来源 机器之心
深夜,OpenAI 发布了 o 系列模型的最新成果 o3 和 o4-mini。该系列模型经过训练,会在响应之前进行更长时间的思考。
OpenAI 表示,这是他们迄今为止发布的最智能模型,也标志着 ChatGPT 能力的巨大飞跃。
这次新发布的推理模型能够像智能体一样使用并组合 ChatGPT 中的每一个工具 —— 这包括搜索互联网、用 Python 分析上传的文件和其他数据、深入推理视觉输入,甚至生成图像。

至关重要的是,这些模型经过训练,能够推理何时以及如何使用工具,以在正确输出格式下产生详细且深思熟虑的答案,通常在不到一分钟的时间内解决更复杂的问题。这使得它们能够更有效地应对多面性问题,迈向一个更具自主性的 ChatGPT,独立为你执行任务。
OpenAI CEO 山姆・奥特曼表示,o3 和 o4-mini 功能非常强大,尤其擅长多模态理解,并且可以组合使用 ChatGPT 中的所有工具。另外,o4-mini 的价格非常划算。
从今天开始,ChatGPT Plus、Pro 和 Team 用户可以在模型选择器中看到 o3、o4-mini 和 o4-mini-high,取代 o1、o3‑mini 和 o3‑mini‑high。ChatGPT Enterprise 和 Edu 用户将在一周内获得访问权限。
免费用户可以在提交查询之前,在编辑器中选择‘Think’来试用 o4-mini。所有计划的速率限制与之前的模型组保持不变。
此外,OpenAI 预计将在几周内发布 o3‑pro,并提供全面的工具支持。目前,Pro 用户仍然可以访问 o1‑pro。
开发者现在也可以通过‘Chat Completions API’和‘Responses API’使用 o3 和 o4-mini(部分开发者需要验证其组织才能访问这些模型)。 Responses API 支持推理摘要,能够在函数调用周围保留推理 token 以提高性能,并且即将在模型推理中支持内置工具,例如网页搜索、文件搜索和代码解释器。
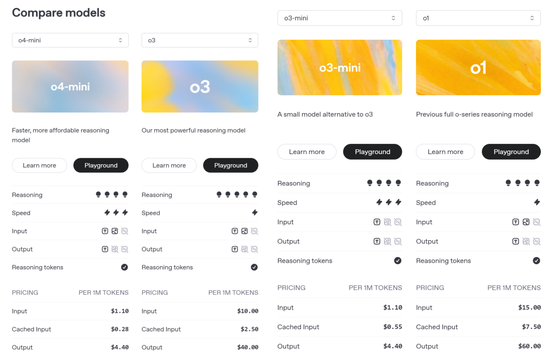
至于 API 价格,o3 比 o1 全方位(输入、cached 输入和输出)降低,o4-mini 也比 o3-mini 部分降低。
新模型强在哪里?
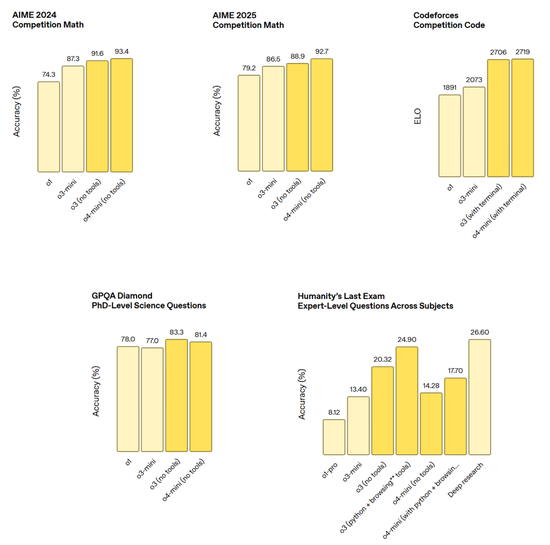
