来源:赛博禅心
就在刚刚,美国的另一家 AI 巨头 Anthropic 的 CEO - Dario Amodei 发表了一篇长达万字的深度分析报告。报告核心观点:DeepSeek 的突破,更加印证了美国对华芯片出口管制政策的必要性和紧迫性。

先补充下前提,这几天,DeepSeek 刷屏、刷屏、再刷屏。
并在新春之际,给欧美股市带来了一抹中国红(暴跌)
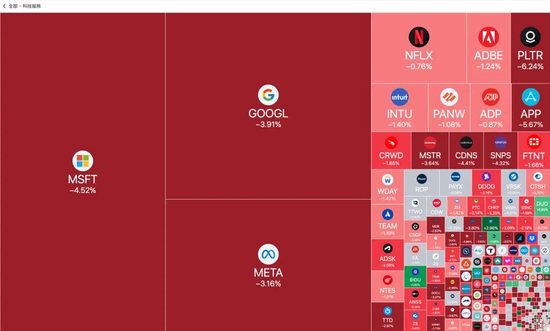
赛博禅心在此前也通过多个纬度,对此进行了一系列报道:
-
DeepSeek 完全指南:这到底是怎样的存在?
-
DeepSeek-V3 是怎么训练的|深度拆解
-
DeepSeek-R1 是怎么训练的|深度拆解
-
DeepSeek 再度开源:用 Janus-Pro 撕开算力铁幕
顺道着...昨天凌晨,Qwen 也发了大货:
金色传说大聪明,公众号:赛博禅心春晚硬科技盘点:我很少用‘浪漫’形容一场绽放
我们回过头来看看 Dario Amodei 这篇报告,里面首先肯定了 DeepSeek 的技术突破:其最新模型在特定基准测试中已逼近美国顶尖水平,模型训练效率提升显著,并尝试将中国 AI 进步纳入全球技术演进坐标系进行定位,从三个维度:
-
算力规模定律: 指出中国超大规模算力基建的持续投入,正在重塑全球 AI 研发的地缘格局。国家级数字基础设施的战略布局,为中国企业突破“算力鸿沟”提供了底层支撑。
-
效率跃迁曲线: 强调全球 AI 行业正经历训练成本指数级下降的技术革命。DeepSeek 的成本控制突破,本质上是把握技术演进窗口期的战略成果。
-
范式革新动能: 着重分析中国团队在强化学习等新兴训练范式中的创新实践,揭示后发者通过技术路线创新实现弯道超车的可能性。
基于此,Dario Amodei 的结论颇具启示性:DeepSeek 的突破绝非孤立现象,而是中国科技创新体系系统性进化的产物。尽管报告刻意淡化“颠覆性创新”的叙事,但字里行间对中国 AI 发展势能的警惕已跃然纸上。
在政策维度,报告剑指芯片出口管制的战略困境。Dario Amodei 坦承,DeepSeek 的突破正在倒逼美国重新评估技术封锁政策的有效性。这种政策层面的连锁反应,恰印证了中国 AI 突围对全球技术秩序的重构效应。其核心论断直指要害——算力霸权已成为 AI 竞赛的胜负手,而中国在自主可控产业链建设方面的进展,正在动摇传统技术封锁的逻辑基础。
报告同时指出,在国家安全与技术发展间,需要寻求动态平衡,这也是当下全球的时代命题:当技术演进速度,已超越政策调整速度,如何在开放与风控中建立新范式,已成为关键中的关键。
需要说一下,Dario Amodei 是前 OpenAI 的研究员,后来离开 OpenAI 后成立其直接竞争对手 Anthropic。这篇报告在保持学术矜持的表象下,已然承认中国 AI 崛起的事实,也预示着创新格局正在发生范式转变——从单一中心的技术辐射,向多极共生的生态演进。
文章发布在 Dario Amodei 的个人博客:https://darioamodei.com/on-deepseek-and-export-controls
我把它也翻译成了中文,如下:
关于 DeepSeek 与出口管制
几周前,我曾撰文呼吁美国应加强对华芯片出口管制。此后不久,中国人工智能公司 DeepSeek 便成功地——至少在某些方面——以更低的成本,实现了与美国顶尖人工智能模型相近的性能水平。
在此,我暂且不讨论 DeepSeek 是否对 Anthropic 等美国人工智能企业构成威胁(尽管我认为许多关于 DeepSeek 威胁美国人工智能领导地位的说法被严重夸大了)。
