DeepSeek利润神话背后:大厂AI的焦虑和自救
作者 | 定焦One 王璐
AI似乎成了大厂的“救命稻草”。
无论财报里的亮点数据,还是隔三岔五的利好信息,都离不开AI。
比如在百度2024年这份喜忧参半的财报中,高光时刻基本都是AI给的:
文心大模型日均调用量持续高速增长,一年增长33倍至16.5亿。百度文库付费用户超4000万,位居全球第二、中国第一。
阿里也凭借着AI在开年来了三连击:
先是受DeepSeek影响,同为开源大模型的阿里通义千问(Qwen)受到关注;接着发布的最新模型Qwen2.5-Max,被评价为性能超越DeepSeek V3;随后又宣布与苹果就AI业务达成合作,股价猛涨。
不过,DeepSeek出圈 近40天以来,大厂AI承受的焦虑多过收获,毕竟各家都投入了大量人力、物力、财力,最后一鸣惊人的却是一个初创团队做出的产品。这两天,DeepSeek还首次公开了爆炸性消息——其成本利润率高达545%(理论收益),利润理论上可达每天346万元。
在种种冲击之下,大厂纷纷改变路线,一边打不过就加入,纷纷宣布接入DeepSeek,一边将自家大模型从闭源转向开源,甚至不惜自断一条商业化路径,将C端产品免费。
可是,这波操作,真能治好大厂的AI焦虑症吗?
大厂AI,做得怎么样了?
在DeepSeek出现前,大厂做AI的路线是高举高打、重投入,围绕自身优势做产品。
大模型被视为AI行业的基础设施,互联网大厂(百度、腾讯、阿里、字节、快手等)、消费电子厂商(华为为代表)、智能语音厂商(科大讯飞等),都推出了自研大模型。相比“AI六小虎”这类初创公司,大厂的优势在于具备更雄厚的资金和人才储备。
从AI行业整体技术迭代速度,以及各家的公开信息来看,大厂大模型在底层技术上没有根性本差别,但在入场时间、模型定位、市场策略上有所不同,具体区别如下:
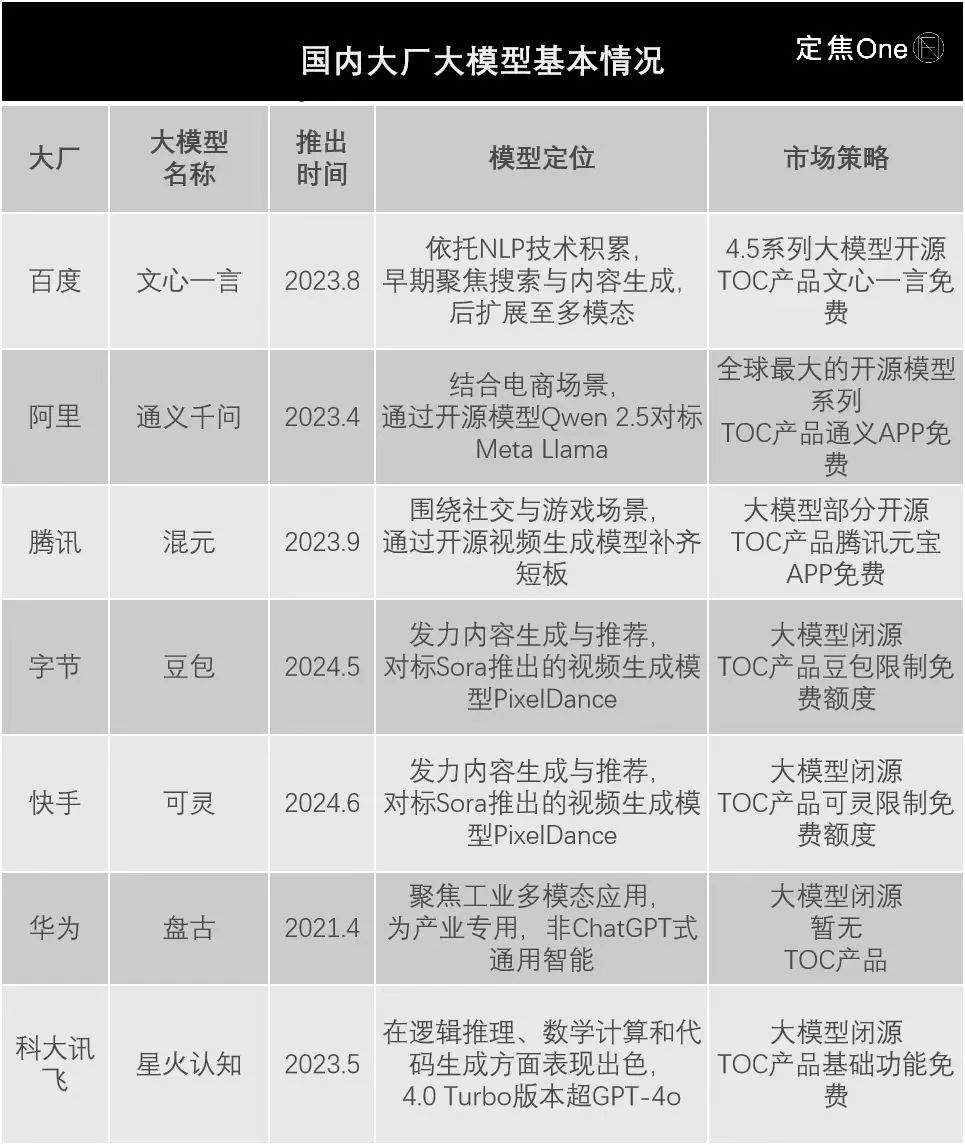
这三大不同,在一定程度上代表的是大厂早期对AI的态度和定位。
比如大模型发布的时间,“早”代表的是该大厂在相关技术领域有较早布局和技术积累,且反应较快,但风险是技术尚未完全成熟,投入的技术研发和市场推广费用相对更高。
从上表来看,华为最早,但需要注意的是,虽然其底层也是基于Transformer架构,但与ChatGPT式对话完全不同,属于AI大模型在“产业专用”方向(ChatGPT式为通用智能)。如果聚焦通用智能大模型,则是百度最早行动,在2023年3月便启动了文心一言大模型的邀测(非全面开放)。
不过,推出时间早晚并不是衡量模型好坏的核心要素。
大厂的业务布局决定着大模型的应用方向,也造就了不同大模型定位,从技术上挖掘,其来源于各家的训练数据。
百度文心一言主要靠互联网文本数据;阿里通义千问为文本、图片、音频等多模态数据;腾讯混元为社交网络和用户行为数据;字节豆包约50%-60%来自字节的自有业务(抖音、今日头条)数据;华为盘古大模型则是用了包含工业、气象、文图、图像在内的各类数据。
