
“超前一步是疯子,超前半步是天才。”
作者丨西西
编辑丨陈彩娴

过去两年,关于大模型的讨论视角很少从商汤这样成立不过十年、资源与技术积累正当青壮年的人工智能公司出发。造成这一现象的主要原因是两个技术周期的迥异:
2023 年之前,商汤的人工智能技术路径以计算机视觉模型为主,不同于 ChatGPT 为代表的新技术浪潮:以自然语言处理为主、大规模参数模型为核心。一个是视觉、一个是语言,在外界看来两个赛道还没有发生直接的关系。
然而,DeepSeek R1 的发布让一切变得“戏剧性”:ChatGPT 之后,各个大语言模型厂商在卷 GPT-4 的路上狂奔两年后几乎所有努力被 V3 与 R1 抹平。当语言方向的基础模型出现新的 SOTA,所有人都面临两个选择:要么以 DeepSeek 为靶子、继续卷最强语言大模型,要么寻找差异化的竞争点。
且不说 DeepSeek 的目标是 AGI、下一代基础模型未必只卷语言,单从数据源来看,根据权威研究机构 EPOCH AI 的调查(如下图),用于训练大语言模型的文本数据正在迅速接近危机点;据预测,到 2028 年,语言大模型的训练数据集将用完互联网的所有可用文本数量。
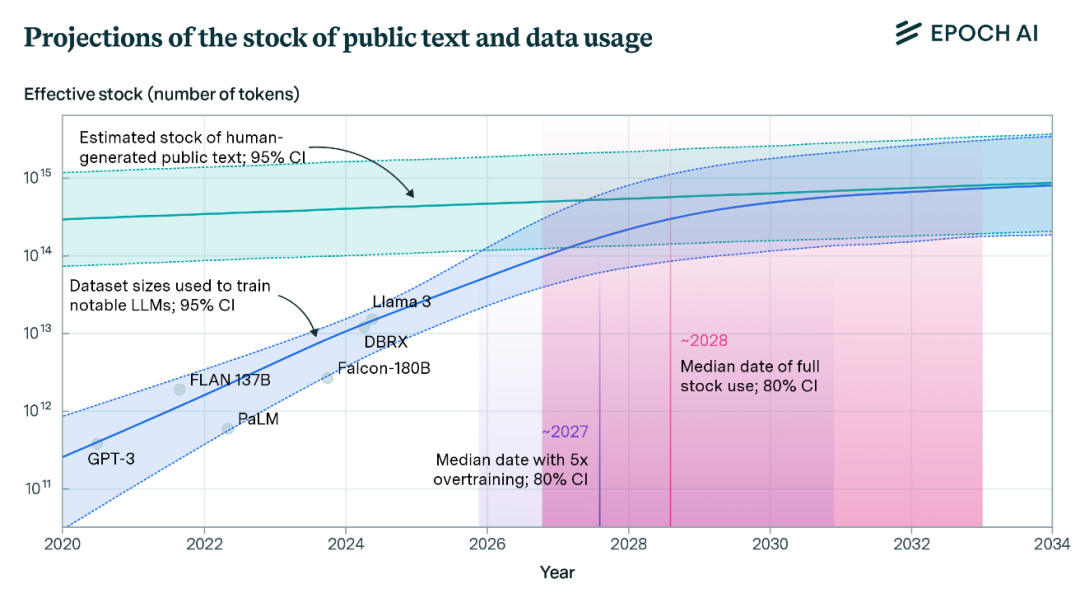
与此同时,近日语言大模型也逐渐体现出性能随参数规模加大提升的边际效益递减趋势。因此,相比大语言模型的竞争,更多顶尖团队将目光看向了迈向 AGI 的下一阶段:多模态大模型。继 GPT-4o 后,OpenAI、谷歌与 Meta 等科技巨头陆续发布了 GPT-4.5、Gemini 2.0/2.5 Pro 与 Llama 4 等数个性能强大的多模态基础模型。
当语言与视觉融合渐成趋势,商汤的过去与人工智能的未来聚首,其在国内大模型市场格局中的角色也逐渐变得更加举足轻重:
除了商汤大装置与过去十年所积累的行业落地经验,商汤在基础模型的研究上也逐渐占据优势,经过两年的投入努力,不仅弥平了文本的差距,而且在最新的多模态大模型中厚积薄发。
据商汤 4 月 10 日的发布,其新一代 6000 亿多模态大模型“日日新 Sense Nova V6” 在多模态综合能力上可以向 GPT-4.5 与 Gemini 2.0 Pro 看齐、甚至略微超过。不仅如此,商汤还引入长思维链,率先将多模态与深度思考结合了起来。
事实上,商汤从 2024 年年中就开始探索原生融合的多模态大模型,并早已在今年的 1 月 10 号、R1 发布并爆火前登上 SuperCLUE 和 OpenCompass 两大权威榜单榜首,成为大语言与多模态能力的“双冠王”。
前有商汤大装置领先半步,后有原生多模态大模型厚积薄发,商汤在大模型这波浪潮中的综合竞争力或许被严重低估了。
01
是落后,还是领先?
