来源:新智元

【新智元导读】奥特曼罕见地承认了自己犯下的‘历史错误’,LeCun发文痛批硅谷一大常见病——错位优越感。DeepSeek的终极意义在哪?圈内热转的这篇分析指出,相比R1,R1-Zero具有更重要的研究价值,因为它打破了终极的人类输入瓶颈!
DeepSeek再度创造历史。
居然能逼得OpenAI CEO奥特曼承认:‘我们在开源/开放权重AI模型方面,一直站在了历史的错误一边。’
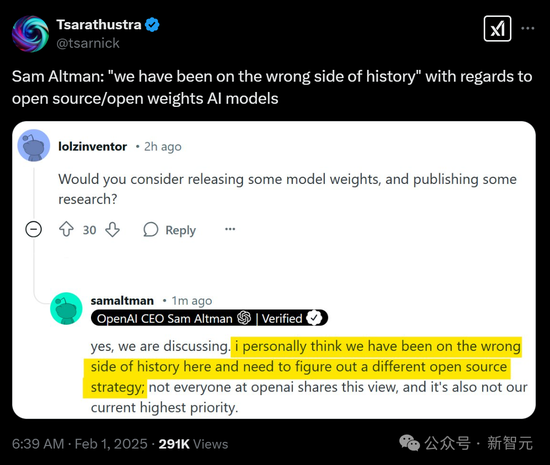
LeCun也发文指出,硅谷圈子的常见病,就是一种错位的优越感。
高级阶段的症状,是认为小圈子就能垄断好的想法。而晚期症状就是,假设来自他人的创新都是靠作弊。
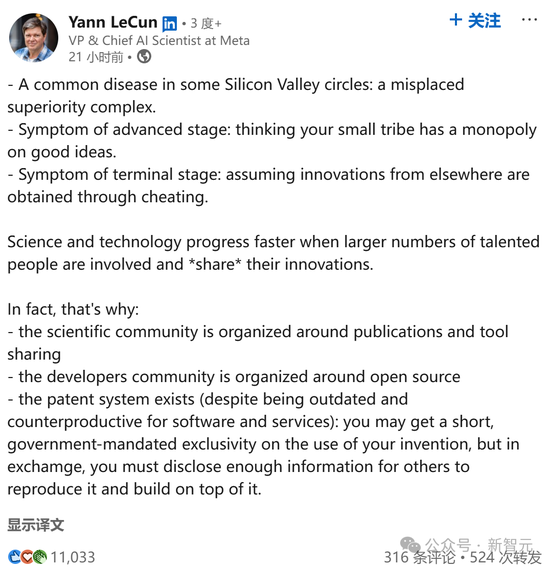
DeepSeek的最大意义在哪里?
ARC Prize联合创始人Mike Knoop发出长文中总结道——R1-Zero打破了最终的人类输入瓶颈——专家CoT标注!其中一个例子,就是监督微调(SFT)。
从R1-Zero到AGI,一切都与效率有关。
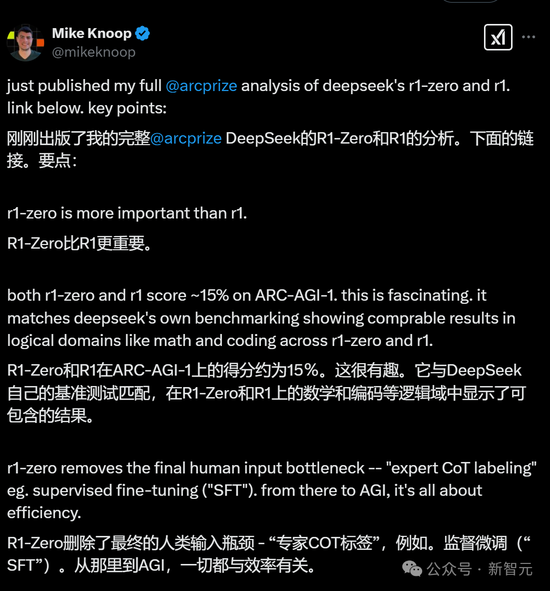
另一个值得注意的观点就是:相比R1,R1-Zero具有更重要的研究价值。
这是因为,R1-Zero完全依赖强化学习(RL),而不使用人类专家标注的监督微调(SFT)。
这就表明,在某些领域,SFT并非实现准确清晰CoT的必要条件,完全有可能让AI通过纯粹的RL方法实现广泛推理能力。
以下为Mike Knoop的完整分析。
从此,推理计算需求激增
上周,DeepSeek发布了他们新的R1-Zero和R1‘推理’系统,在ARC-AGI-1基准测试上的表现可与OpenAI的o1系统相媲美。
R1-Zero、R1和o1(低算力模式)都取得了15-20%的得分,而GPT-4o仅为5%——而这已是多年纯LLM scaling的巅峰成果。
根据本周美国市场的反应,公众也开始理解了纯LLM scaling的局限性。
然而,大多数人仍没有意识到推理计算需求即将激增的问题。
2024年12月,OpenAI发布了一个新的突破性系统o3,经过验证,该系统在低算力模式下得分76%,高算力模式下得分88%。
o3系统首次展示了计算机在面对全新、未知问题时进行适应的通用能力。
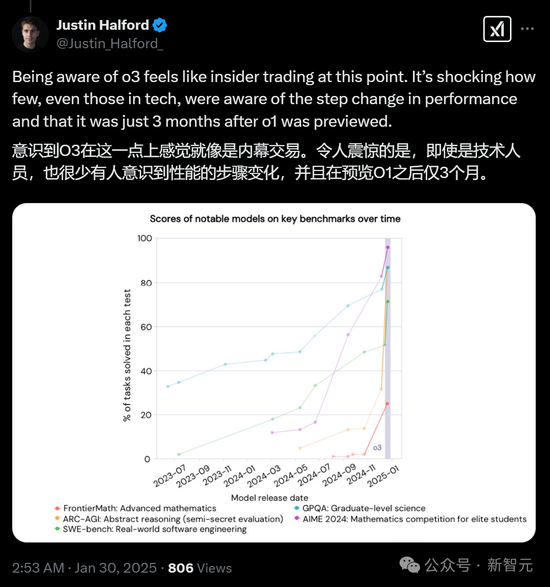
尽管o3在ARC-AGI-1基准测试中取得了突破性的成绩,但这一科技大事件却在主流媒体中几乎未被报道,也未引起广泛关注。
这是AI和计算机科学领域的一个极其重要的时刻,这些系统值得深入研究。
然而,由于o1和o3是闭源的,我们只能依靠推测进行分析。
幸运的是,借助ARC-AGI-1,以及现在(几乎)开源的R1-Zero和R1,我们能够进一步加深对这一领域的理解。
这里的‘几乎’指的是,DeepSeek并未公布从零开始复现其模型权重的方法。
特别值得注意的是,相比R1,R1-Zero具有更重要的研究价值。
R1-Zero比R1更值得分析:它消除了人为瓶颈
在对o1和o3的分析中,ARC Prize团队对这些推理系统的工作原理进行了推测。
它们的关键思路如下:
-
为特定问题领域生成思维链(CoT)。
-
使用人工专家(‘监督微调’SFT)和自动化机器(‘强化学习’RL)的组合对中间的CoT步骤进行标注。
-
利用(2)中标注的数据训练基础模型。
-