这也让各家大模型的优势场景不同,比如文心一言在长文本处理和多语种对话上占优;混元在社交场景更胜一筹;豆包在生成内容和精准推荐上更为领先;通义千问在电商推荐场景响应更快;盘古执行速度和泛化能力出色,能高效应对大规模任务。
不难发现,各家大模型的优势领域都有着其核心业务的影子。
最后看市场策略,在一定程度上反映的是,大厂对自身能力和行业趋势的判断,外界可大致观察到的内容分为两块,开闭源与TO C产品是否免费。
字节、快手、讯飞、华为目前还在坚持闭源,百度、腾讯、阿里则选择大部分开源。在TO C应用上,百度、腾讯、阿里选择了免费路线,字节、快手、讯飞多为提供有限次数的免费额度。
开源的甜头已经被阿里吃到,开源AI平台Hugging Face发布的最新开源大模型榜单显示,排名前十的开源大模型全部是基于阿里通义千问的衍生模型。
在TO C产品中,坚持免费的豆包在一年中涨势最猛。根据AI产品榜显示,2025年1月,豆包在国内千万月活俱乐部中排名第一,为7861万,远超其他大厂应用。
不过,大家更好奇的是大厂大模型整体能力的排名。据多位从业者分析,目前大厂的顶级大模型以闭源为主,在信息不完全透明的情况下,判断各家能力并非易事。
弗若斯特沙利文在《2024年中国大模型能力评测》报告中指出,百度文心一言、腾讯混元、阿里通义千问等大厂大模型都位于第一梯队,认为它们在技术能力上较为全面,用户量也相对较大。但哪家整体能力更为出色,没有给出明确判断。
AI软件工程师覃相表示,各家在技术架构和训练数据等方面都存在差异,比如从技术架构来看,模型规模和参数量是衡量大模型复杂程度和能力的重要指标。一般来说,规模越大、参数越多,模型的学习能力和表达能力就越强。比如,DeepSeek-R1被称作参数上的巨无霸,高达6710亿的参数打造了一个庞大的知识储备库。
他表示,从这一维度判断,在大厂里的大模型中,具有深度推理能力的大模型,比如文心一言在一众大厂中能力更强。但如果看垂直领域的能力,文心一言便比不上通义千问,毕竟后者开发并上线了基于自身的8个垂直领域模型。
总之,各家大模型的优势都不一样,很难有一家在各个维度上都碾压其他家。
DeepSeek出圈40天,大厂四大转变
DeepSeek的出现,促使大厂重新审视自身的AI战略布局,结合各家最新动态及从业者的说法,具体有四大转变。
一是从闭源到开源,这也是最重大的转变。
不止一位从业者指出,DeepSeek的火爆离不开开源。
之前国内外对大模型开闭源的讨论一直没有停过,百度董事长李彦宏曾是闭源的忠实支持者,认为无论保持技术领先性还是商业模式,闭源都强于开源。
覃相从技术角度分析,开源意味着核心代码公开,竞争对手可快速复现技术路径,大厂早期选择闭源主要是为了保护知识产权和商业壁垒(如OpenAI早期未开源GPT-3)。
但他发现,在DeepSeek的带动下,大厂已经转变了方向,更倾向于通过生态绑定(如腾讯混元开源视频模型,吸引开发者使用其云服务)实现长期收益,而不像之前那样单纯依赖技术保密。