我更关注的是,DeepSeek 的成果发布是否削弱了芯片出口管制政策的合理性。我的看法是否定的。事实上,我认为 DeepSeek 的进展反而令出口管制政策显得比一周前更具存在意义上的重要性。
出口管制服务于一个至关重要的目标:确保民主国家在人工智能发展中保持领先地位。需要明确的是,出口管制并非逃避美中竞争的手段。最终,如果美国和其他民主国家的 AI 公司想要胜出,就必须开发出比中国更卓越的模型。但是,在力所能及的情况下,我们不应将技术优势拱手让给中国。
人工智能发展的三大动态
在阐述我的政策主张之前,我将先介绍理解人工智能系统至关重要的三个基本动态:
规模定律 (Scaling laws)。 人工智能的一个特性——我和我的联合创始人在 OpenAI 工作时就率先记录了这一特性——即在其他条件相同的情况下,扩大人工智能系统的训练规模,能够全面且平滑地提升其在各种认知任务上的表现。
例如,一个耗资 100 万美元的模型可能解决 20%的重要编程任务,一个耗资 1000 万美元的模型可能解决 40%,一个耗资 1 亿美元的模型可能解决 60%,以此类推。这些差异在实践中往往具有巨大的影响——十倍的性能提升可能相当于本科生和博士生技能水平之间的差距——因此,各公司都在大力投资于训练这些模型。
曲线偏移 (Shifting the curve)。 人工智能领域不断涌现各种大大小小的创新理念,旨在提高效率或效能。这些创新可能体现在模型架构的改进上(例如对当今所有模型都采用的 Transformer 基础架构进行微调),也可能仅仅是更高效地在底层硬件上运行模型的方法。
新一代硬件的出现也具有相同的效果。这些创新通常会使成本曲线发生偏移:如果某项创新带来了 2 倍的“算力倍增效应”(CM),那么原本需要花费 1000 万美元才能完成 40%编程任务,现在只需 500 万美元即可实现;原本需要 1 亿美元才能完成 60%的任务,现在只需 5000 万美元,以此类推。每一家前沿人工智能公司都会定期发现许多这样的算力倍增效应:小型创新(约 1.2 倍)时有发生,中型创新(约 2 倍)也偶有出现,而大型创新(约 10 倍)则较为罕见。
由于拥有更智能系统的价值极高,这种曲线偏移通常会导致公司在模型训练上投入更多而非更少的资金:成本效率的提升最终完全用于训练更智能的模型,唯一制约因素仅为公司的财务资源。人们自然而然地倾向于“先贵后贱”的思维模式——仿佛人工智能是一种质量恒定的单一事物,当它变得更便宜时,我们就会用更少的芯片来训练它。但关键在于规模曲线:当曲线偏移时,我们只是更快地沿着曲线前进,因为曲线尽头的价值实在太高了。
2020 年,我的团队发表了一篇论文,指出算法进步带来的曲线偏移约为每年 1.68 倍。此后,这个速度可能已显著加快;而且这还没有考虑效率和硬件的进步。我估计今天的数字可能约为每年 4 倍。此处还有另一项估计。训练曲线的偏移也会带动推理曲线的偏移,因此,多年来,在模型质量保持不变的情况下,价格大幅下降的情况一直都在发生。例如,Claude 3.5 Sonnet 的 API 价格比原版 GPT-4 低约 10 倍,但其发布时间比 GPT-4 晚了 15 个月,且在几乎所有基准测试中都优于 GPT-4。
范式转变 (Shifting the paradigm)。 有时,被规模化的底层事物会发生细微变化,或者在训练过程中会加入一种新的规模化方式。在 2020 年至 2023 年期间,主要的规模化对象是预训练模型:即使用越来越多的互联网文本进行训练,并在其基础上进行少量其他训练的模型。
