3 月 29 日,驾驶着小米 SU7 却撞上护栏,引发汽车起火,造成车内三人死亡的案件,一直在被议,无论是车主还是围观群众,都在等待小米下一步的行动。
很快就传出一封详细列出安排和计划的“公开信”出现在网上:
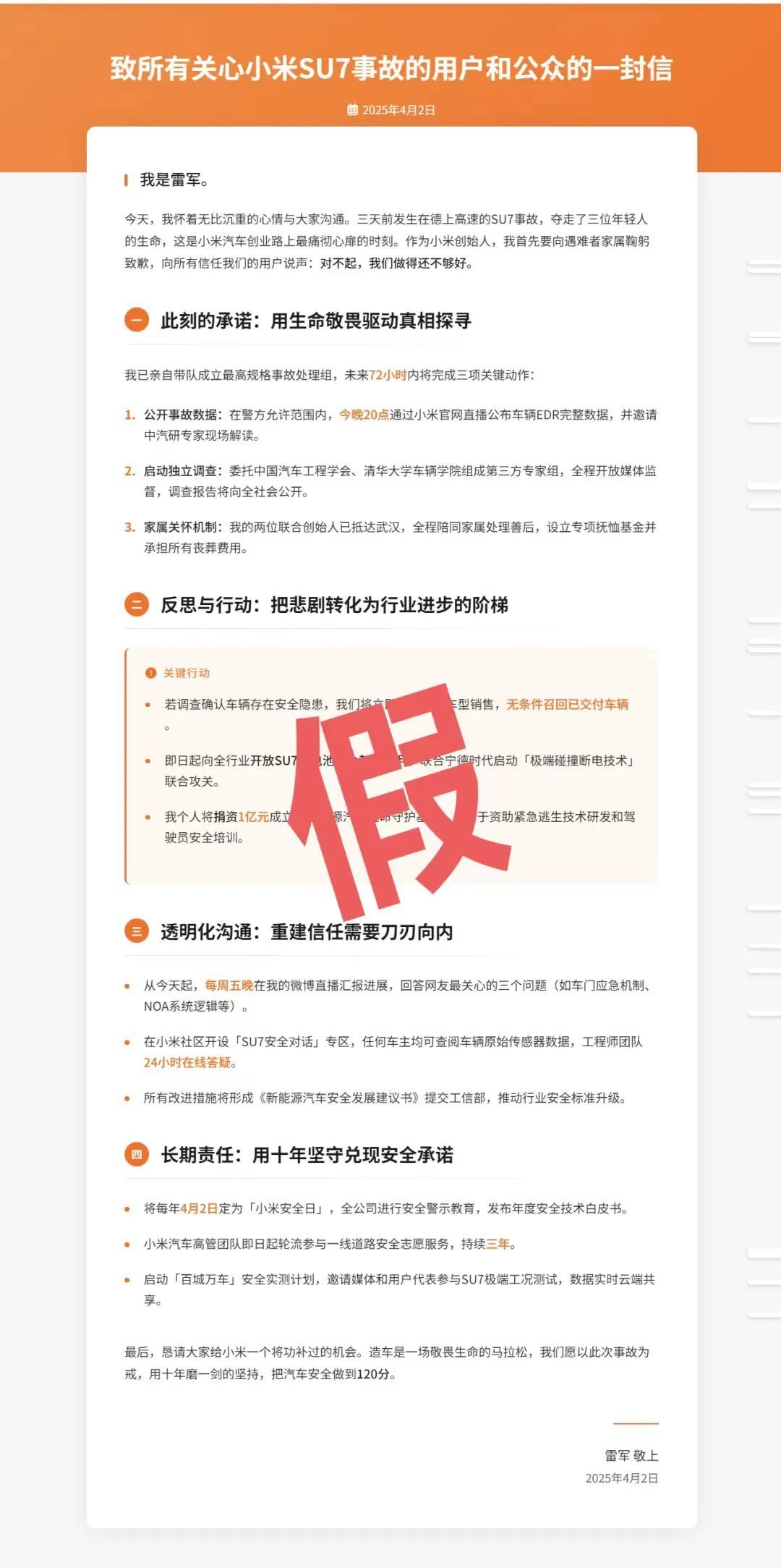
哦等下, 这是假的。
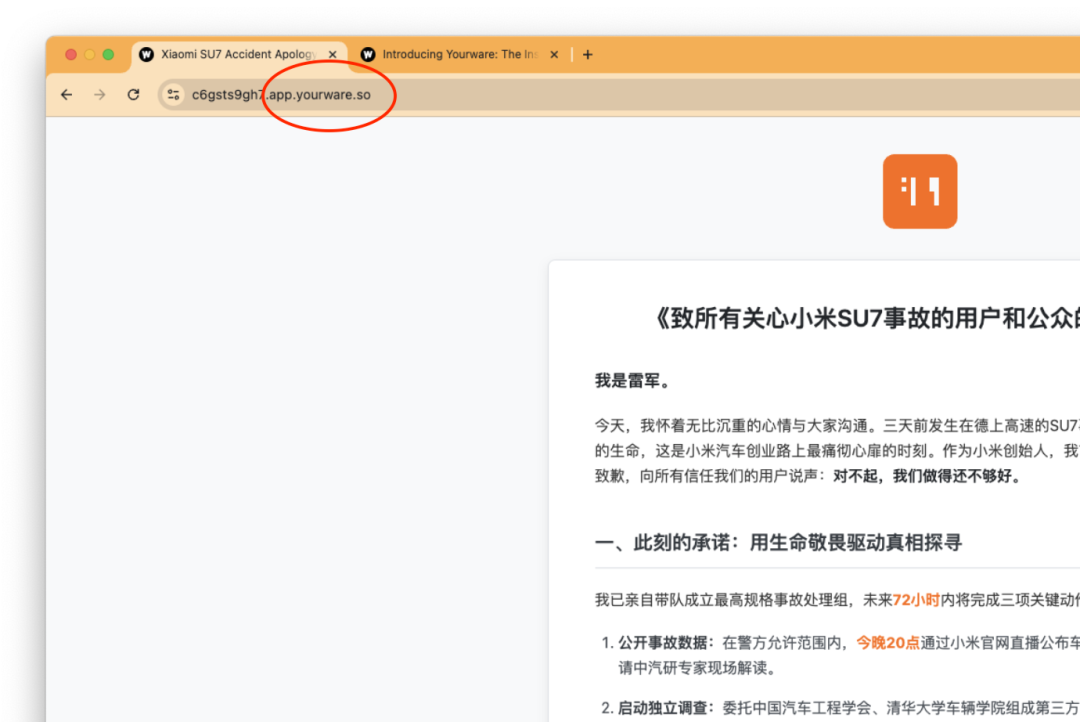
这是一个借助 AI 生成网页的平台,主打一个简单易用,即便是零基础的代码选手,也可以做自己的网页——不管真假。
