概念。在过去大概 80 年的时间里,神经网络几起几落,这是一个基本的发展历史。最早由于 practice比较粗糙,效果并不是很好,当然理论上也发现了神经网络有它的局限性,让大家在70年代对神经网络的能力产生了一些质疑,导致在70 年代进入了一个寒冬。但是在 80、90 年代还是有不少人仍在坚持,比如Hinton、LeCun 等等,而且在设计越来越好的算法,去训练神经网络,包括 Backpropagation 等。到 2000 年,神经网络又进入第二个寒冬,原因主要是在做分类的问题上,出现了一个支持向量机的工作,由于它的数学理论比较严谨、算法比较高效,所以对神经网络也带来一些冲击。一直到2010年以后,神经网络随着数据以及算力的加持,它的性能得到逐渐的提高,才带来了这些年的蓬勃发展。
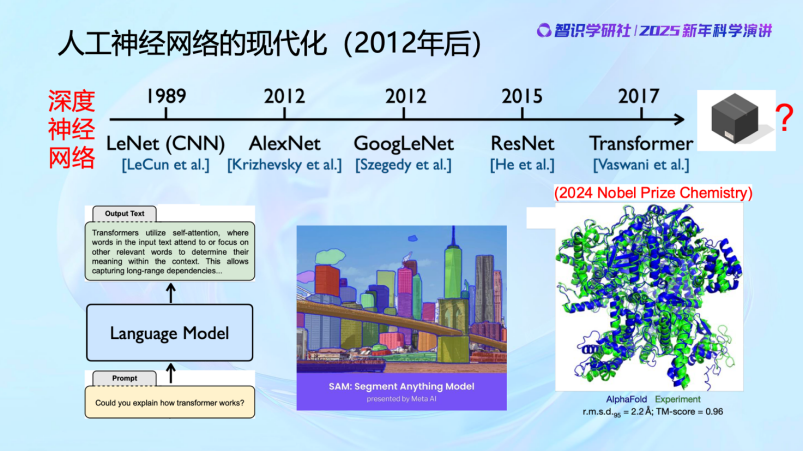
最近这十几年,凭借算力和数据的支持,人工神经网络的应用开始迎来飞跃,直到今天。特别是在文本、图像和科学领域尤为突出。比如说 在Transformer 下,不管是文本、图像,甚至在各方面的科学数据上都取得了非常显著的成效。所以其实近年来AI的成果,实际上是多年前的理念在技术层面的实现。
03
从黑盒到白盒

现代深度神经网络一直是黑盒子。因为基于这些深度网络的人工智能系统都是基于经验或者试错的方式设计出来的。当然,这个黑盒子的确取得了很多非常突出的成果。所以不少人会认为深度网络作为“黑盒子”,只要能用、好用就足够了。从工程角度看,这或许没问题,但从科学角度来看,我觉得这难以接受。更何况历史上,但凡影响力巨大的事物,一旦它还是一个“黑盒子”,就极有可能被人利用。
以天文为例,历史上,在天体物理、牛顿力学诞生之前,迷信与巫师活动盛行。一些人会利用民众对天文现象的无知制造恐惧,从而达到自己的目的。而科学家的重要的价值和责任之一就是要破除这种现象。从这个角度出发,我们必须要搞清楚,智能究竟是什么,这些深度网络究竟在做什么、能做什么。
我们需要研究怎么把智能定义为一个科学问题,明确其科学问题的核心,探究它的数学本质,以及确定正确的计算方法——这些议题现在必须被提上日程。
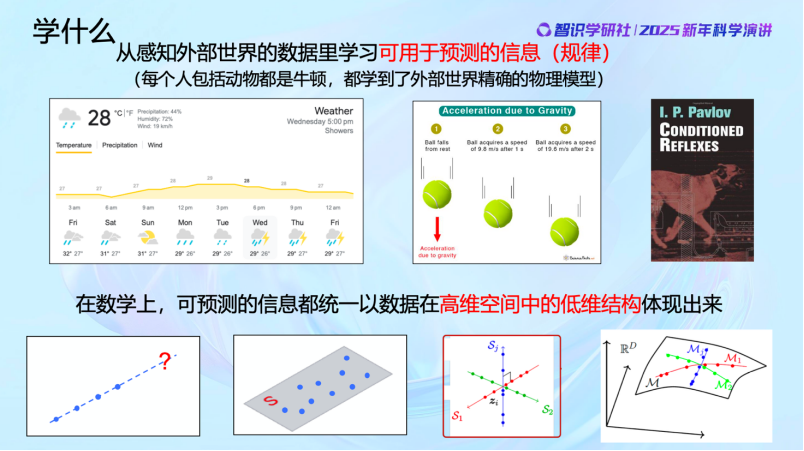
今天的主题是“AI for science”。科学到底是什么,能做什么?某种程度上讲,科学就是感知到并学习外部世界,然后获取可预测的信息和规律。
这里有很多例子,比如气象学,正是因为世界并不是完全随机的,有一些是可以找到内在规律的,我们才能预测天气。物理规律的发现同样是如此。比如一个球的下落,我们知道它是遵循物理定律的。但其实,从智能的角度,我们在座的每个人甚至是阿猫阿狗都是“牛顿”。因为人和猫狗这样的动物其实都对外部世界建立了极为精准的物理模型。比如当玩的球下落的时候,猫和狗能够迅速且精准地接住,甚至比人还准。它们不需要懂牛顿定律,却能不断学习,并用学到的东西对外部物理世界做出精准预判。学习到的是什么呢?是外部世界的数据的分布规律。