o3 是 OpenAI 最强大的推理模型,它推动了编程、数学、科学、视觉感知等领域的前沿发展。o3 在 Codeforces、SWE-bench(无需构建自定义模型专用框架)和 MMMU 等基准测试中创下了新的 SOTA(最佳性能)。
o3 非常适合需要多方面分析且答案可能并非显而易见的复杂查询,并在分析图像、图表和图形等视觉任务中表现尤为出色。在外部专家的评估中,o3 在困难的现实任务中比 o1 犯的重大错误少 20%,尤其是在编程、商业 / 咨询和创意构思等领域表现出色。
早期测试人员强调了 o3 作为思想伙伴的分析严谨性,并强调了其生成和批判性评估新假设的能力,尤其是在生物学、数学和工程学领域。
OpenAI o4-mini 是一款小型模型,专为快速、经济高效的推理而优化,它以其尺寸和成本实现了卓越的性能,尤其是在数学、编程和视觉任务方面。
o4-mini 是 AIME 2024 和 2025 基准测试中表现最佳的模型。在专家评估中,它在非 STEM 任务以及数据科学等领域的表现也优于其前身 o3-mini。得益于其高效性,o4-mini 支持的使用限制远高于 o3,使其成为解决需要推理能力的问题的强大高容量、高吞吐量解决方案。
外部专家评估人员认为,得益于智能化的提升和网络资源的引入,o3 和 o4-mini 都比前代模型展现出了更佳的指令遵循能力,以及更实用、更可验证的响应。
与 OpenAI 之前的推理模型相比,这两个模型的体验也更加自然、更具对话性,尤其是在参考记忆和历史对话的情况下,响应更加个性化和相关。
多模态基准测试(包括 MMMU 大学水平的视觉问答、MathVista 视觉数学推理和 CharXiv-Reasoning 论文图表推理):

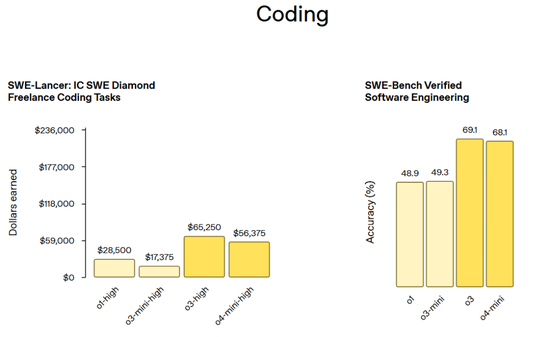
编程基准测试(包括 SWE-Lancer: IC SWE Diamod Freelancer 编程任务和 SWE-Bench Verified 软件工程任务):
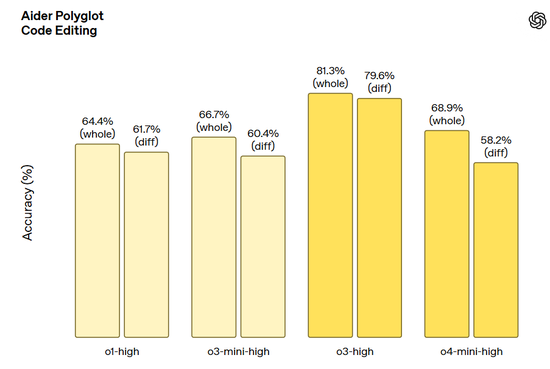
Aider Polyglot 代码编辑任务:
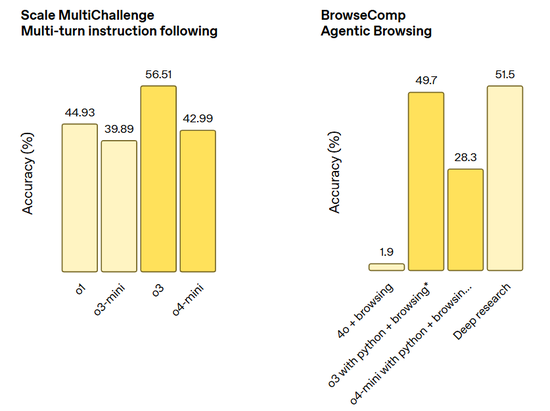
指令遵循和智能体工具使用任务(包括 Scale MultiChallenge 多轮指令遵循和 BrowerComp 智能体浏览):
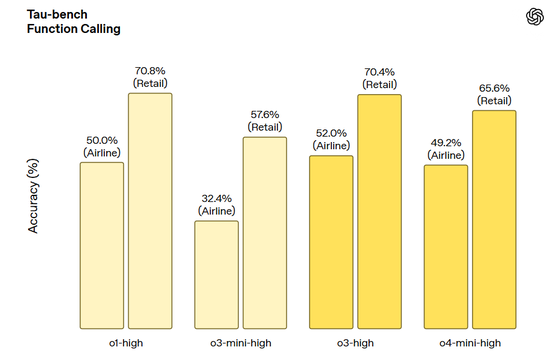