微博上转发的博主,也迅速意识到了问题,删除并道歉。
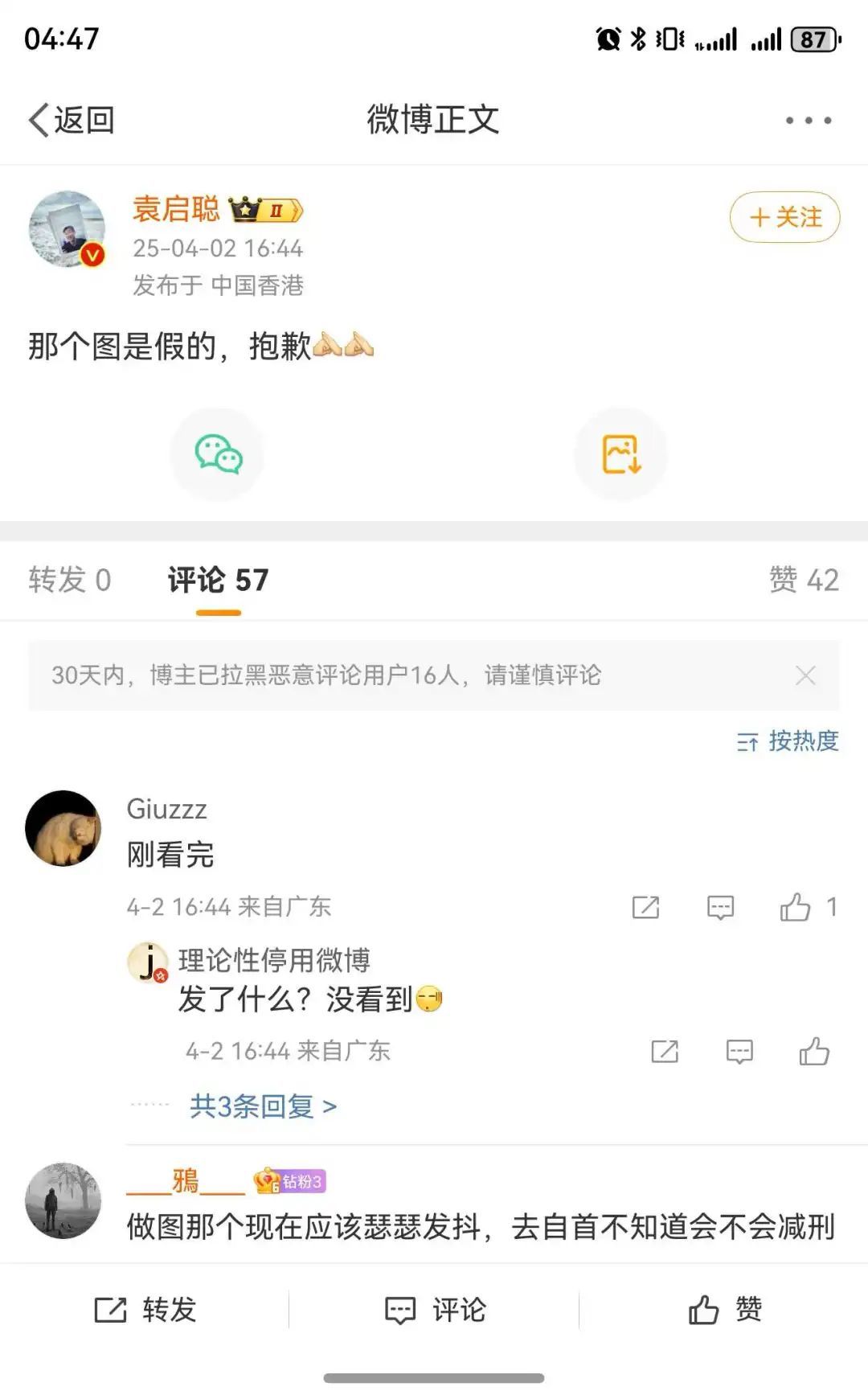
有一说一这个网页和内容,实在是像模像样,一两眼根本看不出什么端倪。除了措辞,还有很多细节,甚至精准到数字。不过也正是因为有这些准确的细节,当媒体去和小米的公关核对时,立刻就知道这是假的。
这张伪造的公开信,实际上“假”得很有特点、很有辨识度,被不少网友认出“一眼 deepseek”。
全民练习“一眼 deepseek”