那能不能从数学角度把这些规律统一起来呢?其实是可以的。牛顿定律和动物学到的物体运动的规律差别仅在于表达的方式不同,语言不同,但在数学上其实是具有一致的表现形式的。比如说一个物体在不受外力影响的情况下,会在一条直线上运动,我们很容易判断它在下 一 秒出现在哪里,它不会随机出现在其它的地方。当然还有更复杂的可预测的问题,它可能不是一条直线,很可能是一个平面,或者是多条直线,甚至多个平面、多个曲面等等,数据里面很多的信息就是通过这种结构体现出来的。
我们学习就是要从这些观测到的高维空间中的数据里面学到低维的数学结构和特征,学到以后还要把它组织好、表示好,这也是现在AI领域的前沿课题。

学习到低维结构有哪些好处呢?低维结构具有很多很好的性质,比如completion(补全)、denoising(去噪)和error correction(纠错)。
首先,completion补全。数据分布在一条线上,部分缺失,AI能够填补这些空白,就像GPT做填空题一样。事实上Transformer就在做这件事,nothing else。

第二是denoising,去噪。当我们识别出数据中的噪声并找到规律后,就能清除噪声,就像我们的大脑会自动清晰化模糊的图像。这就是Diffusion model在做的事,大家现在经常看到的以及用到的用AI生成声音、图像的功能和应用,本质上就是在做这个,nothing else。
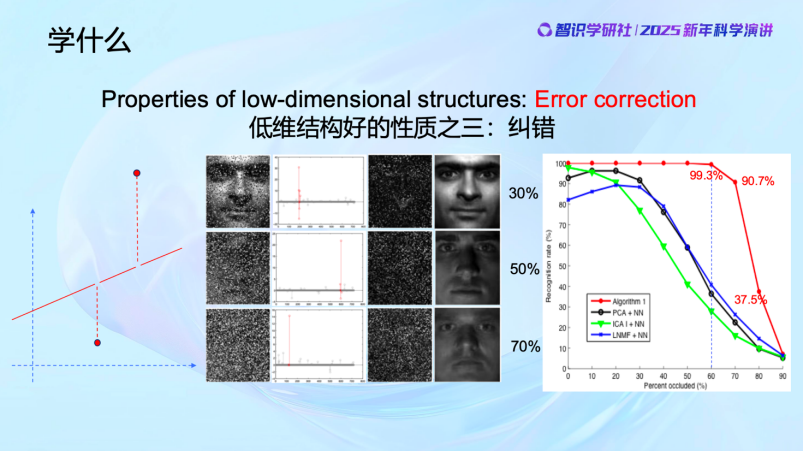
低维结构第三个特别好的性质是Error correction,纠错。当发现数据与已知规律不符的时候,比如物体被遮挡,AI能够像像大脑一样填补缺失部分,甚至损毁了的内容都可以恢复,现在机器做出来的效果可以非常好,远远超过很多人的想象。
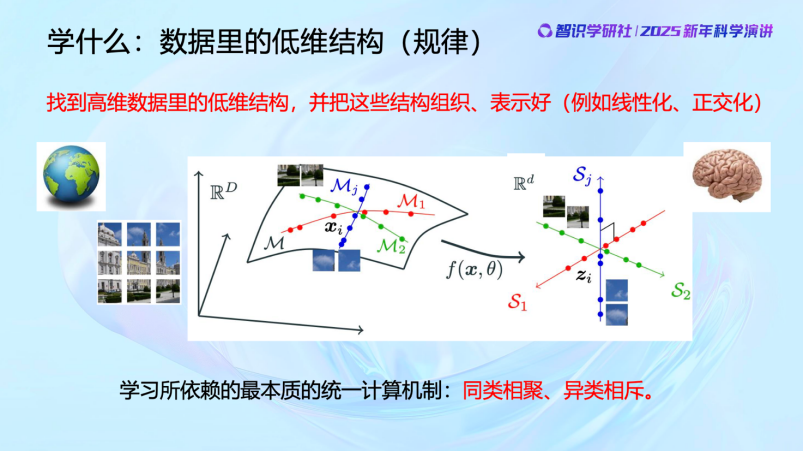
所以我们学习的统一的数学问题,就是从高维世界中学习数据的低维分布,然后把它组织好并结构化。前面讲到,人和动物的大脑天然就在做这个事情,找到相关性和规律。我们现在通过数学方法让机器来做同样的事情——去发现数据间的相关性和规律。
数据分布在很高维空间中,一张图像可能包含一百万或一千万像素,但其结构可能只有几维,甚至非常线性。宇宙广袤,千变万化,但研究弦理论的数学家和物理学家可能会说,从宇宙大爆炸到今天的所有观测到的物理现象,用一个9维或11维的模型就足够描述了,极为简洁。内在的道理是一样的,规律本身简单,而表象千变万化。
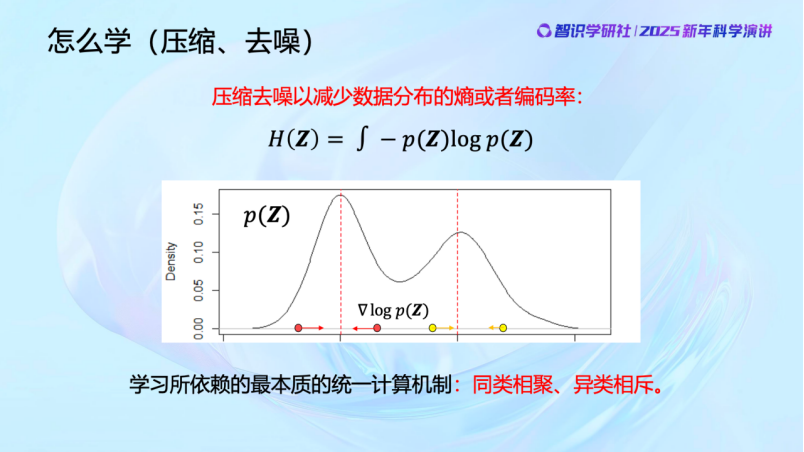
刚才谈的是“学什么”的问题,我们要去找低维结构。那么该怎么找,怎么学呢?
