IT之家 4月15日消息,苹果公司昨日(4月14日)发布博文,披露其AI隐私保护核心技术细节,重点介绍差分隐私和合成数据在Apple Intelligence中的应用。
差分隐私守护AI进化
以生成Genmoji表情为例,用户选择共享设备分析数据时,系统会通过随机噪声算法,收集高频指令(如“戴着牛仔帽的恐龙”),但不会记录频次过低的个性化指令,且所有数据与设备ID完全脱绑。
具体实现中,设备端会随机返回真实指令片段或干扰信号,只有某条指令被数百设备同时提交后,系统才会识别。这种机制已帮助优化多实体组合表情的生成准确率,且全程不触及IP地址等敏感信息。
合成数据破解长文本难题
面对邮件摘要等涉及长文本的功能,苹果研发了专有合成数据方案。首先由大语言模型批量生成虚拟邮件(如“明早11:30打网球吗?”),将其转换为包含主题、语言特征的数字向量(embedding)。IT之家附上苹果官方博文演示图如下:
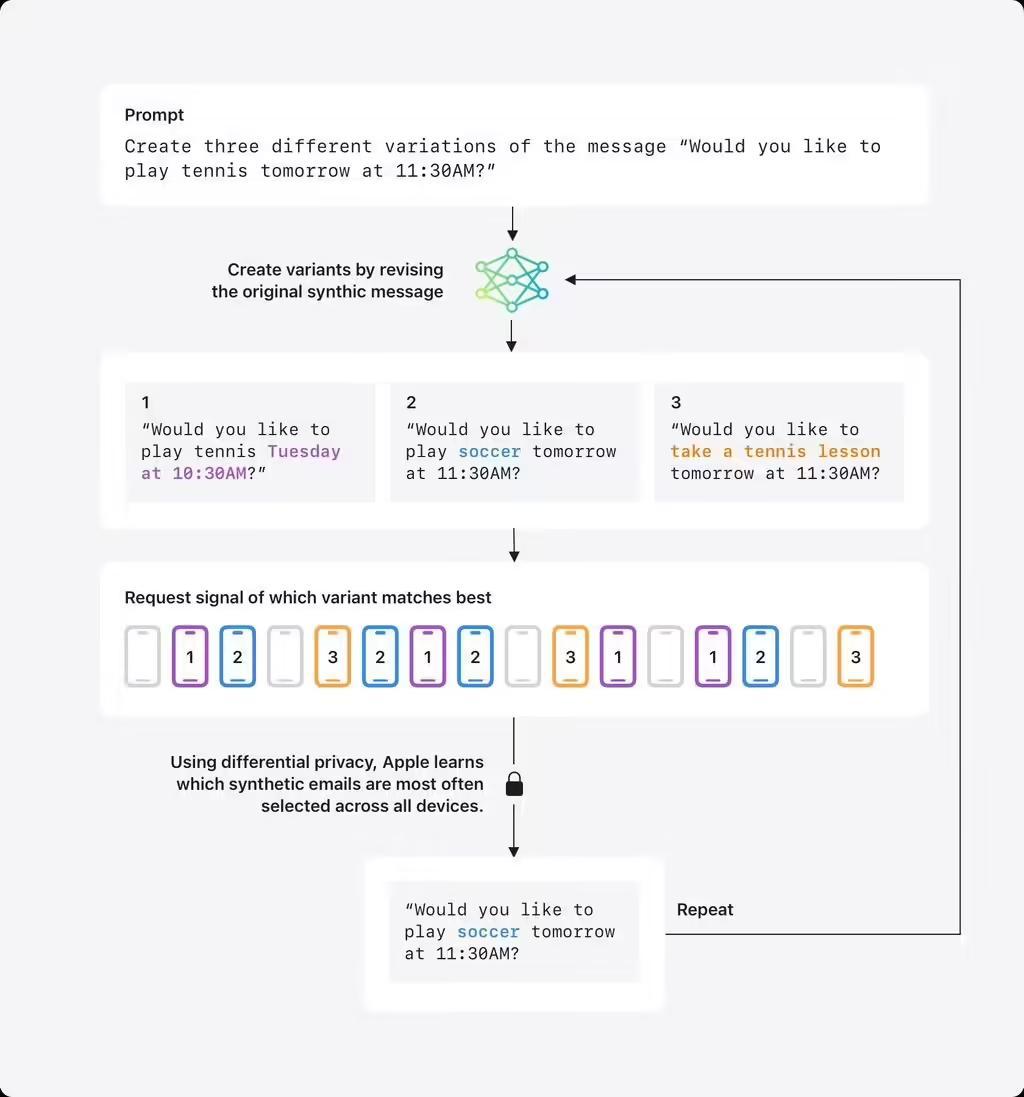
参与计划的设备会在本地计算真实邮件的向量,通过差分隐私技术匿名反馈最接近的合成向量类型。经过多轮迭代,系统最终获得能反映真实邮件分布规律的合成数据集,但全程不接触原始邮件内容。目前该技术已在测试版邮件摘要功能中验证效果,未来还将应用于写作助手等场景。
隐私原则贯穿技术演进
苹果在博文中强调,Apple Intelligence所有模型训练均采用去标识化数据,会预先过滤社交安全号等敏感信息。
即将发布的iOS 18.5等系统中,差分隐私和合成数据技术将扩展至Image Wand图像处理、记忆相册生成等十余项功能。苹果强调,即使用户启用设备分析计划,其个人数据也始终加密存储在本地,公司仅获取经数学验证的群体趋势报告。