处理数百小时超长视频,单张3090就够了?!
这是来自香港大学黄超教授实验室发布的最新研究成果——VideoRAG。

具体而言,VideoRAG可以在单张RTX 3090 GPU (24GB)上高效处理长达数百小时的超长视频内容。这意味着只需要一张普通的显卡,就能一口气完整观看一部《黑悟空》这样的长视频。
此外,VideoRAG还拥有创新的多模态检索机制。
它采用了动态知识图谱构建和多模态特征编码的技术,将视频内容浓缩为基于多模态上下文的结构化知识表示。这不仅支持复杂的跨视频推理,还能够精准地进行多模态内容检索。
而且,为了推动该领域的进一步发展,研究团队还发布了LongerVideos基准数据集。
该数据集涵盖了160多个长达数小时的视频,为未来的研究提供了宝贵的支持。
更多具体内容如下。
突破传统文本RAG跨模态局限
尽管RAG (Retrieval-Augmented Generation) 技术通过引入外部知识显著提升了大语言模型的性能,但其应用场景仍局限于文本领域。
视频作为一种复杂的多模态信息载体,涵盖视觉、语音和文本等异构特征,其理解与处理面临三大关键挑战:
多模态知识融合:传统文本RAG方法难以有效捕捉视频中的跨模态交互,特别是在建模视觉动态特征(如目标运动轨迹)与语音叙述之间的时序关联方面存在局限;
长序列依赖建模:现有方法往往通过视频截断或关键帧提取来简化处理,这不可避免地导致动作连续性损失,造成上下文割裂,影响跨视频知识整合的效果,难以保持长时视频的语义连贯性;
规模化检索效率:在大规模视频库场景下,现有方法在检索速度与结果质量间存在明显权衡,且多依赖单一模态(如语音转录文本)进行检索,未能充分利用视觉语义信息。
为突破上述限制,团队提出创新性RAG框架VideoRAG,通过双通道架构实现以下技术创新:
1、图谱驱动的跨模态知识关联:构建动态演化的语义网络,将视频片段映射为结构化知识节点,有效捕捉并建模跨视频语义关联;
2、有效的多模态上下文编码:建立视觉-文本联合表征空间,保留细粒度时空特征表示,显著增强视频内容理解能力;
3、适应混合检索方法:融合知识图谱推理与视觉特征匹配,突破计算资源限制,实现低显存消耗下的百小时级视频精准检索。
基于首个超长跨视频理解基准数据集LongerVideos的全方位评估表明,VideoRAG在超长视频内容理解任务上展现出卓越性能,为教育知识库构建、影视内容分析等实际应用场景提供了极具潜力的解决方案。
VideoRAG框架设计
VideoRAG创新性地融合多模态知识索引与知识驱动检索机制,实现对视频中视觉、音频及语义信息的高效捕捉、系统化组织与精准检索。
该框架突破了传统视频长度限制,支持对理论上无限时长的视频输入进行智能分析,为超长视频理解领域开创了新范式。
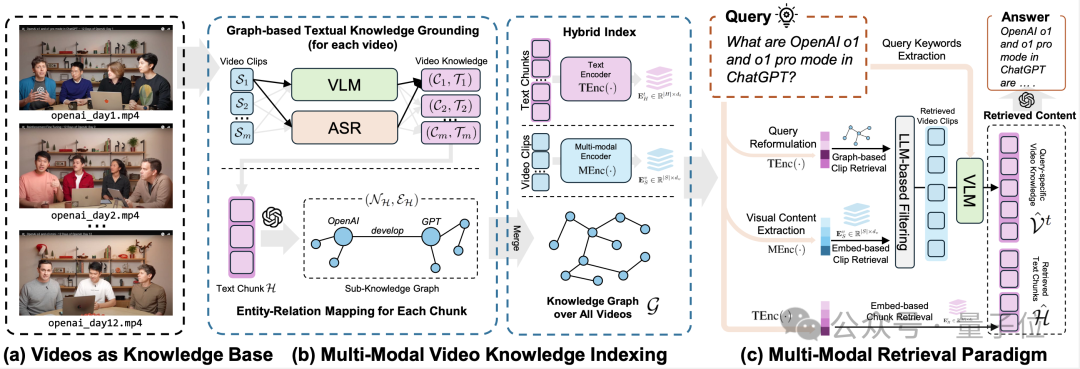
双通道多模态视频知识索引:突破传统范式
视频作为复杂的多模态信息载体,融合了视觉、音频及文本等多维度信息,其处理难度远超传统文本。