首先是去解决观测数据中的噪声问题。比如我们观察的世界空间是一维的,那么它更低维的规律就应该在零维上。我们看这张图,偏离红线以外的观测就应该是噪声,我们可以通过数据压缩,把这两条红线外的区域往里挤压来去噪。而衡量这些数据分布的不确定性的指标就是熵。当我们在去除噪声,朝低维结构压缩的时候熵在减少,这是信息论描述的事情。通过这样的过程,相似的东西会自然聚集,而不相似的则应该被分开。
过去十年间,神经网络不管是感知、分类还是生成,所做的事情都可以通过这张图来解释,今天大家所见的所有AI的现象,它最基本的原理都在这张图上,包括执行方式和优化算子。这里面的数学机理即使是本科生也能理解。
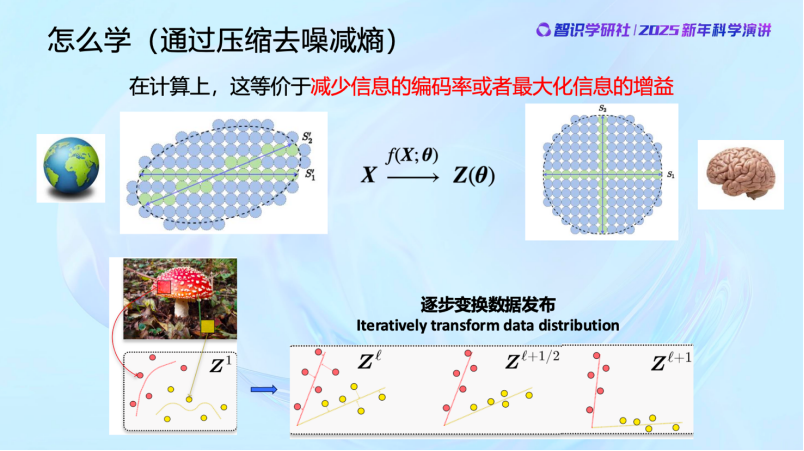
好,刚才说的是从一维到零维的情况。当数据维度更高的时候,情况会稍微复杂一些,但道理是一样的。
当我们对这个世界还什么都不知道的时候,什么事情都可以发生,你可以想像整个未知世界一开始可能是整个蓝色球覆盖的区域。但因为我们的世界不是随机的,它是有规律可预测的,可能发生的事情就是这些绿色的球所表示的区域。如果我找到这些绿色的区域,其实就是对这个世界认知的信息有所增加,这就是信息增益。从信息表达的角度,我就用不着去把每个球都记下来,我只需要记住这些绿色的球,对这些球进行编号,球的编码量就会减少。所以你会看到,对世界的认知的信息在增加,实际上是一种编码量减少的过程,这其实就是压缩的概念。因为这个世界是可预测的,发生的事件存在的分布就是可以被压缩的。这是第一点。香农的信息论其实就是告诉我们怎么用类似编码的方式把信息记录下来。当然,现在有了一个更时髦的词,叫Tokenization.
第二,当我找到这些绿色球所在的地方之后,我还需要在大脑里面把它们组织好。可能一开始我们的脑子还区分不了苹果和桃子,比如说这两条线,一个代表苹果,一个代表桃子,我要把苹果和桃子在我的大脑里面最大限度的分开。相关的变成独立的,不正交的变成正交的。实际上现在Transformer就是在做这样的事,它就是将图像打为Tokens并组织好。