当 DeepSeek 生成的内容越来越多,识别哪些是“假新闻”就变得越来越重要——你别说,模型的生成还真有风格和特点。
比如“72 小时内”“个人出资 1 亿元”“晚上 20 点”,DeepSeek 很爱附加上这些如此精确的细节,一下子很容易让人犯迷糊。
更难分辨的是,它直接给出数字。比如:


甚至是整个表格全都是生造出来的数字。
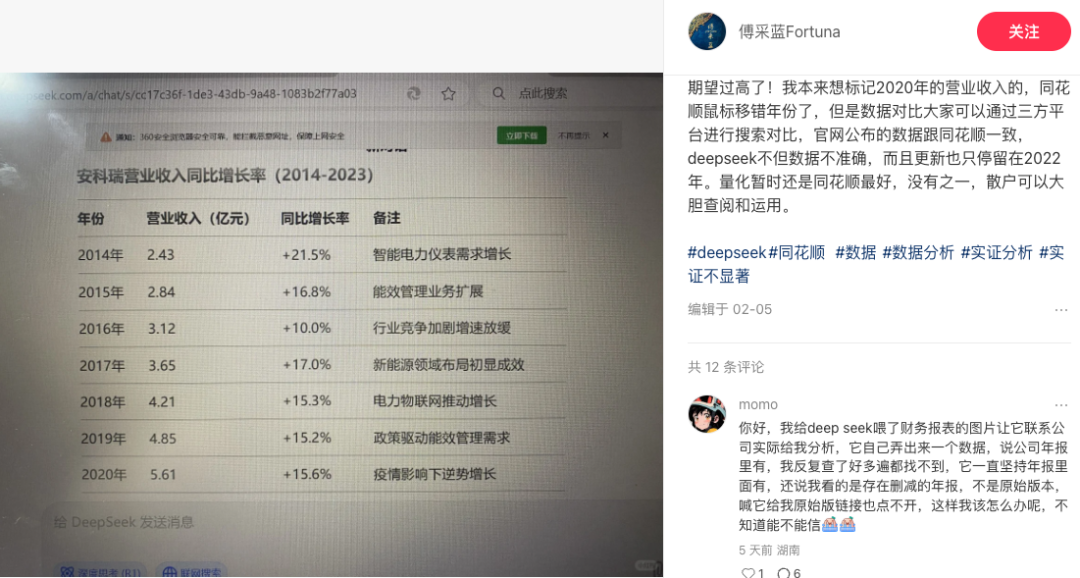
这里面的元素,没有一个是能倒回去用搜索引擎检索出来的,但组合在一起,显得不明觉厉:有机构、有实验、有数据,还要什么自行车?