在测试时,模型会基于这一推理过程进行迭代推理。
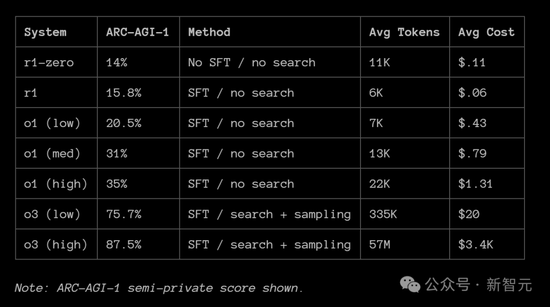
下图回顾了用于各模型用于迭代采样的技术,及其在ARC-AGI-1评分的相关情况。
随着DeepSeek发表的新研究,ARC Prize团队就可以更好地验证自己的推测。
一个关键的发现是,LLM推理系统在适应新颖性(以及提高可靠性)方面的提升,主要沿着以下三个维度展开:
-
为CoT过程模型的训练添加人工标注,即SFT(监督微调)。
-
使用CoT搜索而非线性推理(即每个步骤并行进行CoT推理)。
-
进行整体CoT采样(即并行推理整个轨迹)。
第(1)点受到人工数据生成的限制,因此决定了哪些领域的推理系统能从中受益最大。
例如,在o1系统上,MMLU中的专业法律类目得分远低于数学和逻辑类目,这令人颇感意外。
第(2)和(3)点的主要瓶颈在于计算效率。
o1和o3都在ARC-AGI-1基准测试上表现出对推理计算量的对数式改进,即它们在测试时使用越多的计算资源,基准准确率就越高。
同时,不同的计算方式会影响这条曲线在x轴上的位置。
ARC Prize团队认为,DeepSeek最有趣的做法是单独发布了R1-Zero。R1-Zero不使用SFT(即不依赖人工标注),完全依赖强化学习(RL)。
R1-Zero和R1在ARC-AGI-1上的得分高度一致,分别为14%和15%。
此外,DeepSeek自己发布的基准测试结果也表明R1-Zero和R1的表现相近,例如在 MATH AIME 2024上的得分分别为71%和76%(相比之下,基础模型DeepSeek V3的得分仅为约40%)。
在论文中,R1-Zero的作者指出:‘DeepSeek-R1-Zero在可读性较差和语言混杂等方面存在挑战’,这一点也在网络上得到了印证。
然而,在ARC Prize团队的测试中,他们却几乎没有发现R1-Zero在ARC-AGI-1上表现出不连贯性,而这一测试任务与该系统通过强化学习训练的数学和编程领域相似。
综合这些发现,ARC Prize团队得出了以下结论:
-
在具有强可验证性的领域,SFT(即人工专家标注)并非实现准确且清晰的 CoT(思维链)推理的必要条件。
-
R1-Zero的训练过程能够通过RL优化,在token空间内自发构建内部的特定领域语言(DSL,Domain-Specific Language)。
-
SFT在提升CoT推理的跨领域泛化能力方面是必要的。
这一点符合直觉,因为语言本质上也是一种推理DSL。相同的‘词’可以在一个领域中学习,并在另一个领域中应用,就像程序一样。

而纯RL方法目前尚未能够发现一个广泛共享的词汇体系,这可能会成为未来研究的一个重要方向。
最终,R1-Zero展示了一种潜在的扩展路径——即使在训练数据采集阶段,也完全消除了人工瓶颈。
可以肯定的是,DeepSeek 的目标是挑战OpenAI的o3系统。
接下来的关键观察点在于:SFT是否仍然是CoT搜索和采样的必要条件,或者是否可以构建一个类似‘R2-Zero’的系统,在相同的对数式推理计算扩展曲线上继续提升准确率。
根据R1-Zero的实验结果,团队认为,在这种假设的扩展版本中,SFT并不是超越ARC-AGI-1所必需的条件。
用更多资金,换取AI的可靠性
从经济角度来看,AI领域正在发生两大重要变化:
-
投入更多资金,以获得更高的准确性和可靠性。
-
训练成本正在向推理成本转移。