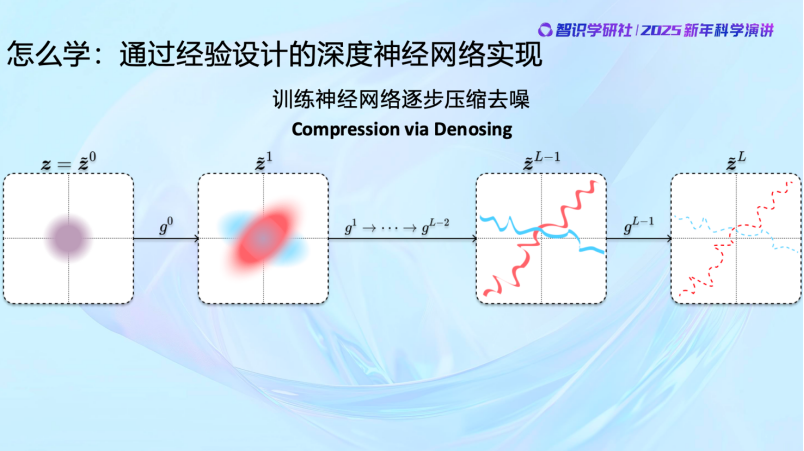
包括现在,我们看到Diffusion Model ,一样的,当我们知道怎么做了以后,就是从一个随机的过程逐渐压缩去噪,最后找到自然图像的分布。而且目前Diffusion Model还有一些缺陷,没有完全组织好。所以完全可控的生成还没有完全实现。
现在大家看到的Stability AI, Midjourney等等其实也都是在做这件事。
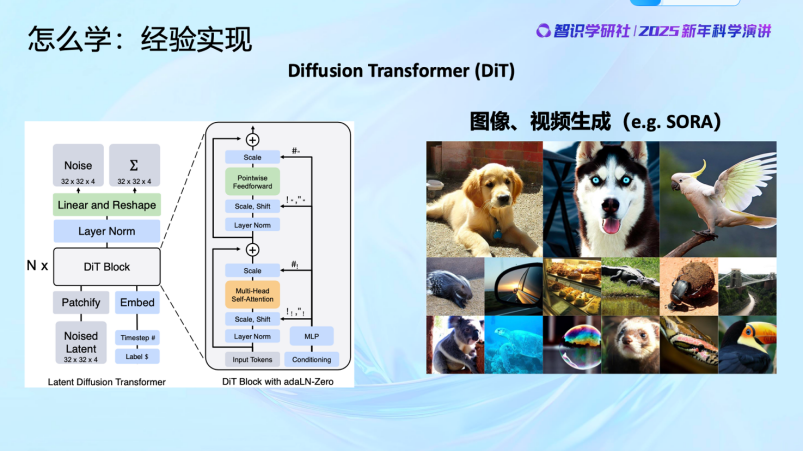
今天的AI技术像Diffusion Transformer,用到图像、视频上,像Sora,本质上都在做这件事。原理上其实是一样的。
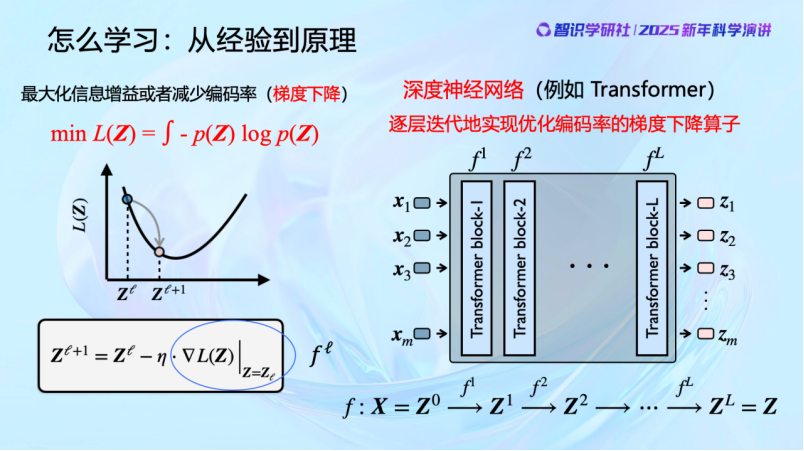
现在知道了学习的目的,那么具体要怎么去实现它呢?
压缩去噪要优化的目标是一个很复杂的函数,目标很复杂。我们找不到全局最优解。但至少可以局部地去优化它。通过对输入的数据的分布稍微重组织一下,使其熵略微减少,一层一层地进行。自然界也不会一次做到位,但自然界知道可以在原有的基础上一步步变化。那我们也可以一步步优化,使得每次数据被处理后都更好一点,熵都减少一点,一层一层,一次一次地来做。神经网络每一层都在做这种整理,让使输出数据比输入更好。所以其实从这里,一目了然,神经网络就是在做压缩、去噪,以找到数据的低维分布并把它组织好。
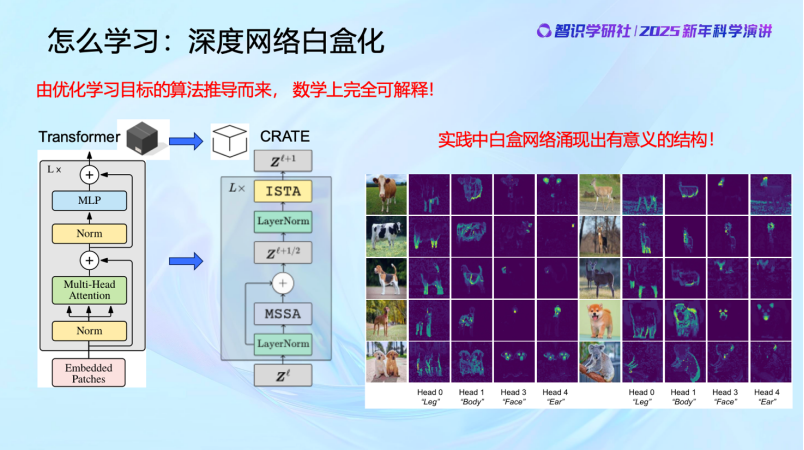
知道了这些,我们就可以通过数学推导,设计这些网络每一层的算子并优化明确的目标函数。大家可以看到,这些数学推导只需要本科生的数学知识,主要就是求导以及做梯度下降。然后大家会发现,对这样的算子的一些简单的实现就有类似Transformer的结构出现。并且这样的网络学到的结构更加简洁,更加具有统计和几何意义。它就是在对数据做聚类和分类。