一个不争的事实是:在第一个十年成立的人工智能算法公司中,经过两年的大模型技术革新,商汤是极少数能够迅速转弯、从视觉算法跨越到大模型技术周期并保持算法创新生命力的 AI 公司之一,手持两大通行证——大装置与日日新。
2023 年大模型风靡初始时,商汤凭借大装置拿到了大模型的入场券,在业内创下不到一个月就构建起服务于大模型训练的千卡集群,不仅使商汤在庞大算力上的投入有所回报、开始盈利,还为商汤在后续赶超基础模型的研究上赢得了时间。
如果说商汤的大装置领先行业至少 3 年,日日新的正式发布比行业最早晚 1 年,将算力与算法协同、再考虑商汤在过去十年所积累的商业化实战经验来看,事实上商汤大模型的综合实力大约领先行业 1-2 年。而在商汤陆续发布原生融合多模态大模型日日新 SenseNova V6 后,这一差距又被拉长至少半年。
为什么这么说?
因为当前原生多模态大模型的技术难度仍极高,而商汤的日日新 V6 已能达到对标国际顶尖多模态大模型 GPT-4.5 与 Gemini 2.0 Pro 的水平。
虽说过去两年海内外发布了大量的多模态模型成果,但真正能够在输入与输出端同时做到文字、语音、图像、视频等至少两个模态数据融合,并完成从感知、理解、推理到决策、生成等任务环节的多模态大模型还寥寥无几。
这要求从底层架构、高质量数据清洗到上层算法的整体创新,如 Transformer 虽擅长文本的长序列表达、却久有说法认为其在多模态乃至空间智能中有待提升,且暂无暴力出奇迹的先例,最新案例可参考 Meta 发布的 Llama 4、即使投入巨大也提升甚微。
目前多模态模型的广泛研究方法大体可以分为两条路线:一条是从语言模型出发,在语言模型的基础上叠加其他的语音、图像等模态;另一条则是从视觉出发,在图像或视频的基础上叠加语言、语音、视觉等模态。此外,多模态研究在终局上也有追求 AIGC 与追求 AGI 之分,这决定了多模态模型的研究天差地别。
当前多模态模型仍以百亿参数规模为主,这背后的原因主要是两点:一是多模态大模型所消耗的算力要比纯语言大模型更大;其次,当多模态模型的参数规模上升到千亿级别后,不同模态之间的数据融合、让彼此相得益彰而非此消彼长的难度也变得更大。
有研究团队曾向雷峰网描述过这样的一个研究难题:当他们尝试从百亿文本模型扩大到超五千亿多模态模型后,后加入的图像、视频与语言数据出现了拉低文本数据表现的现象。由此可见,要获得一个多模态数据规模扩大到数千亿、且多个模态之间能相互“提携”的高水平原生多模态大模型,难度极高。
据商汤科技联合创始人、执行董事及人工智能基础设施和大模型首席科学家林达华介绍,商汤从 2024 年 5 月 GPT-4o 发布后就开始坚信多模态大模型是未来,于是迅速开始研究。一开始商汤也是采取传统的“核心模态+次要模态”路线,但会出现一个模态削弱另一个模态的问题,没有达到 1+1>2 的效果,之后投入大量时间攻坚两个以上模态之间的桥接技术,12 月训练出“双冠王”验证了他们的原生融合路线。