2024 年,使用强化学习(RL)训练模型生成思维链的想法已成为新的规模化重点。Anthropic、DeepSeek 和许多其他公司(或许最引人注目的是 OpenAI,他们在 9 月份发布了 o1-preview 模型)都发现,这种训练方式极大地提高了模型在某些特定、可客观衡量的任务上的性能,例如数学、编程竞赛以及与这些任务相似的推理。这种新范式包括首先使用普通的预训练模型,然后在第二阶段使用强化学习来添加推理技能。
重要的是,由于这种类型的强化学习是全新的,我们仍处于规模曲线的早期阶段:所有参与者在第二阶段(强化学习阶段)的投入都很少。投入 100 万美元而不是 10 万美元就足以获得巨大的收益。各公司目前都在迅速努力将第二阶段的投入规模扩大到数亿美元甚至数十亿美元,但至关重要的是要理解,我们正处在一个独特的“交叉点”,即存在一种强大的新范式,它正处于规模曲线的早期阶段,因此可以迅速取得重大进展。
DeepSeek 的模型
上述三个动态可以帮助我们理解 DeepSeek 近期发布的模型。大约一个月前,DeepSeek 发布了一个名为“DeepSeek-V3”的模型,这是一个纯粹的预训练模型——即上述第三点中描述的第一阶段。上周,他们又发布了“R1”,在 V3 的基础上增加了第二阶段。从外部无法完全了解这些模型的全部信息,但以下是我对这两次发布的最佳理解。
DeepSeek-V3 实际上是真正的创新所在,一个月前就应该引起人们的注意(我们当然注意到了)。作为一款预训练模型,它在某些重要任务上的表现似乎已接近美国最先进的模型水平,但训练成本却大大降低(不过,我们发现,特别是 Claude 3.5 Sonnet 在某些其他关键任务上,例如实际编程方面,仍然明显更胜一筹)。DeepSeek 团队通过一些真正令人印象深刻的创新实现了这一点,这些创新主要集中在工程效率方面。特别是在名为“键值缓存 (Key-Value cache)”的某一方面管理以及推动“混合专家 (mixture of experts)”方法更进一步的应用上,取得了创新性的改进。
然而,有必要进行更深入的分析:
DeepSeek 并未“以 600 万美元的成本实现了美国人工智能公司数十亿美元投入的效果”。我只能代表 Anthropic 发言,Claude 3.5 Sonnet 是一款中等规模的模型,训练成本为数千万美元(我不会给出确切数字)。此外,3.5 Sonnet 的训练方式与任何规模更大或成本更高的模型无关(与某些传言相反)。Sonnet 的训练是在 9-12 个月前进行的,而 DeepSeek 的模型是在 11 月/12 月训练的,但 Sonnet 在许多内部和外部评估中仍然显著领先。因此,我认为一个公正的说法是:“DeepSeek 生产出了一款性能接近美国 7-10 个月前模型的模型,成本大幅降低(但远未达到人们所说的比例)”。
如果成本曲线的历史下降趋势约为每年 4 倍,这意味着在正常的商业进程中——在 2023 年和 2024 年发生的历史成本下降等正常趋势下——我们预计现在会出现一款比 3.5 Sonnet/GPT-4o 便宜 3-4 倍的模型。
由于 DeepSeek-V3 的性能不如那些美国前沿模型——假设在规模曲线上落后约 2 倍,我认为这对于 DeepSeek-V3 来说已经相当慷慨了——这意味着,如果 DeepSeek-V3 的训练成本比美国一年前开发的现有模型低约 8 倍,那将是完全正常、完全符合“趋势”的。我不会给出具体数字,但从前一点可以清楚地看出,即使你完全相信 DeepSeek 宣称的训练成本,他们的表现充其量也只是符合趋势,甚至可能还达不到。例如,这远不如最初的 GPT-4 到 Claude 3.5 Sonnet 的推理价格差异(10 倍),而 3.5 Sonnet 是一款比 GPT-4 更出色的模型。