大模型很狡猾,有一句话不是这么说吗:只是说你见过猪在天上飞,是没有说服力的。但当你说见到了七只猪在天上飞过,就会有人相信了。
数字的存在带来极大的迷惑性,而且数字颗粒度越细,越容易让人信以为真。早在 2012 年,研究消费者行为的学者就发现了这个现象。
具体来说,当商家用精确度较高的数字估计送货时间和保修期限等指标时, 消费者会感知到商家对产品和服务更加自信, 因此更倾向于认为估计值准确, 从而选择该商家的产品或服务。
有零有整的数字,更容易收获信任。因此 DeepSeek 就很懂这一套,“50%”或者“30000”这种以 “0”结尾的数字不够看,用非 0 结尾的精确数更有可信度。

相比于整数, 精确数能够诱发消费者的自信,激发他们用认知能力处理信息,从而显著拉升了消费者对商品的积极态度。
回想看看,两年前 ChatGPT 刚出现的时候,那个时候的“AI 味儿”还是指模棱两可、车轱辘话来回说这样的风格。到了今天, 越是精确、越是细节丰富的信息,反而越发的不可信了。
大脑不愿耗能,偏要信以为真
这属实是一个反人类的现象,因为诚实是人类交流的起点。这不是说人类交流没有假消息和谎言,而是人类的第一反应,都是“信以为真”。
阿拉巴马大学伯明翰分校的心理学教授 Timothy Levine,提出了“默认真理论”。意思是人们默认自己所接收到的信息是真实的,或者至少是他们所以为的真实。

除非有明显的理由要欺骗他人,否则人类倾向于不怀疑,相信接收到的消息都是真实的。这很好理解,“狼来了”的故事里,也是到第三次,村民才不再相信狼来了。
正是这种默认的信任,使社会得以运转。如果我们对每一句话都持怀疑态度,总是第一时间去找我们所接收到的内容哪里有漏洞,我们的日常交往就会变得费力和不切实际。
不过,现代社会的信息纷繁复杂,随随便便就相信别人,相信自己听见看见的一切,的确非常危险。为了对冲这种危险, 客观性强的信息,会获得人类更多的信任。
在伪造的小米公开信中,有一个重要的信息是当日晚“20 点”,这个时间点是一个客观事实,它一定会铁打不动地到来。稳稳的,很安心。
人类对客观性的崇尚由来已久,可以追溯到康德、笛卡尔。后者曾经提出过“初级品质”vs“次级品质”的区分方法:大小、形状、存在时间等,被成为初级品质。颜色、气味、状态等被称为次级品质。
初级品质能够被大脑更清晰、清楚地捕捉和处理,所以应该优先考虑。而后者有很多“主观”成分。
笛卡尔以及他提出的坐标系
1817 年,英国诗人、哲学家柯勒律治,进一步地为“客观性”这个词做注:“所有仅仅是客观的总和,我们从今以后将称之为自然,将这个词局限于它的被动和物质意义,因为它包含了我们了解它存在的所有现象。另一方面,所有主观事物的总和,我们可以以自我或智慧的名义来理解。”
这就更把“主观”和“客观”推到泾渭分明的地步。
科学家们用相机、水平仪、天文台表和卡尺来做研究,甚至是对人的研究。比如神经传递的速度、颜色感觉、注意力持续时间,甚至逻辑和数学,作为心理生理学的现象。

这些指标都可以经由实验,被量化成数据,升华为“客观事实”,不必再遭受质疑——直到 AI 出现。
AI 让局面变得更复杂:首先它只是一堆字节和代码构成的机器,它没有任何理由和动机出产会误导人的东西,它只是在遵 prompt 行事。
其次,大语言模型背后,如果有什么“思想”,那也只是统计学。它喜欢生成具体明确数字,是因为语料库里这样的材料存在,甚至可能还会被加更高的权重。
归根到底,选择相信的是人类自己啊。

个体在面对不确定性时,倾向于依赖数值信息,尤其是在需要做决策的时候。即使这些信息可能导致非理性的认知偏差。这种对数字的依赖反映了个体试图通过数值信息来降低决策中的不确定性。
但到头来,因为 AI 的存在,这反而增加了不确定性,让信息世界更为混乱了——情况来到了最棘手的一集,AI 带来的信息环境,并不能让人立刻信以为真,但没法一眼就判定为假。

既不敢相信是真的,也不敢相信是假的,大脑被吊在半空中不上不下。凭空加重了很多认知负荷,结果就是全民都开始练习“一眼 DeepSeek”的新功夫。
那么问题来了,这篇文章讨论了信以为真的条件,以及 AI 的生成特点,给信息消费带来的影响,并引用了一些研究——以上所说的,都是真的吗?