去年底,我们写了一篇笔记, 《2024年,DeepSeek带给硅谷“苦涩的教训”》,提出了一个观点,相比圣诞前OpenAI的连续12天线上发布会,DeepSeek-V3的发布,才是当年真正的压轴戏。
没想到这篇文章引发了一阵狂炒。DeepSeek-R1推理模型就在特朗普就职日那天发布,性能基本超过了GPT-4o,媲美OpenAI-o1,成本仅为其十分之一到二十分之一。这次不仅让硅谷懵逼,而且让华尔街也不安起来。
尤其是特朗普宣布了任期内投资5000亿美元AI基础设施的 星际之门计划,由软银、OpenAI和甲骨文操盘,微软、英伟达、ARM等为技术伙伴,更是把美国的AI发展的资本+算力模式推到了一个新的高度,还不用说其他科技巨头每年高达数千亿的资本支出主要投向AI。但DeepSeek以高效的训练和推理,让砸钱搞GPU军备竞赛的AI发展模式开始遭到一些质疑,建立在这一基础之上的AI概念公司,无论在一级市场,还是在二级市场,都面临着一次估值的拷问。
相比之下,DeepSeek正在探索一条中国式的AI发展之路,我们在 对2025年AI的十个展望中,第一条就提出来,中国将参与基础模型的创新,而不仅仅是跟随。辞旧迎新之际,我们再度对DeepSeek进行一次”模式“级别的梳理,分下面四个部分:
1,深度求索有深度
2,萤火和R1论文
3,DeepSeek冲击
4,改写AI游戏规则
深度求索有深度
DeepSeek远远不像是许多介绍的、尤其是海外报道和传说中的那样,是一家仅成立一年多的AI公司。实际上它脱胎于幻方量化基金,这是一家已经创办了17年的、有数学、计算、研究和AI基因的对冲基金。
2008年,浙江大学学习信息与通信工程的梁文锋创立了幻方量化,直到2014年,在幻方量化的初创阶段,团队从零开始探索全自动化交易。
2015年才是幻方自认为的创始元年,真正依靠数学与人工智能进行量化投资。“创始团队意气风发、勇于创新、勤勉奋进,立志成为世界顶级的量化对冲基金。”2016年,幻方第一个AI模型建立的股票仓位上线实盘交易,算力开始从CPU转向GPU。至 2017 年底,几乎所有的量化策略都已经采用 AI 模型计算。
作为一家对冲基金,幻方开始确立以 AI 为公司的主要发展方向。但是, 复杂的模型计算需求使得单机训练遭遇算力瓶颈,同时日益增加的训练需求和有限的计算资源产生了矛盾,2018年,幻方的AI团队开始寻求大规模算力解决方案。
其实2019年可能是幻方大模型之路的起点,这一年,幻方AI(幻方人工智能基础研究有限公司)注册成立,致力于 AI 的算法与基础应用研究。AI 软硬件研发团队自研幻方“萤火一号”AI集群,搭载了500块显卡,使用 200Gbps 高速网络互联。一年之间,“萤火一号”总投资近2亿元,于2020年正式投用,满血搭载1100块加速卡,为幻方的AI研究提供算力支持。
幻方AI很快又投入10亿元建设萤火二号。2021年,萤火二号一期确立以任务级分时调度共享AI算力的技术方案,从软硬件两方面共同发力:高性能加速卡、节点间 200Gbps 高速网络互联、自研分布式并行文件系统(3FS)、网络拓扑通讯方案(hfreduce)、算子库(hfai.nn),高易用性应用层等,将萤火二号的性能发挥至极限。
到了2022年,ChatGPT时刻前夕,幻方已经成为国内一家领先的AI公司,而且手中握有上万块英伟达A100卡和一定数量的AMD卡。萤火二号取得了多800口交换机互联加核心扩展子树的软硬件架构革新,突破了一期的物理限制,算力扩容翻倍。新的hfai框架让模型加速50-100%。集群连续满载运行,平均占用率达到96%以上。全年运行任务135万个,共计5674万 GPU 时。用于科研支持的闲时算力高达1533 万GPU 时,占比27%。