现有的文本RAG方法在处理视频数据时面临三大根本性挑战:视觉动态特征提取、时序依赖性建模以及跨模态语义交互。针对这些挑战,VideoRAG创新性地提出双通道架构,实现了对长视频的高效组织与智能索引,同时保持了多模态内容的语义完整性:
基于知识图谱的多模态语义对齐
视觉-文本映射:在视觉语义建模环节,本框架采用精细化的视频分段策略,将视频流按时序均匀划分为连续片段。为平衡计算效率与信息完整性,每个片段通过智能采样算法提取不超过10个代表性关键帧。
随后,借助先进的视觉语言模型(VLM),自动生成高质量的自然语言描述,实现对视频画面中物体、动作语义及场景动态等多维度特征的系统性捕捉。
音频语义转换与融合
在音频处理模块,系统部署了高性能的语音识别(ASR)技术,精确提取视频中的对话内容与旁白信息。
通过创新的语义融合机制,将音频文本信息与视觉描述进行深度整合,构建统一的跨模态语义表示体系,有效保留了视听信息的语义完整性。
跨视频知识网络构建
基于LLMs识别实体关系,动态合并多视频语义节点,形成全局知识网络,确保跨视频内容的一致性与关联性。
多模态上下文编码
为实现跨视频的语义关联,框架基于大语言模型(LLMs)设计了动态知识图谱构建机制。
系统自动识别并提取视频内容中的核心实体与关系信息,通过智能合并算法动态融合多个视频的语义节点,最终形成结构化的全局知识网络。
这一创新设计确保了跨视频内容的语义一致性,作为后续内容检索的基础。
混合检索范式:多维度视频理解
VideoRAG创新性地融合文本语义与视觉内容的双重匹配机制,通过深度语义理解与多模态信息融合,实现了超高精度的视频片段检索。该框架包含三大核心技术模块:
1)知识驱动的语义匹配模块: 基于知识图谱的高级语义理解机制,系统执行多层次的智能检索流程。
首先进行查询意图重构,随后通过实体关系网络进行精准匹配,继而完成相关文本块的智能筛选,最终定位目标视频片段。这种层级化的检索策略确保了语义理解的深度与准确性。
2)跨模态视觉内容匹配引擎: 系统采用先进的语义转换技术,将用户查询智能转化为标准化的场景描述。
通过专用多模态编码器,实时生成视频片段的高维特征向量表示,并基于创新的相似度计算算法,实现精确的跨模态内容匹配。这一设计显著提升了视觉语义检索的准确性。
3)基于大语言模型的智能过滤机制: 框架整合了先进的大语言模型(LLMs)技术,对检索结果进行多维度的相关性评估与智能筛选。
通过深度语义理解,有效过滤低相关性内容与噪声信息,确保系统输出高质量、准确度的回答。这种智能过滤机制提升了检索结果的可靠性。
响应生成:双阶段深度理解框架
在成功检索到相关视频片段后,VideoRAG通过创新性的双阶段内容理解与生成机制,实现高质量的智能问答:
基于大语言模型的语义理解与关键词提取。系统首先对用户查询进行深度语义分析,智能提取核心关键词与意图特征。
这些高价值的语义信息随后与精选的视频关键帧一起,输入到先进的视觉语言模型(VLM)中,生成富含视觉细节的场景描述。这种融合式的处理方法显著提升了系统对视觉内容的理解深度。
