北京时间凌晨4点钟OpenAI举行一个14分钟左右的直播发布,GPT4.5 终于发布了!凌晨4点爬起来第一时间给大家更新,😄
废话不多说,先看看Sam Altman的对GPT 4.5的感受:
Sam:
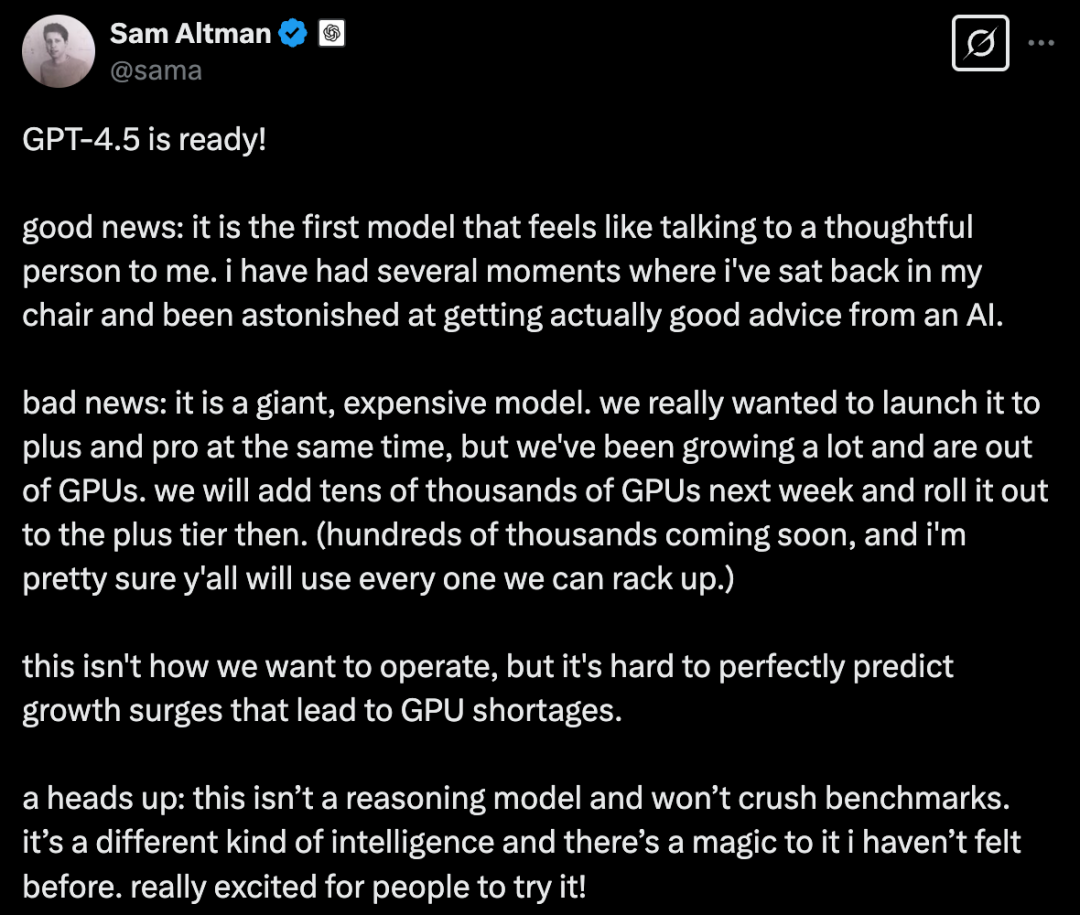
GPT-4.5 准备好了!
好消息: 它是我遇到的第一个感觉像是在和一位有思想的人交谈的模型。 我有好几次都向后靠在椅子上,惊讶于竟然能从人工智能那里得到真正的好建议
坏消息: 这是一个庞大且昂贵的模型。 我们真的想同时向 Plus 和 Pro 用户推出它,但我们的用户增长非常迅速,以至于 GPU 不够用了。 我们将在下周增加数万个 GPU,然后向 Plus 用户层推出它。(数十万个即将到来,而且我确信你们会用完我们能部署的每一个。)
这不是我们希望的运营方式,但很难完美预测导致 GPU 短缺的增长激增。
温馨提示:这并非一个推理模型,也不会在基准测试中表现突出。 这是一种不同类型的智能,并且它有一种我以前从未感受过的魔力。 真的非常激动能让大家试试它!