总而言之,DeepSeek-V3 并非一项独特的突破,也并非从根本上改变了大型语言模型 (LLM) 的经济性;它只是持续成本降低曲线上一个预期的点。这次的不同之处在于,第一个展示预期成本降低的公司是中国公司。这在以前从未发生过,并且具有地缘政治意义。然而,美国公司很快也会效仿——而且他们不会通过复制 DeepSeek 来做到这一点,而是因为他们也在实现通常的成本降低趋势。
DeepSeek 和美国人工智能公司都比以往拥有更多的资金和更多的芯片来训练其明星模型。额外的芯片用于研发支持模型背后的理念,有时也用于训练尚未准备就绪(或需要多次尝试才能成功)的更大模型。有报道称——我们无法确定其真实性——DeepSeek 实际上拥有 50,000 块 Hopper 架构的芯片,我猜这与美国主要人工智能公司拥有的芯片数量在 2-3 倍的差距内(例如,比 xAI 的 “Colossus” 集群少 2-3 倍)。这 50,000 块 Hopper 芯片的成本约为 10 亿美元。因此,DeepSeek 作为一家公司的总支出(与训练单个模型的支出不同)与美国人工智能实验室的支出并没有天壤之别。
值得注意的是,“规模曲线”分析有些过于简化,因为模型在某种程度上是存在差异的,并且各有优缺点;规模曲线数字是一个粗略的平均值,忽略了许多细节。我只能谈谈 Anthropic 的模型,但正如我上面暗示的那样,Claude 在编程和与人进行良好设计的互动风格方面非常出色(很多人用它来寻求个人建议或支持)。在这些以及一些额外的任务上,DeepSeek 完全无法与之相提并论。这些因素在规模数字中并未体现出来。
上周发布的 R1 模型引发了公众的广泛关注(包括英伟达股价下跌约 17%),但从创新或工程角度来看,它远不如 V3 有趣。R1 模型增加了第二阶段的训练——强化学习,在前一节的第 3 点中对此进行了描述——并且基本上复制了 OpenAI 在 o1 模型中所做的工作(他们似乎处于相似的规模,结果也相似)。然而,由于我们正处于规模曲线的早期阶段,只要它们从强大的预训练模型起步,多家公司就有可能生产出这种类型的模型。在 V3 的基础上生产 R1 模型的成本可能非常低廉。因此,我们正处于一个有趣的“交叉点”,暂时会出现多家公司都能生产出优秀的推理模型的情况。但随着所有公司在这种模型的规模曲线上进一步前进,这种情况将迅速消失。
出口管制
以上所有内容都只是我主要关注话题——对华芯片出口管制——的铺垫。根据上述事实,我对当前形势的看法如下:
即使曲线周期性地发生偏移,训练特定智能水平模型的成本迅速下降,但各公司在训练强大人工智能模型上的支出却持续增加。这仅仅是因为训练更智能模型的经济价值实在太大了,以至于任何成本上的节省几乎都立即被抵消——它们被重新投入到制造更智能的模型中,花费的仍然是最初计划支出的巨额资金。DeepSeek 开发的效率创新,如果美国实验室尚未发现,也将很快被美国和中国实验室应用于训练数十亿美元的模型。这些模型将比他们之前计划训练的数十亿美元模型性能更优——但他们仍然会花费数十亿美元。这个数字将继续上升,直到我们达到人工智能在几乎所有事情上都比几乎所有人类更智能的程度。
制造出在几乎所有事情上,都比几乎所有人类更智能的人工智能,将需要数百万块芯片、数百亿美元(至少),并且最有可能在 2026-2027 年实现。DeepSeek 的成果发布并没有改变这一点,因为它们大致符合一直被纳入这些计算的预期成本降低曲线。
这意味着在 2026-2027 年,我们可能会最终进入两个截然不同的世界之一。在美国,多家公司肯定会拥有所需的数百万块芯片(以数百亿美元的成本)。问题是中国是否也能获得数百万块芯片?