多模态知识整合与答案生成。在第二阶段,系统调用先进的大语言模型(如GPT4或DeepSeek),将检索到的多模态信息与用户查询进行深度融合。
通过专门优化的提示工程,模型能够综合利用文本语义、视觉特征和上下文信息,生成既包含丰富视觉细节,又具备深层语义理解的高质量回答。这一设计确保了系统响应的准确性、完整性和连贯性。
实验验证
团队在业界首个超长跨视频理解基准数据集LongerVideos上,对VideoRAG框架进行了系统性的性能评估与实验验证。评估工作涵盖三大关键维度:
(1) 与主流RAG框架的对比实验
通过与当前主流的检索增强生成系统(包括NaiveRAG、GraphRAG和LightRAG)进行全面对比,深入验证了VideoRAG在视频理解与信息检索方面的技术优势。
(2) 与当前视觉模型的性能对标
针对支持超长视频输入的大规模视觉模型(LLaMA-VID、NotebookLM、VideoAgent),进行了详尽的性能对比。
(3) 深入的模型组件分析
通过系统性的消融实验(包括移除知识图谱组件-Graph、视觉理解模块-Vision),结合典型案例分析,深入考察了各核心组件对系统整体性能的贡献。
LongerVideos超长视频理解基准测试数据
LongerVideos是首个专注于超长视频理解的综合性基准数据集,收录了总计164个高质量视频,累计时长突破134小时。
该数据集经过精心策划,系统性地涵盖了学术讲座、专业纪录片和综合娱乐节目三大核心应用场景,既确保了内容的多样性与代表性,也为跨视频推理能力的评估提供了坚实基础。
相较于现有视频问答基准数据集普遍存在的局限性(如单视频时长不足1小时、场景单一等),LongerVideos实现了显著的技术突破。
通过延长单个视频的时间跨度,并支持复杂的跨视频语义理解与推理,该数据集为超长视频理解技术的发展提供了更加全面、科学的评估基准。
这些创新特性不仅弥补了现有评估体系的不足,更为相关技术的进步提供了重要的测试数据集。
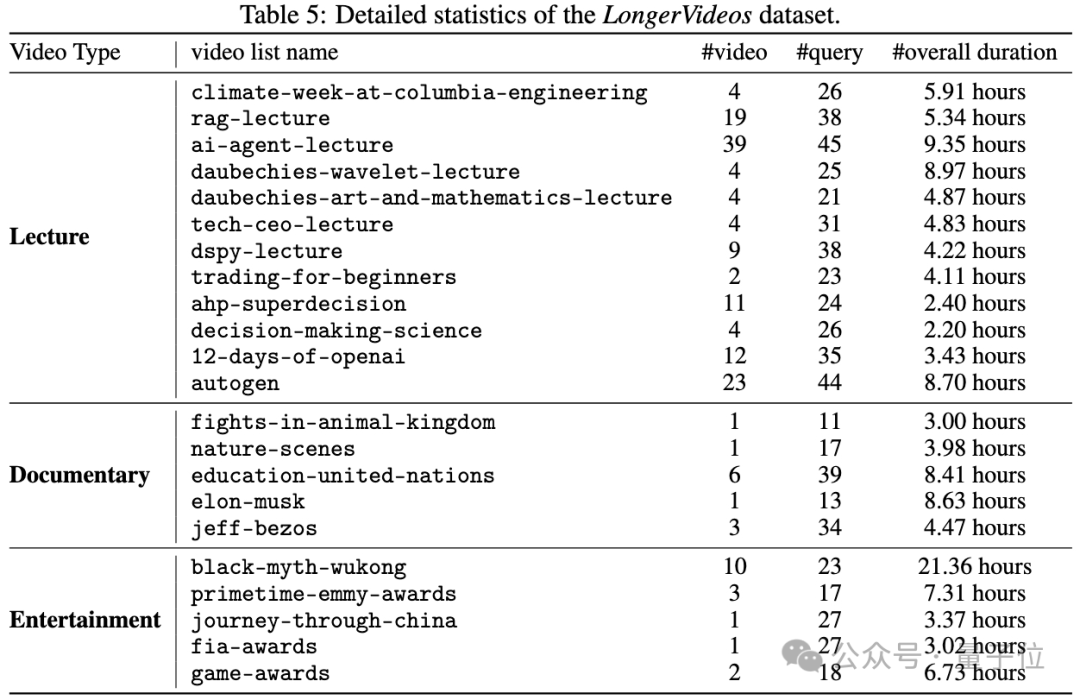
此外,团队设计了一套的双层评估框架,通过定性与定量相结合的方式,系统性地验证VideoRAG的性能表现:
胜率评估:采用基于大语言模型的智能评估方案,通过部署GPT-4-mini作为专业评判器,对比分析不同模型生成的答案质量。
定量评估:在胜率评估的基础上,建立了严格的定量评估体系。通过预设标准答案并采用精细的5分制评分标准(1分代表最低质量,5分代表最优表现),实现了评估结果的可量化与可比较性。
评估框架涵盖五个核心维度:
1、内容全面性(Comprehensiveness):衡量答案对相关信息的覆盖范围与完整度;
2、用户赋能性(Empowerment):评估答案在提升用户理解力与决策能力方面的效果;
3、回答可信度(Trustworthiness):考察答案的准确性、细节充实度及与常识的协调性;
4、分析深度(Depth):验证答案在解析问题时的深入程度与洞察力;
5、信息密度(Density):评估答案在保持精练性的同时传递有效信息的能力。