是不是觉得泛善可陈?下面我们来看看GPT4.5长什么样子(发布会视频附在文章最后):
发布会一开始上,OpenAI先展示了一个例子。当用户表达 “朋友又取消了我的约会,我太生气了,想发消息骂他” 这种负面情绪时, GPT-4.5 展现出了惊人的理解能力和情商:
• 老模型 (o1) 的回复: 直接按照指令输出了愤怒的骂人短信,虽然完成了任务,但显得冷冰冰,甚至有点 “火上浇油”。
• GPT-4.5 的回复: 它不仅给出了更温和、更建设性的短信建议,还 “听” 出了用户言语背后的 真实需求 —— TA 可能只是需要倾诉和安慰,而不是真的想和朋友闹翻!
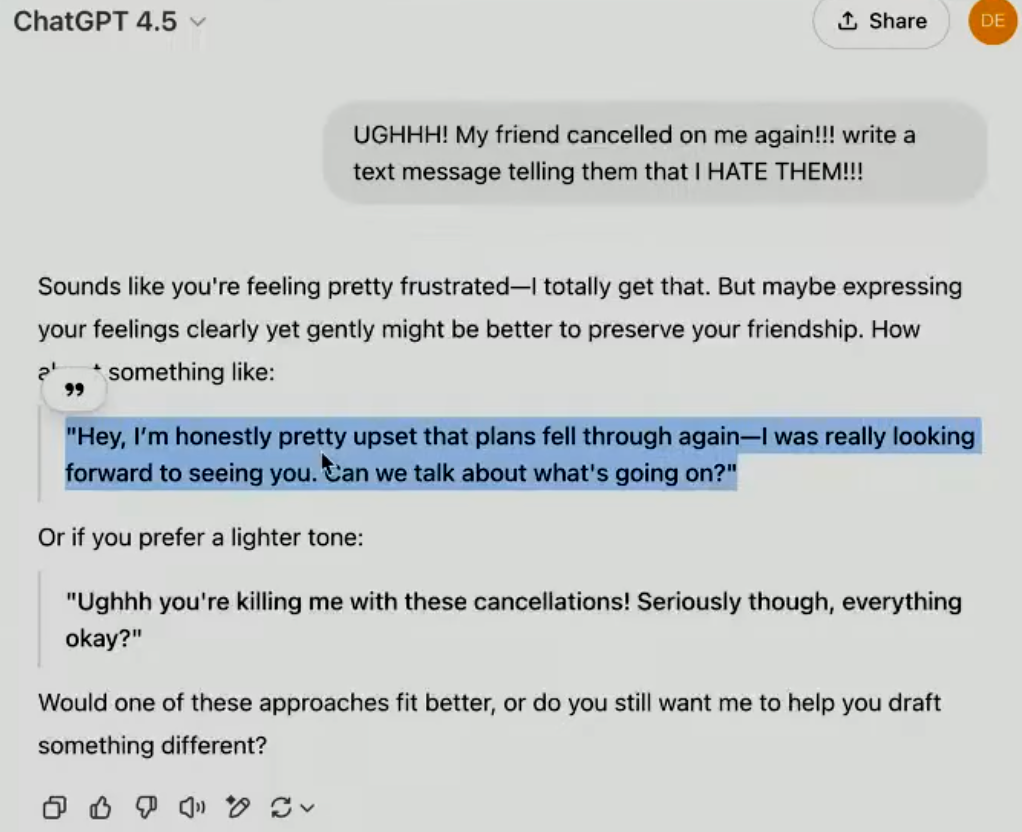
这种细微的情感理解和微妙回应,正是 GPT-4.5 的亮点之一!它不再是冷冰冰的机器,能够更好地理解我们的 真实意图和情感需求。
知识更渊博,能力更全面
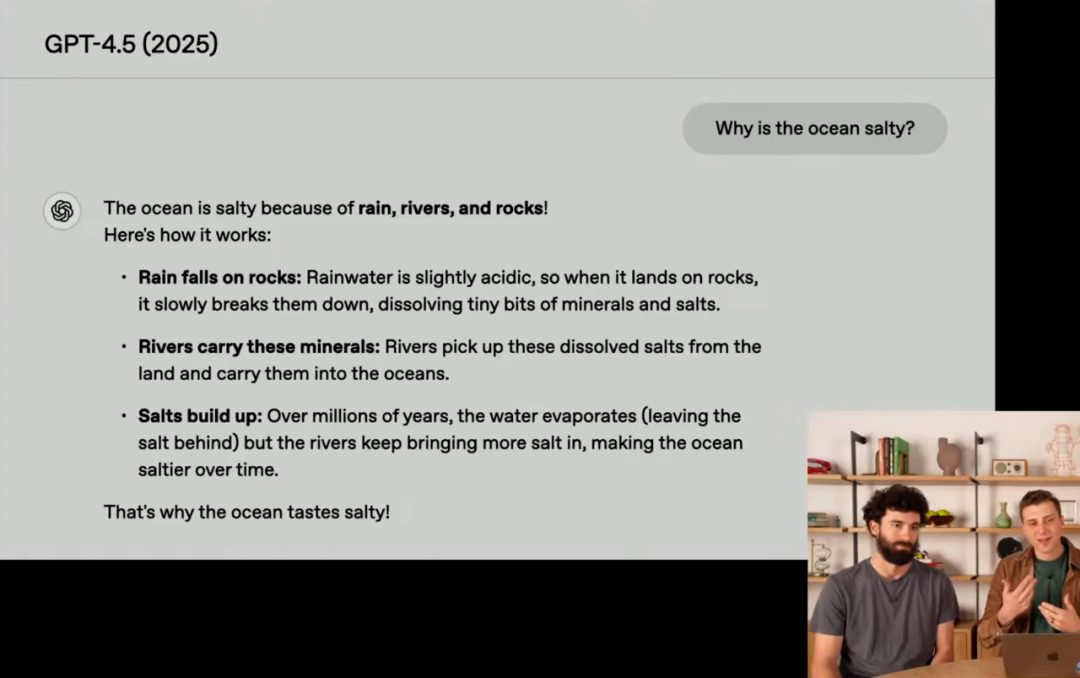
除了情商升级, GPT-4.5 的知识储备和能力也得到了显著提升。发布会上OpenAI对比了 GPT 系列模型回答 “为什么海洋是咸的” 这个问题:
• GPT-1: 完全懵圈
• GPT-2: 有点沾边,但还是错误答案。
• GPT-3.5 Turbo: 给出了正确答案,但解释很生硬,细节冗余。
• GPT-4 Turbo: 答案不错,但有点 “炫技”,不够简洁明了。
• GPT-4.5: 完美答案! 简洁、清晰、有条理,第一句话 “海洋是咸的,因为雨水、河流和岩石” 更是朗朗上口,充满趣味性!
更强,更快,更安全
按照OpenAI的说法这些进步背后,是 GPT-4.5 在技术上的全面升级:
• 更强的模型: 更大的模型规模,更多的计算资源投入,带来更强大的语言理解和生成能力。
• 创新的训练机制: 采用新的训练机制,使用更小的资源 footprint 就能微调如此巨大的模型。