如果中国能够做到,我们将生活在一个两极世界中,美国和中国都将拥有强大的人工智能模型,这将导致科学和技术的飞速发展——我称之为“数据中心里的天才之国”。两极世界不一定会无限期地保持平衡。即使美国和中国在人工智能系统方面势均力敌,中国似乎也更有可能将更多的才能、资本和关注力投入到该技术的军事应用中。结合其庞大的工业基础和军事战略优势,这可能有助于中国在全球舞台上取得支配地位,不仅在人工智能领域,而且在所有领域。
如果中国无法获得数百万块芯片,我们将(至少暂时)生活在一个单极世界中,只有美国及其盟友拥有这些模型。单极世界是否会持久尚不清楚,但至少存在一种可能性,即由于人工智能系统最终可以帮助制造更智能的人工智能系统,暂时的领先优势可能会转化为持久的优势。因此,在这个世界中,美国及其盟友可能会在全球舞台上取得支配且持久的领先地位。
有效执行的出口管制是唯一能够阻止中国获得数百万块芯片的手段,因此也是我们最终会进入单极世界还是两极世界的最重要决定因素。
DeepSeek 的出色表现并不意味着出口管制失败。正如我上面所述,DeepSeek 拥有相当数量的芯片,因此他们能够开发并训练出一个强大的模型并不令人意外。他们的资源约束程度并不比美国人工智能公司高多少,出口管制也不是导致他们“创新”的主要因素。他们只是非常有才华的工程师,并表明中国是美国的一个强大竞争对手。
DeepSeek 也不能证明中国总能通过走私获得所需的芯片,或者证明管制措施总是存在漏洞。我不认为出口管制的目的曾经是阻止中国获得数万块芯片。10 亿美元的经济活动可以被掩盖,但 1000 亿美元甚至 100 亿美元的经济活动却很难隐藏。数百万块芯片在物理上也可能难以走私。
审视一下目前报道的 DeepSeek 拥有的芯片也具有启发意义。根据 SemiAnalysis 的说法,这是一个由 H100、H800 和 H20 组成的混合体,总计 5 万块。H100 自发布以来就受到出口管制禁令的限制,因此如果 DeepSeek 拥有任何 H100,那一定是走私来的(请注意,英伟达已声明 DeepSeek 的进展“完全符合出口管制规定”)。H800 在 2022 年最初的出口管制措施下是允许的,但在 2023 年 10 月管制措施更新时被禁止,因此这些芯片可能是在禁令之前发货的。H20 的训练效率较低,采样效率较高——并且仍然是允许出口的,尽管我认为应该禁止出口。
总而言之,DeepSeek 人工智能芯片舰队的很大一部分似乎是由以下芯片组成:尚未被禁止的芯片(但应该被禁止);在被禁止之前发货的芯片;以及一些非常可能走私来的芯片。这表明出口管制实际上正在发挥作用并不断调整:漏洞正在被堵塞;否则,他们很可能拥有全部由顶级的 H100 组成的芯片舰队。如果我们能够足够快地堵塞漏洞,我们或许能够阻止中国获得数百万块芯片,从而增加美国领先的单极世界出现的可能性。
考虑到我对出口管制和美国国家安全的关注,我想明确一点。我不认为 DeepSeek 本身是对手,重点也不是专门针对他们。在他们接受的采访中,他们看起来像是聪明的、充满好奇心的研究人员,只是想创造有用的技术。
如果中国能够在人工智能领域与美国匹敌,这个他们会是令人恐慌的。出口管制是我们阻止这种情况发生的最有力工具之一,认为技术变得更强大、性价比更高就应该放松出口管制,这种想法根本毫无道理。
责任编辑:王永生