RAG综合性能评估:VideoRAG的技术优势
实验结果显示,VideoRAG在所有评估维度和视频类型中均展现出显著优势,全面超越了包括 NaiveRAG、GraphRAG和LightRAG在内的现有RAG方法。
这一卓越表现主要源于两大核心技术创新:首创的知识图谱索引与多模态上下文编码融合机制,精准捕获视频中的动态视觉特征与深层语义信息;以及创新的混合多模态检索范式,通过有机结合文本语义匹配与视觉内容嵌入检索,显著提升了跨视频检索的精确度。
与NaiveRAG相比,本系统在内容全面性(Comprehensiveness)和用户赋能性(Empowerment)方面表现卓越,这得益于其先进的知识索引架构和强大的跨视频信息整合能力。
实验证明,VideoRAG的创新架构能够更有效地处理和整合跨视频的复杂信息,为用户提供更加全面和深入的答案。
在与GraphRAG和LightRAG的对比中,VideoRAG在视觉-文本信息对齐和查询感知检索等关键技术指标上均实现突破,使生成的答案在上下文连贯性和理解深度方面获得显著提升,成功引领知识驱动型视频问答技术的新发展。
这些技术优势充分证明了VideoRAG在处理复杂视频理解任务时的卓越能力。

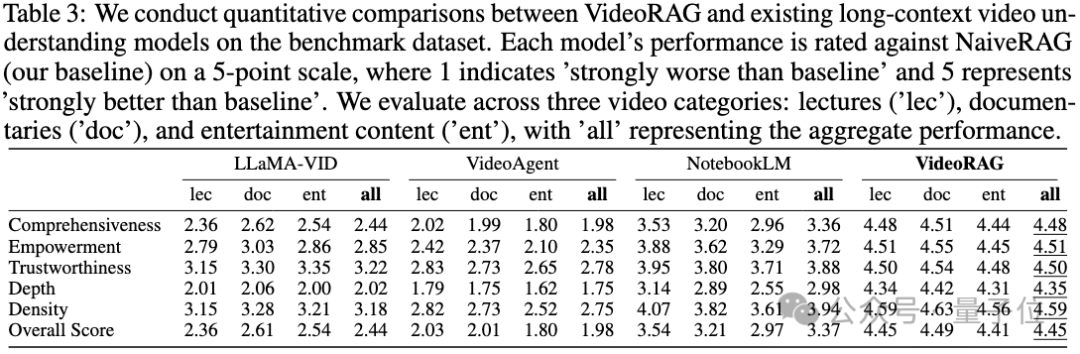
与长视频理解模型的性能对比
VideoRAG在所有维度和视频类型上性能均显著超越LLaMA-VID、NotebookLM和VideoAgent等主流长视频模型。这种全方位的性能优势,充分体现了本系统在处理超长视频内容时的技术的优势。
通过创新性地引入图增强的多模态索引和检索机制,VideoRAG成功突破了传统LVMs在处理长视频时面临的计算瓶颈。这一机制不仅能高效处理跨视频的知识连接,更可以准确捕捉复杂的信息依赖关系,在性能上显著超越了LLaMA-VID等现有模型。
相比仅依赖单一模态的基线模型(如专注于视觉的VideoAgent和侧重语音转录的NotebookLM),VideoRAG展现出优异的多模态信息融合能力。
系统通过精细的跨模态对齐机制,实现了视觉、音频和文本信息的深度整合,为超长视频内容理解提供了更全面、更深入的分析能力。
消融实验分析
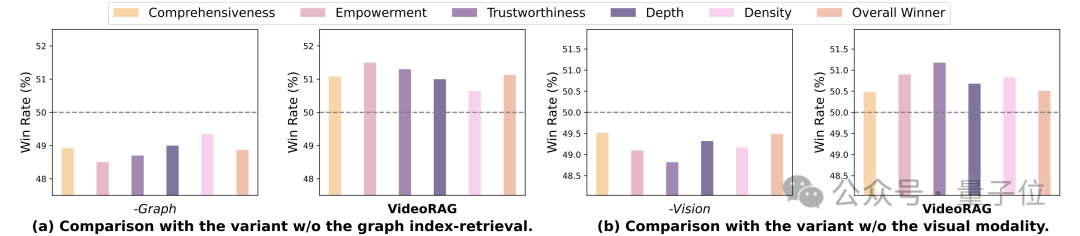
为系统评估VideoRAG框架中多模态索引和检索机制的有效性,团队设计了两组对照实验。
实验通过移除核心功能模块,构建了两个关键变体:变体1(-Graph)移除了基于图的索引-检索管道,变体2(-Vision)则去除了多模态编码器中的视觉索引和检索组件。
这种针对性的模块消融设计,使团队能够精确评估各核心组件的贡献度。
图索引机制的作用。变体1(-Graph)的实验结果显示,移除图形模块后系统性能出现显著下降。
这一现象有力证实了基于图的索引-检索机制在处理复杂视频内容时的关键价值。该机制不仅能有效捕捉跨视频间的深层关联,更在构建视频知识依赖网络方面发挥着不可替代的作用。