在 12 月那版融合模型的基础上,商汤继续 Scale Up,实现了新一代原生融合多模态大模型 SenseNova V6,参数规模 6000 亿,且根据官方评测数据披露,V6 不仅在综合多模态任务上对标 GPT-4.5 与 Gemini 2.0 Pro,且在纯文本任务上也能比拟 DeepSeek V3(看下图左表)、推理能力比拟 GPT-o1(下图右表):
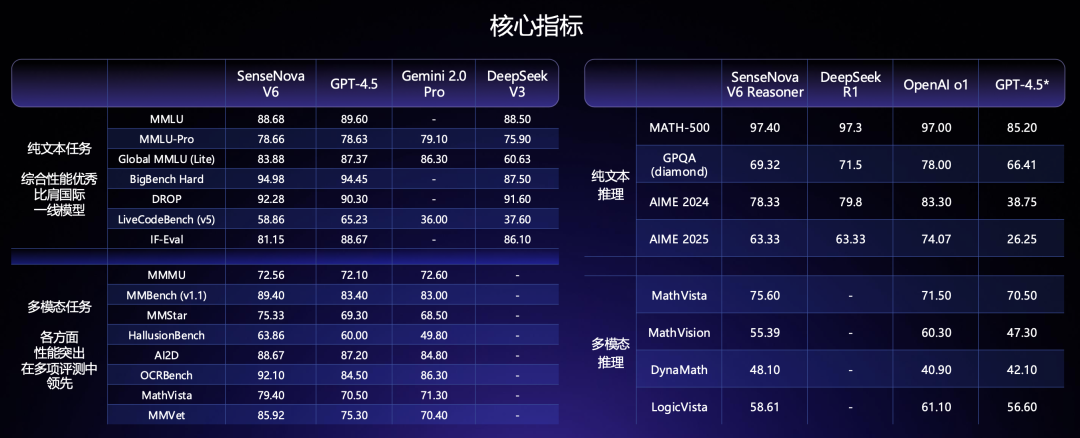
注:谷歌 Gemini 2.5 Pro 才发布不到一个月,各项指标还未有公开评测分数,暂且不计
V6 的主要技术创新性体现在两块:一块是多模态的关键桥接,在模型的预训练阶段就已经将文本、语音、视频和图像等数据融合在一起训练,使不同模态之间相辅相成,在同一个上下文窗口对齐;另一块则是对 DeepSeek 核心思想的借鉴与先前半步,具体表现为多模态的长思维链构造与输出端的融合 RL(强化学习)。
DeepSeek 目前仍以文本为主,而商汤从头到尾都是以开发多模态大模型为核心,因此在深度思考与强化学习的技术上也以多模态为母体,率先探索了多模态模型的长思维链构造。
据了解,目前商汤通过智能体生成的思维链总储备已经超过 1000 万条,日日新 V6 能够生成长达 64K 的高质量思维链,这意味着商汤的多模态大模型在解答用户的提问前就已经能够进行超过 6 万字的深度思考,发展全局记忆。
商汤的独特之处是,在构建思维链的过程中,每一步都会利用前一步的图文多模态信息、以及综合的推理情况来进行下一步思考推理。换言之,V6 的每一步推理都有一个形象的思维与一个逻辑的思维混合——这也是与纯语言思维链的一大不同之处。
而此前无论是人类的成长路径还是大模型的迭代进程,都表明了:多模态数据不仅能弥补纯语言大模型的数据瓶颈,且多模态模型的学习效率更高。
据林达华坦言,V6 并没有完全消除大模型的幻觉问题,而是通过输入端的数据质量严格把关与输出端的融合 RL 来缓解幻觉问题。相比 DeepSeek R1,V6 的奖励信号会更丰富,包含结果奖励、RLHF 奖励以及通过视觉理解判断模型语言描述与图像视频是否一致等;同时在模型的思考过程中分阶段进行基于事实、而非奖励的强化学习。
在多模态大模型的训练上,由于大装置与大模型的紧密协同,商汤日日新 V6 的训练与推理也进行了极大的效率优化。
据商汤科技联合创始人、大装置事业群总裁杨帆介绍,商汤自己去训练 DeepSeek 模型的训练效率,比原厂发布出来的指标还要好。商汤大装置可以达到每卡每秒 1600+ 个 token,DeepSeek 官方报告所披露的数据是 1500+ token。
除了大装置,商汤在自有训练引擎 SenseParrots 上也搭载了最早跑通千卡训练的系统。此外,商汤从 2018 年开始用国产芯片进行模型训练,国产芯片数量至少占比 20%,V6 的一部分训练也是在国产芯片上进行的。