如今百度已经宣布文心大模型4.5系列将于2025年6月底全面开源。截至目前,百度、阿里、腾讯的大部分模型都已经开源或者宣布开源。
二是业务重点从TO B转向“双线并行”。
覃相解释,大模型变现主要有三种方式:增值服务、数据变现、合规服务,其中增值服务占比最大,靠的是企业级定制与API调用收入。他透露,百度文心一言企业版年费超千万元,阿里云通义千问为政企客户提供定制化客服系统,单项目合同额可达数亿元。
也就是说,大厂当前盈利仍主要依赖B端,但近期很多大厂开始重视TO C应用的推广,改为TO B、TO C“双线并行”。
例如腾讯加大对元宝的宣传,一方面将其接入到微信九宫格,拥有了强流量入口,另一方面多渠道打广告,除了在腾讯生态产中做推广外,抖音、B站、知乎也做了大量投放。
根据App Growing数据显示,在2月广告投放强度前20中的AI工具中,大厂AI产品都有上榜(华为没有TOC产品未在其中)。其中花钱最多的便是腾讯元宝,今年2月,其投放金额占比达到了总金额的46%,快赶上过去9个月的总和,超过了字节的豆包。
另外,阿里也大规模招聘TO C业务相关人才。
从业者认为,可能是DeepSeek的开源+API低价给大厂TO B业务带来了更大压力,进而想在TO C上找到更多商业化出路。
方向转变之三是TO C应用从收费变为免费。
DeepSeek好用且免费,在它大火后,国内百度的文心一言、国外OpenAI将露面的GPT-5,都宣布将免费对用户开放。
“目的在于拉拢更多用户,提高市场占有率。”覃相表示,更多的用户反馈可以进一步优化模型性能,从而提升B端服务能力,收取更高的企业定制模型费。
转变之四是从重投入到降本打价格战。
在过去几年的“百模大战”中,国内外AI大模型公司砸出了几十亿甚至上百亿美元,而DeepSeek仅以557.6万美元的GPU成本,就训练出了与OpenAI o1能力不相上下的DeepSeekR1模型,这让大厂开始反思。
不止一位从业者表示,大厂降本从去年下半年就已经开始,但DeepSeek的出现加速了这一趋势。
覃相能明显感觉到,从去年开始,大模型的竞争已经从“技术为先”转向为“成本+生态”。比如去年1月豆包1.5Pro发布的API价格就大幅下降,12月字节又将视觉模型价格降幅打到85%,推动行业进入“厘时代”。
今年2月,两位老百度人还因为大模型价格“隔空交战”,百度智能云事业群总裁沈抖在百度智能云事业群组(ACG)全员会上指出,国内大模型行业存在“恶意价格战”并点名豆包,随后字节火山引擎总裁谭待在朋友圈回应,指出降价是技术进步的必然结果。
DeepSeek也没闲着,刚宣布完API优惠期结束,2月26日又宣布“限时降价”,每日00:30-08:30,DeepSeek-V3降至原价的50%,DeepSeek-R1低至25%,降幅最高达75%。
大厂的压力更大了。
免费、开源,大厂能否赢回主场?