Tau-bench 函数调用:
继续扩展强化学习,模型掌握工具使用
在 OpenAI o3 开发过程中,OpenAI 观察到大规模强化学习表现出与 GPT 系列预训练中观察到的趋势相同,即‘计算量越大,性能越好(more compute = better performance)’。
通过重新追溯这一扩展路径,这次是在强化学习中 ——OpenAI 在训练计算和推理时间推理能力方面又向前推进了一个数量级,但仍能清晰地看到性能的提升,这验证了模型的性能会随着其被允许思考的时间越长而持续提高。在与 OpenAI o1 相同的延迟和成本下,o3 在 ChatGPT 中的性能更高 ——OpenAI 已经验证,如果让模型思考更长时间,其性能还会继续攀升。
OpenAI 还通过强化学习训练这两个模型掌握工具使用的能力 —— 不仅教会它们如何使用工具,更让它们学会判断何时该使用工具。这种根据目标结果自主调配工具的能力,使它们在开放式场景中表现尤为出色 —— 特别是在涉及视觉推理和多步骤工作流的任务中。正如早期测试者反馈所示,这种提升既体现在学术基准测试中,也反映在实际任务表现上。
根据图像进行思考
首次,模型能够在思维链中运用图像进行思考,而不仅仅是看到图像。这开启了一类新的问题解决方式,视觉和文本推理终于结合在一起了。无论是上传的白板照片、教科书图表或手绘草图,即使图像模糊、反转或质量低下,模型也能对其进行解读。
与之前的 OpenAI o1 模型类似,o3 和 o4-mini 经过训练,可以在回答前进行更长时间的思考,并在回复用户之前运用较长的内部思维链。o3 和 o4-mini 进一步扩展了这一能力,将图像融入其思维链中,通过使用工具转换用户上传的图像,使其能够进行裁剪、放大和旋转等简单的图像处理技术。更重要的是,这些功能是原生的,无需依赖单独的专用模型。
这种方法为测试时间计算扩展提供了一个新的轴,可以无缝融合视觉和文本推理,这反映在它们在多模态基准测试中的最先进的性能上,标志着朝着多模态推理迈出了重要一步。
用户可以通过拍照提问,无需担心物体的位置 —— 无论是文字颠倒,还是一张照片中存在多个物理问题。即使物体乍一看并不明显,视觉推理也能让模型放大查看,从而更清晰地观察。
举例来说:问笔记本上写了什么,其实这个笔记本上的字体根本看不清,并且字体是颠倒的,这些问题都被 OpenAI o3 在推理过程中一一解决了。

用户输入图片