在推理上,商汤大装置采取了 PD 分离、通信计算折叠、FP8 强化与算子优化等方法进行效率优化,在线服务推理性能超行业平均水平 25%;离线推理方面,与开源方案相比,商汤大装置在 Prefill 阶段提速 5 倍、Decode 阶段提速 3.5倍。
DeepSeek 在大语言模型赛道的后来居上已经表明:AGI 的长跑需要算力与算法的综合能力。而相比纯语言模型,多模态大模型无论是训练还是推理都需要更高的算力,细微的进步累积起来即是长远的差距。技术无法构建坚不可摧的壁垒,但能赢得利于竞争的时间差。
商汤日日新 V6 在原生多模态大模型与多模态深度思考推理上已领先半步,无疑向大模型行业传递了一个信息:
穿越两个技术周期的商汤,已经坐上了大模型的核心牌桌。
02
更全面的竞争
当商汤在大模型市场上的位置被重新审视,这家相比 BAT 不大、相比初创公司又不小的 AI 小巨头就显现了其独特的竞争优势。
技术上,AGI 是数据、算法与算力的并驾齐驱。数据层,商汤的日日新多模态大模型已经体现其融合文本、图像、3D、视频等多种模态数据的能力;算法与算力层,商汤的十年积累不逊于同时坐拥云计算与基础模型的互联网大厂,但两者虽有诸多相似,却仍有本质的不同。
这种不同体现在“终局思维”的本质差异上:互联网大厂研究基础模型的最终落脚点往往是打造流量聚集的“Super App”;而商汤从成立第一天开始就是一家“人工智能”公司,其终局目标是参与构建人工智能时代,也因此商汤在大模型的商业落地上没有 To B 与 To C 的纠结。无论是算法还是算力,商汤都愿意成为行业的一个“摆渡人”。
当算法的差距被追平后,技术的星辰大海终归回落尘埃大地,在大模型的商业化落地上,商汤过去十年在各行各业所积累的经验天然降维打击——创业公司还在商场学习走路的时候,商汤已经踩完一遍坑,越过山丘。
与 DeepSeek 不同,商汤对大模型的思考天然不仅是基础模型的研究突破,还有模型的商业落地。在过去,商汤本身已触达包括手机、汽车、营销在内的广泛业务,基于业务提炼出来的需求也指导了模型能力的优化。
以日日新 V6 为例,商汤追求原生的多模态大模型之余,同时强调模型的三大能力:推理能力,情感共鸣与实时交互能力,以及长记忆/全局记忆能力。
根据商汤日日新 V6 已接入的场景显示,在大模型的落地场景中,主流的交互方式不单单是文本,实时视频通话的流量与十分巨大。与文本类似,视频交互对长视频的输入窗口与模型的长记忆能力有高要求。V6 可以支持长达 10 分钟的整段视频输入,将语音、文字与视频形成统一的、与时间轴对齐的上下文表达,然后进行深入的理解、分析与推理。