从中可以推算出,在2022年,幻方已经平均每天用4.2万GPU时,相当于每天有近2000张GPU卡在几乎满负荷跑科研而不是交易。如果按照当时A100每小时云服务的市场价,相当于每年在科研方面投入2亿元人民币。这样规模的AI研究,在当时的国内处于领先状态,在当时的国际上巨头之外的AI初创公司中,也算得上是领先的。
2023年4月11日,开源模型Llama1和GPT-4和相继发布之后,幻方宣布做大模型,2023年5月把技术部门做大模型的团队独立出来,成立深度求索公司,进军通用人工智能AGI。
所以,如果从深度求索公司成立算起,DeepSeek还不满2年;但是如果从成立幻方AI算起,已近5年;再从2016第一个AI股票仓位模型上线交易算起,已近10年。
当2018年,幻方确立以AI为公司的主要发展方向时,就已经注定了它将是一家AI技术公司,而对冲基金是其当时主要的应用。
我们可以看到,量化投资与AI研究,构成了幻方基因的双螺旋结构。2019年,幻方跻身百亿私募,这一年,幻方AI成立,并且开始独立构建萤火集群。2021年,幻方管理基金规模一度超过千亿元,它开始构建更大更复杂的算力集群萤火二号。幻方的基金管理业务最辉煌的是2019年和2020年,自然年收益分别为58.69%和70.79%,此后因为行业等方面的原因,量化发展一蹶不振,但幻方作为一家AI公司凸显出来。
如果对比成立于2010年的DeepMind和成立于2015年的OpenAI,作为创业公司,幻方与其处于同一时代。DeepMind和OpenAI创立时都是纯粹的AI实验室,以实现通用人工智能(AGI)为使命,而且在这场深度学习革命中起到了先锋作用,从AlphaGo、AlphaFold到ChatGPT,都是革命性的技术与产品。相比之下,幻方AI一直在复刻研究其成果,直到成立深度求索,推出DeepSeek大模型。从这一点来说,DeepSeek取得的成就,是站在巨人的肩膀上。
从AI交易模型到幻方AI,再到DeepSeek,推动了幻方的对冲基金业务的同时,也一步一步从业务部门独立出来,并逐步重新定义幻方这家公司。幻方AI的发展离不开对冲基金业务的支持。进行长期的AI研究,离不开资金与算力资源的强有力支持。DeepMind最后被谷歌收购,作为一家独立的公司,它一直亏损,但作为一家AI研究实验室,在谷歌内部的作用是战略性的。
我在2017年采访DeepMind创始人哈萨比斯时,他告诉我说,谷歌收购DeepMind,就是为了推动从移动第一到AI第一的战略转型。在ChatGPT之后,谷歌更是对其内部显得杂乱的AI研发和业务进行了整合,全部 归并到DeepMind旗下。
同样,OpenAI也从非营利改组为营利。其中微软先后投资达140亿美元,对于OpenAI能持续以大算力推进Scaling Law (扩展定律),以大资金和高估值吸引全球顶尖人才,成为一家生成式人工智能的领军企业,发挥了至关重要的作用。
对于所有的技术公司来说,AI大模型将成为其技术底座,也将重构所有企业的IT和软件部门,这可以部分解释为什么一个企业内生的AI能力,强大到一定程度,有可能定义出企业新的增长曲线。
从2019年幻方开始构建萤火一号开始,就注定了它走上了一家AI公司的轨迹。2021年,幻方构建萤火二号,在亚太第一个拿到A100卡,在ChatGPT之后,幻方成为全国少数几家拥有上万张A100 GPU的机构。投资十多亿元构建万卡级算力级群,这不会是仅仅用于炒股。
而硅谷和Alex王和Dylan Patel等,在DeepSeek-3V推出之后,更是相信DeepSeek拥有5万块H100。不管怎么说,在DeepSeek做研究,应该是中国实现GPU自由的地方。