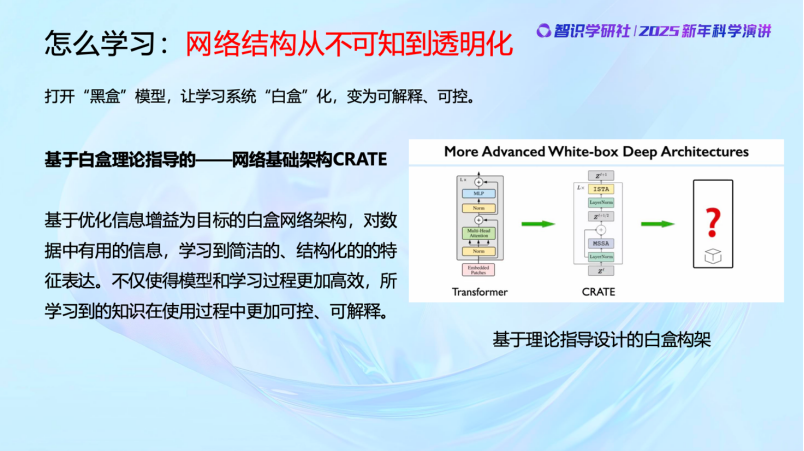
当我们了解神经网络要实现的目标后,就可以完全理解它其实是实现这个目标的手段而已(means to the end)。那么我们就可以清晰、可控地设计每一层的结构,每一层要实现什么算子,作用是什么,算子、参数在做什么,都可以看得很清楚,而且数学上完全是可解释和可控的, 不需要人去猜测、调整。
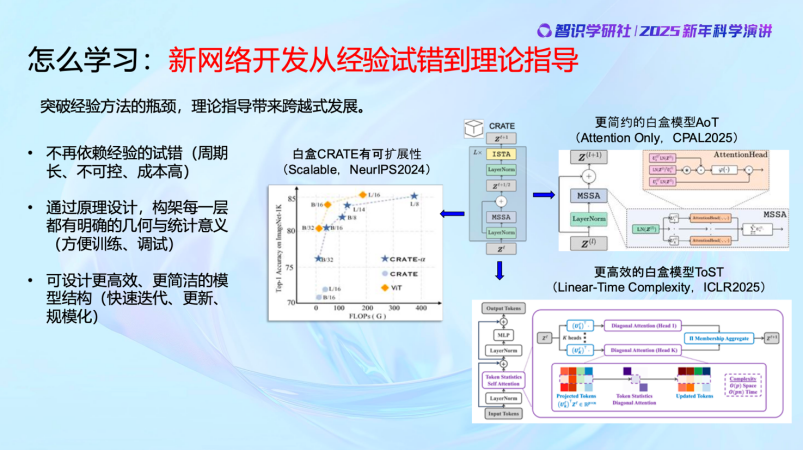
前面讲的是早期的最基本的白盒模型。最近这两年的时间,我们的工作又有了令人振奋的进展。首先,白盒的结构完全可以扩展,处理的图像规模完全可以扩展到几十亿,甚至上百亿。而且,白盒也正在变得更加简约,过去的很多通过经验设计的冗余的地方,全部可以不需要。甚至我们还让它变得更加高效,我们优化了Transformer,每一层算子的计算复杂度从二次复杂度降到了线性复杂度,而且全部是通过数学推出来的,不是猜出来或者试出来的。清清楚楚,更高效,而且去除了冗余的、经验设计中不必要的部分。
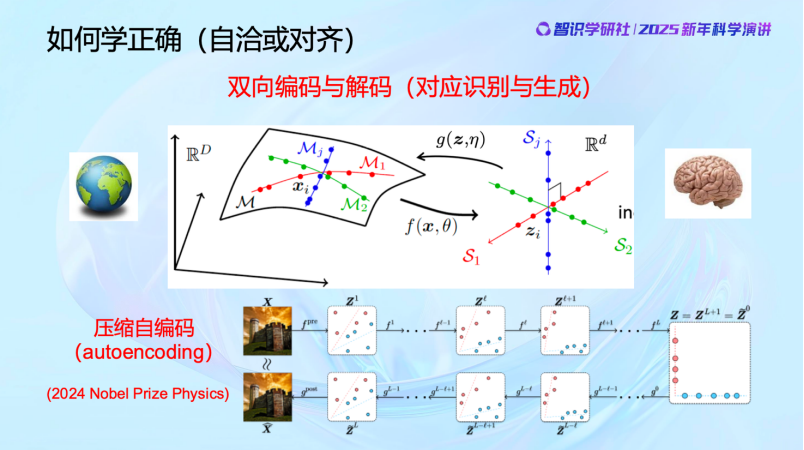
前面是学习,从外部世界学到数据分布,并且组织好。
但怎么判断做对了没有呢?数据够不够学习完整的分布,有没有漏掉的地方?怎么去验证这个模型压缩去噪以后是对的,而且够了呢?只有一个办法——回去用,把它decode 回去。
刚刚过去的2024年,Hinton获得了诺贝尔物理学奖。获奖的这个工作是他在80年代做出的,其实就是在做这件事,从物理学得到启发,把autoencoding做好。当然,今天看来这个方法不见得就完全正确,但这个问题是很对的。

我们是怎么解决这个问题的,又做到了什么样的效果呢?可以看到,用白盒的方法,所有算子都是数学方法搭建出来,完全可以做到和通过经验设计的网络一模一样的效果,甚至可以更好。
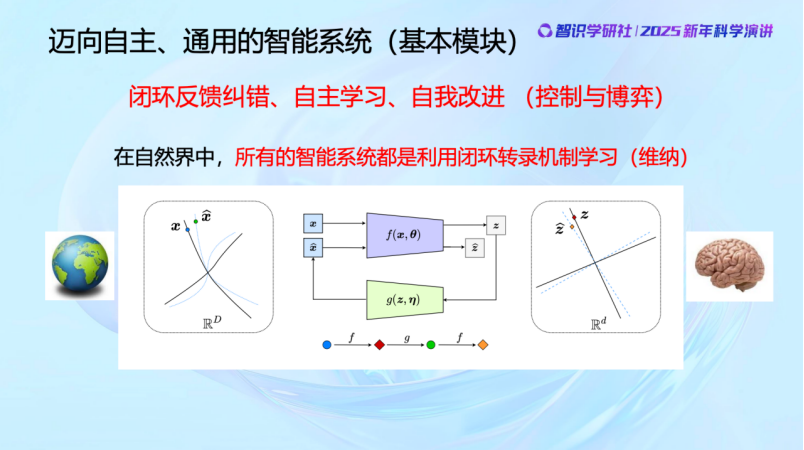
那仅仅依靠编码(encoding)和解码(decoding)就够了吗?