综合从业者的说法,在四大变化中,目前对大厂影响最大的是开源和免费。
先来看开源。
大模型领域专家刘聪指出,在DeepSeek没露面前,无论国外的OpenAI,还是国内大厂,要么选择全部闭源,要么选择开源部分大模型(非最好版本),DeepSeek则是将其最厉害的推理大模型DeepSeek-R1也选择了开源,这是从业者非常兴奋的点。
不过,开源也面临着一些收益损失和技术风险。
人工智能博士微凉表示,开/闭源代表的是间接/直接变现两种商业模式和开发思路。国内大厂的典型开源代表是阿里通义千问大模型,通过给厂家做适配进一步促成商业上的合作,此举是基于自身生态做出的选择。
但很多大厂起初做大模型的定位是技术主导,将其视为生产力,比如OpenAI、百度、华为、科大讯飞,大模型订阅费是很重要的一块收入来源,选择开源肯定会影响到收益。
开源还会面临恶意攻击和社区维护风险。比如在代码公开下,恶意攻击者可以通过分析代码寻找漏洞,从而对使用这些模型的系统进行攻击。
后续的社区维护也是个问题。覃相表示,开源需要持续投入资源维护开发者社区(如提供文档、技术支持、版本更新),否则可能导致技术生态分散。他解释,若开发者自行修改代码并衍生出多个分支(如Linux的分支Ubuntu、CentOS),会加大统一技术标准的难度,导致“技术碎片化”。
部分从业者直言,即便大厂开源,对他们的吸引力也有限。
开源的目的是吸引技术开发者和合作公司,让大家使用其大模型进行技术迭代和应用开发,但微凉博士认为,“目前各家开源有打广告嫌疑。”
“开源能看到的是大模型的推理方法和参数权重,但更重要的数据筛选方法和模型训练技巧,各家都没有放开,这也导致普通开发者很难去做技术迭代。”他表示。
值得注意的是,开源不等于全免费,使用者还要履行大模型提供商的开源协议,其中便包含“付费条款”。
比如微凉博士会用阿里通义千问大模型做一些AI应用,利用千问将技术跑通后,若想进一步做企业定制化微调和适配,便需要联系工作人员。他还透露,开源协议也会有公司规模等限制条款,比如员工人数达到一定数量时,就需要付费。
再来看免费带来的影响。
大厂采取免费策略的目的是想快速占领C端市场,比如突出代表便是一直对用户免费的豆包,QuestMobile数据显示,截至2025年2月9日,豆包周日均(以2月3日-2月9日这一周为周期,计算平均每天的活跃用户数)活跃用户数为1845万,仅次于DeepSeek,高于Kimi、文小言、通义、元宝。
不过免费的意义有多大,从业者还拿不准。这既因为用户对chatbot这类工具的忠诚度很低,也因为国内用户的付费意识并不强。
“即便是需要付费的AI生成视频工具,国内大部分应用也靠提供免费积分来吸引用户使用。”一位从业者表示,他觉得豆包能在一众同类通用型AI产品中跑出来,除免费外,和字节强大的市场推广也分不开。
覃相认为,DeepSeek的鲶鱼效应倒逼大厂从技术竞赛转向成本与生态的综合较量, 开源、免费策略是一把应对竞争与生态构建的“双刃剑” ,即便这些措施短期内会降低自身收益,也不得不为。
DeepSeek引发的鲇鱼效应,还未结束。
Disclaimer: Investing carries risk. This is not financial advice. The above content should not be regarded as an offer, recommendation, or solicitation on acquiring or disposing of any financial products, any associated discussions, comments, or posts by author or other users should not be considered as such either. It is solely for general information purpose only, which does not consider your own investment objectives, financial situations or needs. TTM assumes no responsibility or warranty for the accuracy and completeness of the information, investors should do their own research and may seek professional advice before investing.
Most Discussed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10