作者 | 程茜
编辑 | 心缘
智东西2月27日报道,刚刚,DeepSeek开源周第四弹来袭,豪气一举开源三个代码库。
DualPipe:一种双向流水线并行算法,用于V3/R1训练中的计算-通信重叠;EPLB:用于V3/R1的专家并行负载均衡器;profile-data:训练和推理框架的分析数据。

DualPipe通过重叠计算和通信来减少训练的空闲时间,EPLB平衡了工作负载,使得几乎没有GPU闲置的情况,
值得一提的是,DualPipe的开发人员中有梁文峰参与。

DeepSeek的评论区开发者们依然持续夸夸夸,有人称其“打开了最后的封印”。
有人开始称赞DeepSeek的团队合作能力。
依然有网友在担心自己的英伟达股票:

GitHub地址:
https://github.com/deepseek-ai/DualPipe
https://github.com/deepseek-ai/eplb
https://github.com/deepseek-ai/profile-data
一、DualPipe:双向流水线并行算法
DualPipe是DeepSeek-V3技术报告中介绍的一种创新的双向Pipeline并行算法。它实现了前向和后向计算通信阶段的完全重叠,也减少了流水线气泡。
在两个方向上,8个PP列和20个微批的DualPipe调度示例,其中两个被共享黑边包围的单元具有相互重叠的计算和通信。

流水线气泡和内存使用情况比较:

𝐹表示前向块的执行时间,B表示完全后向块的执行时间,W表示“权重后向”块的执行时间,𝐹&𝐵表示两个相互重叠的前向和后向块的执行时间。
快速启动:

注:对于实际应用程序,开发者需要实现一个定制的overlapped_forward_backward方法,以适应特定模块。
开发要求PyTorch 2.0 and above PyTorch 2.0及以上。
二、负载均衡算法EPLB,涵盖分层负载平衡和全局负载平衡
开源的另一个代码库是EPLB。

当使用专家并行(EP)时,不同的专家被分配到不同的GPU。由于不同专家的负载可能会因当前工作负载而异,因此保持不同GPU的负载平衡非常重要。正如DeepSeek-V3论文中所述,研究人员采用冗余专家策略,复制重载专家。然后将重复的专家打包到GPU上,以确保不同GPU之间的负载平衡。
此外,由于DeepSeek-V3中使用的组限制专家路由,DeepSeek还尝试将同一组的专家放置到同一节点,以尽可能减少节点间的数据流量。
为了便于复制和部署,DeepSeek在eplb.py中开源了EP负载均衡算法。该算法计算一个平衡的专家复制和放置计划的基础上估计的专家负载。
负载平衡算法有分层负载平衡和全局负载平衡两种策略,可用于不同的情况。
当服务器节点的数量除以专家组的数量时,其使用分层负载平衡策略来利用组限制的专家路由。首先将专家组均匀打包到节点上,确保不同节点的负载均衡。然后在每个节点内复制专家,最后将复制的专家打包到各个GPU,以确保不同的GPU负载平衡。分层负载均衡策略可以在预填充阶段使用,专家并行规模较小。
其他情况下使用全局负载平衡策略,在全局范围内复制专家,而不考虑专家组,并将复制的专家打包到单个GPU。该策略可用于专家并行度较大的解码阶段。
接口和示例:负载均衡器的主要功能是eplb.rebalance_experts。
下面的代码演示了一个两层MoE模型的示例,每层包含12个专家,每层引入4个冗余专家,在2个节点上放置16个副本,每个节点包含4个GPU。

三、在DeepSeek Infra中分析数据
最后一个是DeepSeek训练和推理框架的分析数据。
使用PyTorch Profiler捕获分析数据。下载后,开发者可以通过在Chrome浏览器中导航到Chrome://跟踪(或在Edge浏览器中导航到edge://跟踪)来直接将其可视化。他们模拟了一个绝对平衡的MoE路由策略来进行性能分析。
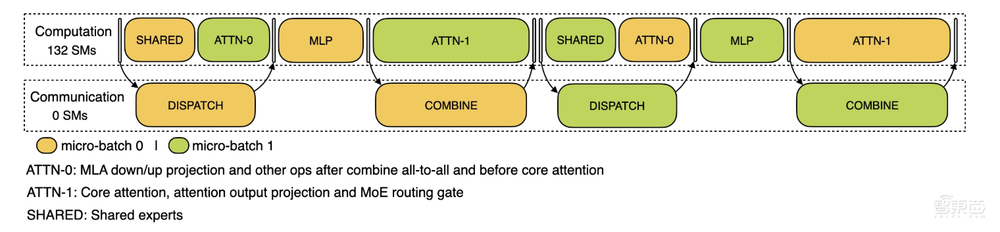
训练配置文件数据展示了其在DualPipe中针对一对单独的向前和向后块的重叠策略。每个块包含4个MoE层。并行配置与DeepSeek-V3预训练设置对齐:EP 64,TP 1,4K序列长度。为了简单起见,在分析期间不包括PP通信。

推理过程,对于预填充,该配置文件采用EP 32和TP 1(与DeepSeek V3/R1的实际在线部署一致),提示长度设置为4K,每个GPU的批量大小为16 K令牌。在我们的预填充阶段,我们利用两个微批来重叠计算和所有对所有的通信,同时确保注意力计算负载在两个微批之间平衡-这意味着相同的提示可以在它们之间分割。
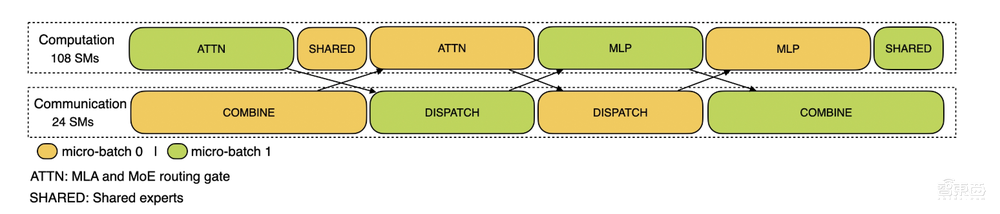
对于解码,该配置文件采用EP 128,TP 1和4K的提示长度(与实际在线部署配置密切匹配),每个GPU的批量大小为128个请求。与预填充类似,解码也利用两个微批进行重叠计算和全对全通信。然而,与预填充不同,解码期间的全对全通信不占用GPU SM:在发出RDMA消息后,所有GPU SM被释放,并且系统在计算完成后等待全对全通信完成。