在流式交互上,商汤从 GPT-4o 发布后就一直坚持打造多模态的交互入口。在商汤的设想中,通过终端与人类进行多模态交互的大模型必然是轻量化模型、而非 600B 的基础模型;此外,与人的实时交互对模型情感共情、拟人表达的能力也提出高要求。而据数据统计,商汤是中国除字节外在拟人对话引擎上的第二大供应商。
基于全新日日新原生多模态大模型,商汤提出“一基两翼”的落地方案:所谓“两翼”,指的是应用在具身智能、硬件、眼镜等方向的智能交互,及应用于金融、办公等领域的生产力工具。
日日新 V6 基础模型能力的提升,让 AI 产品的想象空间也有了一个质的飞跃。例如,多模态综合能力与多模态深度思考推理叠加高情商的拟人交互方式,在数学解题、点读翻译、文旅讲解、绘本讲解等等日常高频需求的响应中都取得了相较于以往多模态模型更出色的性能表现。

同样,在具身智能领域,商汤与傅利叶等机器人厂商合作,也探索了 V6 与终端结合的可能性。基于日日新 V6 多模态融合能力,机器人能同时掌握“大脑”、“耳朵”、“眼睛”与“嘴巴”等多个感官,并通过融合信息理解环境、进行深度思考。
而在小浣熊系列,V6 的多模态深度思考与推理能力使办公小浣熊的任务规划、数据分析、文档编辑等能力有了更大幅的提升。小浣熊不仅支持excel、数据库等结构化数据,还支持word、pdf、txt、图片等非结构化数据解析,并且支持跨数据源融合解析,在 Tablebench 和 1000+ 数据分析场景评测精度超过 GPT-4o。

根据商汤 2024 年的财报,商汤生成式 AI 的业务收入达到 24 亿元,在总收入中的占比高达 63.7%,同比涨幅超过 100%。
当前大模型在许多场景中的落地还没有越过产品性价比的生死线。而商汤作为一家沉浮商海多年的“OG”,无论是大装置与大模型的协同,还是更注重 To B 而非 To C 的商业打法,都死死咬住生存的第一性原理。
以机器人为例。在多模态大模型的进步下,终端的智能只需一个模型就能达到多种能力、而非需要一个多模态模型再加一个语言大模型,性价比更高。
商汤有自己的 C 端应用,但从当前的大模型商业化来看,其重点主要集中在 B 端业务上。从构建人工智能时代的“终局思维”来看,推动更多行业、更多需求转向“AI-Native”对商汤来说比加大投入追求 SuperApp 更有价值。
目前,商汤日日新已经支撑了包括 WPS、阅文、想法流在内的多个明星 C 端应用。这在一方面可以使技术与商业紧密绑定,同时驱动数据飞轮。
算力、算法、用户与商业是一套完整的模型体系,任一环节的极速飞转都会带动其他几环的飞跃。在大模型的浪潮中,商汤的启动飞轮是大装置与商业积累;日日新大模型系列发布后, 商汤多模态大模型的实力有了极大提升,尤其是 V6 的巨大突破让算法飞轮也体现出了巨大的潜力。
超前一步是疯子,超前半步是天才。从大装置到日日新 V6,商汤都精准预判了每一个技术趋势、并快速取得里程碑的成就。商汤大模型的下一个巨大飞轮能否由算法主导,绝对值得拭目以待。