2022年,Hinton发表了一篇文章,叫Forward-Forward Algorithm (编者注:在NeurIPS 2022 上,Hinton 介绍了他的最新工作“ Forward-Forward Algorithm ”即FFA,这是一种新的人工神经网络学习算法,灵感来自于人类对大脑神经激活的了解。他认为forward-forward 有可能在未来取代 backprop。该论文还提出了一种新的更接近大脑的节能机制的计算模型,并可以支持forward-forward算法)。其实我们早就知道,自然界没有BP这个option(选项),没办法像程序员那样可以看左边不够补一下左边,看右边不够又补一下右边,数据不够又去量一量再给系统补下数据。人也好,猫狗也好,我们的大脑是不直接在外部物理世界度量对错的,我们做不到这一点,我们所有的学习都是在大脑内部进行的。
比如说,我看到现场有很多圆形的设备和装饰,但大家怎么确定它的形状就一定是圆的呢?你是用尺子圆规一个个去测过的吗?不是的吧。那你怎么知道的呢?从小到大,我们并没有逐一测量过这些东西,但我们还是能够分辨物体的形状、种类、判断速度并且采取行动。动物也是一样的,当一只山羊看到老虎向它冲过来时,它不可能说老虎你等一下,我来测测你的距离和奔跑速度,不会的。如果真有过这样做的生物,也早就被自然选择淘汰掉了。动物的学习全部是自主(Autonomous)的学习。
其实这就是诺伯特·维纳80年前就提出并且探讨的问题。维纳本科学的是动物学,所以他很早的时候就在思考——动物是怎么学习这些的呢?动物的方法是,我要让我的记忆能够恢复我观察到的物理世界,并对它进行预测。动物没法把自己大脑中的世界和真实的物理世界直接比较,来看到底对还是不对。
那它们是怎么做的呢?答案是闭环。就是不用在真实世界中去比,而是把你假想的和你感知到的进行比较,这就是闭环做的事情。所有的自然界的生物,全部都是闭环学习。
为什么现在有些人主张进行端到端的模型训练呢?那估计他们想卖更多的数据或者芯片给你吧。端到端的方式当然可以训练,但代价很大,成本很高。而像蚂蚁和其他小动物,都能高效、自主地学习,不需要大量的数据和算力,因为它们的学习从机制上就是不一样的。

预训练存在一个显著问题:容易出现灾难性遗忘。大家也可以看到,预训练模型从1.0到2.0再到3.0,每次都需要重新训练。但是我们看我们自己,你的大脑有每次都重新训练的1.0、2.0、3.0的版本吗?没有的。你每天都在持续学习,而且你长大了学了新东西以后,你小时候学的是不会忘的,你还是知道加减乘除怎么算,对不对?闭环系统是不会忘的。这是最近我们与Yann LeCun(杨立昆)团队合作的一些工作。

我们看近年来生物学和计算机科学的跨学科研究。证明了生物的智能就是具备这样的特征,它们就是这样来组织它们的记忆,而且组织得非常精妙。这是对猴子大脑的研究,可以看到它把记忆组织得非常好,组织成正交子空间,而且是稀疏表达,predict control,通过闭环、反馈控制进行纠错与学习。这些机制在自然界的生物中是普遍存在的。
04
我们离通用智能还有多远?
最后总结一下。
这几年,越来越多的人开始讲“通用智能”,我们的目标好像很明确,也很一致。但,到底要怎么实现呢?计算机科学之所以叫计算机科学,这件事的本质就是和计算问题高度相关的。
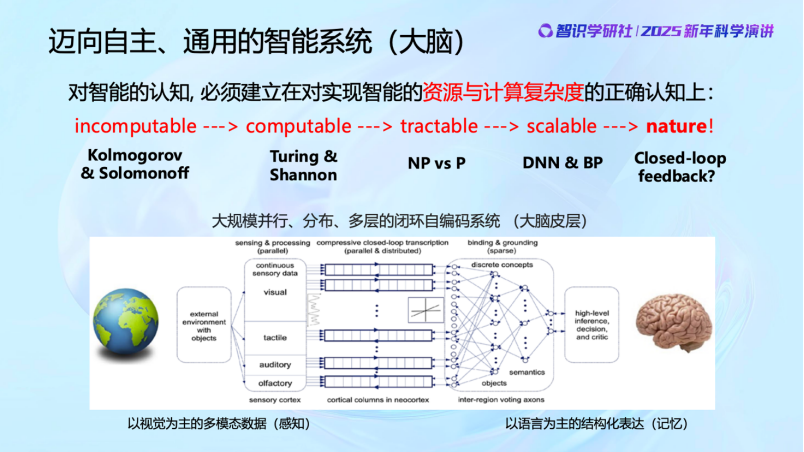