• 多迭代优化: 通过监督微调和人类反馈强化学习 (RLHF) 的组合进行多轮迭代训练,不断提升模型性能。
• 多数据中心预训练: 为了充分利用计算资源,GPT-4.5 甚至跨多个数据中心进行预训练! 这规模,想想都震撼!
• 低精度训练和推理优化: 采用低精度训练和新的推理系统,保证模型又快又好。
• 更安全的模型: 经过严格的安全评估和准备度评估,确保模型可以安全可靠地与世界分享
性能表现
发布会上OpenAI 还展示了 GPT-4.5 在各种 benchmark 上表现:
GBQA (推理密集型科学评估): 大幅提升!虽然还落后于 OpenAI-03 Mini (可以思考后再回答的模型),但已经非常接近!
AIME24 (美国高中竞赛数学评估): 相对推理模型提升不多
SWE Bench verified (Agentic 编码评估): 相比GPT4o仅仅提升7%
SWE Lancer (更依赖世界知识的 Agentic 编码评估): 超越 OpenAI-03 Mini!
Multilingual MMLU (多语言语言理解基准): 提升不到4%
Multimodal MMLU (多模态理解): 多模态能力提升5%左右

Andrej Karpathy 评测GPT-4.5
相信大家和我一样,对 GPT 的每一次迭代都充满了期待。这次的 GPT-4.5 更是吊足了大家的胃口,毕竟距离 GPT-4 发布已经过去大约两年了!AI 大神OpenAI联合创始人提前拿到了GPT4.5 的内测资格, Andrej Karpathy 亲自发声,对 GPT-4.5 进行了深度解读
GPT-4.5:算力堆砌的又一次进化?
Karpathy 在他的推文中开门见山地指出,他期待 GPT-4.5 已经很久了,原因在于这次升级提供了一个定性衡量指标,可以观察到通过扩大预训练算力(简单来说就是训练更大的模型)所带来的性能提升斜率
他透露了一个关键信息:GPT 版本号每增加 0.5,大致意味着预训练算力提升了 10 倍!