DeepSeek与DeepMind和OpenAI一样追求人才密度,所不同的是,后两者吸收了全球最优秀的AI人才,而前者目前只吸收了国内最优秀的人才。记得当时我采访哈萨比斯时问过同样的问题,他回答说:DeepMind吸引了全球60多个国家顶尖的博士生和科学家。
DeepSeek从一家对冲基金的技术研究部门,逐步将其母体转变为一家AI公司,这是一个非常特殊的例子。对冲基金和AI技术都来自美国,但无论是华尔街的对冲基金、还是从华尔街海归做量化的团队,没有一个能像幻方这样,进化出一个做通用AI大模型的核心能力,例如,彭博曾经很早推出了BloombergGPT大模型,然后就没有然后了。从这一点上来说,DeepSeek这个本土团队是独特的,没有“模式”可谈。
但是,DeepSeek也蹚出了一条路,可能用500万美元、千张GPU卡训练出高性价比的模型,这让许多在巨头面前感到绝望、纷纷放弃预训练的初创AI企业,开始重新思考它们的战略,从这一点来说,DeepSeek开创了一种“模式”。
萤火和R1论文
2024年,DeepSeek一口气发布了从V1到V3三个基础模型版本,全部开源,如果看其研究部门之前几年发的论文和技术博客,可以理解这也是厚积薄发的结果。我们在去年底的文章里介绍了DeepSeek的8篇论文,这里再补充介绍两篇。一篇是被国际AI界广泛赞誉为2025年最迄今为止最佳论文的R1。
它的亮点包括:对基础模型直接上强化学习,而不是先用收集起来非常耗时的监督数据进行训练;采用了群体策略相对优化(GRPO),强化学习训练的成本和复杂性都得到了显著降低,同时保持了较好的性能表现;还蒸馏了6个Qwen和Llama的小模型,用起来更加节省,而且针对领域的性能更加强大;特别是DeepSeek-R1-Distill-Qwen-1.5B在数学基准测试中优于GPT-4o和Claude-3.5 Sonnet。它可以装到一个手机里。
这里要特别提及论文中有一段,用散文化的语言,描述了在训练过程中出现的模型自我“顿悟”的时刻:
“在DeepSeek-R1-Zero的训练过程中,观察到一个特别有趣的现象,即“顿悟时刻”(aha moment) 的出现。这一时刻出现在模型的中间版本中。此时,DeepSeek-R1-Zero学会了重新评估其初始方法,为问题分配更多的思考时间。这种行为引人入胜,不仅证明了模型推理能力的提升,也例证了强化学习如何带来意外且复杂结果。
这不仅是模型的‘顿悟时刻’,也是研究人员的‘顿悟时刻’,他们观察到了强化学习的力量与美感:我们并未明确教导模型如何解决问题,而是为其提供了正确的激励,使其自主发展出高级的问题解决策略。‘顿悟时刻’有力地提醒我们,强化学习有潜力在人工系统中解锁新的智能水平,为未来更自主和自适应的模型铺设道路。”

一个有趣的“顿悟时刻”出现在DeepSeek-R1-Zero的中间版本中。该模型学会了以拟人化的语气重新思考。这对我们来说也是一个顿悟时刻,让我们见证了强化学习的力量与美感。(来源:DeepSeek R1论文)
如何构建一个高效的万卡算力集群?DeepSeek发布于2024年8月的论文,介绍了高性价比的萤火AI-HPC架构,提出了深度学习的软件与硬件一体化设计的理念。按姓氏拼音字母,创始人梁文锋排在第17位作者。
这篇论文总结了构建萤火二号的经验,配备10,000个PCIe A100 GPU,其性能接近英伟达的DGX-A100,同时将成本降低了一半,能耗减少了40%。
DeepSeek团队特别设计了HFReduce以加速allreduce通信,并实施了多项措施以确保计算-存储一体化网络无拥塞。通过我们的软件堆栈(包括HaiScale、3FS和HAI-Platform),还通过重叠计算和通信实现了显著的扩展性。