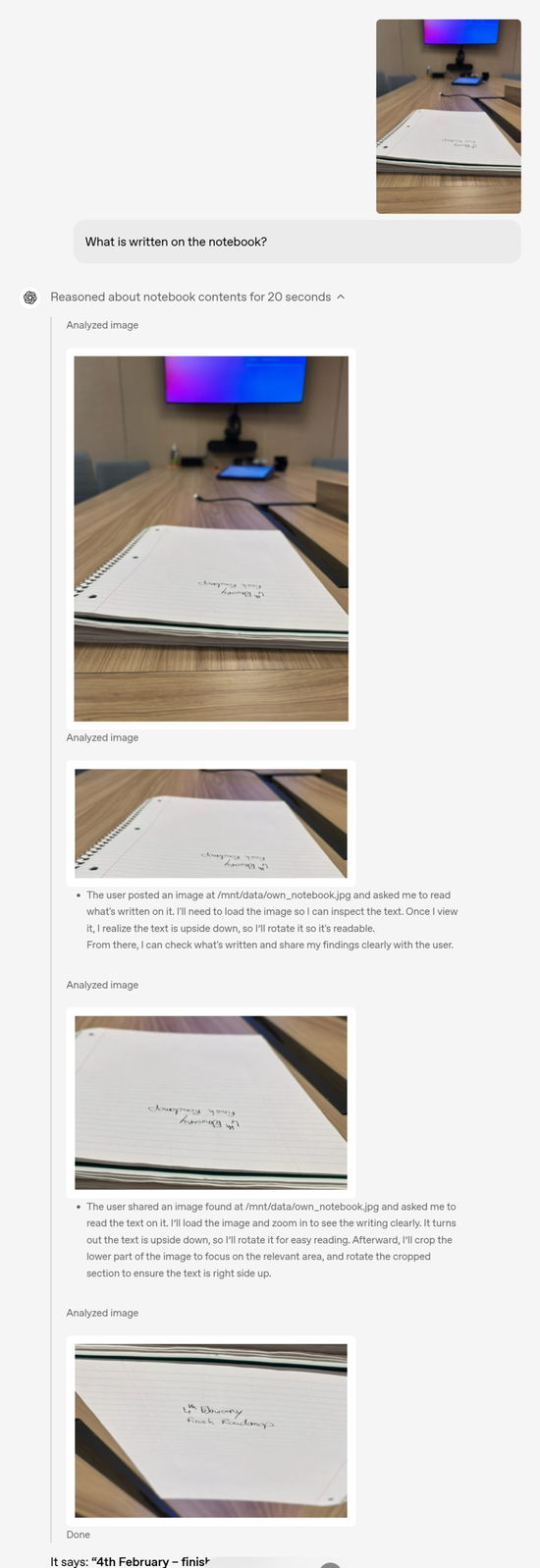
下面的示例是 OpenAI o3 做题过程,我们能看到其清晰的思维链过程。
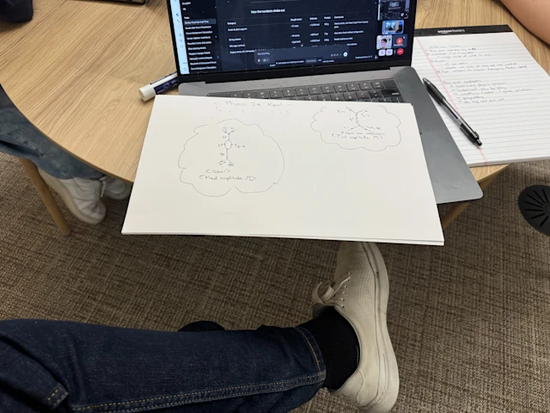
用户输入图片

走迷宫示例:

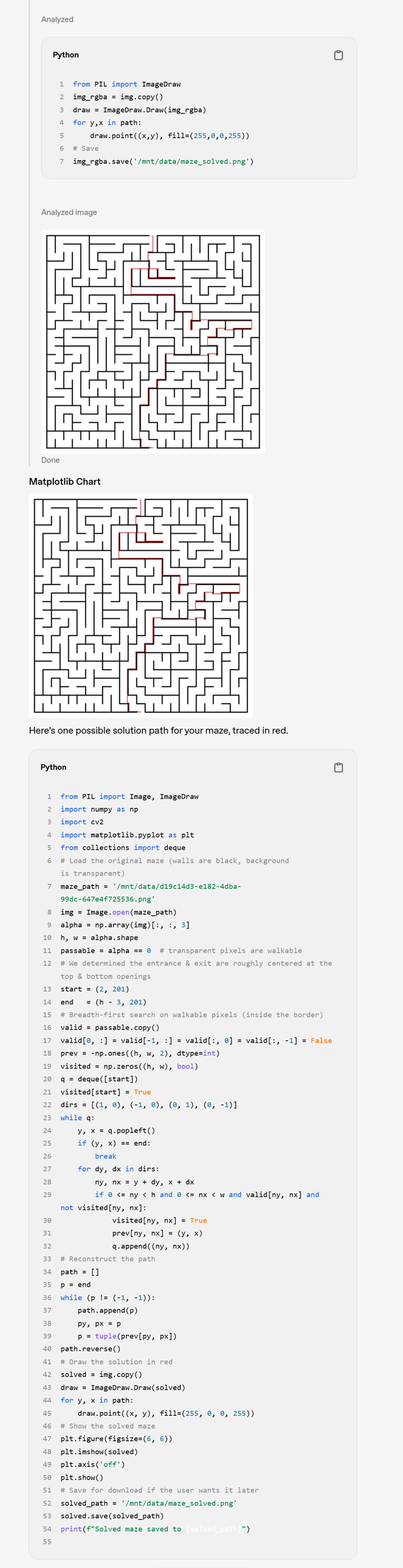
中间省略了较长的思维链过程
智能体工具使用
o3 和 o4-mini 可以完全访问 ChatGPT 中的工具,以及通过 API 中的函数调用访问用户自己的自定义工具。这些模型经过训练,能够推理如何解决问题,选择何时以及如何使用工具,从而快速(通常在一分钟内)以正确的输出格式生成详细而周到的答案。
例如,用户可能会问:‘加州夏季的能源使用量与去年相比如何?’ 该模型可以在网上搜索公共事业数据,编写 Python 代码构建预测,生成图表或图像,并解释预测背后的关键因素,并将多个工具调用串联在一起。
推理功能使模型能够根据遇到的信息做出反应和调整。例如,它们可以借助搜索引擎多次搜索网页,查看结果,并在需要更多信息时尝试新的搜索。
这种灵活的策略方法使模型能够处理需要访问最新信息的任务,而不仅仅是模型的内置知识、扩展推理、综合和跨模态输出生成。
比如在视觉推理任务中,o3 准确地考虑了时间表并输出了可用的计划,而 o1 则存在不准确之处,导致某些演出时间出现错误。

再比如在科学问答任务中,o3 提供了全面、准确且富有洞察力的分析,分析了最近的电池技术突破如何延长电动汽车续航里程、加快充电速度并推动采用,所有这些都有科学研究和行业数据作为支持。o1 虽然可信且切题,但不够详细和具有前瞻性,存在一些小错误或过于简单化。

推进高效(cost-efficient)推理
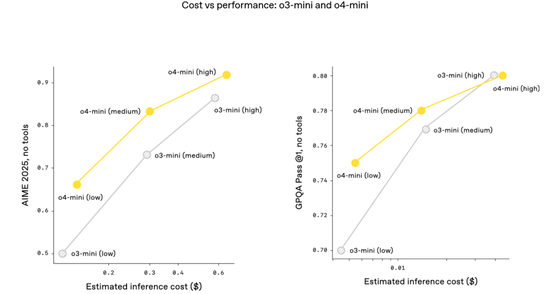
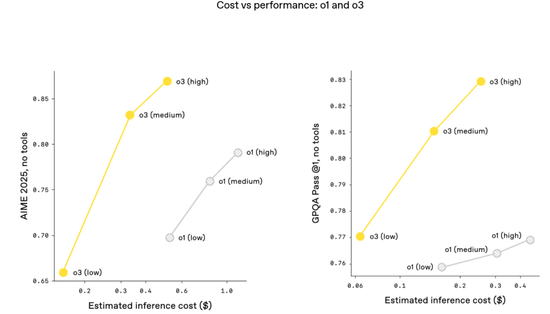
o3 和 o4-mini 是 OpenAI 迄今为止发布的最智能模型,而且它们通常也比其前辈 o1 和 o3-mini 更高效。
例如,在 2025 年 AIME 数学竞赛中,o3 的性价比边界比 o1 有显著提升;同样,o4-mini 的性价比边界也比 o3-mini 有显著提升。
更普遍地讲,OpenAI 预计,在大多数实际应用中,o3 和 o4-mini 也将分别比 o1 和 o3-mini 更智能、更经济。