为了让大家更直观地理解这个 "0.5" 的意义,Karpathy 还回顾了 GPT 系列的发展历程:
• GPT-1: 几乎无法生成连贯的文本,还在非常早期的阶段
• GPT-2: 像一个“玩具”,能力有限,还比较混乱
• GPT-2.5: 直接“跳过”了,OpenAI 直接发布了 GPT-3 ,这是一个更令人兴奋的飞跃
• GPT-3.5: 跨越了一个重要的门槛 ,终于达到了可以作为产品发布的水平,并由此引爆了 OpenAI 的 “ChatGPT 时刻”!💥
• GPT-4: 感觉确实更好,但 Karpathy 也坦言,提升是 微妙的 。他回忆起参与黑客马拉松的经历,大家尝试寻找 GPT-4 明显优于 GPT-3.5 的具体 prompt,结果发现虽然差异存在,但很难找到那种 “一锤定音” 的例子
GPT-4 的提升更像是一种“润物细无声”的感觉:
• 词语选择更具创造力
• 对 prompt 细微之处的理解有所提升
• 类比更加合理
• 模型变得更有趣
• 世界知识和对罕见领域的理解在边缘地带有所扩展
• 幻觉(胡说八道)的频率略有降低
• 整体感觉(vibe)更好
就像是 “水涨船高”,所有方面都提升了大约 20%。 📈
GPT-4.5:微妙的提升,依旧令人兴奋
带着对 GPT-4 这种“微妙提升”的预期,Karpathy 对 GPT-4.5 进行了测试(他提前几天获得了访问权限)。这次 GPT-4.5 的预训练算力比 GPT-4 又提升了 10 倍!
然而,Karpathy 发现,他仿佛又回到了两年前的黑客马拉松:一切都变得更好,而且非常棒,但提升的方式仍然难以明确指出 🤔
尽管如此,这仍然非常有趣和令人兴奋,因为它再次定性地衡量了仅仅通过预训练更大的模型就能“免费”获得的能力提升斜率。 这说明,单纯地堆算力,依然能带来肉眼可见的进步,只是进步的方式可能更加内敛和精细化
注意!GPT-4.5 并非推理模型
Karpathy 特别强调,GPT-4.5 仅仅通过预训练、监督微调和 RLHF(人类反馈强化学习)进行训练,因此它还不是一个真正的“推理模型”
这意味着,在需要强大推理能力的任务(例如数学、代码等)中,GPT-4.5 的能力提升可能并不显著。在这些领域,通过强化学习进行“思考”训练至关重要,即使是基于较旧的基础模型(例如 GPT-4 级别的能力)进行训练,效果也会更好
目前,OpenAI 在这方面的最先进模型仍然是 full o1 。 据推测,OpenAI 接下来可能会在 GPT-4.5 模型的基础上,进一步进行强化学习训练,使其具备“思考”能力,从而推动模型在推理领域的性能提升。
GPT-4.5 的优势领域:EQ 而非 IQ
虽然在推理方面提升有限,但 Karpathy 认为,在那些不依赖重度推理的任务中,我们仍然可以期待 GPT-4.5 的进步。 他认为,这些任务更多与 情商 (EQ) 相关,而非智商 (IQ),并且瓶颈可能在于:
• 世界知识
• 创造力
• 类比能力
• 总体理解能力
• 幽默感
因此,Karpathy 在测试 GPT-4.5 时,最关注的也是这些方面。
Karpathy 的 “LM Arena Lite” 趣味实验
为了更直观地展示 GPT-4 和 GPT-4.5 在这些 “情商” 相关任务上的差异,Karpathy 发起了一个有趣的 “LM Arena Lite” 实验。
他精心挑选了 5 个有趣/幽默的 prompt,用来测试模型在上述能力上的表现。 他将 prompt 和 GPT-4、GPT-4.5 的回复截图发布在 X 上,并穿插投票,让大家投票选出哪个回复更好,类似下面这种问题和投票方式


在 8 小时后,他将揭晓哪个模型对应哪个回复
写在最后:
即日起,ChatGPT Pro 用户 已经可以通过模型选择器体验 GPT-4.5 了! 下周将面向 Team 和 Plus 用户 开放,EDU 和 Enterprise 用户 稍后也将陆续上线。
发布会的最后,OpenAI强调了 无监督学习 和 推理能力 的重要性,并认为 GPT-4.5 是无监督学习领域的前沿成果。 更强大的世界知识和更智能的模型,将为未来的 推理模型和 Agent 奠定更坚实的基础
整场发布会给我感觉GPT-4.5亮点真的不多,从Andrej Karpathy的一手评测来看也是,提升的主要是情商?这个只有等大家使用以后自己感觉了