智通财经APP获悉,2月12日,东方港湾公开发文“回应”投资者的询问。但斌认为,DeepSeek的成果会增加全球AI算力的需求,而非减弱。市场最大的误解,是从根本上把算法、算力和数据三者进行对立;实际上,算法、数据和算力三者之间,是一种“协同关系”。中美AI应用会涌现各种投资机会,而大模型企业的商业模式会继续饱受挑战,只有持续保持前沿模型领先,才能维持巨大的用户数量和定价优势,以弥补前期高额的探索成本。这种难度现在也变得越来越大了。
时值岁末,中国量化基金团队Deepseek,连续发布了V3底座大模型以及R1推理大模型,以低一个数量级的推理成本和匹敌Openai最强模型的性能,震惊世界。
东方港湾收到了许多投资者的询问,最受关注的问题有三个:
1)中国团队在算力卡脖子的情况下,仍能研发出全球领先的AI大模型,是否说明了今后AI的进步不需要算力?
2)Deepseek团队通过修改PTX指令集,优化了GPU的使用,是不是意味着绕过CUDA的壁垒,今后使用国产芯片可以畅行无阻了。
3)中国模型的降本与平权,会带来什么投资机会与风险?=
对于第一个问题,东方港湾的观点是:Deepseek的成果会增加全球AI算力的需求,而非减弱。
首先,市场最大的误解,是从根本上把算法、算力和数据三者进行对立,误认为算法的创新进步,是对算力和数据形成了“替代和竞争”。而实际上,算法、数据和算力三者之间,是一种“协同关系”。
人工智能过去70年的发展,三个要素都须同时取得进步;任一要素被卡住了,人工智能都会止步不前:第一波人工智能浪潮止步于算法的缺陷,第二波浪潮止于算力的不足。而目前第三波浪潮,得益于算法、算力和大数据三者,在互联网时代得到了空前的飞跃。
同样的,三要素中任意一个的发展,都会带动另外两者的价值量提升。就像一家人,父亲的事业成功,也会为孩子的成长和妻子的创业带来更多机会。假设过去算法低效时,单位芯片在一个用例上只能服务10个用户;现在算法提效了,同一芯片可以服务100人。该芯片如果不提价,其价值量肯定是翻了10倍,而不是变得更低。如果一个商品的价值量提升了10倍,而价格不变,那么需求一定是上升的,这是经济学常识。
市场之所以错把算法与算力对立起来,很可能是来自当下中美的竞争关系。当中国模型企业在算力资源受限的情况下,工程算法取得了突破(工程的本质就是“突破限制”),市场心理便很容易将“中美竞争”映射到算法算力竞争之上。加上“东方力量的神秘感”,华尔街很容易从心理上将“意外”的情绪无限放大。
其次,成熟AI模型的“降本与平权”已是过去2年大趋势。25开年Deepseek作为“追赶者”送出的降本平权大礼包,除了“来自中国”和“开源”这2个意外情绪点之外,也在这一趋势内,这是走向“应用普及”的必经之路。而成熟模型的降本与前沿模型的探索是两码事,想争做AI时代模型的领头人,所需算力和资源都不是小数,这也是除了Openai以外许多巨头的野心。
世界上任何一种技术的发展,基本遵循着“创新-跟随-降本”的发展模式。前沿的“探索者”会花重金和时间进行实验探索,最终找到一个有效果的技术方案,并将其商品化;紧接着,社会会出现一大批“跟随者”,沿着探索者的思路去复现其产品,并在工程上进一步降本优化。这种成本优化的思路又会回到探索者那里进行整合和降本,双方相互学习,相得益彰。我们所熟知的领域里,包括了创新药与仿制药,特斯拉与中国电动车,台积电与其他代工厂,还有大模型领域,皆是如此。
目前在大模型的绝大多数能力领域里(如聊天机器人、实时多模态模型、逻辑推理模型等),Openai都暂时充当了探索者的角色,其身后是北美四大模型(Gemini、Claude、Xai、Llama)的追赶;而紧随北美企业的,是中国互联网大厂(如字节豆包、阿里千问、百度文心、腾讯混元)与一众模型创业公司(如Deepseek、智谱GLM、MiniMax海螺、月之暗面Kimi等)的追赶脚步;而中美之外,其他国家鲜有追赶者。