从中可以看出,DeepSeek的策略,是用接近最先进的大模型和基础设施的性能,设计出远超其接近性的高性价比的产品,参与国际大模型竞争。
DeepSeek冲击
DeepSeek-R1已经成为MIT和斯坦福美国顶尖高校研究人员的首选模型。甚至有研究人员表示,它已经代替了ChatGPT。其实最大的受益者,应该是中国用户,它让美国在大模型上对中国的卡脖子基本无效了,中国大多数用户以后可以用上和美国基本相当的AI模型和应用。
全球最大开源平台HuggingFace团队,也正式宣布复刻DeepSeek-R1所有pipeline。完成之后,所有的训练数据、训练脚本等,亦将全部开源。DeepSeek已飙升至 HuggingFace 上下载量最多的模型,仅R1下载已经超过13万次(本文截稿时为止),蒸馏小模型如Qwen 32B 和1.5B,也都名列前茅。
DeepSeek-R1激起了开发人员极大的热情,社交媒体和社区网站上,大家兴奋地分享着自己的尝试,并交流着对他们的 AI 开发意味着什么。用户评论说,DeepSeek的搜索功能现在优于 OpenAI 和 Perplexity ,只有 Google 的 Gemini Deep Research 可以与之匹敌。
尤其是在基础模型上直接强化学习,成为众多AI实验室及研究人员纷纷采用的新范式,为了过程中追求DeepSeek的那一“呵哈时刻”,港科大助理教授何俊贤团队,只用了8K个样本,就在7B模型上复刻出了DeepSeek-R1-Zero和DeepSeek-R1的训练。
一些团队证明,采用了R1-Zero算法——给定一个基础语言模型、提示和真实奖励信号,运行强化学习,小到1.5B的开源模型,应用于一些游戏当中,都能复现出解决方案、自我验证、反复纠正、直到解决问题为止。1.5B模型更是可以下载到手机上,在数学等性能上,相当于拥有了一个性能相当GPT-4o和Claude 3.5 Sonnet的最先进闭源模型。
美国的主流商业、财经、甚至综合时政媒体,也开始报道DeepSeek现象。CNBC对AI独角兽Perplexity创始人CEO Aravind Srinivas的专访,从一个技术产业专家的角度,对DeepSeek V3的亮点进行了点评:
需求是创新之母。正因为他们必须寻找变通方案,他们最终建造出了一个效率更高的系统。“除非在数学上能证明这是不可能的,否则你总能想出更有效率的方案。”
性价比。“他们推出了一个成本比GPT-4低10倍、比Claude低15倍的模型。运行速度很快,达到每秒60个token。在某些基准测试中表现相当或更好,某些则稍差,但总体上与GPT-4水平相当。更令人惊讶的是,他们仅用了大约2048个H800 GPU,相当于1000-1500个H100 GPU,总计算成本仅500万美元左右。这个模型免费开放,并发布了技术论文。”
巧妙的技术解决方案。“首先,他们训练了一个混合专家模型(Mixture of Experts),这并不容易。人们难以追赶OpenAI,特别是在MOE架构方面,主要是因为存在大量不规则的损失峰值,数值并不稳定。但他们提出了非常巧妙的平衡方案,而且没有增加额外的技术修补。他们还在8位浮点训练方面取得突破,巧妙地确定了哪些部分需要更高精度,哪些可以用更低精度。据我所知,8位浮点训练的理解还不够深入,美国的大多数训练仍在使用FP16。”
Perplexity 已经开始使用DeepSeek。他们提供API,而且因为是开源的,我们也可以自己部署。使用它可以让我们以更低的成本完成许多任务。但我在想的是更深层的问题:既然他们能训练出如此优秀的模型,这对美国公司来说,包括我们在内,就不再有借口说做不到这一点了。
DeepSeek-R1开源,已经逼得o3 mini免费!