过去80年,人类对的计算的理解一直在演进。从incomputable(不可算)到computable(理论上可算)到tractable(可以通过计算机计算)到scalable(可扩展的计算),一步一步。现在许多人认为智能就是在做压缩,这是完全错误的,因为这件事情它甚至有可能是不可计算的。当然图灵后来定义了可算与不可算。而即使被证明是可计算的,也未必能计算。NP-hard的问题传统计算机算不了。现在DNN(深度神经网络)和BP(反向传播)之所以流行,是因为它们计算复杂度相对较低。但即便如此,自然界也没有同样的资源用类似BP这样的机制来算。我们看现在的大模型,动辄百亿、千亿的参数,能源消耗动不动就要多少个兆瓦。而我们人类大脑的能耗只有十几二十瓦,这中间还差了很多个数量级。自然界不可能这样去浪费算力和资源。
自然界的计算机制到底是怎么样的?其实现在科学界还在不断的探索研究中,现在还并不完全清楚。但已经知道的是——大脑绝对不仅仅是一个大模型,而是由数十万个并行单元组成的,甚至是以多模态的分布式的处理方式来实现的。这和当前流行的把所有内容砸在一个模型中的做法是完全不同的。我们还有很多需要向自然界学习的地方,也希望在探索智这个问题上,面对自然界的时候,大家能够谦虚一点。
今天的大会主题是“AI for science”,我觉得其实还有另外半句,就是 “Science also for AI”。关于智能的科学机制,我们知道的还太少,还有很长的路要走。
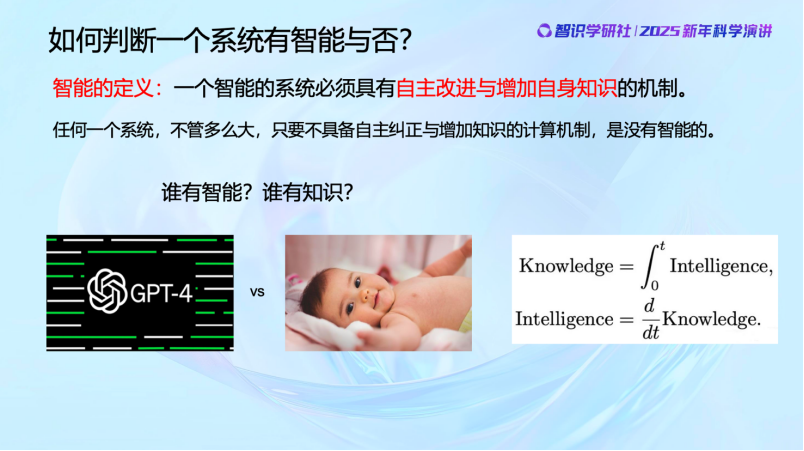
我们看到,今天好像所有人都在谈论智能,但其实对智能一直没有一个明确的科学的定义。这里我们提出一个对智能的定义——真正的智能系统必须具有自主改进和增加自身知识的机制。
任何一个系统,不管它能力多强,储存的知识数据有多庞大,只要不具备自主纠正或增加知识的计算机制,它就是没有智能的。我们经常举的一个例子是 ChatGPT 和一个婴儿,谁更有智能、谁更有知识?显然,GPT虽然拥有大量知识,但按这个标准,它是不具备智能的。一个婴儿虽然知识不多,但通过不断思考与学习,最终可能成为下一个爱因斯坦。某种意义上说,我们认为智能是能够增加知识的,是知识的微分,知识是通过智能活动所积累起来的,它是智能的积分。

我也建议大家,尤其是年轻的研究者和从业人士多深入研究历史。当我们真正理解了人工智能的整个发展历史以后,会发现过去10年所做的事情与50年代定义的“人工智能”其实不是一个东西。当时参加达特茅斯会议的年轻人,其实是想避开维纳和冯·诺依曼等等当时在学术界有着巨大声望的前辈,要在学界证明自己。他们想做和动物层面的感知、预测不一样的智能,研究属于人的独特的智能。50年代图灵提出图灵测试也是。他们想研究人类如何解决符号、抽象问题,这才是当年“人工智能”program 原本想做的事情。
回过头来再看过去十年的智能发展做的事情,我们把它们跟40年代研究的“动物的智能”和50年代提出的“人的智能”要做的事情列出来对比,你可以做下判断,到底离谁更近,离谁更远。
可以说,过去十年做的事,主要还是属于 “Cybernetics”的范畴,而且还没有做全,距离50年代追求的那个“Artificial Intelligence”其实还非常遥远。
05
多一点思想
少一点技术
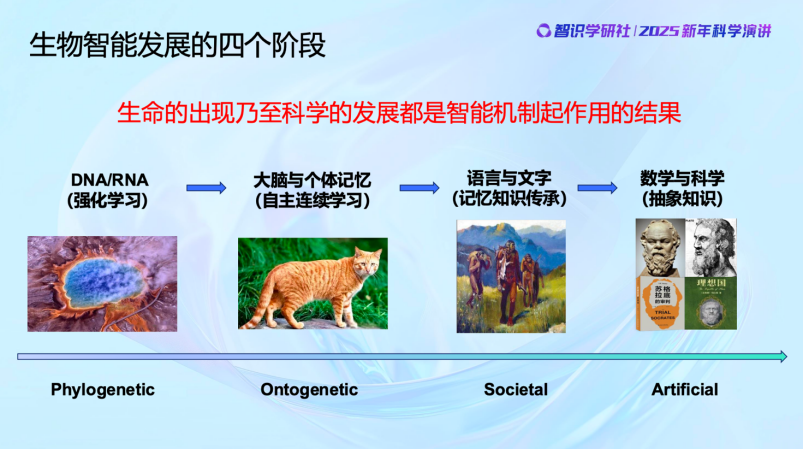