视觉处理能力的作用。变体2(-Vision)的实验数据同样呈现出性能的大幅下滑,充分说明了视觉信息处理对于视频理解的重要性。
这一结果强调了多模态上下文融合在提升系统整体性能方面的关键作用,突显了视觉模块作为VideoRAG框架核心组件的重要地位。
视频理解的案例分析
1、查询设置与数据来源
本案例选取了极具代表性的查询:”The role of graders in reinforcement fine-tuning”,基于OpenAI 2024年发布的12天系列视频(总时长3.43小时)进行分析。
目标信息主要集中在第2天的内容中,这种复杂的跨视频查询场景为系统性能评估提供了理想的测试环境。
2、VideoRAG的检索表现
实验结果展示了VideoRAG卓越的信息检索和整合能力。
系统准确定位并提取了第2天视频中的核心内容,包括评分员的基本定义、评分系统的运作机制以及具体的评分示例。通过多维度的信息聚合,VideoRAG成功构建了一个全面、准确且具有充分证据支持的专业回答。
3、系统性能对比分析
与LightRAG的对比结果凸显了VideoRAG在处理深度技术内容方面的显著优势。
尽管两个系统都能够提供评分系统的基础概念解释,但VideoRAG在评分员评分机制的技术细节阐述上明显更胜一筹。
相比LightRAG给出的表层描述,VideoRAG提供了更深入、更专业的技术解析,体现了系统在处理复杂专业内容时的独特优势。

本案例研究通过案例分析,再次验证了VideoRAG在三个核心技术维度的卓越性能:
1、知识图谱构建能力
系统展现出优异的知识图谱构建能力,不仅能精确捕获视频内容间的复杂关联关系,更能构建起完整的知识依赖网络,为深度理解提供了坚实基础。
2、多模态检索精度
在多模态信息检索方面,VideoRAG实现了高度精确的检索效果,能够准确定位和提取跨模态的关键信息,充分体现了系统在处理复杂信息检索任务时的技术优势。
3、跨视频信息整合
系统在处理和整合来自多个超长视频的关键信息时表现出色,通过先进的信息融合机制,实现了复杂视频内容的高效处理和准确理解。

VideoRAG: 技术创新与未来展望
突破性技术架构
VideoRAG通过开创性的双通道索引架构,成功实现了跨视频知识的深度关联与细粒度视觉特征的精确保留。这一创新设计不仅突破了传统视频理解的局限,更为复杂场景下的知识图谱构建开辟了新途径。
先进检索机制
系统创新性地提出混合检索范式,通过有机融合语义匹配与内容嵌入技术,显著提升了多模态信息的对齐精度。这种先进的检索机制为处理复杂的跨模态视频内容提供了更可靠的技术支持。
标准化评估体系
通过建立LongerVideos基准,VideoRAG为长视频理解研究提供了一个规范化的评估平台。这一基准的建立不仅推动了领域研究的标准化发展,也为后续技术突破提供了可靠的验证基础。
未来发展方向
展望未来,VideoRAG将重点拓展两大关键领域:实时视频流处理能力的增强,以及多语言支持体系的构建。这些创新探索将进一步扩展视频知识的应用边界,释放更大的视频理解技术潜力。
— 完 —