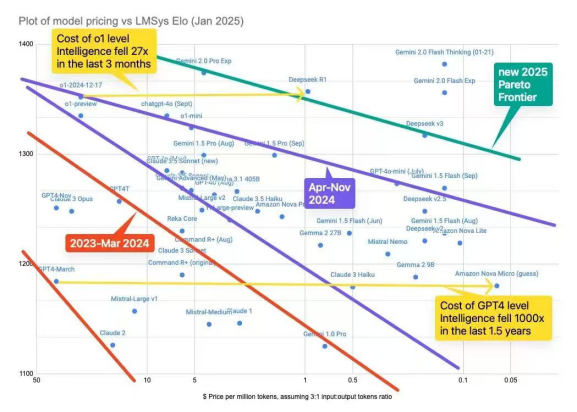
下图很好地描述了过去两年,中美在Openai开辟的“GPT4和o1”这两条赛道上的降本速度:自2023年4月推出GPT4以来,大量追赶者在1.5年的时间里,将同性能模型的成本降低了1000倍——3个数量级;而自2024年9月推出o1版本系列以来,追赶者DeepseekR1在3个月内将成本拉低了27倍——1个数量级,而追赶者Gemini2.0flashthinking更是在同一时间将成本拉低了100倍——2个数量级。所以我们说“平权和降本”是AI时代目前最大的一条时代脉络,Deepseek也没有逃脱这一趋势。人们沉浸于Deepseek的震惊当中,久久不能释怀,甚至连谷歌更为夸张的降本效果都无人谈及。
追赶者之所以能比探索者实现几个数量级的降本,在上期观点中也简单介绍过,方法非常多,拆解Deepseek技术报告的文章也解释得很详尽,我们不做过多赘述。而除了工程创新、数据蒸馏以及随时间不断下降的算力成本以外,探索者与追赶者之间,最大区别来自“探索的成本”。就好比创新药和仿制药之间,实验与临床是最大的成本差别。Deepseek与美国的其他追赶者都一样,若想在时代的最前沿“探路”,不甘只做追随者,所付出的成本将比现在大上许多倍。
再者,随着AI成本的大幅下降,AI应用普及带来的推理需求才是算力的主场。我们在年度思考中对比过o1模型的推理成本,在每百万token55美金的输出价格下,Agent应用使用推理模型几乎是寸步难行。而短短不到一个月,推理模型成本被追赶者的工程优化降低了100倍,预期的Agent应用生态,在以极快的速度向我们走来。
Deepseek带火了一个概念——杰文斯悖论,指的是当资源使用效率提高后,资源的消耗总量不会下降,反而会增加的经济现象。该理论最早于19世纪应用于煤炭的消耗问题。当瓦特改进蒸汽机,提高了煤炭利用率后(单位动力耗煤量大幅下降了75%),烧煤蒸汽机被更广泛地应用到工厂、铁路和船舶上,反而加速了煤炭消耗总量,也提升了煤炭价格。同样的情况,也发生在当汽车燃油效率提升(每公里耗油更少了),带来的行驶里程和总油耗的大幅增长,以及LED灯节能导致更长开灯时间和更多地方安装灯光,总体耗电量不降反升的情况。当一项技术未被大面积采用之前,其单位资源消耗量的下降,反而会促进整体资源消耗总量的上升。同样的情况,也会在AI模型的应用身上发生,因为AI时代才刚刚开幕。
我们可以再回顾一次“人均拥有算力”的概念:如果AI技术未来注定要普及百行千业,影响全球80亿人口,以当前全球AI算力部署4500ExaFlops来计算,人均拥有算力0.6Tops,方兴未艾。一辆自动驾驶汽车所需芯片就在500Tops以上,25年特斯拉最新FSD芯片AI5的算力更是预计高达1500Tops以上。AI算力资源消耗总量还有极大的上涨空间,前提就是算力资源的使用效率需要大幅地提升。
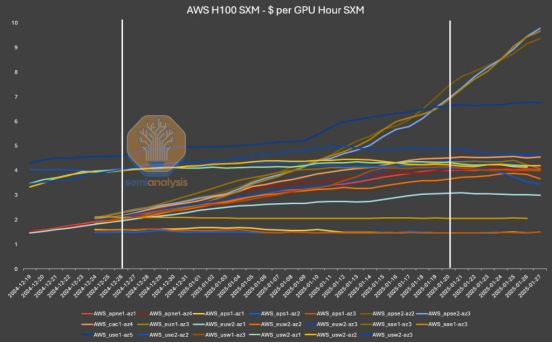
实际上,自Deepseek发布以来,我们看到算力租赁Spot市场价格(非长单即期价格,占比小),出现了快速的上涨,许多AI应用公司都开始采用Deepseek模型作为测试方案(下图为Semi关于亚马逊的GPU租赁价格),导致了算力短缺。而Deepseek的官网也因为用户数快速上升到4000万(豆包才6000万),频繁出现崩溃和拒绝回复。同时,本月发布财报的微软、Meta、谷歌和亚马逊,都在25年AI设备的资本开支上再度加码升级,为接下来的推理应用市场做足准备。