安全
模型能力的每一次提升都意味着安全性的相应提升。对于 o3 和 o4-mini,OpenAI 彻底重建了安全训练数据,在生物威胁(生物风险)、恶意软件生成和越狱等领域添加了新的拒绝提示。
这些更新的数据使 o3 和 o4-mini 在 OpenAI 的内部拒绝基准测试(例如指令层次结构、越狱)中取得了优异的表现。
除了模型拒绝方面的出色表现外,OpenAI 还开发了系统级缓解措施,以标记前沿风险领域的危险提示。与之前在图像生成方面的工作类似,OpenAI 训练了一个推理 LLM 监控器,它基于人工编写且可解释的安全规范。当应用于生物风险时,该监控器成功标记了 OpenAI 人工红队演练活动中约 99% 的对话。
OpenAI 还采用迄今为止最严格的安全程序对这两种模型进行了压力测试。根据 OpenAI 更新的应急准备框架,他们根据该框架涵盖的三个跟踪能力领域(生物和化学、网络安全以及人工智能自我改进)对 o3 和 o4-mini 进行了评估。
根据评估结果,OpenAI 确定 o3 和 o4-mini 在所有三个类别中均低于该框架的‘高’阈值。
关于更多 o3 和 o4-mini 的信息,大家可以参考 OpenAI 完整的模型系统卡。

地址:https://cdn.openai.com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini-system-card.pdf
开源 Codex CLI:终端前沿推理
OpenAI 还分享了一项新实验:Codex CLI,这是一款可在终端运行的轻量级编程智能体。它可以直接在个人计算机上运行,最大限度地提升 o3 和 o4-mini 等模型的推理能力,并即将支持 GPT-4.1 等更多 API 模型。
用户可以通过将屏幕截图或低保真草图传递给模型,并在本地访问代码,从而从命令行获得多模态推理的优势。OpenAI 将 Codex CLI 视为一个将自身模型连接到用户及其计算机的极简界面。Codex CLI 现已完全开源。
开源地址:https://github.com/openai/codex
效果如下:
此外,OpenAI 还将启动一项 100 万美元的计划,以支持使用 Codex CLI 和 OpenAI 模型的项目。OpenAI 将以 API 积分的形式评估和接受每 2.5 万美元的资助申请。
责任编辑:江钰涵