这两点都将极大地推动推理计算的需求,同时也不会抑制对更强计算资源的需求,反而会进一步增加计算需求。
AI 推理系统的价值,远不止于提高基准测试中的准确率。
当前阻碍AI更广泛自动化应用(即推理需求)的首要问题,就是可靠性。
ARC Prize团队曾与数百位试图在业务中部署AI智能体的Zapier客户交流过,他们的反馈高度一致:‘我还不信任它们,因为它们的工作表现不够稳定。’
以前,ARC Prize曾提出,朝着ARC-AGI方向的进展将提升AI可靠性。
LLM智能体的主要挑战在于,它们需要强有力的本地领域控制才能稳定运行。
而更强的泛化能力,要求AI能够适应全新的、未见过的情况。如今,已有证据表明这一观点是正确的。
因此,Anthropic、OpenAI、Apple等多家公司纷纷推出AI智能体也不足为奇。

由于可靠性需求,智能体将推动短期内的推理计算需求增长。
此外,开发者可以选择投入更多计算资源,以提高用户对系统的信任度。
然而,更高的可靠性并不意味着100%的准确性——但它能让错误更加稳定、可预测。
这反而是可接受的,因为当准确率较低时,用户和开发者可以通过提示词更稳定地引导 AI行为。
过去被认为计算机无法解决的问题,如今都可以用金钱衡量其解决成本。随着AI计算效率的提升,这些成本也将逐渐下降。
推理即训练:AI数据获取范式或将永久转变
另一个正在发生的重要变化,是用于LLM预训练的数据来源。
过去,大多数训练数据要么是购买的,要么是从网络爬取的,要么是由现有的LLM合成生成(例如蒸馏或数据增强)。
但推理系统提供了一种全新的选择——生成‘真实’数据,而非传统意义上的‘合成’数据。
AI行业通常将‘合成数据’视为质量较低的数据,这些数据通常是通过LLM循环生成的,仅仅是为了增加训练数据的总体规模,但其收益会逐渐递减。
如今,借助推理系统和验证器,我们可以创造全新的、有效的数据来进行训练。这可以通过两种方式实现:
-
离线生成 ——开发者支付费用来创建数据。
-
推理时生成 ——终端用户支付费用来创建数据。
这是一种引人注目的经济模式转变,可能会导致AI系统开发者之间出现‘赢家通吃’的局面。
拥有最多付费用户的AI公司将拥有巨大的数据垄断优势,因为这些用户在无形中资助了新高质量数据的创建,而这些数据反过来又进一步提升模型能力,使其更受用户青睐……由此形成一个自增强的良性循环。
如果我们能够突破人类专家CoT标注的瓶颈,并构建一个极高效的搜索/合成+验证系统来自动生成新数据,那么可以预见,未来将会有大量计算资源投入到这些推理系统中。
因为这些系统的训练效果将直接与资金投入和数据输入量挂钩,也就是说,只要投入资金和原始数据,模型就会变得更强。
最终,这种AI训练模式将彻底取代基于人类生成数据的预训练方法。

结论:DeepSeek推动全世界科学发展
随着推理需求的增长变得更加明确,市场将继续经历调整。
AI 系统的效率提升不仅会推动更多的应用,这不仅符合杰文斯悖论,更重要的是,更高的计算效率解锁了全新的训练范式。
随着R1的开源和可复现性,越来越多的个人和团队将探索CoT和搜索技术的极限。
这将帮助我们更快地厘清当前AI研究的前沿在哪里,并推动一波技术创新浪潮,从而加速通向 AGI的进程。
已经有几位研究者告诉ARC Prize团队,他们计划在2025年ARC奖中使用R1风格的系统,这让人非常期待看到最终的结果。
R1的开源,对整个世界来说都是一件好事。DeepSeek推动了科学的前沿发展,并为AI 研究带来了新的突破。
责任编辑:何俊熹