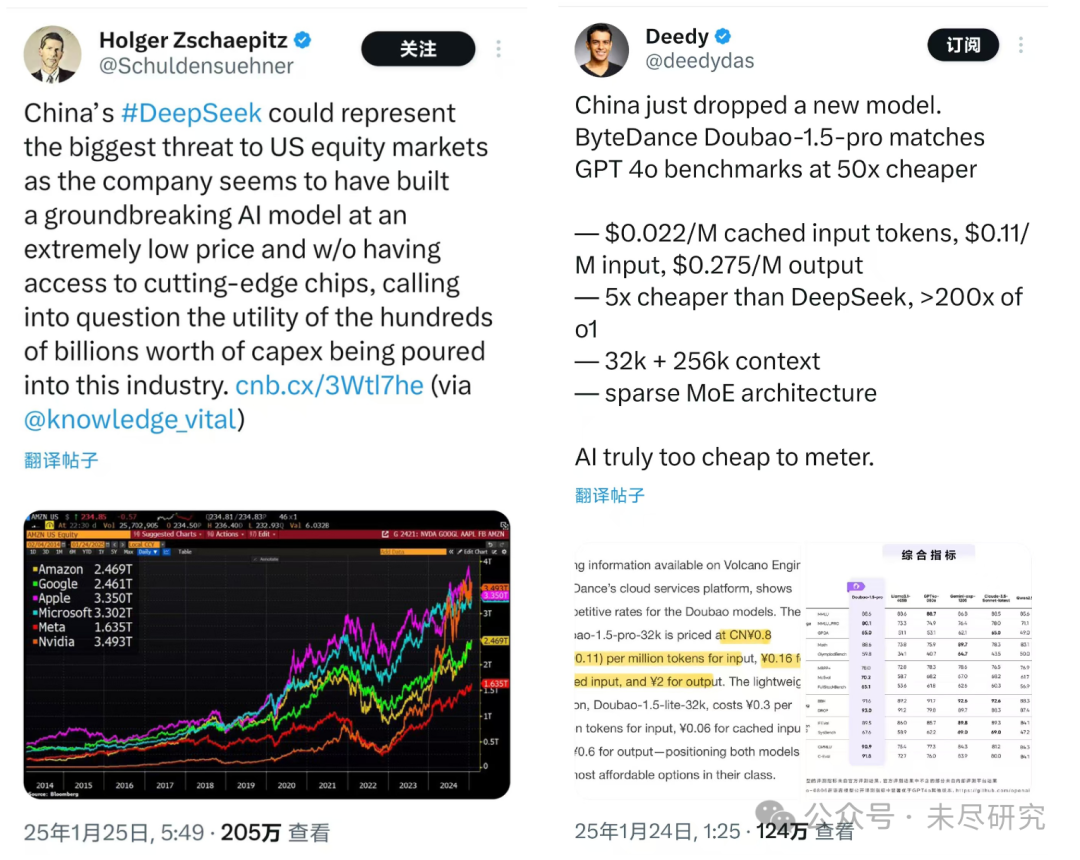
从硅谷到华尔街,分析人士已经开始思考,DeepSeek可能对热炒AI的美国资本市场,从一级到二级,会带来多大的影响。中国企业地板价的AI服务,会不会冲击美科技巨头的估值,AI相关基础设施的投资规模,等等。科技巨头每年巨额的AI资本支出,短期内是否值得。美国AI概念股,是否需要来一次重新估值呢?而中国的AI概念股,是否也需要来一次重新估值呢?有人开玩笑说,DeepSeek背后的幻方量化,在发布V3、R1的同时,幻方可以建立起做空美国AI概念股的策略。
DeepSeek也在改变硅谷的AI初创企业估值,让风险资本多数不约而同站在DeepSeek一边,他们找到了杀价初创公司的最好理由:我pre-A给你500万美元,你能干出点啥?看看人家的孩子,看看DeepDeek!
难道你们都把钱用来买OpenAI的服务了吗?现在不是有DeepSeek,便宜10倍到20倍呵!而且,紧接着DeepSeek,字节的豆包-1.5-pro也推出了,比DeepSeek便宜5倍,比o1最多便宜200倍!