对于第二个问题,东方港湾的观点是:CUDA并未被绕开,壁垒反而被增强。
DeepseekV3的论文中描述到,为了优化英伟达芯片的使用效率,团队不满足于CUDA的高级语言编辑,直接在底层编辑PTX指令集,对H800芯片中的流处理器进行通讯任务分配的修改,从而一定程度提高了全互联的通讯效率和稳定性。很多人看到这里,会认为Deepseek没有使用CUDA软件,而是用PTX汇编语言对GPU进行功能修改,因此团队具备能力绕过CUDA,使用汇编语言在其他厂商的芯片上去复现模型的训练。这是非常大的误解。
首先解释下什么是PTX。英伟达芯片在顶层应用场景中覆盖广泛,涉及游戏图形、自动驾驶、大语言模型和科学模拟等多个领域。每个领域的具体任务若要利用GPU进行加速计算,都需要配套的软件库支持。例如游戏中的OptiX光线追踪加速,大语言模型加速推理的TensorRT-LLM,等等。另一方面,英伟达芯片的底层硬件设计,也从过去的Pascal、Volta架构,到如今广为人知的Ampere、Hopper和Blackwell,架构不断升级,涵盖制程工艺、计算精度、指令集复杂度等多个方面。所以,软件和硬件都在不断迭代和发展,这也带来了兼容性问题。开发者往往会担心,今天设计的软件在未来是否仍能适配更新的芯片架构。为了解决这一问题,英伟达设计了一套专用的“中间表示层”(即PTX)来连接软件与硬件。无论软件和硬件如何升级变化,代码只需通过PTX进行转译,即可适配不同架构的GPU,并生成相应的机器执行码。这就像中国和欧洲的商贸往来,两地的人使用多种不同语言。如果有一个精通中欧语言的美国翻译作为中介,就无需让每位中国商人都学习所有欧洲语言,大家直接用英语沟通即可。
PTX在计算领域的作用,就类似于这个“通用翻译层”,翻译上层CUDA软件的高级语言,成为中间表示,然后再转化成英伟达显卡可以理解的SASS语言(这部分是保密的)。为了增强CUDA开发者对GPU硬件的适配能力,英伟达开放了PTX的编辑权限,使开发者不仅可以编写CUDA代码,还可以直接调整PTX层,以优化代码在不同GPU架构上的执行效率。这个过程可以类比为:CEO(CUDA代码)将任务交给市场部主管(PTX),主管再细化任务并最终分配给各个销售人员(SM流处理器)。如果CEO认为主管的分配方式不合理,还可以直接介入对任务分配进行调整,提升并行任务的执行效率。
所以,Deepseek能够使用PTX(全称为:并行计算任务线程的执行)进行任务执行的优化,也是英伟达架构的“可编辑性”所允许的。英伟达经常会吸收开发人员编辑PTX的创新工程方法,反过来优化官方的CUDA算子,这也是CUDA生态的反哺优势。而AMD、华为、寒武纪的芯片,虽然也有这种中间表达层(IR码),但其IR码是不可编辑的。
弄清以上原理之后,我们可以理解Deepseek使用PTX进行硬件的任务执行优化,非但没有绕过CUDA,反而是在加强和反哺CUDA生态。
首先,PTX就是CUDA架构的一部分。CUDA不只是指软件,还包括了PTX和底层的硬件架构,全称是“计算和设备的统一架构”。正是这种紧密耦合的软件-硬件协同架构,使得CUDA在GPU计算的快速迭代过程中,仍能保持高效兼容性和优化能力。PTX本质上是一种中间表示(IR),它是CUDA代码的另一种表达方式而已。
其次,PTX仅能被英伟达GPU解析和执行。用户编辑PTX指令,相当于在CUDA生态系统中采用更底层的方式进行开发和优化,以更高效地适配和利用英伟达的GPU硬件架构,而不是绕开或超越其架构限制。PTX指令集是专门为英伟达GPU设计的,并不适用于其他厂商的GPU或计算架构,无法直接移植到非英伟达芯片之上。