智能不是一个笼统的概念,我们现在必须把它变成一个科学的概念。可以看到,生物智能的发展是有层次的,它们高度相关,但是每一次跃升都会有新的不一样的东西出现。最早的时候是群体的智能,生物群体通过强化学习来实现群体的智能的增长;然后个体智能得到了提升,动物个体能够自适应、反馈闭环、纠错,连续地来进行学习;然后人类诞生了,人类群体中形成了语言,能够交流,能够共同学习,大大提高了人类群体获取外部世界知识的效率,然后文字诞生以后还能把知识再传承下去,从群体智能层面很大程度上取代了DNA的一部分作用;然后,可能是在几千年前也可能更早,我们人类的大脑开始出现新的变化,产生了抽象思维,发展了自然数等概念,产生了数学和科学。这是整个智能的发展过程。
回过头来看,过去几年这么多大模型,是不是真的有数字能力呢?每次新的大模型出来我的学生都会测这个模型有没有数的概念,结果都是没有,包括GPT4o出来以后,还是3.11大于3.9。当然现在他们通过工程师改过来了,但是你换个方式问,3.11还是大于3.9。大家在接受一个新的信息的时候一定要提高警惕,有没有自己做过试验去验证,最后得到第一手的的可信的知识,如果没有,小心一点。
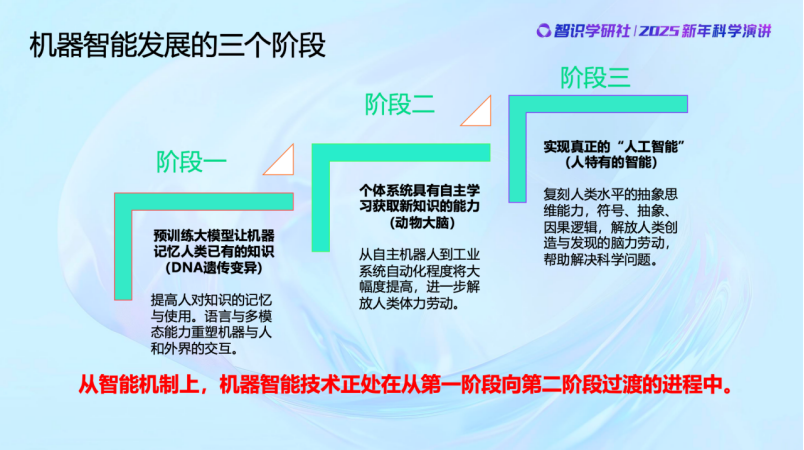
关于机器智能的发展,我个人认为可以分成几个阶段。第一个阶段,预训练大模型,就是模仿DNA,一代一代不同的结构和知识传承下去,百模大战,不好的被淘汰,就是这样,而且进化的机制和方法都很像。第二个阶段,机器智能真正出现个体记忆,自主学习。个体的“大脑”能够有感知,能够自适应,在大模型之外获取新的知识,而且不断改进。目前的机器智能还处于从阶段一迈向阶段二的过渡过程中。我们的团队也在为之努力。至于第三阶段,是真正实现人类水平的思维能力,抽象思维、因果逻辑等等。我个人认为还早,至少现在的智能机制还不太能够做到这些事情。
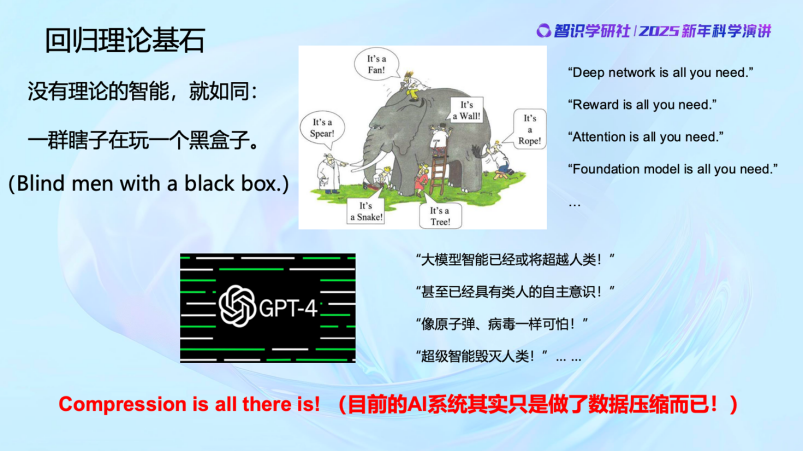
在现在这个时间节点上,理论变得非常重要。智能应该变成了一个科学问题、数学问题和计算问题,一定要科学化。不然大家就会轻易地说出一些奇怪的话来。比如我们经常能看到一些标题党:
“Deep network is all you need.”
“Reward is all you need.”
“Attention is all you need.”
“Foundation model is all you need.”
……
我觉得这样的提法完全是反科学的。但是现在的年轻人可能真的会把这些话当成真理。再往下,更严重的就是“不得了,人工智能马上要超越人了”。那你这个“超越”是什么意义上的“超越”呢?
当然,某种意义上确实超越了。计算机早就在很多地方已经超过人。一个普通的家用计算器,在算数、开根号方面那早就超过人了。但大家对这些事情要有本质的理解,不要泛泛去讲。
现在媒体上动不动就能看到,说人工智能未来要毁灭人类了。说实话我很反感这些耸人听闻的说法。因为我们清楚地知道,至少目前的系统还没有超出对数据进行压缩和编码的范畴。

从方法论上,科学研究往往依托于两个基本方法,一个是归纳法,一个是演绎法,这两者都有它的作用,比如实验物理,理论物理等等,相辅相成。过去十年,机器智能在技术上面突飞猛进,归纳出了很多好的经验,这期间的发展靠的主要是归纳法;但是我希望今后的十年,如果要把智能研究变成科学的问题,数学的问题,应该要有很好的数学理论框架。就像我们计算机学的泰斗Donald Knuth讲的,“The best theory is inspired by practice, the best practice is inspired by theory” 。我们过去十多年积累了那么多的practice,现在就是呼唤英雄的时代,大道至简,需要去找到智能的理论框架,去探索它的基本原理和思想。多一点思想,少一点技术。
谢谢大家!