就连OpenAI刚刚推出的智能体Operator,只有月费200美元的订户才能使用,但是,用DeepSeek可以做出同样好的开源免费版本,而且已经有四五个了。
AMD反应很敏锐,已经把DeepSeek-V3集成到了Instinct MI300X GPU上。
用DeepSeek,还出现了一些新的玩法:如RAT,( retrieval angment thinking),把R1的推理过程,嫁接到任何一个大型语言模型上,可以显著提升其性能,并获得函数调用和JSON模式。
这位小哥在用DeepSeek开发了一个研究智能体。
不过也有一些研究人员表示,DeepSeek 模型在跟踪长时间对话的背景等方面,其能力与花费更高的竞争对手模型相比,还有欠缺。
改写AI游戏规则
这次杨立昆最有话说。“与其说是中国正在超越美国AI,不如说是开源正在超越闭源AI。”
开源与闭源
面对美国的封锁和巨头的军备竞赛,中国的一些AI企业选择了一条不同的道路——开源。较低的成本可以做出优秀可用的推理模型,而且好的模型转化为更“杀手”的应用,似乎是更有效的路径。DeepSeek没有在应用方面花一分钱推广,但它已经在国内和国际的各大应用商店占据榜首。这让一些AI“小龙”们重新思考,回归技术,拥抱开源,如最近MiniMax果断转向开源。

开源能够汇聚全球社区的力量,加速大模型的研发和应用创新。开源模型更容易被广泛采用,尤其是在算力和人才资源有限的国家和行业。 通过开源,中国有机会在全球AI领域建立自己的技术标准。开源模型(如DeepSeek、阿里Qwen等)以高性价比著称,有助于推动AI技术的普惠化,将AI技术推广到全球南方国家,
DeepSeek会影响众多企业AI战略。随着成本降低和开放访问,企业现在可以选择替代昂贵的专有模型,例如OpenAI。DeepSeek的发布可能会使前沿AI 功能的访问变得民主化,使较小的企业能够在 AI 军备竞赛中有效竞争。
Aravind Srinivas进一步指出了为什么美国地精英阶层开始产生的担忧更具战略意义:“比起试图阻止他们(中国AI企业)追赶,更危险的是他们现在拥有最好的开源模型,而所有美国开发者都在使用它进行开发。这更危险,因为这意味着他们可能会掌握整个美国AI生态系统的心智。历史告诉我们,一旦开源赶上或超越闭源软件,所有开发者都会转向开源。”
中国与美国
在美国对中国实施芯片封锁的背景下,DeepSeek展现了一种真正的创新——需求推动的创新。中国企业在仅能从中国本土企业获得比美国落后一两代GPU条件下,依然能够开发出优秀的基础模型。这种创新不仅仅依赖于GPU和资本的军备竞赛,而是通过算法、架构和工程的创新实现了突破。
关于OpenAI的护城河问题,2023年5月,在Meta发布了Llama开源模型后不久,谷歌内部即有人提出,我们没有护城河,OpenAI也没有。
今天,是这一问题再次提出的时候了。首先是OpenAI的护城河在哪里。随着AI技术进入实际应用领域,性价比成为关键因素,而非单纯追求最先进的模型。OpenAI等公司投入数十亿甚至上百亿美元进行预训练和基础设施建设,但如果其技术护城河不够深,其商业模式将面临挑战。这种高投入的模式是否可持续,成为从硅谷到华尔街令人感到焦虑的问题。
DeepSeek已经证明,美国无法在 AI 领域获取绝对的竞争优势,甚至那些科技巨头都无法取得绝对的优势。
应该看到,以AI发展的全栈技术来看,中国与美国依然有明显的差距。越往底层走,差距越明显。在AI芯片领域,从GPU到HBM,中国自主技术的差距在两代到三代。而这一轮AI创新的一个突出特征,是科技巨头主导的,它们拥有自制芯片(ASIC)、数据中心、云计算、AI平台及工具链、操作系统、杀手级应用,建立起全栈技术的垂直整合体系,其中尤以亚马逊、微软、谷歌这三大云服务巨头为代表。
OpenAI也在向一家AI科技巨头演变,它依然拥有强大的技术能力和品牌影响力。它正在从基础模型向上下游扩展,建立起自己的应用芯片团队和数据中心,加快布局基于推理模型的智能体,并全面探索其商业模式,如果昂贵的而又尖端的推理和智能体技术,最终证明能解决复杂和有价值的问题,在性价比上依然拥有强大的竞争力。
Srinivas认为Meta仍然会开发出比DeepSeek 3更好的模型,“不管他们叫它Llama 4还是3点几”。他特别强调了Meta在开源领域的贡献:“实际上,Meta的Llama 3.3技术报告非常详细,对科学发展很有价值。他们分享的细节已经比其他公司多得多了。”相比之下,DeepSeek的技术报告没有公布训练数据来源。
Srinivas认为,与其担心中国的追赶,更重要的是保持创新势头,继续推动技术进步。“我们不应该把所有精力都集中在禁止和阻止他们(中国AI企业)上,而是要努力在竞争中胜出。这才是美国人做事的方式——就是要做得更好。”
对攻的比赛更精彩。蛇年让我们期待Llama 4,Grok 3,也期待 OpenAI-o4, Claude-4, 还有Gemini-2.5或者3,甚至GPT-5。