再者,DeepSeek可以编辑PTX,是因为英伟达开放了PTX指令级优化的权限,而其他芯片(如华为升腾、AMDGPU、谷歌TPU)的中间表示层(IR)则对外开放程度较低,开发者通常无法直接编辑底层指令集。
总而言之,要完全绕开CUDA,有两种主要路径:要么在高级编程语言层面,重新设计一整套覆盖多个行业的GPU计算加速库和开发框架,这需要大量时间、资源以及行业生态的支持;要么尝试将CUDA代码编译成PTX以外的IR代码,以适配不同厂商的GPU硬件架构,但这会受到兼容性和优化的限制。例如,AMD正在通过HIP转换器,将CUDA代码迁移到AMDGPU上,仍然存在性能损失和适配成本。这类似于在苹果电脑上运行Windows系统——虽然技术上可行,但性能、兼容性和体验通常比原生环境差。除此之外,几乎没有更好的替代方案。
对于第三个问题,东方港湾的观点是:中美AI应用会涌现各种投资机会,而大模型企业的商业模式会继续饱受挑战。
Deepseek以一己之力,短短一个月为全国人民做了一次“AI科普”,并在模型能力和推理成本上追平甚至超越了大多数美国模型。Deepseek更重要的贡献在于发现了一种高效的方法,即利用经过强化学习训练并具备推理能力的大模型进行蒸馏,从而生成包含“思维链”的样本数据,并对小模型进行直接的监督微调。相比于直接对小模型进行强化学习,这种方式能更有效地复现大模型的推理能力。因此,在R1模型发布后,全球企业与高校迅速掀起了基于思维链数据对小模型进行微调的复现工程,使得模型推理能力在Deepseek体系之外也得到了快速复制和扩散。推理模型的平权之路猛然加速。因此,我们在美国看到的AI应用机会,同样将在中国市场广泛落地。
唯一需要注意的是,中美AI之间的算力差异,或因算力管制的升级而继续扩大,例如英伟达H20芯片遭到禁运。Deepseek等一众模型已经在国产芯片上做了适配,但国产芯片在架构、软件加速库、集群能力上仍然存在短板,会对于AI产品的推理服务质量产生影响。当更多用户同时使用更多种类AI应用时,推理延迟和服务器繁忙的情况可能都会是常态。
而就在R1发布不久,Openai也如期发布了o3模型,并提供了免费试用。o3的能力相对o1又有了质的飞跃,Openai暂时保住了“领先者”地位。但在“探索者与追赶者”的游戏中,如果探索者持续创新的速度,跟不上追赶者降本复现的速度,探索者前期的成本将入不敷出,商业模式没法实现闭环。而如果追赶者因为“专利壁垒”或“网络效应”等原因无法复现,或者探索者能够持续创新保持领先,探索者就能在最前沿的产品上保持溢价的定价能力,同时在被追上的次代产品上做低价压制,保证了商业模式的合理性,就像台积电在工艺制程上所采取的商业策略一样。但在大模型领域,即没有网络效应也没有专利保护,Openai或其他希望成为领头羊的模型企业,只有持续保持前沿模型领先,才能维持巨大的用户数量和定价优势,以弥补前期高额的探索成本。这种难度现在也变得越来越大了。
以上是东方港湾对这三个问题的主要观点。
2025注定是一个市场波动率很大的年份。但在对投资的细枝末节进行梳理之后,我们还是要回到投资的主线上来。
在AI的时代脉络上,时代车轮在明显地加速驶进。同时,我们也要看到,在高波动率的同时,2025年的美股市场也预计将迎来超过2万亿美元的资金流入,为市场估值和稳定性提供支撑。企业回购预计将达到1万亿美元,通过减少流通股数量和提高每股收益(EPS)来增强投资者信心,尤其是科技巨头将继续加大回购力度。
而标普500企业的分红总额预计将达到6000亿美元,因其稳定性和可预测性吸引了长期投资者,尤其是养老金和401(k)账户。
此外,养老金和长期投资账户预计将贡献超过4000亿美元的资金流入,这些资金通常流向被动管理的基金,如标普500ETF,为市场提供稳定的流动性。